【学习OpenCV】opencv学习(十五)之图像傅里叶变换dft
学习opencv之图像傅里叶变换dft
在学习信号与系统或通信原理等课程里面可能对傅里叶变换有了一定的了解。我们知道傅里叶变换是把一个信号从时域变换到其对应的频域进行分析。如果有小伙伴还对傅里叶变换处于很迷糊的状态,请戳这里,非常通俗易懂。而在图像处理中也有傅里叶分析的概念,我这里给出在其官方指导文件opencv_tutorials中给出的解释。
傅里叶变换可以将一幅图片分解为正弦和余弦两个分量,换而言之,他可以将一幅图像从其空间域(spatial domain)转换为频域(frequency domain)。这种变换的思想是任何函数可以很精确的接近无穷个sin()函数和cos()函数的和。傅里叶变换提供了这种方法来达到这种效果。对于二位图像其傅里叶变换公式如下: 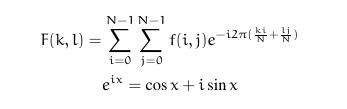
式中f(i, j)是图像空间域的值而F是频域的值。傅里叶转换的结果是复数,这也显示出了傅里叶变换是一副实数图像(real image)和虚数图像(complex image)叠加或者是幅度图像(magitude image)和相位图像(phase image)叠加的结果。在实际的图像处理算法中仅有幅度图像(magnitude image)图像能够用到,因为幅度图像包含了我们所需要的所有图像几何结构的信息。但是,如果想通过修改幅度图像或者相位图像来间接修改原空间图像,需要保留幅度图像和相位图像来进行傅里叶逆变换,从而得到修改后图像。
1.dft()
首先看一下opencv提供的傅里叶变换函数dft(),其定义如下:
C++: void dft(InputArray src, OutputArray dst, int flags=0, int nonzeroRows=0);- 1
参数解释:
. InputArray src: 输入图像,可以是实数或虚数
. OutputArray dst: 输出图像,其大小和类型取决于第三个参数flags
. int flags = 0: 转换的标识符,有默认值0.其可取的值如下所示:
。DFT_INVERSE: 用一维或二维逆变换取代默认的正向变换
。DFT_SCALE: 缩放比例标识符,根据数据元素个数平均求出其缩放结果,如有N个元素,则输出结果以1/N缩放输出,常与DFT_INVERSE搭配使用。
。DFT_ROWS: 对输入矩阵的每行进行正向或反向的傅里叶变换;此标识符可在处理多种适量的的时候用于减小资源的开销,这些处理常常是三维或高维变换等复杂操作。
。DFT_COMPLEX_OUTPUT: 对一维或二维的实数数组进行正向变换,这样的结果虽然是复数阵列,但拥有复数的共轭对称性(CCS),可以以一个和原数组尺寸大小相同的实数数组进行填充,这是最快的选择也是函数默认的方法。你可能想要得到一个全尺寸的复数数组(像简单光谱分析等等),通过设置标志位可以使函数生成一个全尺寸的复数输出数组。
。DFT_REAL_OUTPUT: 对一维二维复数数组进行逆向变换,这样的结果通常是一个尺寸相同的复数矩阵,但是如果输入矩阵有复数的共轭对称性(比如是一个带有DFT_COMPLEX_OUTPUT标识符的正变换结果),便会输出实数矩阵。
. int nonzeroRows = 0: 当这个参数不为0,函数会假设只有输入数组(没有设置DFT_INVERSE)的第一行或第一个输出数组(设置了DFT_INVERSE)包含非零值。这样的话函数就可以对其他的行进行更高效的处理节省一些时间,这项技术尤其是在采用DFT计算矩阵卷积时非常有效。
2. getOptimalDFTSize()
返回给定向量尺寸经过DFT变换后结果的最优尺寸大小。其函数定义如下:
C++: int getOptimalDFTSize(int vecsize);- 1
参数解释:
int vecsize: 输入向量尺寸大小(vector size)
DFT变换在一个向量尺寸上不是一个单调函数,当计算两个数组卷积或对一个数组进行光学分析,它常常会用0扩充一些数组来得到稍微大点的数组以达到比原来数组计算更快的目的。一个尺寸是2阶指数(2,4,8,16,32…)的数组计算速度最快,一个数组尺寸是2、3、5的倍数(例如:300 = 5*5*3*2*2)同样有很高的处理效率。
getOptimalDFTSize()函数返回大于或等于vecsize的最小数值N,这样尺寸为N的向量进行DFT变换能得到更高的处理效率。在当前N通过p,q,r等一些整数得出N = 2^p*3^q*5^r.
