第十六章 C 预处理器和 C 库
文章目录
- 16.1 翻译程序的第一步
- 16.3 明示常量:#define
- 16.2.1 记号
- 16.2.2 重定义常量
- 16.3 在 #define 中使用参数
- 16.3.1 用宏参数创建字符串:# 运算符
- 16.3.2 预处理器黏合剂:## 运算符
- 16.3.3 变参宏:... 和 __VA_ARGS__
- 16.4 宏和函数的选择
- 16.5 文件包含:#include
- 16.5.1 头文件示例
- 16.5.2 使用头文件
- 16.6 其他指令
- 16.6.1 #undef 指令
- 16.6.2 从 C 预处理器角度看已定义
- 16.6.3 条件编译
- 16.6.4 预定义宏
- 16.6.5 #line 和 #error
- 16.6.6 #pragma
- 16.6.7 泛型选择(C11)
- 16.7 内联函数(C99)
- 16.8 _Noreturn 函数(C11)
- 16.9 C 库
- 16.9.1 访问 C 库
- 16.10 数学库
- 16.10.1 三角问题
- 16.11 通用工具库
- 注意 C 和 C++ 中的 void*
- 16.12 断言库
- 16.12.1 assert 的用法
- 16.12.2 _Static_assert(C11)
- 16.13 string.h 库中的 memcpy() 和 memmove()
- 16.14 可变参数:stdarg.h
- 16.15 关键概念
- 16.16 本章小结
- 16.17 复习题
- 16.18 编程练习
C 语言建立在适当的关键字、表达式、语句以及使用它们的规则上。然而,C 标准不仅描述 C 语言,还描述如何执行 C 预处理器、C 标准有哪些函数,以及详述这些函数的工作原理。本章将介绍 C 预处理器和 C 库,我们先从 C 预处理器开始。
C 预处理器在程序执行之前查看程序(故称之为预处理器)。根据程序中的预处理器指令,预处理器把符号缩写替换成其表示的内容。预处理器可以包含程序所需的其他文件,可以选择让编译器查看哪些代码。预处理器并不知道 C。基本上它的工作是把一些文件转换成另外一些文件。这样描述预处理器无法体现它的真正效用和价值,我们将在本章举例说明。前面的程序示例中也有很多 #define 和 #include 的例子。
16.1 翻译程序的第一步
在预处理之前,编译器必须对该程序进行一些翻译出来。首先,编译器把源代码中出现的字符映射到源字符集。该过程处理多字节符和三字符序列——字符扩展让 C 更加国际化。
第二,编译器定位每个反斜杠后面跟着换行符的实例,并删除它们。也就是说,把下面两个物理行(physical line):
printf("That's wond\
erful!\n");
转换成一个逻辑行(logical line):printf("That's wonderful\n!");
注意,在这种场合中,“换行符” 的意思是通过按下 Enter 键在源代码文件中换行所生产的字符,而不是指符号表征 \n。
由于预处理表达式的长度必须是一个逻辑行,所以这一步位预处理器做好准备工作。一个逻辑行可以是多个物理行。
第三,编译器把文本划分成预处理记号序列、空白序列和注释序列(记号是有空格、制表符或换行符分隔的项)。这里要注意的是,编译器将用一个空格字符替换每一条注释。因此,下面的代码:int /* 这看起来并不像一个空格 */fox; 将变成:int fox;
而且,实现可以用一个空格替换所有的空白字符序列(不包括换行符)。最后,程序已经准备好进入预处理阶段,预处理器查找一行中以 # 号开始的预处理指令。
16.3 明示常量:#define
#define 预处理器指令和其他预处理器指令一样,以 # 号作为一行的开始。ANSI 和后来的标准都允许 # 号前面有空格或制表符,而且还允许在 # 和指令的其余部分之间有空格。但是旧版本的 C 要求指令从一行最左边开始,而且 # 和指令其余部分之间不能有空格。指令可以出现在源文件的任何地方,其定义从指令出现的地方到该文件末尾有效。我们大量使用 #define 指令来定义明示常量(manifest constant)(也叫做符号常量),但是该指令还有许多其他用途。程序清单演示了 #define 指令的一些用法和属性。
预处理器指令从 # 开始运行,到后面的第 1 个换行符为止。也就是说,指令的长度仅限于一行。然而,前面提到过,在预处理开始前,编译器会把多行物理行处理位一行逻辑行。
/* 简单的预处理示例 */
#include
#define TWO 2
#define OW "Consistency is the last refuge of the unimagina\
tive. - Oscar Wilde"
#define FOUR TWO*TWO
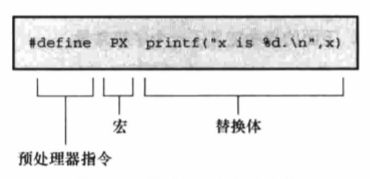
#define PX printf("X is %d.\n",x)
#define FMT "X is %d.\n"
int main(void)
{
int x = TWO;
PX;
x = FOUR;
printf(FMT,x);
printf("%s\n",OW);
printf("TWO: OW\n");
return 0;
}
每行 #define(逻辑行)都由 3 部分组成。第 1 部分是 #define 指令本身。第 2 部分是选定的缩写,也成为宏。有些宏代表值(如本例),这些宏被称为类对象宏(object-like macro)。C 语言还有类函数宏(function-like macro),稍后讨论。宏的名称中不允许有空格,而且必须遵循 C 变量的命名规则:只能使用字符、数字和下划线(_)字符,而且首字符不能是数字。第 3 部分(指令行的其余部分)称为替换列表或替换体。一旦预处理器在程序中找到宏的示实例后,就会用替换代替该宏(也有例外)。从宏变成最终替换文本的过程称为宏展开(macro expansion)。注意,可以在 #define 行使用标准 C 注释。如前所述,每条注释都会被一个空格代替。
运行该程序示例后,输出如下:
X is 2.
X is 4.
Consistency is the last refuge of the unimaginative. - Oscar Wilde
TWO: OW
下面分析具体的过程。下面的语句:int x = TWO; 变成了: int x = 2;
2 代替了 TWO。而语句:PX; 变成了:printf("X is %d.\n",x);
这里同样进行了替换。这是一个新用法,到目前为止我们只是用宏来表示明示常量。从该例中可以看出,宏可以表示任何字符串,甚至可以表示整个 C 表达式。但是要注意,虽然 PX 是一个字符串常量,它只打印一个名为 x 的变量。
下一行也是一个新用法。读者可能认为 FOUR 被替换成 4,但是实际的过程是:x = FOUR; 变成了:x = TWO * TWO; 即是:x = 2 * 2;
宏展开到此处为止。由于编译器在编译期对所有的常量表达式(只包含常量的表达式)求值,所以预处理器不会进行实际的乘法运算,这一过程在编译时进行。预处理器不做计算,不对表达式求值,它只进行替换。
注意,宏定义还可以包含其他宏(一些编译器不支持这种嵌套功能)。
程序中的下一行:printf(FMT,x); 变成了:printf("X is %d.\n",x); 相应的字符串替换了 FMT。如果要多次使用某个冗长的字符串,这种方法比较方便。另外,也可以用下面的方法:const char * fmt = "X is %d.\n"; 然后可以把 fmt 作为 printf() 的格式字符串。
下一行中,用相应的字符串替换 OW。双引号使替换的字符串成为字符串常量。编译器把该字符串储存在以空字符结尾的数组中。因此,下面的指令定义了一个字符常量:#define HAL 'z' 而下面的指令则定义了一个字符串(z\0):#define HAP "z"
在程序示例中,我们在一行的结尾加一个反斜杠字符使该行扩展至下一行:
#define OW "Consistency is the last refuge of the unimagina\
tive. - Oscar Wilde"
那么输出的内容是:Consistency is the last refuge of the unimaginative. - Oscar Wilde
第 2 行开始到 tive 之间的空格也算是字符串的一部分。
一般而言,预处理器发现程序中的宏后,会用宏等价的替换文本进行替换。如果替换的字符串中还包含宏,则继续替换这些宏。唯一例外的是双引号中的宏。因此,下面的语句:printf("TWO: OW"); 打印的是 TWO: OW,而不是打印:2: Consistency is the last refuge of the unimaginative. - Oscar Wilde 要打印这行,应该这样写:printf("%d: %s\n",TWO,OW); 这行代码中,宏不在双引号内。
那么,何时使用字符常量?对于绝大部分数字常量,应该使用字符常量。如果在算式中用字符常量代替数字,常量名能更清楚地表达该数字的含义。如果是表示数组大小的数字,用符号常量后更容易改变数组的大小和循环次数。如果数字是系统代码(如,EOF),用符号常量表示的代码更容易移植(只需改变 EOF 的定义)。助记、易更改、可移植,这些都是符号常量很有价值的特性。
C 语言现在也支持 const 关键字,提供了更灵活的方法。用 const 可以创建在程序运行过程中不能改变的变量,可具有文件作用域或块作用域。另一方面,宏常量可用于指定标准数组的大小和 const 变量的初始值。
#define LIMIT 20
const int LIM = 50;
static int datal[LIMIT]; // 有效
static int data2[LIM]; // 无效
const int LIM2 = 2 * LIMIT; // 有效
const int LIM3 = 2 * LIM; // 无效
这里解释一下上面代码中的 “无效” 注释。在 C 中,非自动数组的大小应该是整型常量表达式,这意味着数组大小的必须是整型常量的组合(如 5)、枚举常量和 sizeof 表达式,不包括 const 声明的值(这也是 C++ 和 C 的区别之一,在 C++ 中可以把 const 值作为常量表达式的一部分)。但是,有的实现可能接受其他形式的常量表达式。
16.2.1 记号
从技术角度来看,可以把宏的替换体看作是记号(token)型字符串,而不是字符型字符串。C 预处理器记号是宏顶一顶额替换体中单独的 “词”。用空白把这些词分开。例如:#define FOUR 2*2 该宏定义有一个记号:22 序列。但是,下面的宏定义中:#define SIX 2 * 3 有 3 个记号:2、、3。
