java编程思想-第18章-java I/O系统
第18章:java I/O 系统
18.1 File
表面上看File指的是一个文件,实际上FIle既可以表示一个文件也可以表示很多文件的集合,用目录来解释File比较合适。
18.1.1 目录列表器
File path = new File(“,”);
String list = path.list();
or
String list = path.list(new FilenameFilter());
用Array.sort(list, String.CASE_INSENSITIVE_ORDER)可以对其进行排序;
上面提到了new FilenameFilter();过滤器。
public interface FilenameFilter {
boolean accept(File dir, String name);
}
是一个接口。
下面是一个接口实现的示例。
private Pattern pattern = Pattern.compile(regex); //这是一个regex(正则表达式)的解析,在String那一章会讲到。
boolean accpet(File dir, String name) {
return pattern.matcher(name).matches();
}
18.1.2 目录的实用工具
File[] file.listFiles();
18.1.3 目录的检查及创建
f.getAbsolutePath();
f.canRead();
f.canWrite();
f.getName();
f.getParent();
f.getPath();
f.length();
f.lastModified();
f.isFile();
f.isDirectory();
f.renameTo(File file); //移动到另一个FIle目录下;
f.exists();
f.delete();
f.mkdirs();
f.mkdir();
f.createNewFile();
18.2 输入输出
编程语言的I/O类库中尝试用流这个概念,他代表任何 有能力产生数据的数据源对象 与 有能力接受数据的接收端对象。“流”屏蔽了实际的I/O设备中处理数据的细节。
18.2.1 InputStream类型
InputStream的来源有
1)字节数组:ByteArrayInputStream
2)String对象:StringBufferInputStream
3)文件:FileInputStream
4)管道:PipeInputStream
5)其他输入流(合并):SequenceInputStream
6)其他输入流(过滤,抽象类):FilterInputStream
18.2.2 OutputStream类型
1)字节数组:ByteArrayOutputStream
2)文件:FileOutputStream
3)管道:PipeOutputStream
4)其他输入流(过滤,抽象类):FilterOutputStream
18.3 添加属性和有用的接口
18.3.1 FilterInputStream
1)基本类型数据输入过滤器:DataInputStream
2)缓冲器:BufferedInputStream
18.3.2 FilterOutputStream
1)基本类型数据输出过滤器:DataOutputStream
2)缓冲器:BufferedOutputStream
3)格式化输出:PrintStream
DataOutputStream处理数据的存储,PrintStream处理数据的显示。
18.4 Reader 和 Writer
提供兼容Unicode与面向字符的I/O功能。
18.5 自我独立的类:RandomAccessFile
RandomAccessFile不是InputStream或者OutputStream继承层次结构的一部分,除了实现了DataInput与DataOutput接口之外,他和这两个继承层次结构没有任何关系。是一个完全独立的类。
只有RandomAccessFile支持搜寻方法,并且只适用于文件。
在JDK1.4中,RandomAccessFile的大多数功能由nio存储映射文件所取代,后面会介绍。
18.6 I/O流的典型使用方式
18.6.1 缓冲输入文件
Reader:
readLine并不能读入换行符
BufferedReader in = new BufferedReader(new FileReader(“a.txt”));
StringBuilder sb = new StringBuilder();
String str = null;
while((str = in.readLine()) != null) {
sb.append(str + “\n”);
}
System.out.println(sb.toString());
in.close();
InputStream:
BufferedInputStream in = new BufferedInputStream(new FileInputStream("a.txt"));
int c;
while((c = in.read()) != -1) {
System.out.print((char)c);
}
in.close();
18.6.2 从内存中输入
StringReader:
StringReader sin = new StringReader(new String(“asdasdas”));
int c;
while((c = sin.read()) != -1) {
System.out.print((char)c);
}
sin.close();
StringBufferInputStream:已弃用。
18.6.3 格式化的内存输入:
DataInputStream,是一个面向字节的I/O类,因此我们必须使用InputStream而不是Reader。
try {
DataInputStream in = new DataInputStream(new ByteArrayInputStream(“asdasd”.getBytes()));
while (true) {
System.out.print((char) in.readByte());
}
} catch (EOFException e) {
System.out.println(“EOF“);
}
in.readByte()一个字节一个字节地读取字符,因为任何一个字节都是一个合法的结果,所以只能通过捕捉运行时异常来结束读取。