这个函数不能直接用于DCT(离散余弦变换)最优尺寸的估计,可以通过getOptimalDFTSize((vecsize+1)/2)*2得到。
3.magnitude()
计算二维矢量的幅值,其定义如下:
C++: void magnitude(InputArray x, InputArray y, OutputArray magnitude);- 1
参数解释:
. InputArray x: 浮点型数组的x坐标矢量,也就是实部
. InputArray y: 浮点型数组的y坐标矢量,必须和x尺寸相同
. OutputArray magnitude: 与x类型和尺寸相同的输出数组
其计算公式如下: ![]()
4. copyMakeBorder()
扩充图像边界,其函数定义如下:
C++: void copyMakeBorder(InputArray src, OutputArray dst, int top, int bottom, int left, int right, int borderType, const Scalar& value=Scalar() );- 1
参数解释:
. InputArray src: 输入图像
. OutputArray dst: 输出图像,与src图像有相同的类型,其尺寸应为Size(src.cols+left+right, src.rows+top+bottom)
. int类型的top、bottom、left、right: 在图像的四个方向上扩充像素的值
. int borderType: 边界类型,由borderInterpolate()来定义,常见的取值为BORDER_CONSTANT
. const Scalar& value = Scalar(): 如果边界类型为BORDER_CONSTANT则表示为边界值
5. normalize()
归一化就是把要处理的数据经过某种算法的处理限制在所需要的范围内。首先归一化是为了后面数据处理的方便,其次归一化能够保证程序运行时收敛加快。归一化的具体作用是归纳同意样本的统计分布性,归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布,在机器学习算法的数据预处理阶段,归一化也是非常重要的步骤。其定义如下:
C++: void normalize(InputArray src, OutputArray dst, double alpha=1, double beta=0, int norm_type=NORM_L2, int dtype=-1, InputArray mask=noArray() )- 1
参数解释:
. InputArray src: 输入图像
. OutputArray dst: 输出图像,尺寸大小和src相同
. double alpha = 1: range normalization模式的最小值
. double beta = 0: range normalization模式的最大值,不用于norm normalization(范数归一化)模式
. int norm_type = NORM_L2: 归一化的类型,主要有
。NORM_INF: 归一化数组的C-范数(绝对值的最大值)
。NORM_L1: 归一化数组的L1-范数(绝对值的和)
。NORM_L2: 归一化数组的L2-范数(欧几里得)
。NORM_MINMAX: 数组的数值被平移或缩放到一个指定的范围,线性归一化,一般较常用。
. int dtype = -1: 当该参数为负数时,输出数组的类型与输入数组的类型相同,否则输出数组与输入数组只是通道数相同,而depth = CV_MAT_DEPTH(dtype)
. InputArray mask = noArray(): 操作掩膜版,用于指示函数是否仅仅对指定的元素进行操作。
示例程序:
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
程序分析:
1.图像填充:
Mat padded;
int m = getOptimalDFTSize(I.rows);
int n = getOptimalDFTSize(I.cols);