替换体中有多个空格时,字符型字符串和记号型字符串的处理方式不同。考虑下面的定义:#define EIGHT 4 * 8
如果预处理器把该替换体解释位字符型字符串,将用 4 * 8 替换 EIGHT。即,额外的空格是替换体的一部分。如果预处理器把该替换体解释为记号型字符串,则用 3 个的记号 4 * 8(分别由单个空格分隔)来替换 EIGHT。换而言之,解释位字符型字符串,把空格视为替换体的一部分;解释位记号型字符串,把空格视为替换体找那个各记号的分隔符。在实际应用中,一些 C 编译器把宏替换体视为字符串而不是记号。在比这个例子更复杂的情况下,两者的区别才有实际意义。
顺带一提,C 编译器处理记号的方式比预处理器复杂。由于编译器理解 C 语言的规则,所以不要求代码中用空格来分隔记号。例如,C 编译器可以把 22 直接视为 3 个记号,因为它可以识别 2 是常量, 是运算符。
16.2.2 重定义常量
假设先把 LIMIT 定义为 20,稍后在该文件中又把它定义为 25.这个过程称为重定义常量。不同的实现采用不同的重定义方案。除非新定义与旧定义相同,否则有些实现会将其视为错误。另外一些实现允许重定义,但会给出警告。ANSI 标准采用第 1 种方案,只有新定义和旧定义完全相同才允许重定义。
具有相同的定义意味着替换体中的记号必须相同,且顺序也相同。因此,下面两个定义相同:
#define SIX 2 * 3
#define SIX 2 *3
这两条定义都有 3 个相同的记号,额外的空格不算替换体的一部分。而下面的定义则与上面两条宏定义不同:#define SIX 2*3
这条宏定义中只有一个记号,因此与前两条定义不同。如果需要重新定义宏,使用 #undef 指令。
如果确实需要重定义常量,使用 const 关键字和作用域规则更容易些。
16.3 在 #define 中使用参数
在 #define 中使用参数可以创建外形和作用域函数类似的类函数宏。带有参数的宏看上去很像函数,因为这样的宏也使用圆括号。类函数宏定义的圆括号中可以有一个或多个参数,随后这些参数出现在替换体中,如图所示。

下面是一个类函数宏的示例:#define SQUARE(x) X*X 在程序中可以这样用:z = SQUARE(2); 这看上去像函数调用,但是它的行为和函数调用完全不同。程序清单演示了类函数宏和另一个宏的用法。该示例有一些陷阱,请读者仔细阅读。
/* 带参数的宏 */
#include
#define SQUARE(X) X*X
#define PR(X) printf("The result is %d.\n",X)
int main(void)
{
int x = 5;
int z;
printf("x = %d\n",x);
z = SQUARE(x);
printf("Evaluating SQUARE(x): ");
PR(z);
z = SQUARE(2);
printf("Evaluating SQUARE(2): ");
PR(z);
printf("Evaluating SQUARE(x + 2): ");
PR(SQUARE(x + 2));
printf("Evaluating 100/SQUARE(2): ");
PR(100/SQUARE(2));
printf("x is %d.\n",x);
printf("Evaluating SQUARE(++x): ");
PR(SQUARE(++x));
printf("After incrementing, x is %x.\n",x);
return 0;
}
SQUARE 宏的定义如下:#define SQUARE(X) X*X
这里,SQUARE 是宏标识符,SQUARE(X) 中的 X 是宏参数,XX 是替换列表。程序清单中出现 SQUARE(X) 的地方都会被 XX 替换。这与前面的示例不同,使用该宏时,既可以用 X,也可以用其他符合。宏定义中的 X 由宏调用中的符号代替。因此,SQUARE(2) 替换为 2*2,X 实际上起到参数的作用。
然而,稍后你将看到,宏参数与函数参数不完全相同。下面是程序的输出。注意有些内容可能与我们的预期不符。实际上,你得编译器输出甚至与下面的结果完全不同。
x = 5
Evaluating SQUARE(x): The result is 25.
Evaluating SQUARE(2): The result is 4.
Evaluating SQUARE(x + 2): The result is 17.
Evaluating 100/SQUARE(2): The result is 100.
x is 5.
Evaluating SQUARE(++x): The result is 49.
After incrementing, x is 7.
16.3.1 用宏参数创建字符串:# 运算符
下面是一个类函数宏:#define PSQR(X) printf("The square of X is %d.\n",((X)*(X))); 假设这样使用宏:PSQR(8); 输出为:The square of X is 64. 注意双引号字符串中的 X 被视为普通文本,而不是一个可被替换的记号。
C 允许在字符串中包含宏参数。在类函数宏的替换体中,# 号作为一个预处理运算符,可以把记号转换成字符串。例如,如果 x 是一个宏形参,那么 #x 就是转换为字符串 “x” 的形参名。这个过程称为字符串化(stringizing)。程序清单演示了该过程的用法。
/* 在字符串中替换 */
#include
#define PSQR(x) printf("The square of " #x " is %d.\n",((x)*(x)))
int main(void)
{
int y = 5;
PSQR(y);
PSQR(2 + 4);
return 0;
}
该程序的输出如下:
The square of y is 25.
The square of 2 + 4 is 36.
调用第 1 个宏时,用 “y” 替换 #x。调用第 2 个宏时,用 “2 + 4” 替换 #x。ANSI C 字符串的串联特性将这些字符串与 printf() 语句的其他字符串组合,生成最终的字符串。例如,第 1 次调用变成:printf("The square of " "y" " is %d.\n",((y)*(y))) 然后,字符串串联动功能将这 3 个相邻的字符串组合成一个字符串:"The square of y is %d.\n"
16.3.2 预处理器黏合剂:## 运算符
与 # 运算符类似,## 运算符可用于类函数宏的替换部分。而且,## 还可用于对象宏的替换部分。## 运算符把两个记号组合成一个记号。例如,可以这样做:#define XNAME(n) x ## n 然后,宏 XNAME(4) 将展开位 x4.程序清单演示了 ## 作为记号粘合剂的用法。
/* 使用 ## 运算符 */
#include
#define XNAME(n) x ## n
#define PRINT_XN(n) printf("x " #n " = %d\n",x ## n)
int main(void)
{
int XNAME(1) = 14; // 变成 int x1 = 14;
int XNAME(2) = 20; // 变成 int x2 = 20;
int x3 = 30;
PRINT_XN(1); // 变成 printf("x1 = %d\n",x1);
PRINT_XN(2); // 变成 printf("x2 = %d\n",x2);
PRINT_XN(3); // 变成 printf("x3 = %d\n",x3);
return 0;
}
该程序的输出如下:
x 1 = 14
x 2 = 20
x 3 = 30
注意,PRINT_XN() 宏用 # 运算符组合字符串,## 运算符把记号组合为一个新的标识符。
16.3.3 变参宏:… 和 VA_ARGS
一些函数(如 printf() )接受数量可变的参数。stdvar.h 头文件提供了工具,让用户自定义带可变参数的函数。C99/C11 也对宏提供了这样的工具。虽然标准中未使用 “可变”(variadic)这个词,但是它已成为描述这种工具的通用词(虽然,C 标准的索引添加了字符串化(stringizing)词条,但是,标准并未把固定参数的函数或宏成为固定函数和不变宏)。
通过把宏参数列表中最后的参数写成省略号(即,3 个点 …)来实现这一功能。这样,预定义宏 VA_ARGS 可用在替换部分中,表明省略号代表什么。例如,下面的定义:#define PR(...) printf(__VA_ARGS__)
假设稍后调用该宏:
PR("Howdy");
PR("weight = %d, shipping = $%.2f\n",wt,sp);
对于第 1 次调用, VA_ARGS 展开位 1 个参数:“Howdy”。
对于第 2 次调用, VA_ARGS 展开位 3 个参数:“weight = %d, shipping = $%.2f\n”,wt,sp。
因此,展开后的代码是:
printf("Howdy")
printf("weight = %d, shipping = $%.2f\n",wt,sp)
程序清单演示了一个示例,该程序使用了字符串的串联功能和 # 运算符。
/* 变参宏 */
#include
#include
#define PR(X,...) printf("Message " #X ": "__VA_ARGS__)
int main(void)
{
double x = 48;
double y;
y = sqrt(x);
PR(1,"x = %g\n",x);
PR(2,"x = %.2f, y = %.4f\n",x,y);
return 0;
}
第 1 个宏调用,X 的值是 1,所以 #X 变成 “1”。展开后成为:printf("Message " #X ": " "x = %g\n",x); 然后,串联 4 个字符,把调用简化为:printf("Message 1: x = %g\n",x);
下面是该程序的输出:
Message 1: x = 48
Message 2: x = 48.00, y = 6.9282
记住,省略号只能代替最后的宏参数:#define WRONG(X,...,Y) #X #__VA_ARGS__ #y // 不能这样做
16.4 宏和函数的选择
有些编程任务既可以用带参数的宏完成,也可以用函数完成。应该使用宏还是函数?这没有硬性规定,但是可以参考下面的情况。
使用宏比使用普通函数复杂一些,稍有不慎会产生奇怪的副作用。一些编译器规定宏只能定义成一行。不过,即使编译器没有这个限制,也应该这样做。
