pandas series 相加_Numpy和Pandas教程
Pandas简介
- python数据分析library
- 基于numpy (对ndarray的操作)
- 有一种用python做Excel/SQL/R的感觉
- 为什么要学习pandas?
- pandas和机器学习的关系,数据预处理,feature engineering。
- pandas的DataFrame结构和大家在大数据部分见到的spark中的DataFrame非常类似。
目录
- numpy速成
- Series
- DataFrame
- Index
- 文件读写
Numpy简介
Numpy是Python语言的一个library numpy
- Numpy主要支持矩阵操作和运算- 现在比较流行的机器学习框架(例如Tensorflow/PyTorch等等),语法都与Numpy比较接近
Arrays/数组
%config ZMQInteractiveShell.ast_node_interactivity='all'
%pprint
import numpy as np#嵌套list转numpy array
a = np.array([[1,2,3], [4,5,6]])
a
type(a)# 随机生成array
b= np.random.random((2,2))
b# 查看维度
a=np.array([[[1,2,3],[4,5,6]],[[1,2,3],[2,4,5]]])
a
a.shapeprint(a.shape, b.shape, a.dtype, b.dtype)# astype做类型转换
a.astype(np.float)数组索引与切片/Array indexing and slicing
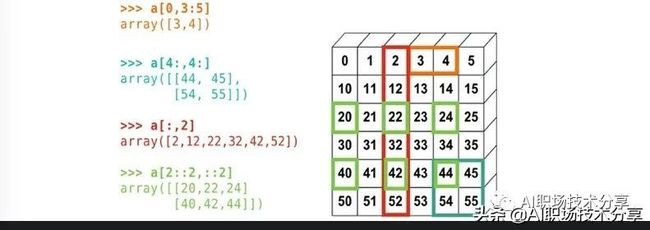
a
a[0,1]a
a[:, 1:3]a.sizeboolean indexing
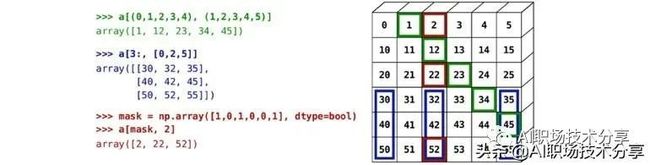
a
a > 2a[a>2] #根据条件选择a[a>2] = 0 #根据条件选择数据进行赋值
a数学运算
a
a.shapec = np.random.random((2,3))
c
c.shapea + ca - ca * ca / c广播特性/boardcasting
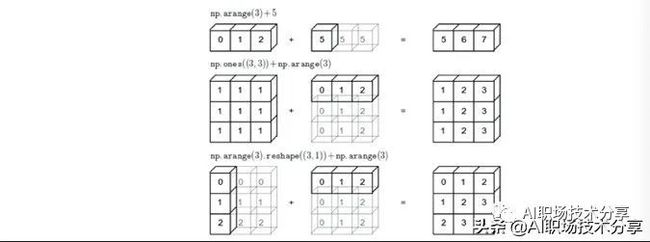
a + 2 #类似于上图1c = np.random.random((1,3))
caa + c #维度(2,2,3)和(1,3)的array相加,基于广播特性,最后得到维度(2,2,3)的array当操作两个array时,numpy会逐个dimension比较它们的shape,在下述情况下,两arrays会兼容和输出broadcasting结果:
相等
其中一个为1,(进而可进行拷贝拓展已至,shape匹配)
当两个ndarray的维度不完全相同的时候,rank较小的那个ndarray会被自动在前面加上一个一维维度,直到与另一个ndarray rank相同再检查是否匹配
比如求和的时候有:
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3
A (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5
A (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
A (2d array): 15 x 3 x 5
B (1d array): 15 x 1 x 5
Result (2d array): 15 x 3 x 5a=np.random.random((8,1,6))
b=np.random.random((1,6,1))
(a+b).shape统计数学运算
a
np.sum(a) #全部元素求和np.sum(a, axis=0) #按照第1个维度汇总求和np.sum(a, axis=2) #按照第3个维度汇总求和np.mean(a, axis=2) #按照第3个维度汇总求均值乘法
np.dot是点乘(矩阵乘法)
|A B| . |E F| = |A*E+B*G A*F+B*H|
|C D| |G H| |C*E+D*G C*F+D*H|
np.multiply是逐元素乘法
|A B| ⊙ |E F| = |A*E B*F|
|C D| |G H| |C*G D*H|a = np.array([[1,2], [3,4]])
b = np.array([[1,2], [2,3]])
a
bnp.dot(a,b)np.multiply(a,b)Pandas数据结构Series
构造和初始化Series
import pandas as pd
pd.__version__ #查看版本,不同版本的pandas功能有一些差异
Series是一个一维的数据结构,下面是一些初始化Series的方法。
s = pd.Series([7, 'Beijing', 2.17, -12344, 'Happy Birthday!'])
ss = pd.Series([7, 'Beijing', 2.17, -12344, 'Happy Birthday!'])
spandas会默认用0到n-1来作为Series的index,但是我们也可以自己指定index。index我们可以把它理解为dict里面的key。
s = pd.Series([7, 'Beijing', 2.17, -12344, 'Happy Birthday!'],
index=['A', 'B', 'C', 'D', 'E'])
s
还可以用dictionary来构造一个Series,因为Series本来就是key value pairs。
cities = {'Beijing': 55000, 'Shanghai': 60000, 'Shenzhen': 50000, 'Hangzhou': 20000, 'Guangzhou': 25000, 'Suzhou': N