BERT源码分析PART II
写在前面
BERT的使用可以分为两个步骤:pre-training和fine-tuning。pre-training的话可以很好地适用于自己特定的任务,但是训练成本很高(four days on 4 to 16 Cloud TPUs),对于大对数从业者而言不太好实现从零开始(from scratch)。不过Google已经发布了各种预训练好的模型可供选择,只需要进行对特定任务的Fine-tuning即可。
今天我们就继续按照原始论文的框架,来一起读读BERT预训练的源码。BERT预训练过程分为两个具体子任务:Masked LM 和 Next Sentence Prediction
- tokenization.py
- create_pretraining_data.py
- run_pretraining
1、分词(tokenization.py)
tokenization.py是对原始文本语料的处理,分为BasicTokenizer和WordpieceTokenizer两类。
BasicTokenizer
根据空格,标点进行普通的分词,最后返回的是关于词的列表,对于中文而言是关于字的列表。
class BasicTokenizer(object):
def __init__(self, do_lower_case=True):
self.do_lower_case = do_lower_case
def tokenize(self, text):
text = convert_to_unicode(text)
text = self._clean_text(text)
# 增加中文支持
text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text)
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
def _run_strip_accents(self, text):
# 对text进行归一化
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
# 把category为Mn的去掉
# refer: https://www.fileformat.info/info/unicode/category/Mn/list.htm
if cat == "Mn":
continue
output.append(char)
return "".join(output)
def _run_split_on_punc(self, text):
# 用标点切分,返回list
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
def _tokenize_chinese_chars(self, text):
# 按字切分中文,实现就是在字两侧添加空格
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
# 判断是否是汉字
# refer: https://www.cnblogs.com/straybirds/p/6392306.html
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
def _clean_text(self, text):
# 去除无意义字符以及空格
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
WordpieceTokenizer
WordpieceTokenizer是将BasicTokenizer的结果进一步做更细粒度的切分。做这一步的目的主要是为了去除未登录词对模型效果的影响。这一过程对中文没有影响,因为在前面BasicTokenizer里面已经切分成以字为单位的了。
class WordpieceTokenizer(object):
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
def tokenize(self, text):
"""使用贪心的最大正向匹配算法
例如:
input = "unaffable"
output = ["un", "##aff", "##able"]
"""
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
我们用一个例子来看代码的执行过程。比如假设输入是”unaffable”。我们跳到while循环部分,这是start=0,end=len(chars)=9,也就是先看看unaffable在不在词典里,如果在,那么直接作为一个WordPiece,如果不再,那么end-=1,也就是看unaffabl在不在词典里,最终发现”un”在词典里,把un加到结果里。
接着start=2,看affable在不在,不在再看affabl,…,最后发现 ##aff 在词典里。注意:##表示这个词是接着前面的,这样使得WordPiece切分是可逆的——我们可以恢复出“真正”的词。
FullTokenizer
BERT分词的主要接口,包含了上述两种实现。
class FullTokenizer(object):
def __init__(self, vocab_file, do_lower_case=True):
# 加载词表文件为字典形式
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
def tokenize(self, text):
split_tokens = []
# 调用BasicTokenizer粗粒度分词
for token in self.basic_tokenizer.tokenize(text):
# 调用WordpieceTokenizer细粒度分词
for sub_token in self.wordpiece_tokenizer.tokenize(token):
split_tokens.append(sub_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
2、训练数据生成(create_pretraining_data.py)
这个文件的这作用就是将原始输入语料转换成模型预训练所需要的数据格式TFRecoed。
参数设置
flags.DEFINE_string("input_file", None,
"Input raw text file (or comma-separated list of files).")
flags.DEFINE_string("output_file", None,
"Output TF example file (or comma-separated list of files).")
flags.DEFINE_string("vocab_file", None,
"The vocabulary file that the BERT model was trained on.")
flags.DEFINE_bool( "do_lower_case", True,
"Whether to lower case the input text. Should be True for uncased "
"models and False for cased models.")
flags.DEFINE_integer("max_seq_length", 128, "Maximum sequence length.")
flags.DEFINE_integer("max_predictions_per_seq", 20,
"Maximum number of masked LM predictions per sequence.")
flags.DEFINE_integer("random_seed", 12345, "Random seed for data generation.")
flags.DEFINE_integer( "dupe_factor", 10,
"Number of times to duplicate the input data (with different masks).")
flags.DEFINE_float("masked_lm_prob", 0.15, "Masked LM probability.")
flags.DEFINE_float("short_seq_prob", 0.1,
"Probability of creating sequences which are shorter than the maximum length.")