宏和函数的选择时间上是时间和空间的权衡。宏生成内联代码,即在程序中生成语句。如果调用 20 次宏,即在程序中插入 20 行代码。如果调用函数 20 次,程序中只有一份函数语句的副本,所以节省了空间。然而另一方面,程序的控制必须跳转至函数内,随后再返回主调程序,这显然比内联代码花费更多的时间。
宏的一个优点是,不用担心变量类型(这是因为宏处理的是字符串,而不是实际的值)。因此,只有能用 int 或 float 类型都可以使用 SQUARE(x) 宏。
C99 提供了第 3 中可替换的方法——内联函数。本章后面将介绍。
对于简单的函数,程序员通常使用宏,如下所示:
#define MAX(X,Y) ((X) > (Y) ? (X) : (Y))
#define ABS(X) ((X) < 0? -(X) : (X))
#define ISSIGN(X) ((X) == '+' || (X) == '-' ? 1 : 0) // 如果 x 是一个代数符号字符,最后一个宏的值为1,即为真。
要注意以下几点:
- 记住宏名中不允许有空格,但是在替换字符串中可以有空格。ANSI C 允许在参数列表中使用空格。
- 用圆括号把宏的参数和整个替换体括起来。这样能确保被括起来的部分在下面这样的表达式中正确地展开:
forks = 2 * MAX(guests + 3,last); - 用大写字母表示宏函数的名称,该管理不如用大写字母表示宏常量应用广泛。但是,大写字母可以提醒程序员注意,宏可能产生的副作用。
- 如果打算打算使用宏来加快程序的运行速度,那么首先要确定使用宏和使用函数是否会导致较大差异。在程序中只使用一次的宏无法明显减少程序的运行时间。在嵌套循环中使用宏更有助于提高效率。
许多系统提供程序分析器以帮助称一下压缩程序中最耗时的部分。
假设你开发了一些方便的宏函数,是否每写一个新程序都要重写这些宏?如果使用 #include 指令,就不用这样做了。
16.5 文件包含:#include
当预处理器发现 #include 指令时,会查看后面的文件名并把文件的内容包含到当前文件中,即替换源文件中的 #include 指令。这相当于把被包含文件的全部内容输入到源文件 #include 指令所在的位置。#include 指令有两种形式:
#include // 文件名在尖括号中
#include "mystuff.h" // 文件名在双引号中
在 UNIX 系统中,尖括号告诉预处理器在标准系统目录中查找该文件。双引号告诉预处理器首先在当前目录中(或文件名指定的其他目录)查找该文件,如果未找到再查找标准系统目录:
#include // 查找系统目录
#include "hot.h" // 查找当前工作目录
#include "/usr/biff/p.h" // 查找 /usr/biff 目录
集成开发环境(IDE)也有标准路径或系统头文件的路径。许多集成开发环境提供菜单选项,指定用尖括号时的查找路径。在 UNIX 中,使用双引号意味着先查找本地目录,但是具体查找哪个目录取决于编译器的设定。有些编译器会搜索源代码文件所在的目录,有些编译器则搜索当前的工作目录,还有些搜索项目文件所在的目录。
ANSI C 不为文件提供统一的目录模型,因为不同的计算机所以的系统不同。一般而言,命名文件的方法因系统而异,但是尖括号和双引号的规则与系统无关。
C 语言习惯用 .h 后缀表示头文件,这些文件包含需要放在程序顶部的信息。头文件经常包含一些预处理器指令。有些头文件(如 stdio.h)由系统提供,当然你也可以创建自己的头文件。
包含一个大型头文件不一定显著增加程序的大小。在大部分情况下,头文件的内容是编译器生成最终代码时所需的信息,而不是添加到最终代码中的材料
16.5.1 头文件示例
/* names_st.h -- names_st 结构的头文件 */
// 常量
#include
#define SLEN 32
// 结构声明
struct names_st
{
char first[SLEN];
char last[SLEN];
};
// 类型定义
typedef struct names_st names;
// 函数原型
void get_names(names *);
void show_names(const names *);
char * s_gets(char * st, int n);
该头文件包含了一些文件中常见的内容:#define 指令、结构声明、typedef 和函数原型。注意,这些内容是编译器在创建可执行代码时所需的信息,而不思可执行代码。为简单起见,这个特殊的头文件过于简单。通常,应该用 #ifndef 和 # #define 防止多重包含头文件。
可执行代码通常在源代码文件中,而不是在头文件中。
/* names_st.c -- 定义 names_st.h 中的函数 */
/* names_st.c -- 定义 names_st.h 中的函数 */
#include "names_st.h"
#include // 包含头文件
// 函数定义
void get_names(names * pn)
{
printf("Please enter your first name: ");
s_gets(pn->first,SLEN);
printf("Please enter your last name: ");
s_gets(pn->last,SLEN);
}
void show_names(const names * pn)
{
printf("%s %s",pn->first,pn->last);
}
char * s_gets(char * st, int n)
{
char * ret_val;
char * find;
ret_val = fgets(st,n,stdin);
if(ret_val)
{
find = strchr(st,'\n');
if(find)
*find = '\0';
else
while(getchar() != '\n')
continue;
}
return ret_val;
}
get_names() 函数通过 s_gets() 函数调用了 fgets() 函数,避免了目标数组溢出。
#include
#include "names_st.h" // 记住要连接 names_st.c
int main(int argc,char *argv[])
{
names candidate;
get_names(&candidate);
printf("Let's welcome ");
show_names(&candidate);
printf(" to this program!\n");
return 0;
}
下面是该程序的输出:
Please enter your first name: Ian
Please enter your last name: Smersh
Let’s welcome Ian Smersh to this program!
该程序要注意下面几点。
- 两个源代码文件都使用 names_st 类型结构,所以它们必须包含 names_st.h 头文件。
- 必须编译和链接 names_st.c 和 useheader.c 源代码文件。
- 声明和指令放在 names_st.h 头文件中,函数定义放在 names_st.c 源代码文件中。
16.5.2 使用头文件
浏览任何一个标准头文件都可以了解头文件的基本信息。头文件中最常用的形式如下。
- 明示常量——例如,stdio.h 中定义的 EOF、NULL 和 BUFSIZE(标准 I/O 缓冲区大小)。
- 宏函数——例如,getc(stdin) 通常用 getchar() 定义,而 getc() 经常用于定义较复杂的宏,头文件 ctype.h 通常包含 ctype 系列函数的宏定义。
- 函数声明——例如,string.h 头文件包含字符串函数系列的函数声明。在 ANSI C 和后面的标准中,函数声明都是函数原型形式。
- 结构模板定义——标准 I/O 函数使用 FILE 结构,该结构中包含了文件和与文件缓冲区相关的信息。FIEL 结构在头文件 stdio.h 中。
- 类型定义——标准 I/O 函数使用指向 FIEL 的指针作为参数。通常,stdio.h 用 #define 或 typedef 把 FILE 定义为指向结构的指针。类似地,size_t 和 time_t 类型也定义在头文件中。
许多程序员在程序中使用自己开发的标准头文件。如果开发一系列相关的函数或结构,那么这种方法特别有价值。
另外,还可以使用头文件声明外部变量供其他文件共享。例如,如果已经开发了共享某个变量的一系列函数,该变量报告某种状况(如,错误情况),这种方法就很有效。这种情况下,可以在包含这些函数声明的源代码文件定义一个文件作用域的外部链接变量:int status = 0; // 该变量具有文件作用域,在源代码文件
然后,可以在与源代码文件相关联的头文件中进行引用式声明:extern int status; // 在头文件中
这行代码会出现在包含了该头文件的文件中,这样使用该系列函数的文件都能使用这个变量。虽然源代码文件中包含该头文件后也包含了该声明,但是只有声明的类型一致,在一个文件中同时使用定义式声明和引用式声明没问题。
需要包含头文件的另一种情况是,使用具有文件作用域、内部链接和 const 限定符的变量或数值。const 防止值被意外修改,static 意味着每个包含该头文件的文件都获得一份副本。因此,不需要在一个文件中进行定义式声明,在其他文件中进行引用式声明。
#include 和 #define 指令时最常用的两个 C 预处理器特性。
16.6 其他指令
不同的环境可能使用不同的代码类型。预处理器提供一些指令,程序员通过修改 #define 的值即可生成可移植的代码。#undef 指令取消之前的 #define 定义。#if、#ifdef、#ifndef、#else、#elif 和 #endif 指令用于指定什么情况下编写哪些代码。#line 指令用于重置行和文件信息,#error 指令用于给出错误信息,#pragma 指令用于向编译器发出指令。
16.6.1 #undef 指令
#undef 指令用于 “取消” 已定义的 #define 指令。也就是说,假设有如下定义:#define LIMIT 400 然后,下面的指令:#undef LIMIT
将移除上面的定义。现在就可以把 LIMIT 重新定义为一个新值。即使原来没有定义 LIMIT,取消 LIMIT 的定义仍然有效。如果想使用一个名称,又不确定之前是否已经用过,为安全起见,可以用 #undef 指令取消该名字的定义。
16.6.2 从 C 预处理器角度看已定义
