第十七章 高级数据表示
文章目录
- 17.1 从数组到链表
- 17.1.1 使用链表
- 17.1.2 反思
- 17.2 抽象数据类型(ADT)
- 17.2.1 建立抽象
- 17.2.2 建立接口
- 17.2.3 使用接口
- 17.2.4 实现接口
- 提示 const 的限制
- 17.3 队列 ADT
- 17.3.1 定义队列抽象数据类型
- 17.3.2 定义一个接口
- 17.3.3 实现接口数据表示
- 17.3.4 测试队列
- 17.4 链表和数组
- 17.5 二叉查找树
- 17.5.1 二叉树 ADT
- 17.5.2 二叉查找树接口
- 17.5.3 树的思想
- 17.6 其他说明
- 17.7 关键概念
- 17.8 本章小结
- 17.9 复习题
- 17.10 编程练习
17.1 从数组到链表
理想的情况是,用户可以不确定地添加数据(或者不断添加数据直到用完内存量),而不是先指定要输入多少项,也不用让程序分配多余的空间。这可以通过在输入每一项后调用 malloc() 分配正好能储存该项的空间。如果用户输入 3 部影片,程序就调用 malloc() 3 次;如果用户输入 300 部影片,程序就调用 malloc() 300 次。
不过,我们又制造了另一个麻烦。比较一下,一种方法是调用 malloc() 一次,为 300 个 filem 结构请求分配足够的空间;另一种方法是调用 malloc() 300 次,分别为每个 file 结构请求分配足够的空间。前者分配的是连续的内存块,只需要一个单独的指向 struct 变量(film)的指针,该指针指向已分配块中的第 1 个结构。简单的数组表示法让指针访问块中的每个结构,如前面的代码段所示。第 2 种方法的问题是,无法保证每次调用 malloc() 都能分配到连续的内存块。这意味着结构不一定被连续储存。因此,与第 1 种方法储存一个指向 300 个结构块的指针相比,你需要储存 300 个指针,每个指针指向一个单独储存的结构。

一种解决方法是创建一个大型的指针数组,并在分配新结构时逐个给这些指针赋值,但是我们不打算使用这种方法:
#define TSIZE 45 /* 储存片名的数组大小 */
#define FMAX 500 /* 影片的最大数量 */
struct film {
char title[TSIZE];
int rating;
};
...
struct film * movies[FMAX]; /* 结构指针数组 */
int i;
...
movies[i] = ( struct film * )malloc(sizeof(struct film));
如果用不完 500 个指针,这种方法节约了大量的内存,因为内含 500 个指针的数组比内含 500 个结构的数组所占的内存少得多。尽管如此,如果用不到 500 个指针,还是浪费了不少空间。而且,这样还是有 500 个结构的限制。
还有一种更好的方法。每次使用 malloc() 为新结构分配空间时,也为新指针分配空间。但是,还得需要另一个指针来跟踪新分配的指针,用于跟踪新指针的指针本身,也需要一个指针来跟踪,以此类推。要重新定义结构才能解决这个潜在的问题,即每个结构中包含指向 next 结构的指针。然后,当创建新结构时,可以把该结构的地址储存在上一个结构中。简而言之,可以这样定义 film 结构:
#define TSIZE 45 /* 储存片名的数组大小 */
struct film {
char title[TSIZE];
int rating;
struct film * next;
};
虽然结构不能含有与本身类型相同的结构,但是可以含有指向同类型结构的指针。这种定义是定义链表(linked list)的基础,链表中的每一项都包含着在何处能找到下一项的信息。
在学习链表的代码之前,我们先从概念上理解一个链表。假设用户输入的片名是 Modern Times,等级为 10。程序将为 film 类型的结构分配空间,把字符串 Modern Times 拷贝到结构中的 title 成员中,然后设置 rating 成员为 10。为了表明该结构后面没有其他结构,程序要把 next 成员指针设置为 NULL(NULL 是一个定义在 stdio.h 头文件中的符号常量,表示空指针)。当然,还需要一个单独的指针储存第 1 个结构的地址,该指针被称为头指针(head pointer)。头指针指向链表中的第 1 项。下图演示了这种结构。

现在,假设用户输入第 2 部电影及其评级,如 Midnight in Paris 和 8。程序为第 2 个 film 类型结构分配空间,把新结构的地址储存在第 1 个结构的 next 成员中(擦写了之前储存在该成员中的 NULL),这样链表中第 1 个结构中的 next 指针指向第 2 个结构。然后程序把 Midnight in Paris 和 8 拷贝到新结构中,并把第 2 个结构中的 next 成员设置为 NULL,表明该结构是链表中的最后一个结构。下图演示了这两个项。

每加入一部新电影,就以相同的方式来处理。新结构的地址将储存在上一个结构中,新信息储存在新结构中,而且新结构中的 next 成员设置为 NULL。从而建立起如下图的链表。

假设要显示这个链表,每显示一项,就可以根据该项中已储存的地址来定位下一个待显示的项。然而,这种方案能正常运行,还需要一个指针储存链表中第 1 项的地址,因为链表中没有其他储存该项的地址。此时,头指针就派上了用场。