这里就说几个参数
- dupe_factor: 重复参数,即对于同一个句子,我们可以设置不同位置的【MASK】次数。比如对于句子
Hello world, this is bert.,为了充分利用数据,第一次可以mask成Hello [MASK], this is bert.,第二次可以变成Hello world, this is [MASK[. - max_predictions_per_seq: 一个句子里最多有多少个[MASK]标记
- masked_lm_prob: 多少比例的Token被MASK掉
- short_seq_prob: 长度小于“max_seq_length”的样本比例。因为在fine-tune过程里面输入的target_seq_length是可变的(小于等于max_seq_length),那么为了防止过拟合也需要在pre-train的过程当中构造一些短的样本。
Main入口
首先来看构造数据的整体流程,
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
input_files = []
for input_pattern in FLAGS.input_file.split(","):
input_files.extend(tf.gfile.Glob(input_pattern))
tf.logging.info("*** Reading from input files ***")
for input_file in input_files:
tf.logging.info(" %s", input_file)
rng = random.Random(FLAGS.random_seed)
instances = create_training_instances(
input_files, tokenizer, FLAGS.max_seq_length, FLAGS.dupe_factor,
FLAGS.short_seq_prob, FLAGS.masked_lm_prob, FLAGS.max_predictions_per_seq,
rng)
output_files = FLAGS.output_file.split(",")
tf.logging.info("*** Writing to output files ***")
for output_file in output_files:
tf.logging.info(" %s", output_file)
write_instance_to_example_files(instances, tokenizer, FLAGS.max_seq_length,
FLAGS.max_predictions_per_seq, output_files)
- 构造tokenizer对输入语料进行分词处理(Tokenizer部分会在后续说明)
- 经过
create_training_instances函数构造训练instance - 调用
write_instance_to_example_files函数以TFRecord格式保存数据
下面我们一一解析这些函数。
构造训练样本
首先定义了一个训练样本的类
class TrainingInstance(object):
def __init__(self, tokens, segment_ids, masked_lm_positions, masked_lm_labels,
is_random_next):
self.tokens = tokens
self.segment_ids = segment_ids
self.is_random_next = is_random_next
self.masked_lm_positions = masked_lm_positions
self.masked_lm_labels = masked_lm_labels
def __str__(self):
s = ""
s += "tokens: %s\n" % (" ".join(
[tokenization.printable_text(x) for x in self.tokens]))
s += "segment_ids: %s\n" % (" ".join([str(x) for x in self.segment_ids]))
s += "is_random_next: %s\n" % self.is_random_next
s += "masked_lm_positions: %s\n" % (" ".join(
[str(x) for x in self.masked_lm_positions]))
s += "masked_lm_labels: %s\n" % (" ".join(
[tokenization.printable_text(x) for x in self.masked_lm_labels]))
s += "\n"
return s
def __repr__(self):
return self.__str__()
构造训练样本的代码如下。在源码包中Google提供了一个实例训练样本输入(sample_text.txt),输入文件格式为:
- 每行一个句子,这应该是实际的句子,不应该是整个段落或者段落的随机片段(span),因为我们需要使用句子边界来做下一个句子的预测。
- 不同文档之间用一个空行分割。
- 我们认为同一文档的句子之间是有关系的,不同文档句子之间没有关系。
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
all_documents = [[]]
# all_documents是list的list,第一层list表示document,
# 第二层list表示document里的多个句子。
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
while True:
line = tokenization.convert_to_unicode(reader.readline())
if not line:
break
line = line.strip()
# 空行表示文档分割
if not line:
all_documents.append([])
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# 删除空文档
all_documents = [x for x in all_documents if x]
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys())
instances = []
# 重复dupe_factor次
for _ in range(dupe_factor):
for document_index in range(len(all_documents)):
instances.extend(
create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
rng.shuffle(instances)
return instances
上面的函数会调用create_instances_from_document来实现从一个文档中抽取多个训练样本。
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
document = all_documents[document_index]
# 为[CLS], [SEP], [SEP]预留三个空位
max_num_tokens = max_seq_length - 3
target_seq_length = max_num_tokens
# 以short_seq_prob的概率随机生成(2~max_num_tokens)的长度
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
#
instances = []
current_chunk = []
current_length = 0
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
# 将句子依次加入current_chunk中,直到加完或者达到限制的最大长度
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
# `a_end`是第一个句子A结束的下标
a_end = 1
# 随机选取切分边界
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# 是否随机next
is_random_next = False
# 构建随机的下一句
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
# 随机的挑选另外一篇文档的随机开始的句子
# 但是理论上有可能随机到的文档就是当前文档,因此需要一个while循环
# 这里只while循环10次,理论上还是有重复的可能性,但是我们忽略
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# 对于上述构建的随机下一句,我们并没有真正地使用它们
