Tensorflow学习用slim模块进行猫狗分类
最近实践仿照着做了一下slim模块的使用,以Inception_v3模型对kaggle数据集中的dogsVScats数据集进行分类。由于只需要分两类,所以需要对以Inception_v3模型的输出层进行调整,因为原模型是分1000类的。实验过程中共采用猫狗的图片,最后只需分猫狗两类。
1.准备数据集
kaggle数据集:https://www.kaggle.com/salader/dogsvscats
我百度云已经下载好的:链接:https://pan.baidu.com/s/1rs8jm2bMHyXbgsjKqoQPyw 提取码:2wep
kaggle
├─test1
└─train
从train的25000张图片里面选择所用到的猫狗图片。
主要学习的地方为:
1.理解和掌握卷积神经网络中卷积层、卷积步长、卷积核、池化层、池化核、微调(Fine-tune)等概念。
2.对已经有的ImageNet数据集上训练好的模型进行微调以实现猫狗分类任务。
Inception V3网络:
Inception V3将n*n卷积层分解成1*n卷积层和n*1卷积层,这样既可以加速计算(多余的计算能力可以用来加深网络),同时又可以将一个卷积层拆成两个卷积层,从而加深网络,增加了网络的非线性,进一步提升了模型的性能。
2.下载slim模块:
在GitHub上下载好slim模块:
https://github.com/tensorflow/models/tree/master/research/slim
1. datasets/:定义一些训练时用的数据集,预先定义了4个数据集:MNIST、CIFAR-10、Flowers、ImageNet,实验中训练自己的数据dogsVScats,则可以在datasets文件夹中定义。
2. nets/:定义了一些常用的网络结构如AlexNet、VGG16、Inception系列等。
3. preprocessing/:定义了一些图片预处理和数据增强方法。
4. train_image_classifer.py:训练模型的入口代码。
5. eval_image_claasifer.py:验证模型的入口代码。
然后在该模块下进行操作:
2.1添加数据集:
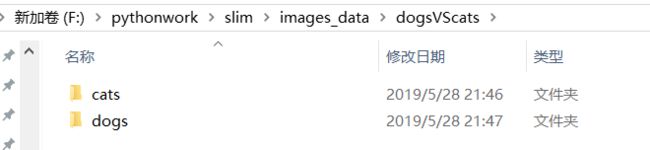
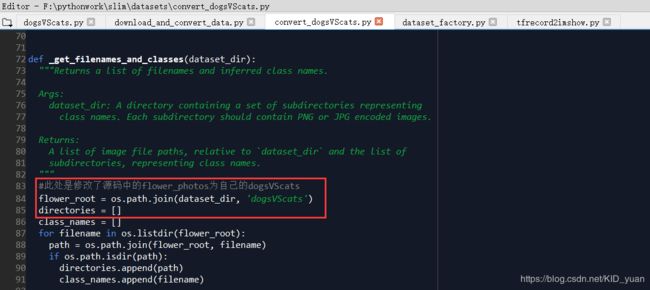
slim文件下,新建一个image_data文价夹下添加:./slim/images_data/dogsVScats/文件
该文件下包含cats和dogs两个图像数据文件即:
dogsVScats
├─cats
└─dogs
选择自己想用到的数据集的数量,因为只需要分猫狗2类,并不需要将25000张照片全部都进行训练都能得到很好的分类结果。我这里选择了2500张进行试验(猫狗各自1250张图片)。
2.2制作自己dogsVScats数据集的TF-Record文件转换程序。