17.1.1 使用链表
从概念上了解了链表的工作原理,接着我们来实现它。程序清单用链表来储存电影信息。
/* 使用结构链表 */
#include
#include /* 提供 malloc() 原型 */
#include /* 提供 strcpy() 原型 */
#define TSIZE 45 /* 储存片名的数组大小 */
struct film {
char title[TSIZE];
int rating;
struct film * next; /*指向链表中的下一结构 */
};
char * s_gets(char * st, int n);
int main(void)
{
struct film * head = NULL;
struct film * prev, * current;
char input[TSIZE];
/* 收集并储存信息 */
puts("Enter first movie title:");
while(s_gets(input,TSIZE) != NULL && input[0] != '\0')
{
current = (struct film *)malloc(sizeof(struct film));
if(head == NULL) /* 第 1 个结构 */
head = current;
else /* 后续的结构 */
prev->next = current;
current->next = NULL;
strcpy(current->title,input);
puts("Enter your rating <0 - 10>:");
scanf("%d",¤t->rating);
while(getchar() != '\n')
continue;
puts("Enter next movie title (empty line to stop):");
prev = current;
}
/* 显示电影列表 */
if(head == NULL)
printf("No data entered.\n");
else
printf("Here is the movie list:\n");
current = head;
while(current != NULL)
{
printf("Movie: %s Rating: %d\n",current->title,current->rating);
current = current->next;
}
/* 完成任务,释放已分配的内存 */
current = head;
while(current != NULL)
{
head = current->next;
free(current);
current = head;
}
printf("Bye!\n");
return 0;
}
char * s_gets(char * st, int n)
{
char * ret_val;
char * find;
ret_val = fgets(st,n,stdin);
if(ret_val)
{
find = strchr(st,'\n'); // 查找换行符
if(find) // 如果地址不是 NULL
*find = '\0'; // 在此处放置一个空字符
else
while(getchar() != '\n') // 处理剩余输入行
continue;
}
return ret_val;
}
该程序用链表执行两个任务。第 1 个任务是,构造一个链表,把用户输入的数据储存在链表中。第 2 个任务是,显示链表。显示链表的任务比较简单,所以我们先来讨论它。
1、显示链表
显示链表从设置一个指向第 1 个结构的指针(名为 current)开始。由于头指针(名为 head)已经指向链表中的第 1 个结构,所以可以用下面的代码来完成:current = head; 然后,可以使用指针表示法访问结构的成员:printf("Movie: %s Rating: %d\n",current->title,current->rating);
下一步是根据储存在该结构中 next 成员中的信息,重新设置 current 指针指向链表中的下一个结构。代码如下:current = current->next;
完成这些之后,在重复整个过程。当显示到链表中最后一个项时,current 将被设置为 NULL,因为这是链表最后一个结构中 next 成员的值。
while(current != NULL)
{
printf("Movie: %s Rating: %d\n",current->title,current->rating);
current = current->next;
}
遍历链表时,为何不直接使用 head 指针,而要重新创建一个新指针(current)?因为如果使用 head 会改变 head 中的值,程序就找不到链表的开始处。
2、创建链表
创建链表设计下面 3 步:
1、使用 malloc() 为结构分配足够的空间;
2、储存结构的地址;
3、把当前信息拷贝到结构中。