# 所以为了避免数据浪费,我们将其“放回”
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# 构建真实的下一句
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
# 如果太多了,随机去掉一些
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
tokens = []
segment_ids = []
# 处理句子A
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
# 句子A结束,加上【SEP】
tokens.append("[SEP]")
segment_ids.append(0)
# 处理句子B
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
# 句子B结束,加上【SEP】
tokens.append("[SEP]")
segment_ids.append(1)
# 调用 create_masked_lm_predictions来随机对某些Token进行mask
(tokens, masked_lm_positions,
masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances
上面代码有点长,在关键的地方我都注释上了。下面我们结合一个具体的例子来看代码的实现过程。以提供的sample_text.txt中语料为例,只截取了一部分,下图包含了两个文档,第一个文档中有6个句子,第二个有4个句子:
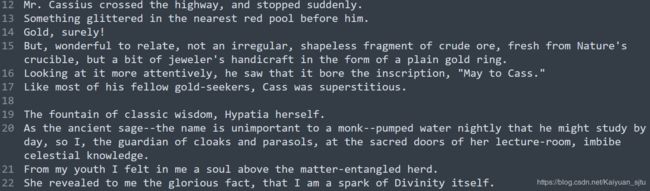
create_instances_from_document分析的是一个文档,我们就以上述第一个为例。
- 算法首先会维护一个chunk,不断加入document中的元素,也就是句子(segment),直到加载完或者chunk中token数大于等于最大限制,这样做的目的是使得padding的尽量少,训练效率更高。
- 现在chunk建立完毕之后,假设包括了前三个句子,算法会随机选择一个切分点,比如2。接下来构建
predict next判断:
(1) 如果是正样本,前两个句子当成是句子A,后一个句子当成是句子B;
(2) 如果是负样本,前两个句子当成是句子A,无关的句子从其他文档中随机抽取 - 得到句子A和句子B之后,对其填充tokens和segment_ids,这里会加入特殊的[CLS]和[SEP]标记
- 对句子进行mask操作(下一节中描述)
随机MASK
对Tokens进行随机mask是BERT的一大创新点。使用mask的原因是为了防止模型在双向循环训练的过程中“预见自身”。于是,文章中选取的策略是对输入序列中15%的词使用[MASK]标记掩盖掉,然后通过上下文去预测这些被mask的token。但是为了防止模型过拟合地学习到【MASK】这个标记,对15%mask掉的词进一步优化:
- 以80%的概率用[MASK]替换:
- hello world, this is bert. ----> hello world, this is [MASK].
- 以10%的概率随机替换:
- hello world, this is bert. ----> hello world, this is python.
- 以10%的概率不进行替换:
- hello world, this is bert. ----> hello world, this is bert.
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
cand_indexes = []
# [CLS]和[SEP]不能用于MASK
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
cand_indexes.append(i)
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
if index in covered_indexes:
continue
covered_indexes.add(index)
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
# 按照下标重排,保证是原来句子中出现的顺序
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
保存tfrecord数据
最后是将上述步骤处理好的数据保存为tfrecord文件。整体逻辑比较简单,代码如下
def write_instance_to_example_files(instances, tokenizer, max_seq_length,
max_predictions_per_seq, output_files):
writers = []
for output_file in output_files:
writers.append(tf.python_io.TFRecordWriter(output_file))
writer_index = 0
total_written = 0
for (inst_index, instance) in enumerate(instances):
# 将输入转成word-ids
input_ids = tokenizer.convert_tokens_to_ids(instance.tokens)
# 记录实际句子长度
input_mask = [1] * len(input_ids)
segment_ids = list(instance.segment_ids)
assert len(input_ids) <= max_seq_length
# padding
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
masked_lm_positions = list(instance.masked_lm_positions)
masked_lm_ids = tokenizer.convert_tokens_to_ids(instance.masked_lm_labels)
masked_lm_weights = [1.0] * len(masked_lm_ids)
while len(masked_lm_positions) < max_predictions_per_seq:
masked_lm_positions.append(0)
masked_lm_ids.append(0)
masked_lm_weights.append(0.0)
next_sentence_label = 1 if instance.is_random_next else 0
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])
# 生成训练样本
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
# 输出到文件
writers[writer_index].write(tf_example.SerializeToString())
writer_index = (writer_index + 1) % len(writers)
total_written += 1
# 打印前20个样本
if inst_index < 20:
tf.logging.info("*** Example ***")
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in instance.tokens]))
for feature_name in features.keys():
feature = features[feature_name]
values = []
if feature.int64_list.value:
values = feature.int64_list.value
elif feature.float_list.value:
values = feature.float_list.value
tf.logging.info(
"%s: %s" % (feature_name, " ".join([str(x) for x in values])))
for writer in writers:
writer.close()
tf.logging.info("Wrote %d total instances", total_written)
测试代码
python create_pretraining_data.py \
--input_file=./sample_text_zh.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
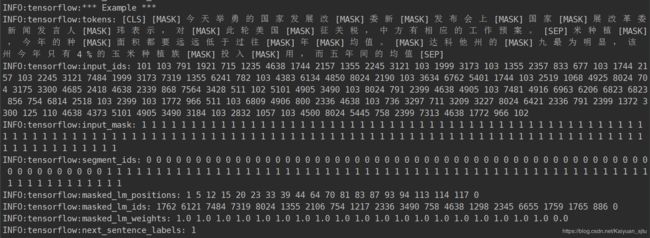
因为我之前下载的词表是中文的,所以就网上随便找了几篇新闻进行测试。结果如下

这是其中的一个样例:
小结一哈
主要介绍BERT的自带分词组件以及pretraining数据生成过程,属于整个项目的准备部分。
没想到代码这么多,pretraining训练的部分就不放在这一篇里了,请见下篇~
以上~
2019.05.17