处理器在识别标识符时,遵循与 C 相同的规则:标识符可以由大写字母、小写字母、数字和下划线字符组成,且首字符不能是数字。当预处理器在预处理器指令中发现一个标识符时,它会把该标识符当作已定义的或未定义的。这里的已定义表示有预处理器定义。如果标识符时同一个文件中由前面的 #define 指令创建的宏名,而且没有用 #undef 指令关闭,那么该标识符时已定义的。如果标识符不是宏,假设是一个文件作用域的 C 变量,那么该标识符对预处理器而言就是未定义的。
已定义宏可以是对象宏,包括空宏或类函数宏:
#define LIMIT 1000 //LIMIT 是已定义的
#define GOOD // GOOD 是已定义的
#define A(X) ((-X_))*(X)) // A 是已定义的
int q; // q 不是宏,因此是未定义的
#undef GOOD // GOOD 取消定义,是未定义的的
注意,#define 宏的作用域从它在文件中的声明处开始,知道用 #undef 指令取消宏为止,或延伸至文件尾(以二者中先满足的条件作为宏作用域的结束)。另外在意注意,如果宏通过头文件引入,那么 #define 在文件中的位置取决于 #include 指令的位置。
16.6.3 条件编译
可以使用其他指令创建条件(conditional compilation)。也就是说,可以使用这些指令高数编译器根据编译时的条件执行或忽略信息(或代码)块。
1、#ifdef、#else 和 #endif 指令
我们用一个简短的示例来演示条件编译的情况。考虑下面的代码:
#ifdef MAVIS // 如果已经用 #define 定义了 MAVIS,则执行下面的指令
#include "horse.h"
#define STABLES 5
#else // 如果没有用 #define 定义了 MAVIS,则执行下面的指令
#include "cow.h"
#define STABLES 15
#endif
这里使用的较新的编译器和 ANSI 标准支持的缩进格式。如果使用旧的编译器,必须左对齐所以的指令或至少左对齐 # 号,如下所示:
#ifdef MAVIS // 如果已经用 #define 定义了 MAVIS,则执行下面的指令
#include "horse.h"
#define STABLES 5
#else // 如果没有用 #define 定义了 MAVIS,则执行下面的指令
#include "cow.h"
#define STABLES 15
#endif
#ifdef 指令说明,如果预处理器已定义了后面的标识符(MAVIS),则执行 #else 或 #endif 指令之前的所有指令并编译所有 C 代码(先出现哪个指令就执行到哪里),如果预处理器未定义 MAVIS,且有 #else 指令,则执行 #else 和 #endif 指令之间的所有代码。
#ifdef #else 很像 C 的 if else。两者的主要区别是,预处理器不识别用于标记块的花括号( {} ),因此它使用 #else (如果需要)和 #endif(必须存在)来标记指令块。这些指令结构可以嵌套。也可以用这些指令标记 C 语句块,如程序清单所示。
/* 使用条件编译 */
#include
#define JUST_CHECKING
#define LIMIT 4
int main(void)
{
int i;
int total = 0;
for(i = 1; i <= LIMIT; i++)
{
total += 2 * i * i + 1;
#ifdef JUST_CHECKING
printf("i = %d, running total = %d\n",i,total);
#endif // JUST_CHECKING
}
printf("Grand total = %d\n",total);
return 0;
}
编译并运行该程序后,输出如下:
i = 1, running total = 3
i = 2, running total = 12
i = 3, running total = 31
i = 4, running total = 64
Grand total = 64
如果省略了 JUST_CHECKING 定义(把它放在 C 注释中,或者使用 #undef 指令取消它的定义)并重新编译该程序,只会输出最后一行。可以用这种方法在调试程序。定义 JUST_CHECKING 并合理使用 #ifdef,编译器执行用于调试的程序代码,打印中间值。调试结束后,可移除 JUST_CHECKING 定义并重新编译。如果以后还需要使用这些信息,重新插入定义即可。这样做省去了再次输入额外打印语句的麻烦。#ifdef 还可用于根据不同的 C 实现选择合适的代码块。
2、#ifndef 指令
#ifndef 指令与 #ifdef 指令的用法类似,也可以和 #else、#endif 一起使用,但是它们的逻辑相反。#ifndef 指令判断后面的标识符是否是未定义的,常用于定义之前未定义的常量。如下所示:
/* arrays.h */
#ifndef SIZE
#define SIZE 100
#endif
(旧的实现可能不允许使用缩进的 #define)
通常,包含多个头文件时,其中的文件可能包含了相同宏定义。#ifndef 指令可以防止相同的宏被重复定义。在首次定义一个宏的头文件中用 #ifndef 指令激活定义,随后再其他头文件中的定义都被忽略。
#ifndef 指令还有另一种用法。假设有上面的头文件,然后把下面一行代码放入一个头文件中:include "arrays.h" SIZE 被定义为 100。但是,如果把下面的代码放入该头文件中:
#define SIZE 10
include "arrays.h"
SIZE 则被设置为 10。这里,当执行到 include "arrays.h" 这行处理 arrays.h 中的代码时,由于 SIZE 是已定义的,所以跳过了 #define SIZE 100 这行代码。鉴于此,可以利用这种方法,应一个较小的数测试程序。测试完毕后,移除 #define SIZE 10 并重新编译。这样,就不用修改头文件数组本身了。
#ifndef 指令通常用于防止多次包含一个文件。
为何要多次包含一个文件?最常见的原因是,许多倍包含的文件中都包含着其他文件,所以显式包含的文件中可能包含着已经包含的其他文件。这有什么问题?在被包含的文件中有某些项(如,一些结构类型的声明)只能在一个文件中出现一次。C 标准头文件使用 #ifndef 技巧避免重复包含。但是,这存在一个问题:如果确保待测试的标识符没有在别处定义。通常,实现的供应商使用这些方法解决这个问题:用文件名作为标识符、使用大写字母、用下划线字符代替文件名中的点字符、用下划线字符做前缀或后缀(可能使用两条下划线)。
你也可以这样做。但是,由于标准保留使用下划线作为前缀,所以在自己的代码中不要这样写,避免与标准头文件中的宏发生冲突。
**3、#if 和 #elif 指令
#if 指令很像 C 语言中的 if。#if 后面跟整型常量表达式,如果表达式为非零,则表达式为真,可以在指令中使用 C 的关系运算符和逻辑运算符:
#if SYS == 1
#include "ibmpc.h"
#elif SYS == 2
#include "vax.h"
#elif SYS == 3
#include "mac.h"
#else
#include "general.h"
#endif
较新的编译器提供另一种方法测试名称是否已定义,即用 #if defined (VAX) 代替 #ifdef VAX。这里,defined 是一个预处理运算符,如果它的参数是用 #defined 定义过,则返回 1;否则返回 0。这种新方法的有点是,它可以和 #elif 一起使用。下面这种形式重写前面的示例:
#if defined (IBMPC)
#include "ibmpc.h"
#elif defined (VAX)
#include "vax.h"
#elif defined (MAC)
#include "mac.h"
#else
#include "general.h"
#endif
如果在 VAX 机上运行这几行代码,那么应该在文件前面用下面的代码定义 VAX:#define VAX
条件编译还有一个用途是让程序更容易移植。改变文件开头部分的几个关键的定义,即可根据不同的系统设置不同的值和包含不同的文件。
16.6.4 预定义宏
C 标准规定了一些预定义宏,如表。
| 宏 | 含义 |
|---|---|
__DATE__ |
预处理的日期(“Mmm dd yyyy” 形式的字符串字面量,如 Nov 23 2013 ) |
__ FILE__ |
表示当前源代码文件名的字符串字面量 |
__LINE__ |
表示当前源代码文件中行号的整型常量 |
__STDC__ |
设置为 1 时,表明实现遵循 C 标准 |
__STDC_HOSTED__ |
本机环境设置为 1;否则设置为 0 |
__STDC_VERSION__ |
支持 C99 标准,设置为 1999901L;支持 C11 标准,设置为 201112L |
__TIME__ |
翻译代码的时间,格式为 “hh:mm:ss” |
C99 标准提供一个名为 __func__ 的预定义标识符,它展开为一个代表函数名的字符串(该函数包含该标识符)。那么,__func__ 必须具有函数作用域,而从本质上看宏具有文件作用域。因此,__func__ 是 C 语言的预定义标识符,而不是预定义宏。
/* 使用预定义宏和预定义标识符 */
#include
void why_me();
int main(void)
{
printf("The file is %s.\n",__FILE__);
printf("The date is %s.\n",__DATE__);
printf("The time is %s.\n",__TIME__);
printf("The version is %ld.\n",__STDC_VERSION__);
printf("The is line %d.\n",__LINE__);
printf("The function is %s.\n",__func__);
why_me();
return 0;
}
void why_me()
{
printf("The function is %s.\n",__func__);
printf("The is line %d.\n",__LINE__);
}
下面是该程序的输出:
The file is D:\CProject\Demo1\Demo1.c.
The date is Jul 23 2019.
The time is 20:03:38.
The version is 201112.
The is line 11.
The function is main.
The function is why_me.
The is line 20.