具体操作流程如下:
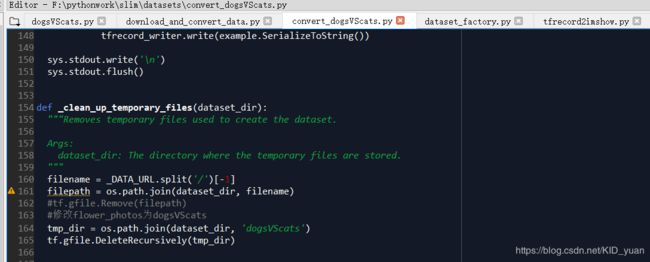
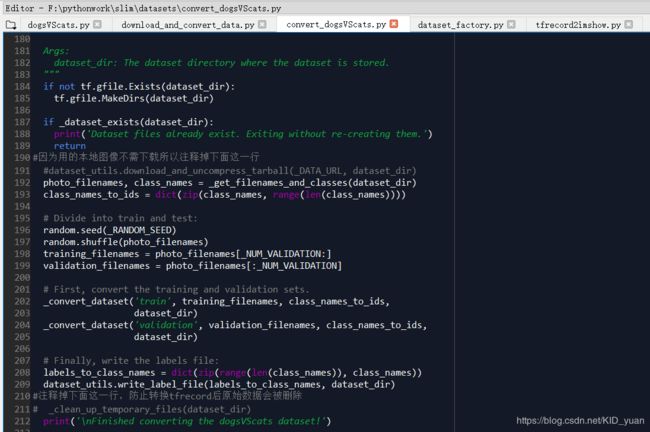
1.修改\slim\datasets文件夹下的
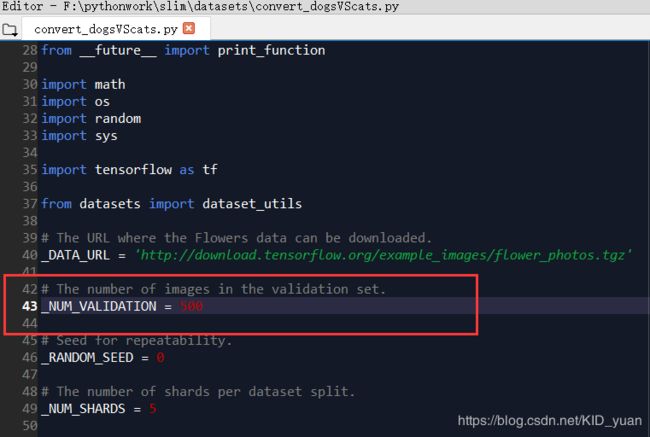
复制download_and_convert_flowers.py并将文件名改为convert_dogsVScats.py。修改后的源码:
2.修改download_and_convert_data.py文件
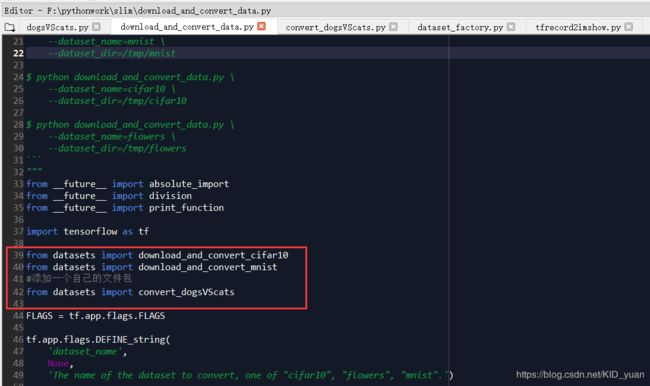
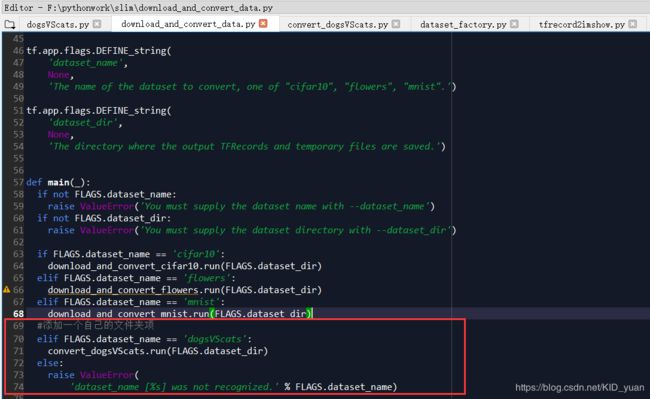
数据整理好以后,模仿slim里面的数据转换代码程序形式,首先找到slim文件下download_and_convert_data.py。仿照并为自己的dogsVScats数据集添加 TF-Record文件转换程序,修改的源码具体位置如下:
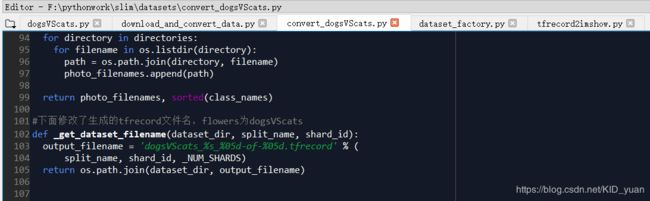
3.将slim/datasets/flowers.py复制并重命名为dogsVScats.py ,将
_FILE_PATTERN = 'flowers_%s_*.tfrecord'
改为
_FILE_PATTERN = 'dogsVScats_%s_*.tfrecord'
将
SPLITS_TO_SIZES = {'train': 3320, 'validation': 350}
改为
SPLITS_TO_SIZES = {'train': 2000, 'validation': 500}
其中,train代表训练的图片张数,validation代表验证使用的图片张数。这里我选择的训练集图片数目为2000张,验证测试集图片数目为500张。
修改slim/datasets/dataset_factory.py文件,由get_dataset函数读取数据的格式可知需要获取数据集名称,因此新增一个dogsVScats:dogsVScats对自己的数据集设置字典映射:
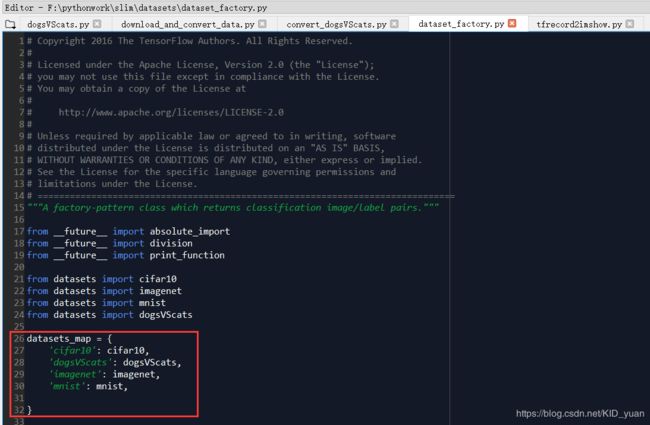
选择好训练集与验证集图片数目后CMD运行命令:
python download_and_convert_data.py ^ --dataset_name=dogsVScats ^ --dataset_dir=images_data
文件转换后结构:
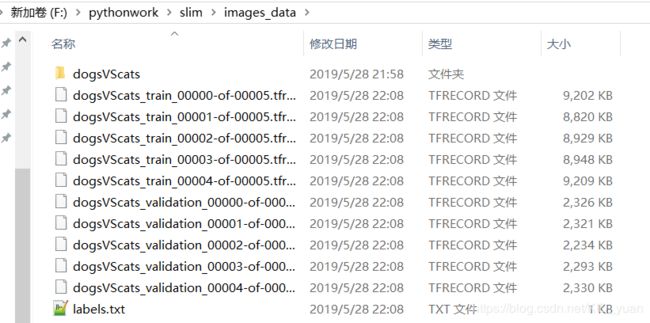
检验转换的TFRECORD文件是否正确,可以设置一个读取TFRECORD的程序用来显示TFRECORD文件里面存储的图片数据。
# -*- coding: utf-8 -*-
"""
Created on Tue May 28 21:19:07 2019
@author: Ziyuan