同时我们可以使用available查看还有多少可供读取的字符。
如下:
DataInputStream in = new DataInputStream(new ByteArrayInputStream(“asdasd”.getBytes()));
while (in.available() != 0) {
System.out.print((char) in.readByte());
}
注意:available()会随着读取媒介的不同而有所不同,字面意思就是“在没有阻塞的情况下所能读取的字节数”。对于文件,意味着整个文件,但对于不同类型的流,可能就不是这样。
我们也可以通过异常来检测输入的末尾,但是,使用异常来进行流控制,被认为是对异常的错误的使用方式。
18.6.4 基本的文件输出
PrintWriter + BufferedWriter + FileWriter
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(“b.txt”)));
out.println(“asd”);
out.println(“ss”);
out.close();
文本文件输出的快捷方式:
PrintWriter out = new PrintWriter(“c.txt”);
out.println(“asd”);
out.println(“ss”);
out.close();
18.6.5 存储和回复数据:
当我们使用DataOutputStream传输字符串并且希望能够通过DataOutputStream恢复时,唯一可靠的方法就是使用,writeUTF()与readUTF(),使用UTF-8的格式来传输。但是,这样传输的是适用于java的一种UTF-8的变体,若要使用非java的方式来进行操作的话,需要编写一些特殊的代码才能正确的读取字符串。
18.6.6 读写随机访问的文件:
RandomAccessFile :
RandomAccessFile rd = new RandomAccessFile(new File(“d.txt”), “rw”);
for(int i = 0; i < 7; i++) {
rd.writeDouble(i);
}
rd.writeUTF(“ssss”);
rd.seek(4 * 8);
rd.writeDouble(4.1);
rd.seek(0);
for(int i = 0; i < 7; i++) {
System.out.println(rd.readDouble());
}
System.out.println(rd.readUTF());
18.6.7 管道流
价值只有在我们开始理解多线程之后才会显现。
18.7 文件读写的实用工具:
18.7.1读取二进制文件:
BufferedInputStream in = new BufferedInputStream(new FileInputStream("a.txt"));
byte[] by = new byte[in.available()];
in.read(by);
for(byte b : by) {
System.out.print((char)b);
}
18.8 标准I/O
标准I/O这个术语参考的是UNIX中的“程序所使用的单一信息流”这个概念,程序所有的输入都来自标准输入,程序所有的输出也都可以发送到标准输出。
18.8.1从标准输入中读取:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String s;
while((s = in.readLine()) != null && s.length() != 0) {
System.out.println(s);
}
18.8.2 将System.out转换成PrintWriter
PrintWriter out = new PrintWriter(System.out, true);
out.println("asdsd");
PrintWriter构造器既可以接受一个Writer又可以接受一个OutputStream。这个构造器还有一个选项,就是“自动执行清空”选项,如果构造器设置此选项,则在每个Println执行之后便会自动清空。
18.8.3 标准I/O重定向
setIn(InputStream);
setOut(OutputStream);
setErr(PrintStream);
就是把这三个流对接到别的流上。
实例:
BufferedInputStream in = new BufferedInputStream(new FileInputStream(“a.txt”));
PrintStream out = new PrintStream(new FileOutputStream(“e.txt”));
System.setIn(in);
System.setOut(out);
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String string;
while((string = reader.readLine()) != null) {
System.out.println(string);
}
out.close();
效果:把a.txt中的内容复制到e.txt中。
18.9 进程控制
一些关于命令行执行程序与在进程中开启另一个进程,并捕捉新进程的in.out.err的故事。(有eclipse用命令行新手的很少了,之后需要学习一下java命令)
18.10 新I/O
JDK 1.4的java.nio.*包中引入了新的javaI/O类库,其目的在提高速度。实际上,旧的I/O包已经使用nio重新实现过,以便充分利用这种速度的提高。因此,我们不显示地使用nio编写代码,也能从中受益。
那到底是如何提高速度的呢?
速度的提高来自于所使用的结构更接近于操作系统执行的I/O的方式:通道与缓存器。通道相当于一个煤矿,缓存器相当于一个卡车,卡车从煤矿中拉出煤矿送给我们。。。书上的例子有点不太恰当。因为这是一个交互的过程,而不只是单向的;而且通道才是运输的主体,缓存器就如同他的名字一样,是来缓存东西的。可以说,缓存器就相当于高铁站,通道就相当于高铁,我们把人送到高铁站(缓存器)缓存起来,达到一定条件就可以开启高铁(通道);反之亦然,高铁(通道)把人送到高铁站(缓存器),我们再从高铁站(缓存器)把人从领走。
唯一直接与通道交互的缓冲器是ByteBuffer,一个相当基础的类。
旧I/O库中的FileInputStream,FileOutputStream,RandomAccessFile这三个被修改,用来产生FileChannel.