16.6.5 #line 和 #error
#line 指令重置 __LINE__ 和 __FILE__ 宏报告的行号和文件名。可以这样使用 #line:
#line 1000 // 把当前行号重置为 1000
#line 10 "cool.c" // 把行号重置为 10,把文件名重置为 cool.c
#error 指令让处理器发出一条错误消息,该消息包含指令中的文本。如果可能的话,编译过程应该中断。可以这样使用 #error 指令:
#if __STDC_VERSION__ != 201112L
#error Not C11
#endif
如果编译器只支持旧标准,则会编译失败;如果支持 C11 标准,就能成功编译。
16.6.6 #pragma
在现在的编译器中,可以通过命令行参数或 IDE 菜单修改编译器的一些设置。#pragma 把编译器指令放入源代码中。例如,在开发 C99 时,标准被称为 C9X,可以使用下面的编译指示(pragma)让编译器支持 C9X:#pragma c9x on
一般而言,编译器都有自己的编译指示集。例如,编译指示可能用于控制分配给自动变量的内存量,或者设置错误检查的严格程度,或者启用非标准语言特性等。C99 标准提供了 3 个标准编译指示。
C99 还提供 _Pragma 预处理器运算符,该运算符把字符串转换成普通的编译指示。例如:_Pragma ("nonstandardtreatmenttypeB on") 等价于下面的指令:#pragma nonstandardtreatmenttypeB on 由于该运算符不适用 # 符号,所以可以把它作为宏展开的一部分:
#define PRAGMA(X) _Pragma(#X)
#define LIMRG(X) PRAGMA(STDC CX_LIMITED_PRANGE X)
然后,可以使用类似下面的代码:LIMRG( on ) 顺带一提,下面的定义看上去没问题,但实际上无法正常运行:#define LIMRG(X) PRAGMA(STDC CX_LIMITED_PRANGE #X)
问题在于这行代码依赖字符串的串联功能,而预处理过程完成之后才会串联字符串。
_Pragma 运算符完成 “解字符串”(destringizing)的工作,即把字符串中的转义序列转换成它所代表的字符。因此,_Pragma("use_bool \"true \"false") 变成了:#pragma use_bool "true "false
16.6.7 泛型选择(C11)
在程序设计中,泛型编程(generic programming)指那些没有特定类型,但是一旦指定一种类型,就可以转换成指定类型的代码。例如,C++ 在模板中可以创建泛型算法,然后编译器根据指定的类型自动使用实例化代码。C 没有这种功能。然而,C11 新增了一种表达式,叫作泛型选择表达式(generic selection expression),可根据表达式的类型(即表达式的类型是 int、double 还是其他类型)选择一个值。泛型选择表达式不是预处理器指令,但是在一些泛型编程中它常用作 #define 宏定义的一部分。
下面是一个泛型选择表达式的示例:_Generic(x, int: 0, float: 1, double: 2, default: 3)
_Generic 是 C11 的关键字。_Generic 后面的圆括号中包含多个用逗号分隔的项。第 1 个项是一个表达式,后面的每个项都由一个类型、一个冒号和一个值组成,如 float: 1。第 1 个项的类型匹配哪个标签,整个表达式的值是该标签后面的值。例如,假设上面表达式中 x 是 int 类型的变量,x 的类型匹配 int: 标签,那么整个表达式的值就是 0。如果没有与类型匹配的标签,表达式的值就是 default: 标签后面的值。泛型选择语句与 switch 语句类似,只是前者用表达式的类型匹配标签,而后者用表达式的值匹配标签。
下面是一个把泛型选择语句和宏定义组合的例子:
#define MYTYPE(X) _Generic((X),\
int: "int",\
float: "float",\
double: "double",\
default: "other"\
)
宏必须定义为一条逻辑行,但是可以用 \ 把一条逻辑行分隔成多条物理行。在这种情况下,对泛型选择表达式求值得字符串。例如,对 MYTYPE(5) 求值得 “int”,因为值 5 的类型为 int: 标签匹配。程序清单演示了这种用法。
#include
#define MYTYPE(X) _Generic((X),\
int: "int",\
float: "float",\
double: "double",\
default: "other"\
)
int main(void)
{
int d = 5;
printf("%s\n",MYTYPE(d)); // d 是 int 类型
printf("%s\n",MYTYPE(2.0 * d)); // 2.0 * d 是 double 类型
printf("%s\n",MYTYPE(3L)); // 3L 是 long 类型
printf("%s\n",MYTYPE(&d)); // &d 的类型是 int *
return 0;
}
下面是该程序的输出:
int
double
other
other
MYTYPE() 最后两个示例所用的类型与标签不匹配,所以打印默认的字符串。可以使用更多类型标签来扩展宏的能力,但是该程序主要是为了演示 _Generic 的基本工作原理。
对一个泛型选择表达求值时,程序不会先对第一个项求值,它只确定类型。只有匹配标签的类型后才会对表达式求值。
可以像使用独立类型(“泛型”)函数那样使用 _Generic 定义宏。
16.7 内联函数(C99)
通常,函数调用都有一定的开销,因为函数的调用过程包括建立调用、传递参数、跳转到函数代码并返回。使用宏使代码内联,可以避免这样的开销。C99 还提供另一种方法:内联函数(inline function)。读者可能顾名思义地认为内联函数会用内联代码替换函数调用。其实 C99 和 C11 标准中叙述的是:“把函数变成内联函数建议尽可能快地调用该函数,其具体效果由实现定义”。因此,把函数变成内联函数,编译器可能会用内联代码替换函数调用,并(或)执行一些其他的优化,但是也可能不起作用。
创建内联函数的定义有多种方法。标准规定具有内部链接的函数可以成为内联函数,还规定了内联函数的定义与调用该函数的代码必须在用一个文件中。因此,最简单的方法是使用函数说明符 inline 和存储类别说明符 static。通常,内联函数应定义在首次使用它的文件中,所以内联函数也相当于函数原型。如下所示:
#include
inline static void eatline() // 内联函数定义/原型
{
while(getchar() != '\n')
continue;
}
int main()
{
...
eatline(); // 函数调用
...
}
编译器查看内联函数的定义(也是原型),可能会用函数体中的代码替换 eatline() 函数调用。也就是说,效果相当于在函数调用的位置输入函数体中的代码:
#include
inline static void eatline() // 内联函数定义/原型
{
while(getchar() != '\n')
continue;
}
int main()
{
...
while(getchar() != '\n') // 替换函数调用
continue;
...
}
由于并未给内联函数预留单独的代码块,所以无法获得内联函数的地址(实际上可以获得地址,不过这样做之后,编译器会省农村一个非内联函数)。另外,内联函数无法在调试器中显示。
内联函数应该比较短小。把较长的函数变成内联并未节约多少时间,因为执行函数体的时间比调用函数的时间长得多。
编译器优化内联函数必须知道该函数定义的内容。这意味着内联函数定义与函数调用必须在同一个文件中。鉴于此,一般情况下内联函数都具有内部链接。因此,如果程序有多个文件都要使用某个内联函数,那么这些文件中都必须包含该内联函数的定义。最简单的做法是,把内联函数定义放入头文件,并在使用该内联函数的文件中包含该头文件即可。
#ifndef EATLINE_H_
#define EATLINE_H_
inline static void eatline()
{
while(getchar() != '\n')
continue;
}
#endif
一般都不在头文件中放置可执行代码,内联函数是个特例。因为内联函数具有内部链接,所以在多个文件中定义同一个内联函数不会产生什么问题。
与 C++ 不同的是,C 还允许混合使用内联函数定义和外部函数定义(具有外部链接的函数定义)。例如,一个程序中使用下面 3 个文件:
// file1.c
...inline static double square(double);
double square(double x) { return x * x; }
int main()
{
double q = square(1.3);
...
// file2.c
...
double square(double x) { return (int)(x * x); }
void spam(double v)
{
double kv = square(v);
...
// file3.c
...
inline double square(double x) { return (int)(x * x + 0.5); }
void masp(double w)
{
double kw = square(w);
...
如上述代码所示,3 个文件中都定义了 square() 函数。file1.c 文件中是 inline static 定义;file2.c 文件中是普通的函数定义(因此具有外部链接);file3.c 文件中是 inline 定义,省略了 static。
3 个文件中的函数都调用了 square() 函数,这会发生什么情况?file1.c 文件中的 main() 使用 square() 的局部 static 定义。由于该定义也是 inline 定义,所以编译器有可能优化代码,也许会内联该函数。file2.c 文件中,spam() 函数使用该文件中 square() 函数的定义,该定义具有外部链接,其他文件也可见。file3.c 文件中,编译器既可以使用该文件中 square() 函数的内联定义,也可以使用 file2.c 文件中的外部链接定义。如果像 file3.c 那样,省略 file1.c 文件 inline 定义中的 static,那么该 inline 定义被视为可替换的外部定义。
16.8 _Noreturn 函数(C11)
C99 新增 inline 关键字时,它是唯一的函数说明符(关键字 extern 和 static 是存储类别说明符,可应用于数据对象和函数)。C11 新增了第 2 个函数说明符 _Noreturn,表明调用完成后函数不返回主调函数。exit() 函数是 _Noreturn 函数的一个示例,一旦调用 exit(),它不会再返回主调函数。注意,这与 void 返回类型不同。void 类型的函数在执行完毕后返回主调函数,只是它不提供返回值。
_Noreturn 的目的是告诉用户和编译器,这个特殊的函数不会把控制返回主调程序。高数用户以免滥用该函数,通知编译器可优化一些代码。
16.9 C 库
最初,并没有官方的 C 库。后来,基于 UNIX 的 C 实现成为了标准。ANSI C 委员会主要以这个标准为基础,开发了一个官方的标准库。在意识到 C 语言的应用范围不断扩大后,该委员会重新定义了这个库使之可以应用于其他系统。
16.9.1 访问 C 库
如何访问 C 库取决于实现,因此你要了解当前系统的一般情况。首先,可以在多个不同哦的位置找到库函数。例如,getchar() 函数通常作为宏定义在 stdio.h 头文件中,而 strlen() 通常在库文件中。其次,不同的系统搜索这些函数的方法不同。下面介绍 3 种可能的方法。
1、自动访问
在一些系统中,只需编译程序,就可以使用一些常用的库函数。
记住,在使用函数之前必须先声明函数的类型,通过包含合适的头文件即可完成。在描述库函数的用户手册中,会指出使用某函数时应包含哪个头文件。但是在一些旧系统上,可能必须自己输入函数声明。再次提醒读者,用户手册中指明了函数类型。
2、文件包含
