强化学习系列 1:强化学习入门简介
<1>、强化学习入门简介
强化学习是一种机器学习方法,对比监督学习,无监督学习,强化学习最开始并没有标好的标签,而是通过一次次在环境中尝试,获取数据和标签,然后通过学习自己总结出来的经验;

一些比较有名的算法, 比如有通过行为的价值来选取特定行为的方法, 包括使用表格学习的 Q-learning, sarsa, 使用神经网络学习的 deep Q network, Sarsa,还有直接输出行为的 policy gradients, 又或者了解所处的环境, 想象出一个虚拟的环境并从虚拟的环境中学习的Model based RL 等等.我们可以将所有强化学习的方法分为理不理解所处环境,如果我们不尝试去理解环境, 环境给了我们什么就是什么. 我们就把这种方法叫做 model-free, 这里的 model 就是用模型来表示环境, 那理解了环境也就是学会了用一个模型来代表环境, 所以这种就是 model-based 方法;
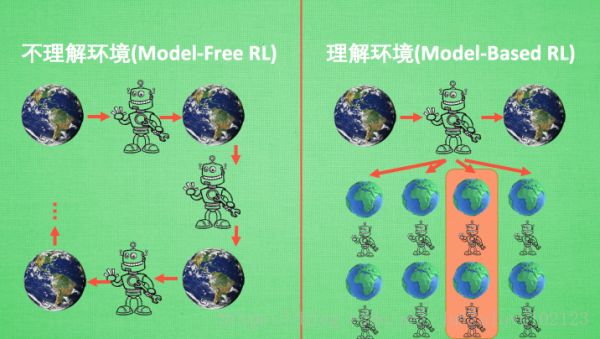
Model-free RL的方法有很多, 像 Qlearning, Sarsa, Policy Gradients 都是从环境中得到反馈然后从中学习.
Model-based RL 只是多了一道程序, 为真实世界建模, 也可以说他们都是 model-free 的强化学习, 只是 model-based 多出了一个虚拟环境, 我们不仅可以像 model-free 那样在现实中而且还能在虚拟中学习, 学习的方式也都是 model-free 中那些方式, 最终 model-based 还有一个杀手锏就是想象力.
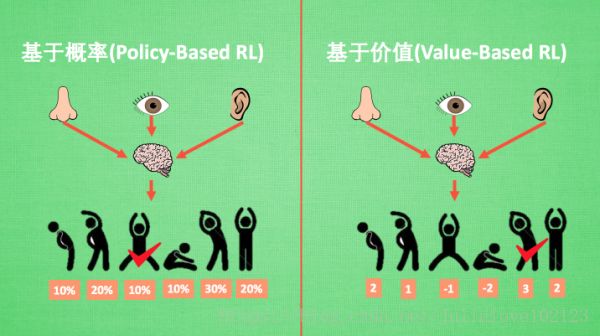
基于概率是强化学习中最直接的一种, 他能通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同. 比如:policy gradients,
基于价值的方法输出则是所有动作的价值, 我们会根据最高价值来选着动作, 相比基于概率的方法, 基于价值的决策部分更为铁定, 毫不留情, 就选价值最高的, 而基于概率的, 即使某个动作的概率最高, 但是还是不一定会选到他.比如:q learning, sarsa 等. 对于选取连续的动作, 基于价值的方法是无能为力的.
强化学习用另外一种方式分类, 回合更新和单步更新, 想象强化学习就是在玩游戏, 游戏回合有开始和结束.
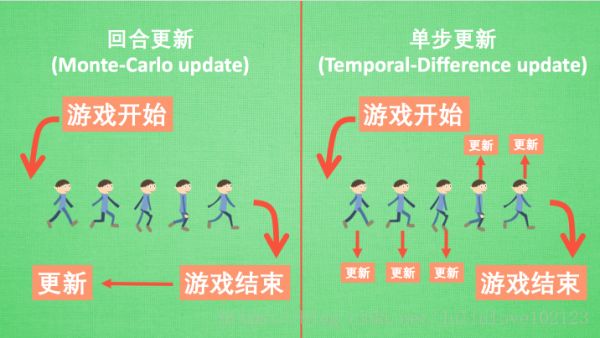
回合更新指的是游戏开始后, 我们要等待游戏结束, 然后再总结这一回合中的所有转折点, 再更新我们的行为准则. Monte-carlo learning 和基础版的 policy gradients 等 都是回合更新制。
单步更新则是在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样我们就能边玩边学习了.Qlearning, Sarsa, 升级版的 policy gradients 等都是单步更新制. 单步更新更有效率, 所以现在大多方法都是基于单步更新.

在线学习, 就是指我必须本人在场, 并且一定是本人边玩边学习,最典型的在线学习就是 sarsa 了, 还有一种优化 sarsa 的算法,叫做 sarsa lambda;
离线学习,你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则, 离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习. 或者我也不必要边玩边学习, 我可以白天先存储下来玩耍时的记忆, 然后晚上通过离线学习来学习白天的记忆. 最典型的离线学习就是 Q learning, 后来人也根据离线学习的属性, 开发了更强大的算法, 比如让计算机学会玩电动的 Deep-Q-Network.