copyMakeBorder(I, padded, 0, m - I.rows, 0, n - I.cols, BORDER_CONSTANT, Scalar::all(0));- 1
- 2
- 3
- 4
根据前面的理论介绍可以知道当图像尺寸为2、3、5的倍数时可以得到最快的处理速度,所以通过getOptimalDFTSize()函数获取最佳DFT变换尺寸,之后再结合copyMakeBorder()函数对图像进行扩充。
2.为实部和虚部分配存储空间
Mat planes[] = { Mat_<float>(padded), Mat::zeros(padded.size(),CV_32F) };
Mat complexI;
merge(planes, 2, complexI);- 1
- 2
- 3
傅里叶变换的结果是复数,这就意味着经过傅里叶变换每个图像值都会变成两个值,此外其频域(frequency domains)范围比空间域(spatial counterpart)范围大很多。我们通常以浮点型数据格式对结果进行存储。因此我们将输入图像转换为这种类型,通过另外的通道扩充图像。
3.傅里叶变换
dft(complexI, complexI);- 1
傅里叶变换函数,对图像进行傅里叶变换。
4.将实数和复数的值转换为幅度值
split(complexI, planes);
magnitude(planes[0], planes[1], planes[0]);
Mat magI = planes[0];- 1
- 2
- 3
复数包含实部和虚部两个部分,傅里叶变换的结果是一个复数,傅里叶变换的幅度计算公式是: 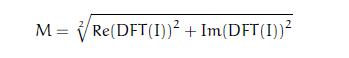
5.转换为对数尺度(Switch to a logarithmic scale)
magI += Scalar::all(1);
log(magI, magI);- 1
- 2
之所以要进行对数转换是因为傅里叶变换后的结果对于在显示器显示来讲范围比较大,这样的话对于一些小的变化或者是高的变换值不能进行观察。因此高的变化值将会转变成白点,而较小的变化值则会变成黑点。为了能够获得可视化的效果,可以利用灰度值将我们的线性尺度(linear scale)转变为对数尺度(logarithmic scale),其计算公式如下: ![]()
6.剪切和象限变换
magI = magI(Rect(0, 0, magI.cols&-2, magI.rows&-2));
int cx = magI.cols / 2;
int cy = magI.rows / 2;
Mat q0(magI, Rect(0, 0, cx, cy));
Mat q1(magI, Rect(cx, 0, cx, cy));
Mat q2(magI, Rect(0, cy, cx, cy));
Mat q3(magI, Rect(cx, cy, cx, cy));
//变换左上角和右下角象限
Mat tmp;
q0.copyTo(tmp);
q3.copyTo(q0);
tmp.copyTo(q3);
//变换右上角和左下角象限
q1.copyTo(tmp);
q2.copyTo(q1);
tmp.copyTo(q2);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在进行傅里叶变换时,为了取得更快的计算效果,对图像进行了扩充,现在就需要对新增加的行列进行裁剪了。为了可视化的需要,我们同样需要对显示的结果图像像素进行调整,如果不进行调整,最后显示的结果是这样的: 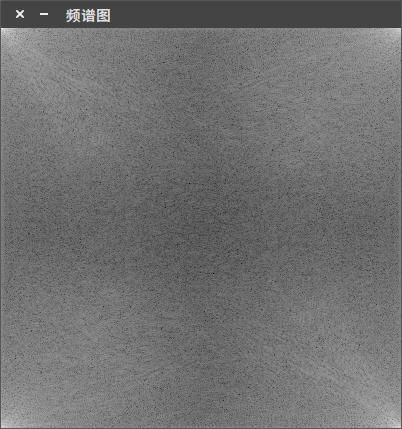
可以看到四周的角上时高频分量,现在我们通过重新调整象限将高频分量调整到图像正中间。
7.归一化
normalize(magI, magI, 0, 1, CV_MINMAX);- 1
对结果进行归一化处理同样是处于可视化的目的。现在我们得到了幅度值,但是这仍然超出了0-1的显示范围。这就需要利用normalize()函数对数据进行归一化处理。
程序运行结果如图: 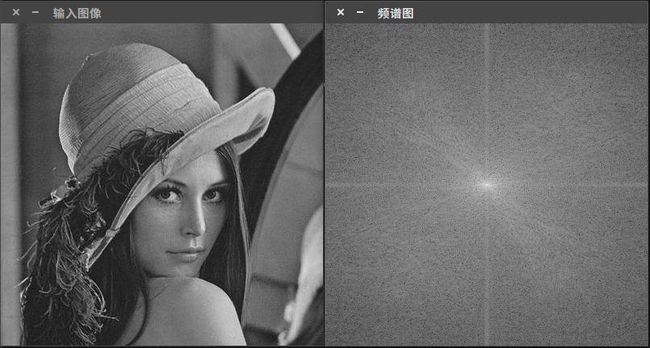
离散傅立叶变换¶
目标
本文档尝试解答如下问题:
- 什么是傅立叶变换及其应用?