如果函数被定义为宏,那么可以通过 #include 指令包含定义宏函数的文件。通常,类似的宏都放在合适名称的头文件中。例如,许多系统都有 ctype.h 文件,该文件中包含了一些确定字符性质的宏。
3、库包含
在编译或链接程序的某些阶段,可能需要指定库选项。即使在自动检测标准库的系统中,也会有不常用的函数库。必须通过编译时选项显式指定这些库。注意,这个过程与包含头文件不同。头文件提供函数声明或原型,而库选项告诉系统到哪里查找函数代码。
16.10 数学库
数学库中包含许多有用的数学函数。math.h 头文件提供这些函数的原型。表列出了一些声明在 math.h 中的函数。注意,函数中涉及的角度都以弧度为单位( 1 弧度 = 180 / π = 57.296 度)。
| 原型 | 描述 |
|---|---|
double acos(double x) |
返回余弦值为 x 的角度( 0 ~ π 弧度) |
double asin(double x) |
返回正弦值为 x 的角度( -π/2 ~ π/2 弧度) |
double atan(double x) |
返回正切值为 x 的角度( -π/2 ~ π/2 弧度) |
double atan2(double y, double x) |
返回正弦值为 y/x 的角度( -π ~ π 弧度) |
double cos(double x) |
返回 x 的余弦值,x 的单位为弧度 |
double sin(double x) |
返回 x 的正弦值,x 的单位为弧度 |
double tan(double x) |
返回 x 的正切值,x 的单位为弧度 |
double exp(double x) |
返回 x 的指数函数的值( ex ) |
double log(double x) |
返回 x 的自然对数值 |
double log10(double x) |
返回 x 的以 10 为底的对数值 |
double pow(double x, double y) |
返回 x 的 y 次幂 |
double sqrt(double x) |
返回 x 的平方值 |
double cbrt(double x) |
返回 x 的立方值 |
double cell(double x) |
返回不小于 x 的最小整数值 |
double fabs(double x) |
返回 x 的绝对值 |
double floor(double x) |
返回不大于 x 的最大整数值 |
16.10.1 三角问题
数学库提供平方根函数和一对反正切函数,所以可以用 C 程序表示这个问题。平方根函数是 sqrt(),接受一个 double 类型的参数,并返回参数的平方根,也是 double 类型。
atan() 函数接受一个 double 类型的参数(即正切值),并返回一个角度(该角度的正切值就是参数值)。但是,当前的 x 值和 y 值均为 -5 时,atan() 函数产生混乱。因为 (-5) / (-5) 得 1,所以 atan() 返回 45°,该值与 x 和 y 均为 5 时的返回值相同。也就是说,atan() 无法区分角度相同但反向相反的线(实际上,atan() 返回值的单位是弧度而不是度)。
当然,C 库还提供了 atan2() 函数。它接受两个参数:x 的值和 y 的值。这样,通过检测 x 和 y 的正负号就可以得出正确的角度值。atan2() 和 atan() 均返回弧度值。把弧度转换为度,只需将弧度值乘以 180,再除以 pi 即可。pi 的值通过计算表达式 4 * atan(1) 得到。
/* 把直角坐标转换为极坐标 */
#include
#include
#define RAD_TO_DEG (180 / (4 * atan(1)))
typedef struct polar_v {
double magnitude;
double angle;
} Polar_v;
typedef struct rect_v {
double x;
double y;
} Rect_v;
Polar_v rect_to_polar(Rect_v);
int main(void)
{
Rect_v input;
Polar_v result;
puts("Enter x and y coordinates; enter q to quit:");
while(scanf("%lf %lf",&input.x,&input.y) == 2)
{
result = rect_to_polar(input);
printf("magnitude = %0.2f, angle = %0.2f\n",result.magnitude,result.angle);
}
puts("Bye.");
return 0;
}
Polar_v rect_to_polar(Rect_v rv)
{
Polar_v pv;
pv.magnitude = sqrt(rv.x * rv.x + rv.y * rv.y);
if(pv.magnitude == 0)
pv.angle = 0.0;
else
pv.angle = RAD_TO_DEG * atan2(rv.y,rv.x);
return pv;
}
下面是运行该程序的一个输出示例:
Enter x and y coordinates; enter q to quit:
10 10
magnitude = 14.14, angle = 45.00
-12 -5
magnitude = 13.00, angle = -157.38
q
Bye.
16.11 通用工具库
通用工具库包含各种函数,包括随机数生成器、查找和排序函数、转换函数和内存管理函数。在 ANSI C 标准中,这些函数的原型都在 stdlib.h 头文件中。
1、atexit() 函数
这个函数使用函数指针。要使用 atexit() 函数,只需把退出时要调用的函数地址传递给 atexit() 即可。函数名作为函数参数时相当于该函数的地址。然后,atexit() 注册函数列表中的函数,当调用 exit() 时就会执行这些函数。ANSI 保证,在这个列表中至少可以放 32 个函数。最后调用 exit() 函数时,exit() 会执行这些函数(执行顺序与列表中的函数顺序相反,即最后添加的函数最先执行)。
atexit() 注册的函数应该不带任何参数且返回类型为 void。通常,这些函数会执行一些清理任务,例如更新监视程序的文件或重置环境变量。
注意,即使没有显示调用 exit(),还是会调用。因为 main() 结束时会隐式调用 exit()。
2、exit() 函数
exit() 执行完 atexit() 指定的函数后,会完成一些清理工作:刷新所以输出流、关闭所有打开的流和关闭有标准 I/O 函数 tmpfile() 创建的临时文件。然后 exit() 把控制权返回主机环境,如果可能的话,向主机环境报告终止状态。通常,UNIX 程序使用 0 表示成功终止,用非零值表示终止失败。UNIX 返回的代码并不使用于所有的系统,所有 ANSI C 为了可移植性的要求,定义了一个名为 EXIT_FAILURE 的宏表示终止失败。类似地,ANSI C 还定义了 EXIT_SUCCESS 表示成功终止。不过,exit() 函数也接受 0 表示成功终止。在 ANSI C 中。在非递归的 main() 中使用 exit() 函数等价于使用关键字 return。尽管如此,在 main() 以外的函数中使用 exit() 也会终止整个程序。
3、qsort() 函数
快速排序算法在 C 实现中的名称是 qsort()。qsort() 函数排序数组的数据对象。其原型如下:void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
第 1 个参数是指针,指向待排序数组的首元素。ANSI C 允许把指向任何数据类型的指针强制转换成指向 void 的指针,因此,qsort() 的第 1 个实际参数可以引用任何类型的数组。
第 2 个参数是待排序项的数量。函数原型把该值转换为 size_t 类型。前面提到过,size_t 定义在标准头文件中,是 sizeof 运算符返回的整数类型。
由于 qsort() 把第 1 个参数转换为 void 指针,所以 qsort() 不知道数组中每个元素的大小。为此,函数原型用第 3 个参数补偿这一信息,显式指明待排序数组中每个元素的大小。例如,如果排序 double 类型的数组,那么第 3 个参数应该是 sizeof(double)。
最后,qsort() 还需要一个指向函数的指针,这个被指针指向的比较函数用于确定排序的顺序。该函数应接受两个参数:分别指向待比较两项的指针。如果第 1 项的值大于第 2 项,比较函数则返回正数;如果两项相同,则返回 0;如果第 1 项的值小于第 2 项,则返回负数。qsort() 根据给定的其他信息计算出两个指针的值,返回把它们传递给比较函数。
qsort() 原型中的第 4 个函数确定了比较函数的形式:int (*compar)(const void *, const void *) 这表明 qsort() 最后一个参数是一个指向函数的指针,该函数返回 int 类型的值且接受两个指向 const void 的指针作为参数,这两个指针指向待比较项。
/* 用 qsort() 排序一组数字 */
#include
#include
#define NUM 40
void fillarray(double ar[], int n);
void showarray(const double ar [], int n);
int mycomp(const void * p1, const void * p2);
int main(void)
{
double vals[NUM];
fillarray(vals,NUM);
puts("Random list:");
showarray(vals,NUM);
qsort(vals,NUM,sizeof(double),mycomp);
puts("\nSorted list:");
showarray(vals,NUM);
return 0;
}
void fillarray(double ar[], int n)
{
int index;
for(index = 0; index < n; index++)
ar[index] = (double)rand() / ((double)rand() + 0.1);
}
void showarray(const double ar [], int n)
{
int index;
for(index = 0; index < n; index++)
{
printf("%9.4f ",ar[index]);
if(index % 6 == 5)
putchar('\n');
}
if(index % 6 != 0)
putchar('\n');
}
/* 按从小到大的顺序排序 */
int mycomp(const void * p1, const void * p2)
{
/* 要使用指向 double 的指针来访问这两个值 */
const double * a1 = (const double *)p1;
const double * a2 = (const double *)p2;
if(*a1 < *a2)
return -1;
else if(*a1 == *a2)
return 0;
else
return 1;
}
下面是该程序的运行示例:
Random list:
0.0022 0.2390 1.2191 0.3910 1.1021 0.2027
1.3835 20.2830 0.2508 0.8880 2.2179 25.4866
0.0236 0.9308 0.9911 0.2507 1.2802 0.0939
0.9760 1.7217 1.2054 1.0326 3.7892 1.9635
4.1137 0.9241 0.9971 1.5582 0.8955 35.3798
4.0579 12.0460 0.0096 1.0109 0.8506 1.1529
2.3614 1.5876 0.4825 6.8749
Sorted list:
0.0022 0.0096 0.0236 0.0939 0.2027 0.2390
0.2507 0.2508 0.3910 0.4825 0.8506 0.8880