如无必要不用创建一个结构,所以程序使用临时存储区(input 数组)获取用户输入的电影名。如果用户通过键盘模拟 EOF 或输入一行空行,将退出下面的循环:while(s_gets(input,TSIZE) != NULL && input[0] != '\0') 如果用户进行输入,程序就分配一个结构的空间,并将其地址赋给指针变量 current:current = (struct film *)malloc(sizeof(struct film));
链表中第 1 个结构的地址应储存在指针变量 head 中。随后每个结构的地址应储存在其前一个结构的 next 成员中。因此,程序要知道它处理的是否是第 1 个结构。最简单的方法是在程序开始时,把 head 指针初始化为 NULL。然后,程序可以使用 head 的值进行判断:
if(head == NULL) /* 第 1 个结构 */
head = current;
else /* 后续的结构 */
prev->next = current;
在上面的代码中,指针 prev 指向上一次分配的结构。
接下来,必须为结构成员设置合适的值。尤其是,把 next 成员设置为 NULL,表明当前结构是链表的最后一个结构。还有把 input 数组中的电影名拷贝到 title 成员中,而且要给 rating 成员提供一个值。如下代码所示:
current->next = NULL;
strcpy(current->title,input);
puts("Enter your rating <0 - 10>:");
scanf("%d",¤t->rating);
由于 s_gets() 限制了只能输入 TSIZE - 1 个字符,所以用 strcpy() 函数把 input 数组中的字符串拷贝到 title 成员很安全。
最后,要为下一次输入做好准备。尤其是,要设置 prev 指向当前结构。因为在用户输入下一部电影且程序为新结构分配空间后,当前结构将成为新结构的上一个结构,所以程序在循环末尾这样设置该指针:prev = current;
程序是否能正常运行?下面是该程序的一个运行示例:
Enter first movie title:
Spirited Away
Enter your rating <0 - 10>:
9
Enter next movie title (empty line to stop):
The Duelists
Enter your rating <0 - 10>:
8
Enter next movie title (empty line to stop):
Devil Dog: The Mound of Hound
Enter your rating <0 - 10>:
1
Enter next movie title (empty line to stop):
Here is the movie list:
Movie: Spirited Away Rating: 9
Movie: The Duelists Rating: 8
Movie: Devil Dog: The Mound of Hound Rating: 1
Bye!
3、释放链表
在许多环境中,程序结束时都会自动释放 malloc() 分配的内存。但是,最后还是成对调用 malloc() 和 free()。因此,程序在清理内存时为每个已分配的结构都调用了 free() 函数:
current = head;
while(current != NULL)
{
head = current->next;
free(current);
current = head;
}
17.1.2 反思
程序还有些不足。例如,程序没有检查 malloc() 是否成功请求到内存,也无法删除链表中的项。这些不足可以弥补。例如,添加代码检查 malloc() 的返回值是否是 NULL(返回 NULL 说明未获得所需内存)。如果程序要删除链表中的项,还要编写更多的代码。
这种用特定方法解决特定问题,并且在需要时才添加相关功能的编程方式通常不是最后的解决方案。另一方面,通常都无法预料程序要完成的所有任务。随着编程项目越来越大,一个程序员或编程团队事先计划好一切模式,越来越不现实。很多成功的大型程序都是由成功的小型程序逐步发展而来。
如果要修改程序,首先应该强调最初的设计,并简化其他细节。程序示例没有遵循这个原则,它把概念模型和代码细节混在一起。例如,该程序的概念模型在一个链表中添加项,但是程序却把一些细节放在最明显的位置,没有突出接口。如果程序能以某种方式强调给链表添加项,并隐藏具体的处理细节会更好。把用户接口和代码细节分开的程序,更容易理解和更新。
17.2 抽象数据类型(ADT)
在编程时,应该根据编程问题匹配合适的数据类型。例如,用 int 类型代表你有多少双鞋,用 float 或 double 类型代表每双鞋的价格。在前面的电影示例中,数据构成了链表,每个链表项由电影名(C 字符串)和评级(一个 int 类型值)。C 中没有与之匹配的基本类型,所以我们定义了一个结构代表单独的项,然后设计了一些方法把一系列结构构成一个链表。本质上,我们使用 C 语言的功能设计了一种符合程序要求的新数据类型。但是,我们的做法并不系统。现在,我们用更系统的方法来定义数据类型。
什么是类型?类型特指两类信息:属性和操作。例如,int 类型的属性是它代表一个整数值,因此它共享整数的属性。允许对 int 类型进行算术操作时:改变 int 类型值的符号、两个 int 类型值相加、相减、相乘、相除、求模。当声明一个 int 类型的变量时,就表明了只能对该变量进行这些操作。