"""
from datasets import dogsVScats
import tensorflow as tf
import pylab
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
slim = tf.contrib.slim
#tfrecord文件的数据集目录
DATA_DIR = 'images_data/'
#指定获取“validation”下的数据
dataset = dogsVScats.get_split('validation', DATA_DIR)
# Creates a TF-Slim DataProvider which reads the dataset in the background
# during both training and testing.
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])
#在session下读取数据,并用pylab显示图片
with tf.Session() as sess:
#初始化变量
sess.run(tf.global_variables_initializer())
#启动队列
tf.train.start_queue_runners()
image_batch,label_batch = sess.run([image, label])
#显示图片
pylab.imshow(image_batch)
pylab.show()
效果如下:

3.Fine-tuning设置参数并开始训练
训练之前,下载inception_v3模型参数:
下载地址:http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
并自己新建一个文件路径checkpoint/下将其放进:
即slim/checkpoint/inception_v3.ckpt
下面开始制定参数:(具体参数含义可参考slim模块的README.md官方文档说明)
--checkpoint_path:指定checkpoint文件的路径。
--checkpoint_exclude_scopes:当pre-trained checkpoint对应的网络最后一层分类的类别数量和现在数据集的类别数量不匹配时使用,可以指定checkpoint restore时哪些层的参数不恢复。
--trainable_scopes:如果只希望某些层参与训练,其他层的参数固定时,就使用这个flag,在这个flag中指定需要训练的参数。
训练时参数如下:
python train_image_classifier.py^
--train_dir=saver/inv3_checkpoint_dogsVScats^
--dataset_name=dogsVScats^
--dataset_split_name=train^
--dataset_dir=images_data^