0.8955 0.9241 0.9308 0.9760 0.9911 0.9971
1.0109 1.0326 1.1021 1.1529 1.2054 1.2191
1.2802 1.3835 1.5582 1.5876 1.7217 1.9635
2.2179 2.3614 3.7892 4.0579 4.1137 6.8749
12.0460 20.2830 25.4866 35.3798
注意 C 和 C++ 中的 void*
C 和 C++ 对待指向 void 的指针有所不同。在这两种语言中,都可以把任何类型的指针赋给 void 类型的指针。但是,C++ 要求在把 void* 指针赋给任何类型的指针时必须进行强制类型转换。而 C 没有这样的要求。
16.12 断言库
assert.h 头文件支持的断言库是一个用于辅助调试程序的小型库。它由 assert() 宏组成,接受一个整型表达式作为参数。如果表达式求值为假(非零),assert() 宏就在标准错误流(stderr)中写入一条错误信息,并调用 abort() 函数终止程序( abort() 函数的原型在 stdlib.h 头文件中)。assert() 宏时为了标识出程序中某些条件为真的关键位置,如果其中的一个具体条件为假,就用 assert() 语句终止程序。通常,assert() 的参数是一个条件表达式或逻辑表达式。如果 assert() 中止了程序,它首先会显示失败的测试、包含测试的文件名和行号。
16.12.1 assert 的用法
/* 使用 assert() */
#include
#include
#include
int main(void)
{
double x, y, z;
puts("Enter a pair of numbers (0 0 to quit):");
while(scanf("%lf%lf",&x,&y) == 2 && (x != 0 || y != 0))
{
z = x * x - y * y;
assert(z >= 0);
printf("answer is %f\n",sqrt(z));
puts("Next pair of numbers: ");
}
puts("Done");
return 0;
}
下面是该程序的运行示例:
Enter a pair of numbers (0 0 to quit):
4 3
answer is 2.645751
Next pair of numbers:
5 3
answer is 4.000000
Next pair of numbers:
3 5
Assertion failed: z >= 0, file D:\CProject\Demo1\Demo1.c, line 14
使用 assert() 有几个好处:它不仅能自动标识文件和出问题的行号,还有一种无需更改代码就能开启或关闭 assert() 的机制。如果认为已经排除了程序的 bug,就可以把下面的宏定义写在包含 assert.h 的位置前面:#define NDEBUG 并重新编译程序,这样编译器就会禁用文件中的所有 assert() 语句。如果程序又出现问题,可以移除这条 #define 指令(或者把它注释掉),然后重新编译程序,这样就重新启用了 assert() 语句。
16.12.2 _Static_assert(C11)
assert() 表达式是在运行时进行检查。C11 新增了一个特性:_Static_assert 声明,可以在编译时检查 assert() 表达式。因此,assert() 可以导致正在运行的程序中止,而 _Static_assert() 可以导致程序无法通过编译。_Static_assert() 接受两个参数。第 1 个参数是整型常量表达式,第 2 个参数是一个字符串。如果第 1 个表达式求值Wie 0(或 _False),编译器会显示字符串,而且不编译该程序。看看程序清单,然后查看 assert() 和 _Static_assert() 的区别。
#include
#include
_Static_assert(CHAR_BIT == 16,"16-bit char falsely assumed");
int main(void)
{
puts("char is 16 bits.");
return 0;
}
下面为 Code Blocks 编译的示例:
D:\CProject\Demo1\Demo1.c|3|error: static assertion failed: “16-bit char falsely assumed”|
根据语法,_Static_assert() 被视为声明。因此,它可以出现在函数中,或者在这种情况下出现在函数外部。
_Static_assert 要求它的第 1 个参数是整型常量表达式,这保证了能在编译期求值(sizeof 表达式被视为整型常量)。不用 assert 代替 _Static_assert,因为 assert 中作为测试表达式的 z > 0 不是常量表达式,要到程序运行时才求值。当然,可以在程序清单的 main() 函数中使用 assert(CHAR_BIT == 16),但这会在编译和运行程序后才生成一条错误信息,很没效率。
16.13 string.h 库中的 memcpy() 和 memmove()
不能把一个数组赋给另一个数组,所以要通过循环把数组中的每个元素赋给另一个数组相应的元素。有一个例外的情况是:使用 strcpy() 和 strncpy() 函数来处理字符数组。memcpy() 和 memmove() 函数提供类似的方法处理任意类型的数组。下面是这两个函数的原型:
void *memcpy(void * restrict s1, const void * restrict s2, size_t n);
void *memmove(void *s1,const void *s2, size_t n);
这两个函数都从 s2 指向的位置拷贝 n 字节到 s1 指向的位置,而且都返回 s1 的值。所不同的是,memcpy() 的参数待关键字 restrict,即 memcpy() 假设两个内存区域之间没有重叠;而 memmove() 不作这样的假设,所以拷贝过程类似于先把所有字节拷贝到一个临时缓冲区,然后再拷贝到最终目的地。如果使用 memcpy() 时,两区域出现重叠会怎样?其行为是未定义的,这意味着该函数可能正常工作,也可能失败。编译器不会在本不该使用 memcpy() 时禁止你使用,作为程序员,在使用该函数时有责任确保两个区域不重叠。
由于这两个函数设计用于处理任何数据类型,所以它们的参数都是两个指向 void 的指针。C 允许把任何类型的指针赋给 void * 类型的指针。如此宽容导致函数无法知道待拷贝数据的类型。因此,这两个函数使用第 3 个参数指明待拷贝的字节数。注意,对数组而言,字节数一般与元素个数不同。如果要拷贝数组中的 10 个 double 类型的元素,要使用 10 * sizeof(double),而不是 10。
/* 使用 memcpy() 和 memmove() */
#include
#include
#include
#define SIZE 10
void show_array(const int ar[], int n);
/* 如果编译器不支持 C11的,可以注释掉下面这行 */
_Static_assert(sizeof(double) == 2 * sizeof(int),"double not twice int size");
int main(void)
{
int values[SIZE] = {1,2,3,4,5,6,7,8,9,10};
int target[SIZE];
double curious[SIZE / 2] = {2.0,2.0e5,2.0e10,2.0e20,5.0e30};
puts("memcpy() used:");
puts("values (original data): ");
show_array(values,SIZE);
memcpy(target,values,SIZE * sizeof(int));
puts("target (copy of values):");
show_array(target,SIZE);
puts("\nUsing memmove() with overlapping ranges:");
memmove(values + 2,values,5 * sizeof(int));
puts("values -- elements 0-4 copied to 2-6:");
show_array(values,SIZE);
puts("\nUsing memcpy() with overlapping ranges:");
memcpy(target,curious,(SIZE / 2) * sizeof(double));
puts("target -- 5 doubles into 10 int positions:");
show_array(target,SIZE / 2);
show_array(target + 5, SIZE / 2);
return 0;
}
void show_array(const int ar[], int n)
{
int i;
for(i = 0; i < n; i++)
printf("%d ",ar[i]);
putchar('\n');
}
下面是该程序的输出:
memcpy() used:
values (original data):
1 2 3 4 5 6 7 8 9 10
target (copy of values):
1 2 3 4 5 6 7 8 9 10
Using memmove() with overlapping ranges:
values – elements 0-4 copied to 2-6:
1 2 1 2 3 4 5 8 9 10
Using memcpy() with overlapping ranges:
target – 5 doubles into 10 int positions:
0 1073741824 0 1091070464 536870912
1108516959 2025163840 1143320349 -2012696540 1179618799
程序中最后一次调用 memcpy() 从 double 类型数组中把数据拷贝到 int 类型数组中,这演示了 memcpy() 函数不知道也不关心数据的类型,它只负责从一个位置把一些字节拷贝到另一个位置(例如,从结构中拷贝数据到字符数组中)。而且,拷贝过程中也不会进行数据转换。如果用循环对数组中的每个元素赋值,double 类型的值会在赋值过程被转换为 int 类型的值。这种情况下,按原样拷贝字节,然后程序把这些位组合解释成 int 类型。
16.14 可变参数:stdarg.h
本章前面提到过变参宏,即该宏可以接受可变数量的参数。stdarg.h 头文件为函数提供了一个类似的功能,但是用法比较复杂。必须按如下步骤进行:
- 提供一个使用省略号的函数原型;
- 在函数定义中创建一个 va_list 类型的变量;
- 用宏把该变量初始化为一个参数列表;
- 用宏访问参数列表;
- 用宏完成清理工作。
接下来详细分析这些步骤。这种函数的原型应该有一个形参列表,其中至少有一个形参和一个省略号:
void f1(int n, ...); // 有效
int f2(const char * s, int k, ...); // 有效
char f3(char c1, ..., char c2); // 无效,省略号不在最后
double f4(...); // 无效,没有形参
最右边的形参(即省略号的前一个形参)起着特殊的作用,标准中用 parmN 这个术语来描述该形参。在上面的例子中,第 1 行 f1() 中 parmN 为 n,第 2 行 f2() 中 parmN 为 k。传递给该形参的实际参数是省略号部分代表的参数数量。例如,可以这样使用前面声明的 f1() 函数:
f1(2,200,400); //2 个额外的参数
f1(4,13,117,18,23); // 4 个额外的参数
接下来,声明在 stdarg.h 中的 va_list 类型代表一种用于储存形参对应的形参列表中省略号部分的数据对象。变参函数的定义起始部分类似下面这样:
double sum(int lim, ...)