假设要定义一个新的数据类型。首先,必须提供储存数据的方法,例如设计一个结构。其次,必须提供操控数据的方法。
计算机科学领域已开发了一种定义新类型的好方法,用 3 个步骤完成从抽象到具体的过程。
1、提供类型属性和相关操作的抽象描述。这些描述既不能依赖特定的实现,也不能依赖特定的编程语言。这种正式的抽象描述被称为抽象数据类型(ADT)。
2、开发一个实现 ADT 的编程接口。也就是说,指明如何储存数据和执行所需操作的函数。例如在 C 中,可以提供结构定义和操控该结构的函数原型。这些作用于用户定义类型的函数相当于作用于 C 基于类型的内置运算符。需要使用该新类型的程序员可以使用这个接口进行编程。
3、编写代码实现接口。这一步至关重要,但是使用该新类型的程序员无需了解具体的实现细节。
17.2.1 建立抽象
从根本上看,电影项目所需的是一个项链表。每一项包含电影名和评级。你所需要的操作时把新项添加到链表的末尾和显示链表中的内容。我们把需要处理这些需求的抽象类型叫作链表。链表具有哪些属性?首先,链表应该能储存一系列的项。也就是说,链表能储存多个项,而且这些项以某种方式排列,这样才能描述链表的第 1 项、第 2 项或最后一项。其次,链表类型应该提供一些操作,如在链表中添加新项。下面是链表的一些有用的操作:
- 初始化一个空链表;
- 在链表末尾添加一个新项;
- 确定链表是否为空;
- 确定链表是否已满;
- 确定链表中的项数;
- 访问链表中的每一项执行某些操作,如显示该项。在链表的任意位置插入一个项;
- 移除链表中的一个项;
- 在链表中检索一个项(不改变链表);
- 用另一个项替换链表中的一个项;
- 在链表中搜索一个项。
非正式但抽象的链表定义是:链表是一个能储存一系列项且可以对其进行所需操作的数据对象。该定义既未说明链表中可以储存什么项,也未指定是用数组、结构还是其他数据形式来储存项,而且并未规定用什么方法来实现操作。这些细节都留给实现完成。
为了让示例尽量简单,我们采用一种简化的链表作为抽象数据类型。它只包含电影项目中的所需属性。该类型总结如下:
类型名:简单链表
类型属性;可以储存一系列项
类型操作:初始化链表为空、确定链表为空、确定链表已满、确定链表中的项数、在链表末尾添加项、遍历链表,处理链表中的项、清空链表。
17.2.2 建立接口
这个简单链表的接口有两个部分。第 1 部分是描述如何表示数据,第 2 部分是描述实现 ADT 操作的函数。例如,要设计在链表中添加项的函数和报告链表中项数的函数。接口设计应尽量与 ADT 的描述保存一致。因此,应该用某种通用的 Item 类型而不是一些特使类型,如 int 或 struct film。可以用 C 的 typedef 功能来定义所需的 Item 类型:
#define TSIZE 45
struct file {
char title[TSIZE];
int rating;
};
typedef struct film Item;
然后,就可以在定义的其余部分使用 Item 类型。如果以后需要其他数据形式的链表,可以重新定义 Item 类型,不必更改其余的接口定义。
定义了 Item 之后,现在必须确定如何储存这种类型的项。实际上这一步属于实现步骤,但是现在决定好可以让示例更简单些。
typedef struct node {
Item item;
struct node * next;
} Node;
typedef Node * List;
在链表的实现中,每一个链节叫作节点(node)。每个节点包含形成链表内容的信息和指向下一个节点的指针。为了强调这个术语,我们把 node 作为节点结构的标记名,并使用 typedef 把 Node 作为 struct node 结构的类型名。最后,为了管理链表,还需要一个指向链表开始处的指针,我们使用 typedef 把 List 作为该类型的指针名。因此,下面的声明:List movies; 创建了该链表所需类型的指针 movies。
这是否是定义 List 类型的唯一方法?不是,例如,还可以添加一个变量记录项数:
typedef struct list {
Node * head; /* 指向链表头的指针 */
int size; /* 链表中的项数 */
} List; /* List 的另一种定义 */
可以像稍后的程序示例中那样,添加第 2 个指针储存链表的末尾。现在,我们还是使用 List 类型的第 1 种定义。这里要着重理解下面的声明创建了一个链表,而不是一个指向节点的指针或一个结构:List movies; movies 代表的确切数据应该是接口层次不可见的实现细节。
例如,程序启动后应把头指针初始化为 NULL。但是,不要使用下面这样的代码:movies = NULL;
为什么?因为稍后你会发现 List 类型的结构实现更好,所以应这样初始化:
movies.next = NULL;
movies.size = 0;
使用 List 的人都不用担心这些细节,只要能使用下面的代码就行:InitializeList(movies); 使用该类型的程序员只需知道用 InitializeList() 函数来初始化链表,不必了解 List 类型变量的实现细节。这是数据隐藏的一个示例,数据隐藏是一种从编程的更高层次隐藏数据表示细节的艺术。
为了指导用户使用,可以在函数原型前面提供一下注释:
/* 操作:初始化一个链表 */
/* 前提条件:plist 指向一个链表 */
/* 后置条件:该链表初始化为空 */