- 如何使用OpenCV提供的傅立叶变换?
- 相关函数的使用,如: copyMakeBorder(), merge(), dft(), getOptimalDFTSize(), log() 和 normalize() .
源码
你可以 从此处下载源码 或者通过OpenCV源码库文件 samples/cpp/tutorial_code/core/discrete_fourier_transform/discrete_fourier_transform.cpp 查看.
以下为函数 dft() 使用范例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include
|
原理
对一张图像使用傅立叶变换就是将它分解成正弦和余弦两部分。也就是将图像从空间域(spatial domain)转换到频域(frequency domain)。 这一转换的理论基础来自于以下事实:任一函数都可以表示成无数个正弦和余弦函数的和的形式。傅立叶变换就是一个用来将函数分解的工具。 2维图像的傅立叶变换可以用以下数学公式表达:

式中 f 是空间域(spatial domain)值, F 则是频域(frequency domain)值。 转换之后的频域值是复数, 因此,显示傅立叶变换之后的结果需要使用实数图像(real image) 加虚数图像(complex image), 或者幅度图像(magitude image)加相位图像(phase image)。 在实际的图像处理过程中,仅仅使用了幅度图像,因为幅度图像包含了原图像的几乎所有我们需要的几何信息。 然而,如果你想通过修改幅度图像或者相位图像的方法来间接修改原空间图像,你需要使用逆傅立叶变换得到修改后的空间图像,这样你就必须同时保留幅度图像和相位图像了。
在此示例中,我将展示如何计算以及显示傅立叶变换后的幅度图像。由于数字图像的离散性,像素值的取值范围也是有限的。比如在一张灰度图像中,像素灰度值一般在0到255之间。 因此,我们这里讨论的也仅仅是离散傅立叶变换(DFT)。 如果你需要得到图像中的几何结构信息,那你就要用到它了。请参考以下步骤(假设输入图像为单通道的灰度图像 I):
将图像延扩到最佳尺寸. 离散傅立叶变换的运行速度与图片的尺寸息息相关。当图像的尺寸是2, 3,5的整数倍时,计算速度最快。 因此,为了达到快速计算的目的,经常通过添凑新的边缘像素的方法获取最佳图像尺寸。函数 getOptimalDFTSize() 返回最佳尺寸,而函数 copyMakeBorder() 填充边缘像素:
Mat padded; //将输入图像延扩到最佳的尺寸 int m = getOptimalDFTSize( I.rows ); int n = getOptimalDFTSize( I.cols ); // 在边缘添加0 copyMakeBorder(I, padded, 0, m - I.rows, 0, n - I.cols, BORDER_CONSTANT, Scalar::all(0));
添加的像素初始化为0.
