机器学习.周志华《8 集成学习》
个体与集成
集成学习的概念:通过构建并结合多个学习期来完成学习任务,通过投票(voting)产生;
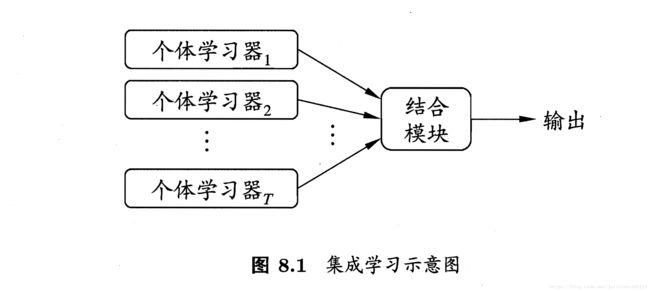
- 同质(homogeneous):多个“基学习器(base learner)”集成的学习器;(个体分类器算法类型相同)
- 异质(heterogenous):由多个不同类型算法的组件学习器(component learner)集成的学习器;(个体分类器算法类型不同)
要点:
- 个体学习器的“准确性”和“多样性”很重要,且相互冲突;
- 随着集成中个体分类器数目的增大,集成的错误率指数级下降,最终趋于0;
核心:产生和结合“好而不同”的个体学习器;
分类:
- 串行生成的序列化方法(个体学习器间存在强依赖关系);Eg:Boosting
- 并行化方法(个体学习器间不存在强依赖关系);Eg:Bagging和随机森林
Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似: 先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的样本在后面受到更多关注,然后基于调整后的样本分布来训练下一个基学习器。重复执行直到基学习器数目达到事项制定的值T,最终将T个基学习器进行加权结合。
Adaboost算法:

Boosting代表Adaboost的推导方式:
Eg:“加性模型(additive model)”:基学习器的线性组合:
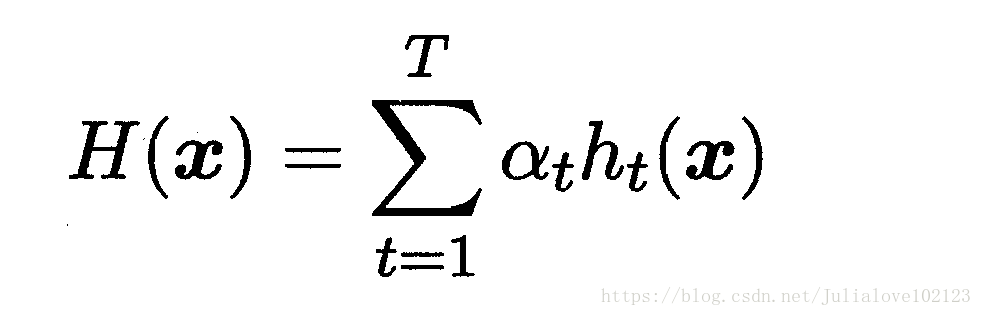
Step 1 :基分类器H(x)
最小化指数损失函数:
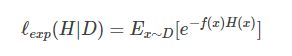
对H(x)求偏导:
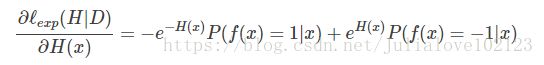
解得:
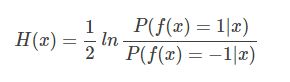
则:

- sign(H(x))达到了贝叶斯最优错误率【若指数函数最小,则分类错误率也最小】
- 指数损失函数是0/1损失函数的一致性替代损失函数;
Step 2 :基分类器的权重αt
最小化指数损失函数:
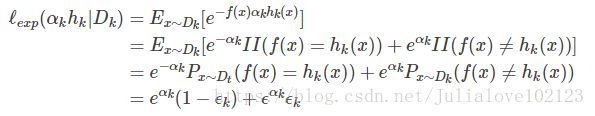
求导:

求解得:

Step 3 :调整错误
理想的ht将在Dt下最小化误差,纠正Ht-1的错误,弱分类器基于Dt来训练,考虑Dt和Dt-1的关系,则有:
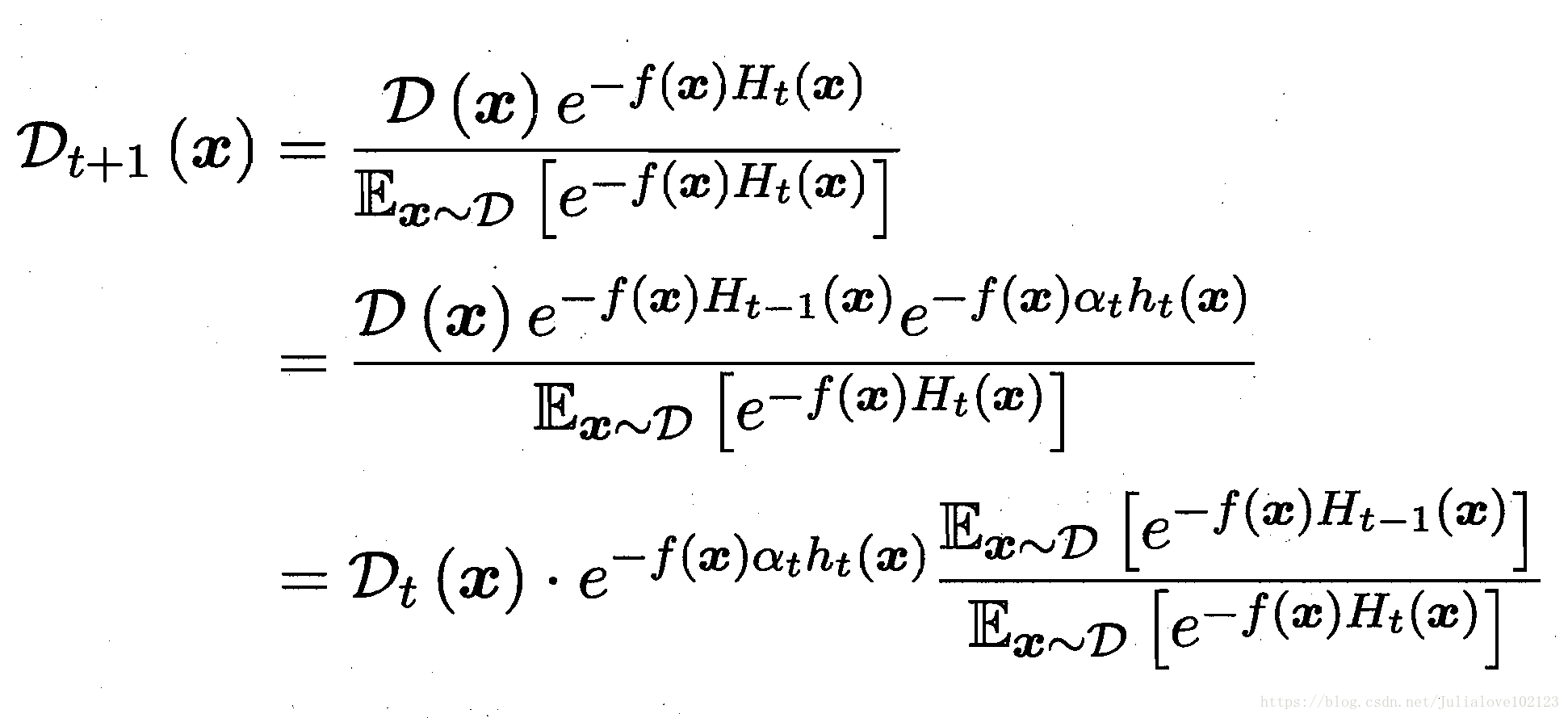
Boosting要求基学习器能对特定数据分布进行学习;
- 方法一:重赋权重re-weighting
- 方法二:重采样法re-sampling(对无法接受带权样本进行训练的基分类器)--可获得“重启动”防止早停止;
偏差方差角度:
- Boosting关注降低偏差;
- Boosting算法不容易overfitting。
Bagging与随机森林
希望个体学习器独立,不容易实现,可以设法使基学习器尽可能有较大差异,所以使用相互有交叠的采样子集;
bagging
并行式集成学习的最著名代表;
基于自助采样法(bootstrap sampling):
优点:63.2%用于训练,剩余36.8%当做验证集对泛化性能做“包外估计”;

bagging对分类任务采用简单投票法;
bagging对回归任务采用简单平均法;
对比:
- Adaboosting只适用于二分类任务;
- Bagging适用于多分类、回归任务;
偏差-方差角度:Bagging关注降低方差;
随机森林:
随机森林(Random Forest)是Bagging的一个扩展变体。在决策树训练过程中引入了随机属性选择。
在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k属性的子集,然后从这个子集中选择一个最优属性用于划分,这里k控制了随机性的引入程度:若k=d则与传统决策树一样,若k=1则为随机选择,推荐k=log2(d);
RF起始性能相对较差,训练效率优于Bagging,随着基学习器数目的增加,收敛到更低的泛化误差;
对比:
- Bagging:使用“确定型”决策树,选择划分属性时对结点的所有属性考察;
- RF:使用“随机型”决策树,只考察一个属性子集;
结合策略
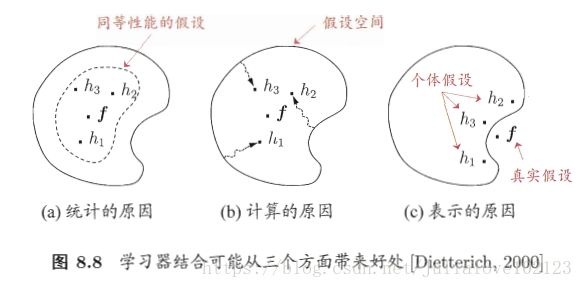
学习器结合三个好处:
1、统计方面:可能有多个假设达到同等性能,导致泛化性能不佳;结合可解决;
2、计算方面:陷入局部最小;结合可解决;
3、表示方面:学习任务的真是假设不在当前学习所考虑的范围之内;结合可解决;
1.平均法
数值型输出:平均法;
- 简单平均法:
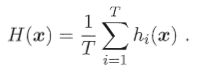
注:特殊的加权平均法,wi=1/T,简单平均法在个体学习器性能相近时使用
- 加权平均法:

注:权重wi,是从训练数据中得到(加权平均法在个体学习器性能相差较大时使用)
2.投票法
分类任务,学习器hi将从类别标记集合{c1,c2,...,cN}中预测出一个标记:投票法;
- 绝大多数投票法:
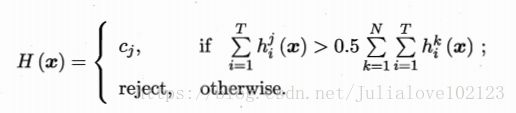
注:某标记得票过半,预测为该标记,否则拒绝预测;(若不允许拒绝预测,则退化为相对多数投票)
- 相对多数投票法:
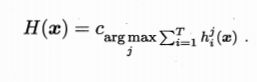
注:预测为得票最多的标记,若同时多个最多,则从中随机选取;
- 加权投票法:
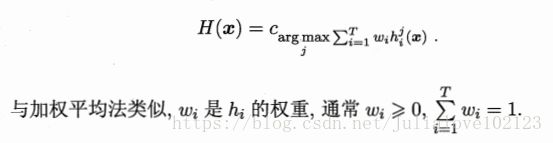
个体学习器的输出类型:
- -类标记:

- -类概率:

注:
1、不同类型的hi在类别标记cj上的输出不能混用;
2、一些能预测出类别标记的同时产生分类置信度的学习器,可将分类置信度转换为类概率使用;
3、分类置信度必须要经过规范化才能使用;
4、基于类概率进行结合往往比直接基于类标记结合性能更好;
5、基学习器类型不同,不能直接比较类概率值,此时可将类概率值转化为类标记输出;
3.学习法
训练数据很多:学习法;
典型代表1:Stacking:
1、从初始数据集训练处初级学习器;
2、生成一个新数据集来训练次级学习器(元学习器);
3、新数据集中,初级学习器的输出作为样例输入,初始样本的标记仍当做样例标记;

次级学习器的输入属性表示和次级学习算法对Stacking集成的泛化性能影响很大;
MLR:初级学习器的输出类概率作为次级学习器的输入属性,将多响应线性回归(MLR)作为次级学习算法;
典型代表2:BMA:
贝叶斯模型平均基于后验概率来为不同模型赋予权重;
注:
Stacking通常优于BMA,鲁棒性好,BMA对模型近似误差非常敏感;
多样性
1.误差-分歧分解
![]()
![]()
![]()
结论:个体学习器准确性越高、多样性越大、则集成性越好;
2.多样性度量
目的:度量集成中个体分类器的多样性(多样化程度)【典型做法:分析相似性/不相似性】
pairwise(成对)多样性度量:

- 不合度量:
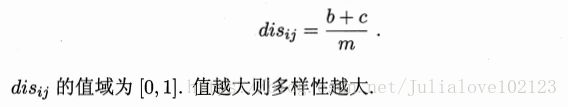
- 相关系数:

- Q-统计量:

- k-统计量:

Eg:k-误差图:
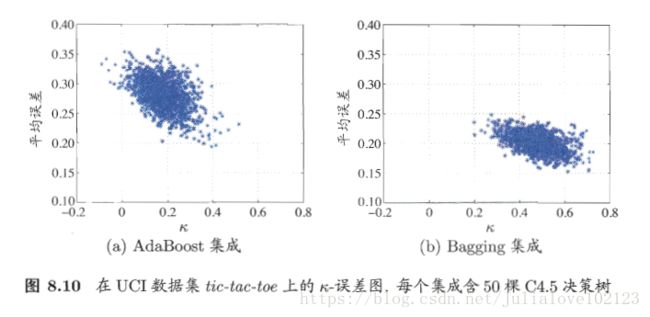
点:表示每一对分类器;
数据点云位置越高:个体分类器准确性月底;
数据点云位置越靠右:个体分类器的多样性越小;
3.多样性增强
增强多样性方法:扰动----对数据样本、输入属性、输出表示、算法参数进行扰动;
- 数据样本扰动:
数据扰动:通常基于采样法;
Eg:
Bagging:自主采样;
Adaboost:序列采样;
适用于“不稳定基学习器”:决策树、神经网络等;
- 输入属性扰动:
输入属性:训练样本通常由一组属性描述;
Eg:
随机子空间算法;
适用于“稳定基学习器”:线性学习器、朴素贝叶斯、k近邻学习器等;

- 输出表示扰动:
输出表示:对输出表示操纵;
Eg:翻转法随机改变一些训练样本的标记、“输出调制法”将分类输出转化为回归输出狗构建个体学习器等;
- 算法参数扰动:
对基学习算法的参数进行设置;
Eg:神经网络的隐藏层神经元数、初始连接权值等
-----------------------------------------------------------------------------------------------------------*-*----
更多详细内容请关注公众号:目标检测和深度学习

---------------------------------------------------------------------------------------------------------------…^-^……---------