void InitializeList(List * plist);
这里要注意 3 点。第 1,注释中的 “前提条件(precondition)” 是调用该函数前应具备的条件。例如,需要一个带初始化的链表。第 2,注释中的 “后置条件(postcondition)” 是执行完该函数后的情况。第 3,该函数的参数是一个指向链表的指针,而不是一个链表。所以应该这样调用该函数:InitializeList(&movies);
由于按值传递参数,所以该函数只能通过指向该变量的指针才能更改主调程序传入的变量。这里,由于语言的限制使得接口和抽象描述略有区别。
C 语言把所有类型和函数的信息集合成一个软件包的方法是:把类型定义和函数原型(包括前提条件和后置条件注释)放在一个头文件中。该文件应该提供程序程序员使用该类型所需的所有信息。程序清单给出了一个简单链表类型的头文件。该程序定义了一个特定的结构作为 Item 类型,然后根据 Item 定义了 Node,再根据 Node 定义了 List。然后,把表示链表操作的函数设计为接受 Item 类型和 List 类型的参数。如果函数要修改一个参数,那么该参数的类型应该是指向相应类型的指针,而不是该类型。在头文件中,把组成函数名的每个单词的首字母大写,以这种方式表明这些函数是接口包的一部分。另外,该文件使用第 16 章介绍的 #ifndef 指令,防止多次包含一个文件。
/* list.h -- 简单链表类型的头文件 */
#ifndef LIST_H_
#define LIST_H_
#include /* C99 特性 */
/* 特定程序的声明 */
#define TSIZE 45 /* 储存电影名的数组大小 */
struct film {
char title[TSIZE];
int rating;
};
/* 一般类型定义 */
typedef struct film Item;
typedef struct node {
Item item;
struct node * next;
} Node;
typedef Node * List;
/* 函数原型 */
/* 操作: 初始化一个链表 */
/* 前提条件:plist 指向一个链表 */
/* 后置条件:链表初始化为空 */
void InitializeList(List * plist);
/* 操作:确定链表是否为空定义,plist 指向一个已初始化的链表 */
/* 后置条件:如果链表为空,该函数返回 true;否则返回 false */
bool ListIsEmpty(const List *plist);
/* 操作:确定链表是否已满,plist 指向一个已初始化的链表 */
/* 后置条件:如果链表已满,该函数返回真;否者返回假 */
bool ListIsFull(const List *plist);
/* 操作:确定链表中的项数,plist 指向一个已初始化的链表 */
/* 后置条件:该函数返回链表中的项数 */
unsigned int ListItemCount(const List *plist);
/* 操作:在链表的末尾添加项 */
/* 前提条件:item 是一个待添加至链表的项,plist 指向一个已初始化的链表 */
/* 后置条件:如果可以,该函数在链表末尾添加一个项,且返回 true;否则返回 false */
bool AddItem(Item item, List *plist);
/* 操作:把函数作用于链表中的每一项 */
/* plist 指向一个已初始化的链表 */
/* pfun 指向一个函数,该函数接受一个 Item 类型的参数,且无返回值 */
/* 后置条件:pfun 指向的函数作用域链表中的每一项一次 */
void Traverse(const List *plist, void(*pfun)(Item item));
/* 操作:释放已分配的内存(如果有的话)*/
/* plist 指向一个已初始化的链表 */
/* 后置条件:释放了为链表分配的所有内存,链表设置为空 */
void EmptyTheList(List *plist);
#endif
只有 InitializeList()、AddItem() 和 EmptyTheList() 函数要修改链表,因此从技术角度看,这些函数需要一个指针参数。然而,如果某些函数接受 List 类型的变量作为参数,而其他函数却接受 List 类型的地址作为参数,用户会很困惑。因此,为了减轻用户的负担,所以的函数均使用指针参数。
头文件中的一个函数原型比其他原型复杂:
/* 操作:把函数作用于链表中的每一项 */
/* plist 指向一个已初始化的链表 */
/* pfun 指向一个函数,该函数接受一个 Item 类型的参数,且无返回值 */
/* 后置条件:pfun 指向的函数作用域链表中的每一项一次 */
void Traverse(const List *plist, void(*pfun)(Item item));
参数 pfun 是一个指向函数的指针,它指向的函数接受 item 值且无返回值。第 14 章中介绍过,可以把函数指针作为参数传递另一个函数,然后该函数就可以使用这个被指针指向的函数。例如,该例中可以让 pfun 指向显示链表项的函数。然后把 Traverse() 函数把该函数作用于链表中的每一项,显示链表中的内存。
17.2.3 使用接口