为傅立叶变换的结果(实部和虚部)分配存储空间. 傅立叶变换的结果是复数,这就是说对于每个原图像值,结果是两个图像值。 此外,频域值范围远远超过空间值范围, 因此至少要将频域储存在 float 格式中。 结果我们将输入图像转换成浮点类型,并多加一个额外通道来储存复数部分:
Mat planes[] = {Mat_<float>(padded), Mat::zeros(padded.size(), CV_32F)}; Mat complexI; merge(planes, 2, complexI); // 为延扩后的图像增添一个初始化为0的通道
进行离散傅立叶变换. 支持图像原地计算 (输入输出为同一图像):
dft(complexI, complexI); // 变换结果很好的保存在原始矩阵中
将复数转换为幅度.复数包含实数部分(Re)和复数部分 (imaginary - Im)。 离散傅立叶变换的结果是复数,对应的幅度可以表示为:
![M = \sqrt[2]{ {Re(DFT(I))}^2 + {Im(DFT(I))}^2}](http://img.e-com-net.com/image/info8/259688e8173a4933aa5c95da78ab21a7.png)
转化为OpenCV代码:
split(complexI, planes); // planes[0] = Re(DFT(I), planes[1] = Im(DFT(I)) magnitude(planes[0], planes[1], planes[0]);// planes[0] = magnitude Mat magI = planes[0];
对数尺度(logarithmic scale)缩放. 傅立叶变换的幅度值范围大到不适合在屏幕上显示。高值在屏幕上显示为白点,而低值为黑点,高低值的变化无法有效分辨。为了在屏幕上凸显出高低变化的连续性,我们可以用对数尺度来替换线性尺度:

转化为OpenCV代码:
magI += Scalar::all(1); // 转换到对数尺度 log(magI, magI);
剪切和重分布幅度图象限. 还记得我们在第一步时延扩了图像吗? 那现在是时候将新添加的像素剔除了。为了方便显示,我们也可以重新分布幅度图象限位置(注:将第五步得到的幅度图从中间划开得到四张1/4子图像,将每张子图像看成幅度图的一个象限,重新分布即将四个角点重叠到图片中心)。 这样的话原点(0,0)就位移到图像中心。
magI = magI(Rect(0, 0, magI.cols & -2, magI.rows & -2)); int cx = magI.cols/2; int cy = magI.rows/2; Mat q0(magI, Rect(0, 0, cx, cy)); // Top-Left - 为每一个象限创建ROI Mat q1(magI, Rect(cx, 0, cx, cy)); // Top-Right Mat q2(magI, Rect(0, cy, cx, cy)); // Bottom-Left Mat q3(magI, Rect(cx, cy, cx, cy)); // Bottom-Right Mat tmp; // 交换象限 (Top-Left with Bottom-Right) q0.copyTo(tmp); q3.copyTo(q0); tmp.copyTo(q3); q1.copyTo(tmp); // 交换象限 (Top-Right with Bottom-Left) q2.copyTo(q1); tmp.copyTo(q2);
归一化. 这一步的目的仍然是为了显示。 现在我们有了重分布后的幅度图,但是幅度值仍然超过可显示范围[0,1] 。我们使用 normalize() 函数将幅度归一化到可显示范围。
normalize(magI, magI, 0, 1, CV_MINMAX); // 将float类型的矩阵转换到可显示图像范围 // (float [0, 1]).
结果
离散傅立叶变换的一个应用是决定图片中物体的几何方向.比如,在文字识别中首先要搞清楚文字是不是水平排列的? 看一些文字,你就会注意到文本行一般是水平的而字母则有些垂直分布。文本段的这两个主要方向也是可以从傅立叶变换之后的图像看出来。我们使用这个 水平文本图像 以及 旋转文本图像 来展示离散傅立叶变换的结果 。
水平文本图像:

旋转文本图像:

观察这两张幅度图你会发现频域的主要内容(幅度图中的亮点)是和空间图像中物体的几何方向相关的。 通过这点我们可以计算旋转角度并修正偏差。
翻译者
niesu@ OpenCV中文网站