Reader,Writer这种字符模式的类不能用于产生通道,但是可以用java.nio.channels.Channels类提供的方法,来在通道中产生Reader,Writer。
FileChannel made by FileOutputStream:
FileChannel fc = new FileOutputStream(“a.txt”).getChannel();
fc.write(ByteBuffer.wrap(“hello world”.getBytes()));
fc.close();
FileChannel made by FileInputStream:
FileChannel fc = new FileInputStream(“a.txt”).getChannel();
ByteBuffer by = ByteBuffer.allocate(1024);
fc.read(by);
by.flip();
while(by.hasRemaining())
System.out.print((char)by.get());
FileChannel made by RandomAccessFile:
FileChannel fc = new RandomAccessFile(new File(“a.txt”), “rw”).getChannel();
fc.position(fc.size());
fc.write(ByteBuffer.wrap(“\nand change the world”.getBytes()));
fc.close();
buffer有mark,reset,rewind,flip,clear这5个控制方法。还有一个常用方法hasReminding,稍后会介绍。
通过图来讲解是最好理解,也是最快理解的方法,下图:
campacity——buffer最大容量
limit——buffer已存储大小+1的位置
position——当前所在位置
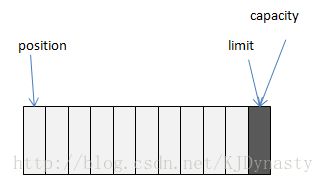
第一图是还未存储任何值的时候。
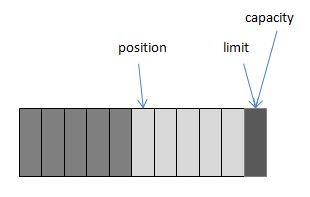
第二图是存储了5个byte后。
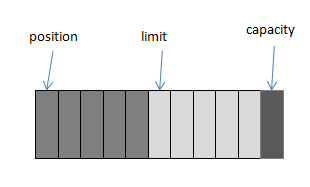
第三图是flip之后。
所以现在很容易理解flip的含义了,就是将position置0,limit置已存储大小+1的位置,准备进行接下来的读操作。
clear是将position置0,limit置为compacity。
rewind仅仅是将position置0,便于读完之后再读一遍。
mark是将当前的position记录。
reset是将mark记录的position复原。
有一个需要注意的地方时,当position的值小于mark的值时,mark会被抛弃,并重新置为0。
就是这样。
FileChannel.transferTo();
in.transferTo(position,size,To);
out.transferFrom(From,position,size);
例子如下:
FileChannel in = new FileInputStream(“a.txt”).getChannel();
FileChannel out = new FileOutputStream(“g.txt”).getChannel();
FileChannel out1 = new FileOutputStream(“h.txt”).getChannel();
in.transferTo(0, in.size(), out);
out1.transferFrom(in, 0, in.size());
18.10.1 转换数据
ByteBuffer有一个方法,asCharBuffer()返回一个charBuffer,而charBuffer有一个toString()方法,为何我们不这样直接输出呢?
例子如下:
FileChannel fc = new FileInputStream(“a.txt”).getChannel();
ByteBuffer buffer = ByteBuffer.allocate(64);
fc.read(buffer);
buffer.flip();
System.out.println(buffer.asCharBuffer());
console输出:桥汬漠睯牬搊?瑨敮?桡湧攠瑨攠睯牬
我们发现是一堆乱码。肯定是传输格式不对了。
格式不对这样解决:
buffer.rewind();
String encoding = System.getProperty(“file.encoding”);
System.out.print(Charset.forName(encoding).decode(buffer));
通过系统配置文件找到编码格式,再用系统编码格式产生一个Charset类来解码buffer。
或者我们可以直接通过将合适的编码存在文件里,这样就可以直接取出来了。
如下:
FileChannel out = new FileOutputStream(“a.txt”).getChannel();
out.write(ByteBuffer.wrap(“hello world then change the world”.getBytes(“UTF-16BE”)));
out.close();
FileChannel fc = new FileInputStream("a.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(128);
fc.read(buffer);
buffer.flip();
System.out.println(buffer.asCharBuffer());
Charset.availableCharsets():可以获得一个SortedMap,里面的键是字符集的名称,值是该字符集的Charset类。
下面的Test输出了所有的字符集及字符集的别名(aliases):
SortedMap
18.10.2 获取基本类型
一个重要的信息,新分配的buffer每个位置上都是0.