我们的目标是,使用这个接口编写程序,但是不必知道具体的实现细节(如,不知道函数的实现细节)。
在编写具体函数之前,我们先编写电影程序的一个新版本。由于接口要使用 List 和 Item 类型,所以该程序也应使用这些类型。下面是编写该程序的一个伪代码方案。
1、创建一个 List 类型的变量。
2、创建一个 Item 类型的变量。
3、初始化链表为空。
4、当链表未满且有输入时:把输入读取到 Item 类型的变量中;在链表末尾添加项。
5、访问链表中的每个项并显示他们。
程序清单中的程序按照以上伪代码来编写,其中还加入了一些错误检查,注意该程序利用了 list.h 中描述的接口。另外,还需注意,链表中含有 showmovies() 函数的代码,它与 Traverse() 的原型一致。因此,程序可以把指针 showmovies 传递给 Traverse(),这样 Traverse() 可以把 showmovies() 函数应用于链表中的每一项。
/* films3.c -- 使用抽象数据类型(ADT)风格的链表 */
/* 与 list.c 一起编译 */
#include
#include
#include "list.h"
void showmovies(Item item);
char * s_gets(char *st, int n);
int main(int argc,char *argv[])
{
List movies;
Item temp;
InitializeList(&movies);
if(ListIsFull(&movies))
{
fprintf(stderr,"NO memory available! Bye!\n");
exit(EXIT_FAILURE);
}
puts("Enter first movie title:");
while(s_gets(temp.title,TSIZE) != NULL && temp.title[0] != '\0')
{
puts("Enter your rating <0 - 10>:");
scanf("%d",&temp.rating);
while(getchar() != '\n')
continue;
if(AddItem(temp,&movies) == false)
{
fprintf(stderr,"Problem allocating memory\n");
break;
}
if(ListIsFull(&movies))
{
puts("The list is now full.");
break;
}
puts("Enter next movie title (empty line to stop):");
}
if(ListIsEmpty(&movies))
printf("NO data entered. ");
else
{
printf("Here is the movie list:\n");
Traverse(&movies,showmovies);
}
printf("You entered %d movies.\n",ListItemCount(&movies));
EmptyTheList(&movies);
printf("Bye!\n");
return 0;
}
void showmovies(Item item)
{
printf("MOvie: %s Rating: %d\n",item.title,item.rating);
}
char * s_gets(char *st, int n)
{
char *ret_avl;
char *find;
ret_avl = fgets(st,n,stdin);
if(ret_avl)
{
find = strchr(st,'\n');
if(find)
*find = '\0';
else
while(getchar() != '\n')
continue;
}
return ret_avl;
}
17.2.4 实现接口
当然,我们还是必须实现 List 接口。C 方法是把函数定义统一放在 list.c 文件中。然后,整个程序由 list.h(定义数据结构和提供用户接口的原型)、list.c(提供函数代码实现接口)和 films3.c(把链表接口应用于特定编程问题的源代码文件)组成。程序清单演示了 list.c 的一种实现。
/* list.c -- 支持链表操作的函数 */
#include "list.h"
#include
#include
/* 局部函数原型 */
static void CopyToNode(Item item, Node *pnode);
/* 接口函数 */
/* 把链表设置为空 */
void InitializeList(List * plist)
{
*plist = NULL;
}
/* 如果链表为空,返回 true */
bool ListIsEmpty(const List *plist)
{
if(*plist == NULL)
return true;
else
return false;
}
/* 如果链表已满,返回 true */
bool ListIsFull(const List *plist)
{
Node *pt;
bool full;
pt = (Node *)malloc(sizeof(Node));
if(pt == NULL)