{
va_list ap; // 声明一个储存参数的对象
在该例中,lim 是 parmN 形参,它表明变参列表中参数的数量。
然后,该函数将使用定义在 stdarg.h 中的 va_start() 宏,把参数列表拷贝到 va_list 类型的变量中。该宏有两个参数:va_list 类型的变量和 parmN 形参。接着上面的例子讨论,va_list 类型的变量是 ap,parmN 形参是 lim。所以,应这样调用它:va_start(ap,lim); // 把 ap 初始化为参数列表
下一步是访问参数列表的内容,这涉及使用另一个宏 va_arg()。该宏接受两个参数:一个 va_list 类型的变量和一个类型名。第 1 次调用 va_arg() 时,它返回参数列表的第 1 项;第 2 次调用时返回第 2 项,以此类推。表示类型的参数指定了返回值的类型。例如,如果参数列表中的第 1 个参数是 double 类型,第 2 个参数是 int 类型,可以这样做:
double tic;
int toc;
tic = va_arg(ap,double); // 检索第 1 个参数
toc = va_arg(ap,int); // 检索第 2 个参数
注意,传入的参数类型必须与宏参数的类型相匹配。如果第 1 个参数是 10.0,上面 tic 那行待可以正常工作。但是如果参数是 10,这行代码可能会出错。这里不会像赋值那样把 double 类型自动转换成 int 类型。
最后,要使用 va_end() 宏完成清理工作。例如,释放动态分配用于储存参数的内存。该宏接受一个 va_list 类型的变量:va_end(ap); // 清理工作
调用 va_end(ap); 后,只有用 va_start 重新初始化 ap 后,才能使用变量 ap。
因为 va_arg() 不提供退回之前参数的方法,所以必要保存 va_list 类型变量的副本。C99 新增了一个宏用于处理这种情况:va_copy()。该宏接受两个 va_list 类型的变量作为参数,它把第 2 个参数拷贝给第 1 个参数:
va_list ap;
va_lsit apcopy;
double tic;
int toc;
va_start(ap,lim); // 把 ap 初始化为一个参数列表
va_copy(apcopy,ap); // 把 apcopy 作为 ap 的副本
tic = va_arg(ap,double); // 检索第 1 个参数
toc = va_arg(ap,int); // 检索第 2 个参数
此时,即使删除了 ap,也可以从 apcopy 中检索两个参数。
/* 使用 memcpy() 和 memmove() */
#include
#include
double sum(int, ...);
int main(void)
{
double s,t;
s = sum(3,1.1,2.5,13.3);
t = sum(6,1.1,2.1,13.1,4.1,5.1,6.1);
printf("return value for sum(3,1.1,2.5,13.3): %g\n",s);
printf("return value for sum(6,1.1,2.1,13.1,4.1,5.1,6.1): %g\n",t);
return 0;
}
double sum(int lim, ...)
{
va_list ap; // 声明一个对象储存参数
double tot = 0;
int i;
va_start(ap,lim); // 把 ap 初始化为参数列表
for(i = 0; i < lim; i++)
tot += va_arg(ap,double); // 访问参数列表中的每一项
va_end(ap); // 清理工作
return tot;
}
下面是该程序的输出:
return value for sum(3,1.1,2.5,13.3): 16.9
return value for sum(6,1.1,2.1,13.1,4.1,5.1,6.1): 31.6
查看程序中的运算可以发现,第 1 次调用 sum() 时对 3 个数求和,第 2 次调用时对 6 个数求和。
总而言之,使用变参函数比使用变参宏更复杂,但是函数的应用范围更广。
16.15 关键概念
C 标准不仅描述 C 语言,还描述了组成 C 语言的软件包、C 预处理器和 C 标准库。通过预处理器可以控制编译过程、列出要替换的内容、指明要编译的代码行和影响编译器其他地方的行为。C 库扩展了 C 语言的作用范围,为许多编程问题提供现成的解决方案。
16.16 本章小结
C 预处理器和 C 库是 C 语言的两个重要的附件。C 预处理遵循预处理器指令,在编译源代码之前调整代码。C 库提供许多有助于完成各种任务的函数,包括输入、输出、文件处理、内存管理、排序与搜索、数学运算、字符串处理等。
16.17 复习题
1、下面的机组代码有一个或多个宏组成,其后是使用宏的源代码。在每种情况下代码的结构是什么?这些代码是否是有效代码?(假设其中的变量已声明)
a、
#define FPM 5280 /* 每英里的英尺数 */
dist = FPM * miles;
b、
#define FEET 4
#define POD FEET + FEET
plort = FEET * POD;
c、
#define SIX = 6;
nex = SIX;
d、
#define NEW(X) X + 5
y = NEW(y);
berg = NEW(berg) / NEW(y);
nilp = lob * NEW(-berg);
2、修改复习题 1 中 d 部分的定义,使其更可靠。
3、定义一个宏函数,返回两值中的较小值。
4、定义 EVEN_GT(X, Y) 宏,如果 X 为偶数且大于 Y,该宏返回 1.
5、定义一个宏函数,打印两个表达式及其值。例如,若参数为 3 + 4 和 4 * 12,则打印:3+4 id 7 and 4+12 id 48。
6、创建 #define 指令完成下面的任务。
a、创建一个值为 25 的命令常量。
b、SPACE 表示空格字符。
c、PS() 代表打印空格字符。
d、BIG(X) 代表 X 的值加 3。
e、SUMSQ(X, Y) 代表 X 和 Y 的平方和。
7、定义一个宏,以下面的格式打印名称、值和 int 类型变量的地址:name: fop; value: 23; address: ff464016。
8、假设在测试程序时要暂时跳过一块代码,如果在不移除这块待的前提下完成这项任务?
9、编写一段代码,如果定义了 PR_DATE 宏,则打印预处理的日期。
10、内联函数部分讨论了 3 种不同版本的 square() 函数。从行为方面看,这 3 中版本的函数有何不同?
11、创建一个使用泛型选择表达式的宏,如果宏参数是 _Bool 类型,对 “boolean” 求值,否则对 “not boolean” 求值。
12、下面的程序有什么错误?
#include
int main(int argc, char argv[])
{
printf("The square root of %f is %f\n", argv[1],sqrt(argv[1]));
}
13、假设 scores 是内含 1000 个 int 类型元素的数组,要按降序排列该数组中的值。假设你使用 qsort() 和 comp() 比较函数。
a、如何正确调用 qsort()?
b、如何正确定义 comp()?
14、假设 data1 是内含 100 个 double 类型元素的数组,data2 是内含 300 个 double 类型元素的数组。
a、编写 memcpy() 的函数调用,把 data2 中的前 100 个元素拷贝到 data1 中。
b、编写 memcpy() 的函数调用,把 data2 中的后 100 个元素拷贝到 data1 中。
16.18 编程练习
1、开发一个包含你需要的预处理器定义的头文件。
2、两数的调和平均数这样计算:先得到两数的倒数,然后计算两个倒数的平均值,最后取计算结果的倒数。使用 #define 指令定义一个宏 “函数”,指向该运算。编写一个简单的程序测试该宏。
3、极坐标用向量的模(即向量的长度)和向量相对 x 轴逆时针旋转的角度来描述该向量。直角坐标用向量的 x 轴和 y 轴的坐标来描述该向量。编写一个程序,读取向量的模和角度(单位;度),然后显示 x 轴和 y 轴的坐标。相关方程如下:x = r * cos(A);y = r * sin(A)
需要一个函数来完成转换,该函数接受一个包含极坐标的结构,并返回一个包含直角坐标的结构(或返回指向该结构的指针)。
4、ANSI 库这样描述 clock() 函数的特性:
#include
clock_t clock(void);
这里,clock_t 是定义在 time.h 中的类型。该函数返回处理器时间,其单位取决于实现(如果处理器时间不可用或无法表示,该函数将返回 -1)。然而,CLOCKS_PER_SEC(也定义在 time.h 中)是每秒处理器时间单位的数量。因此,两个 clock() 返回值的差值除以 CLOCKS_PER_SEC 得到两次调用之间经过的秒数。在进行除法运算之前,把值的烈性强制转换成 double 类型,可以将时间精确到小数点以后。编写一个函数,接受一个 double 类型的参数表示时间延迟数,然后在这段时间运行一个循环。编写一个简单的程序测试该函数。
5、编写一个函数接受这些参数:内含 int 类型元素的数组名、数组的大小和一个代表选区次数的值。该函数从数组中随机选择指定数量的元素,并打印它们。每个元素只能选择一次(迷你抽奖数字或挑选陪审团成员)。另外,如果你的实现由 time()或类似的函数,可在 srand() 中国石油这个函数的输出来初始化随机数生成器 rand()。编写一个简单的程序测试该函数。
6、修改程序清单,使用 struct names 元素,而不是 double 类型的数组。使用较少的元素,并用选定的名字显式初始化数组。
/* 用 qsort() 排序一组数字 */
#include
#include
#define NUM 40
void fillarray(double ar[], int n);
void showarray(const double ar [], int n);
int mycomp(const void * p1, const void * p2);
int main(void)
{
double vals[NUM];
fillarray(vals,NUM);
puts("Random list:");
showarray(vals,NUM);
qsort(vals,NUM,sizeof(double),mycomp);
puts("\nSorted list:");
showarray(vals,NUM);
return 0;
}
void fillarray(double ar[], int n)
{
int index;
for(index = 0; index < n; index++)
ar[index] = (double)rand() / ((double)rand() + 0.1);
}
void showarray(const double ar [], int n)
{
int index;
for(index = 0; index < n; index++)
{
printf("%9.4f ",ar[index]);
if(index % 6 == 5)
putchar('\n');
}
if(index % 6 != 0)
putchar('\n');
}
/* 按从小到大的顺序排序 */
int mycomp(const void * p1, const void * p2)
{
/* 要使用指向 double 的指针来访问这两个值 */
const double * a1 = (const double *)p1;
const double * a2 = (const double *)p2;
if(*a1 < *a2)
return -1;
else if(*a1 == *a2)
return 0;
else
return 1;
}
7、下面是变参函数的一个程序段:
#include
#include
#include
void show_array(const double ar[], int n);
double * new_d_array(int n, ...);
int main()
{
double *p1;
double *p2;
p1 = new_d_array(5,1.2,2.3,3.4,4.5,5.6);
p2 = new_d_array(4,100.0,20.00,8.08,-1890.0);
show_array(p1,5);
show_array(p2,4);
free(p1);
free(p2);
return 0;
}
new_d_array() 函数接受一个 int 类型的参数和 double 类型的参数。该函数返回一个指针,指向有 malloc() 分配的内存块。int 类型的参数指定了动态数组中的元素个数,double 类型的值用于初始化元素。编写 show_array() 和 new_d_array() 函数的代码,完成这个程序。