略略
18.10.3 视图缓冲器
何为视图缓冲器,就是在缓冲器上包装一个视图,便于使用各种基本类型来访问缓冲器,学过数据库的人应该都会对视图有更好的了解。
如下:
ByteBuffer buffer = ByteBuffer.allocate(8);
DoubleBuffer db = buffer.asDoubleBuffer();
db.put(0, 1.5);
System.out.println(db.get());
关于基本类型的大小:
byte 1字节
char 2字节
short 2字节
int 4字节
float 4字节
long 8字节
double 8字节
字节存放的次序:
字节存放的次序有两种 一种是:高位优先,即存储在高位的取出来放在高位,存储在低位的取出来放在低位。另一种是:低位优先,跟高位优先相反。
什么叫字节存放的次序:比如一个Double类型的值,想储存在buffer中,一个Double总共有8个字节,如:0x12345678。高位优先时buffer中是这样的:0x12345678,而低位优先时buffer中是这样的:0x78563412。这样看起来确实比较奇怪=_=。解释一下:两个16进制数是8位,8位是一个字节,存储时只是字节之间的顺序不一样,但每个字节内的内容是不变的。
有一个方法:ByteBuffer.order(ByteOrder.BIG_ENDIAN)高位优先,ByteBuffer.order(ByteOrder.SMALL_ENDIAN),话说indian跟endian真的傻傻分不清楚。
18.10.6 内存映射文件
内存映射文件允许我们创建和修改那些因为太大而不能放入内存的文件。有了内存映射文件,我们可以把整个大文件放入内存中。暂时还不知道是怎么实现的。
内存映射文件表面上看就是一个缓存器映射一个管道,这个管道channel就是你打开文件的管道。
实例:
MappedByteBuffer mbb = new RandomAccessFile(new File(“a.txt”), “rw”).getChannel().map(FileChannel.MapMode.READ_WRITE, 0, 10);
CharBuffer cb = mbb.asCharBuffer();
for(int i = 0; i < 5; i++) {
System.out.print(cb.get());
}
实例中的MappedByteBuffer很小,只是为了示例大致用法。
操作MappedByteBuffer大致上就跟操作ByteBuffer一样,而操作ByteBuffer我们已经很熟悉了。
获取MappedByteBuffer:FileChannel..map(FileChannel.MapMode.READ_WRITE, 0, 10);
第一个函数是模式,有三种模式FileChannel.MapMode.PRIVATE,FileChannel.MapMode.READ_ONLY,FileChannel.MapMode.READ_WRIT。常用的也就只读与读写两种。FileChannel.MapMode.PRIVATE并没有详细说明。第二个参数于第三个参数意思是起始位置与大小。
性能:书中的意思就是内存映射在进行大量数据的操作时,速度要远远快于通过管道进行数据传输的nio。
18.10.7 文件加锁
JDK1.4引入了文件加锁机制,允许我们同步的访问 某个作为共享的 文件。注意是给文件加锁,加锁的方式大概分为两种,一种是给整个文件加锁,另一种是给指定大小的文件的一部分加锁。
第一种
我先是这样写:
FileChannel fc = new FileInputStream(“a.txt”).getChannel();
FileLock fl = fc.tryLock();
运行发现有错误:Exception in thread “main” java.nio.channels.NonWritableChannelException
也就是说只有可写的channel才可以上锁,想想也是,读不需要同步,因为一个线程的读对另一个线程读写都不会造成影响。相反,对文件写操作的时候,一个线程是会对另一个线程造成很大的影响的。
所以应该这样写:
FileChannel fc = new FileOutputStream(“a.txt”).getChannel();
FileLock fl = fc.tryLock();
if(fl != null) {
fl.release();
}
上面的上锁使用的是tryLock,这种上锁是非阻塞式的。还有一种上锁方法是阻塞式的,就是lock。啥是阻塞非阻塞?就像他们的名字一样,trylock就是我试着锁一下,能锁上就锁上,锁不上就不锁了,就是非阻塞。lock是我锁不上就一直锁,直到我锁上为止。
第二种
部分文件上锁:
tryLock(position, size, isshared);
lock(position, size, isshared);
18.11 压缩
java I/O库中支持读写压缩格式的数据流,这些类与nio管道一样,都是使用字节类的流进行包装的。
18.11.1 用GZIP进行简单压缩
就跟直接对文件操作一样,只不过多了一层包装。四层包装看起来真的很蛋疼,初学者一看会被吓出翔。不过熟悉了之后便会觉得一层层的逻辑非常清楚明了。
PrintWriter writer = new PrintWriter(new OutputStreamWriter(new GZIPOutputStream(new FileOutputStream("test.gz"))));
writer.println(new String("hello world then change the world").toCharArray());
writer.println("wtf".toCharArray());
writer.close();
BufferedReader in = new BufferedReader(new InputStreamReader(new GZIPInputStream(new FileInputStream("test.gz"))));
String string;
while((string = in.readLine()) != null) {
System.out.println(string);
}
in.close();
18.11.2 用zip进行多文件保存。
这个功能真的很高端。
ZipOutputStream zip = new ZipOutputStream(new CheckedOutputStream(new FileOutputStream(“sss.zip”), new Adler32()));