full = true;
else
full = false;
free(pt);
return full;
}
/* 返回节点的数量 */
unsigned int ListItemCount(const List *plist)
{
unsigned int count = 0;
Node *pnode = *plist; /* 设置链表的开始 */
while(pnode != NULL)
{
++count;
pnode = pnode->next; /* 设置下一个节点 */
}
return count;
}
/* 创建储存项的节点,并将其添加至由 plist 指向的链表末尾(较慢的实现)*/
bool AddItem(Item item, List *plist)
{
Node *pnew;
Node *scan = *plist;
pnew = (Node *)malloc(sizeof(Node));
if(pnew == NULL)
return false; /* 失败时退出函数 */
CopyToNode(item,pnew);
pnew->next = NULL;
if(scan == NULL) /* 空链表,所以把 pnew 放在链表的开头 */
*plist = pnew;
else
{
while(scan->next != NULL) /* 找到 链表的末尾 */
scan = scan->next;
scan->next = pnew; /* 把 pnew 添加到链表的末尾 */
}
return true;
}
/* 访问每个节点并执行 pfun 指向的函数 */
void Traverse(const List *plist, void(*pfun)(Item item))
{
Node *pnode = *plist; /* 设置链表的开始 */
while(pnode != NULL)
{
(*pfun)(pnode->item); /* 把函数应用于链表中的项 */
pnode = pnode->next; /* 前进到下一项 */
}
}
/* 释放由 malloc() 分配的内存 */
/* 设置链表指针为 NULL */
void EmptyTheList(List *plist)
{
Node *psave;
while(*plist != NULL)
{
psave = (*plist)->next; /* 保存下一个节点的地址 */
free(*plist); /* 释放当前节点 */
*plist = psave; /* 前进至下一个节点 */
}
}
/* 局部函数定义 */
/* 把一个项拷贝到节点中 */
static void CopyToNode(Item item, Node *pnode)
{
pnode->item = item; /* 拷贝结构 */
}
提示 const 的限制
多个处理链表的函数都把
const List *plist作为形参,表明这些函数不会更改链表。这里,const 确实提供了一些保护,它防止了 *plist(即 plist 所指向的量)被修改,在该程序中,plist 指向 movies,所以 const 防止了这些函数修改 movies。因此,在 ListItemCount() 中,不允许有类似下面的代码:pnode = pnode->next; // 如果 *plist 是 const,不允许这样做
因为改变 *plist 就改变了 movies,将导致程序无法跟踪数据。然而,*plist 和 movies 都被看作是 const 并不意味着 *plist 或 movies 指向的数据是 const。例如,可以编写下面的代码:(*plist)->item.rating = 3; // 即使 *plist 是 const,也可以这样做
因为上面的代码并未改变 *plist,它改变的是 *plist 指向的数据。由此可见,不要指望 const 能捕获到以外修改数据的程序错误。
17.3 队列 ADT
在 C 语言中使用抽象数据类型方法编程包含以下 3 个步骤。
1、以抽象、通用的方式描述一个类型,包括该类型的操作。
2、设计一个函数接口表示这个新类型。
3、编写具体代码实现这个接口。
前面已经把这种方法应用到简单链表中。现在,把这种方法应用于更复杂的数据烈性:队列。
17.3.1 定义队列抽象数据类型
队列(queue)是具有两个特殊属性的链表。第一,新项只能添加到链表的末尾。从这方面看,队列与简单链表类似。第二,只能从链表的开头移除项。可以把队列想象成排队买票的人。你从队尾加入队列,买完票从队首离开。队列是一种 “先进先出”(first in, first out, 缩写为 FIFO)的数据形式,就像排队买票的队伍一样(前提是没有人插队)。接下来,我们建立一个非正式的抽象定义:
1、类型名:队列
2、类型属性:可以储存一系列项
3、类型操作;初始化队列为空、确定队列为空、确定队列已满、确定队列中的项数、在队列末尾添加项、在队列开头删除或恢复项、清空队列
17.3.2 定义一个接口
接口定义放在 queue.h 文件中。我们使用 C 的typedef 工具创建两个类型名:Item 和 Queue,相应结构的具体实现应该是 queue.h 文件的一部分,但是从概念上来看,应该在实现阶段才设计结构。现在,只是假定已经定义了这些类型,着重考虑函数的原型。