--model_name=inception_v3^
--checkpoint_path=checkpoint/inception_v3.ckpt^
--max_number_of_steps=4000^
--batch_size=5^
--learning_rate=0.0001^
--learning_rate_decay_type=fixed^
--save_interval_secs=60^
--save_summaries_sec=60^
--log_every_n_step=10^
--optimizer=rmsprop^
--weight_decy=0.00004^
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits
测试验证集时参数设置如下:
python eval_image_classifier.py^
--checkpoint_path=saver/inv3_checkpoint_dogsVScats^
--eval_dir=saver/inv3_dogsVScats^
--dataset_name=dogsVScats^
--dataset_split_name=validation^
--dataset_dir=images_data^
--model_name=inception_v3^
--batch_size=2
4.程序执行
为了好修改与执行,我将上面两段参数写在了两个Windows批处理文件中:train.bat 和 test.bat
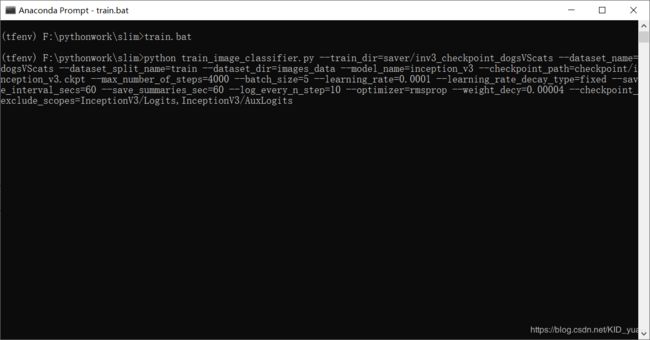
然后CMD运行
train.bat即开始训练:
报错.......遇到问题... Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED;
我重新启动了一下电脑试了一下=_=!....果然我重启一次电脑之后又好了,貌似是cudnn之前被别的程序占用了。
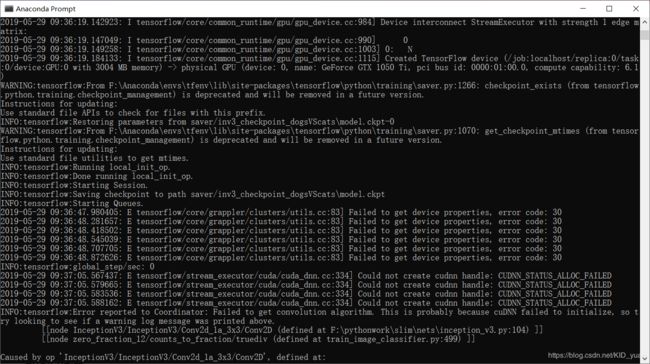
没有别的意外的话就开始训练了:
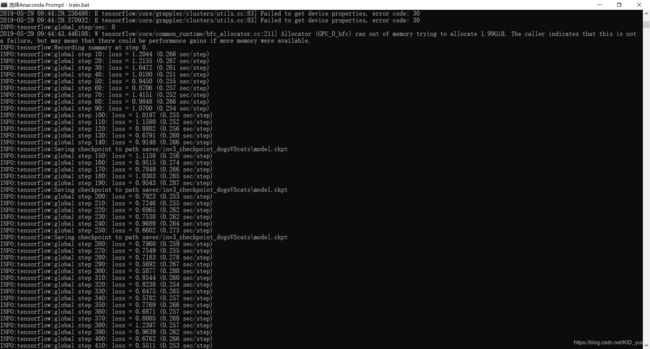
我这里设置训练了4000步,学习率可能出了点问题,到了最后损失函数突然开始震荡了。。。
我又重新调整一下训练5000步,然后缩小一下学习率和或者可以设置其参数exponential指数衰减形式再进行训练。

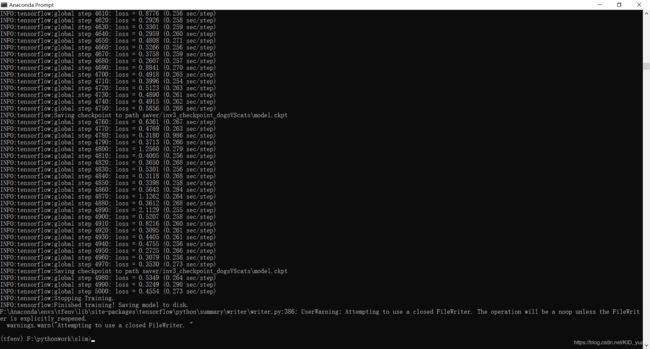
测试时:
同样CMD执行:test.bat
![]()
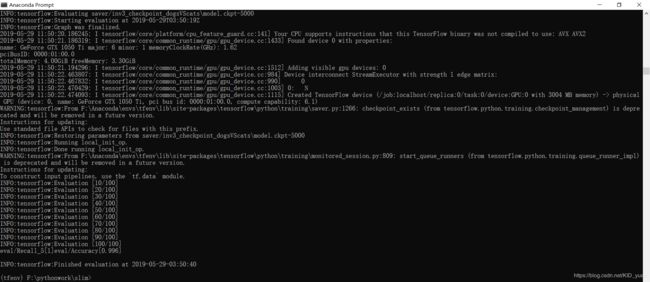
最后验证集准确率:召回率为100%,准确率为99.6%,效果还算可以。
参考博客:
https://blog.csdn.net/rookie_wei/article/details/80796009