BufferedOutputStream out = new BufferedOutputStream(zip);
zip.setComment(“A new ZIP”);
zip.putNextEntry(new ZipEntry(“first file”));
out.write(“first file”.getBytes());
zip.putNextEntry(new ZipEntry(“second file”));
out.write(“second file”.getBytes());
out.close();
ZipInputStream zipi = new ZipInputStream(new CheckedInputStream(new FileInputStream("sss.zip"), new Adler32()));
BufferedInputStream in = new BufferedInputStream(zipi);
System.out.println(zipi.getNextEntry());
int b;
while((b = in.read()) != -1) {
System.out.print((char)b);
}
System.out.println(zipi.getNextEntry());
while((b = in.read()) != -1) {
System.out.print((char)b);
}
in.close();
18.12 对象序列化
啥是对象序列化?
当程序运行时,有关对象的信息就存储在了内存当中,(具体怎么储存的请参照java虚拟机)但是当程序终止时,有关信息将不再继续存在。我们需要一种储存对象信息的方法,使我们的程序关闭之后他还继续存在,当我们再次打开程序时,可以轻易的还原当时的状态。这就是对象序列化的目的。
java的对象序列化将那些实现了Serializable接口的对象转换成一个字节序列,并且能够在以后将这个字节序列完全恢复为原来的对象,甚至可以通过网络传播。
利用这种方法,java实现了“轻量级持久性”,为啥是轻量级,因为在java中我们还不能直接通过一个类似public这样的关键字直接使一个对象序列化,还不能让系统自动维护其他细节问题。我们得使用一个严格的机制来进行相应的序列化与序列化还原操作。
一个简单的例子:
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(buffer);
Worm worm = new Worm(5);
out.writeObject(worm);
out.flush();
ByteArrayInputStream inBuffer = new ByteArrayInputStream(buffer.toByteArray());
ObjectInputStream in = new ObjectInputStream(inBuffer);
try {
System.out.println((Worm)in.readObject());
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
in.close();
Worm是一个内部类:定义如下
static class Worm implements Serializable {
private int id;
private Worm next;
Worm(int size) {
id = size;
System.out.println(“Constructor:” + id);
if(size != 0)
next = new Worm(size - 1);
}
@Override
public String toString() {
// TODO Auto-generated method stub
if(next != null)
return “<” + id + “:>” + next;
else return “<” + id + “:>”;
}
}
console输出:
Constructor:5
Constructor:4
Constructor:3
Constructor:2
Constructor:1
Constructor:0
<5:><4:><3:><2:><1:><0:>
这里我们会发现虫子每一节的Constructor只被调用了一次,现在看着没什么,当你看到后面Externalizable的实例后你会发现明显的区别。
18.12.1 寻找类
对象的序列化可以在一个程序内实现,也可以跨过网络来实现,或者你把存储着已序列化对象的文件拷贝到另一台主机上也是可以使用的。当我们在一个程序内实现序列化的读写时,程序始终能找到一个相同的类,就比如上例中的Worm。但当我们跨过网络,在另一台主机上实现序列化对象的读写时,问题就产生了,如果主机上找不到这个对象的class文件时,就会抛出错误,所以使用序列化对象时,一定要保证jvm能找到相应的class文件。
18.12.2 序列化的控制
一个Externalizable实现的类BigWorm:
static class BigWorm implements Externalizable {
private int id;
private BigWorm next;
public BigWorm(int size) {
// TODO Auto-generated constructor stub
id = size;
System.out.println("Constructor:" + id);
if(size != 0)
next = new BigWorm(size - 1);
}
@Override
public String toString() {
// TODO Auto-generated method stub
if(next != null)
return "<" + id + ":>" + next;
else return "<" + id + ":>";
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
// TODO Auto-generated method stub
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
// TODO Auto-generated method stub
}
}
跟Worm的区别在于多了两个继承接口的方法。其他完全一样。
运行下面的代码,也跟运行Worm的代码一样:
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(buffer);
BigWorm worm = new BigWorm(5);
out.writeObject(worm);
out.flush();
System.out.println(worm);
ByteArrayInputStream inBuffer = new ByteArrayInputStream(buffer.toByteArray());
ObjectInputStream in = new ObjectInputStream(inBuffer);
try {
System.out.println((BigWorm)in.readObject());
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
in.close();
发现报错:java.io.InvalidClassException: com.xxx.test.Test$BigWorm; no valid constructor
没有合法的构造器。
书上的例子证明了继承这个接口需要一个public修饰的默认构造器。还必须得是public。
添加了一个public修饰的默认构造器后,程序能运行,但结果不正确:
发送之前是这样的:<5:><4:><3:><2:><1:><0:>
收到之后变成了这样:<0:>
之前的数据并没有保存过来,我们需要在继承的这两个接口方法中对数据进行恢复并且在默认构造器写上一句输出:
static class BigWorm implements Externalizable {
private int id;
private BigWorm next;
public BigWorm() {
// TODO Auto-generated constructor stub
System.out.println("Constructor:" + id);
}
public BigWorm(int size) {
// TODO Auto-generated constructor stub
id = size;
System.out.println("Constructor:" + id);
if(size != 0)
next = new BigWorm(size - 1);
}
@Override
public String toString() {
// TODO Auto-generated method stub
if(next != null)
return "<" + id + ":>" + next;
else return "<" + id + ":>";
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
// TODO Auto-generated method stub
id = (int) in.readObject();
next = (BigWorm)in.readObject();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeObject(id);
out.writeObject(next);
}
}
这样在运行,结果:
Constructor:5
Constructor:4
Constructor:3
Constructor:2
Constructor:1
Constructor:0
<5:><4:><3:><2:><1:><0:>
Constructor:0
Constructor:0
Constructor:0
Constructor:0
Constructor:0
Constructor:0
<5:><4:><3:><2:><1:><0:>
Constructor:id=0的原因是,默认构造器运行在readExternal()之前。
transient关键字
当我们不想让继承serializable的对象中的某个成员变量序列化时,可以给它加上这个关键字就不会再被序列化了。
Externalizable的替代方法。
在继承Serializable的对象中添加两个方法:
private void readObject(ObjectInputStream stream) throws IOException, ClassNotFoundException {}
private void writeObject(ObjectOutputStream stream) throws IOException {}
亲测可用,并且使用方法跟继承Externalizable效果一样,不同的地方就是这样不再需要一个public的默认构造器。
蛋疼的地方时这两个方法看起来像是隐藏方法或是什么作者通道,因为没有任何迹象表明你可以使用这两个方法,并没有抽象类或是接口给你的规范。而且必须是private,只有这样才能识别。至于如何识别的,应该是运用了反射来获取该方法。
ObjectInputStream,ObjectOutputStream各自有一个方法:defaultReadObject();defaultWriteObject();进行跟没有添加这两个方法时Serializable默认进行的工作。
18.12.3 使用“持久性”
当我们多次把同一个序列化对象输出到同一个地方,取出来时这些对象的hasCode是相同的。但当我们把同一个对象输出到两个不同的地方,取出来时这些对象的hasCode是不同的。不管输出到哪再取出来,hasCode都与存进去时的hasCode不同。
还有就是static值是不会被序列化的。
18.14 Preferences
Preferences p = Preferences.userNodeForPackage(Test.class);
p.put("a", "asd");
System.out.println(Preferences.userNodeForPackage(Test.class).get("a", "sss"));
System.out.println(Preferences.userNodeForPackage(Test.class).get("b", "sss"));
try {
Preferences.userNodeForPackage(Test.class).clear();
} catch (BackingStoreException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
输出:
asd
sss
这个Preferences会永久存在,windows往注册表里写。