首先,考虑初始化。这涉及改变 Queue 类型,所以该函数应该以 Queue 的地址作为参数:void InitializeQueue(Queue *pq);
接下来,确定队列是否为空或已满的函数应返回真或假值。这里,假设 C99 的 stdbool.h 头文件可用。如果该文件不可用,可用使用 int 类型或自己定义 bool 类型。由于该函数不更改队列,所以接受 Queue 类型的参数。但是,传递 Queue 的地址更快,更节省内存,这取决于 Queue 类型的对象大小。这次我们尝试不更改队列,可用且应该使用 const 限定符:
bool QueueIsFull(const Queue *pq);
bool QueueIsEmpty(const Queue *pq);
指针 pq 指向 Queue 数据对象,不能通过 pq 这个代理更改数据。可用定义一个类似该函数的原型返回队列的项数:int QueueItemCount(const Queue *pq);
在队列末尾添加项涉及标识项和队列。这次要更改队列,所以有必要(而不是可选)使用指针。该函数的返回类型可以是 void,或者通过返回值类表示是否成功添加项。我们采用后者:bool EnQueue(Item item, Queue *pq);
最后,删除项有多种方法。如果把项定义为结构或一种基本类型,可以通过函数返回待删除的项。函数的参数可以是 Queue 类型或指向 Queue 的指针。因此,可能是下面这样的原型:Item DeQueue(Queue q); 然而,下面的原型会更合适一些:bool DeQueue(Item *pitem, Queue *pq); 从队列中待删除的项储存在 pitem 指针指向的位置,函数的返回值表明是否删除成功。
清空队列的函数所需的唯一参数是队列的地址,可以使用下面的函数原型:void EmptyTheQueue(Queue *pq);
17.3.3 实现接口数据表示
第一步是确定在队列中使用何种 C 数据形式。有可能是数组。数组的优点是方便使用,而且向数组的末尾添加项很简单。问题是如何从队列的开头删除项。类比于排队买票的队列,从队列的开头删除一个项包括拷贝数组首元素的值和把数组剩余各项依次向前移动一个位置。编程实现这个过程很简单,但是会浪费大量的计算机时间。
解决这种问题的一个好方法是,使队列成为环形。这意味着把数组的首尾相连,即数组的首元素紧跟在最后一个元素后面。这样,当到达数组末尾时,如果首元素空出,就可以把新添加的项储存到这些空出的元素中。可以想象在一张条形的纸上画出数组,然后把数组的首尾粘起来形成一个环。当然,要做一些标记,以免尾端超过首端。
另一种方法是使用链表。使用链表的好处是删除首项时不必移动其余元素,只需重置头指针指向新的首元素即可。由于我们已经讨论过链表,所以采用这个方案。我们用一个整数队列开始测试:typedef int iIem; 链表由节点组成,所以,下一步是定义节点:
typedef struct node {
Item item;
struct node * next;
} Node;
对列表而言,要保存首尾项,这可以使用指针来完成。另外,可以用一个计数器来记录队列中的项数。因此,该结构应由两个指针成员和一个 int 类型的成员构成:
typedef struct queue {
Node * front; /* 指向队列首项的指针 */
Node * rear; /* 指向队列尾项的指针 */
int items; /* 队列中的项数 */
} Queue;
注意,Queue 是一个内含 3 个成员的结构,所以用指向队列的指针作为参数比直接用队列作为参数节约了时间和空间。
接下来,考虑队列的大小。对链接而言,其大小受限于可以的内存量,因此链表不用太大。例如,能使用一个队列模拟飞机等待在机场着陆。如果等待的飞机数量太多,新到的飞机就应该改到其他机场降落。我们把队列的最大长度设置为 10。程序清单包含了队列接口的原型和定义。Item 类型留给用户定义。使用该接口时,可以根据特定的程序插入合适的定义。
/* queue.h -- Queue 的接口 */
#include
#ifndef _QUEUE_H_
#define _QUEUE_H_
// 在这里插入 Item 类型的定义
typedef int Item;
#define MAXQUEUE 10
typedef struct node{
Item item;
struct node * next;
} Node;
typedef struct queue {
Node * front; /* 指向队列首项的指针 */
Node * rear; /* 指向队列列尾项的指针 */
int items; /* 队列中的项数 */
} Queue;
/* 操作:初始化队列 */
/* 前提条件:pq 指向一个队列 */
/* 后置条件:队列被初始化为空 */
void InitializeQueue(Queue *pq);
/* 操作:检查队列是否已满 */
/* 前提条件:pq 指向之前被初始化的队列 */
/* 后置条件:如果队列已满则返回 true,否则返回 false */
bool QueueIsFull(const Queue *pq);
/* 操作:检查队列是否为空 */
/* 前提条件:pq 指向之前被初始化的队列 */
/* 后置条件:如果队列为空则返回 true,否则返回 false */
bool QueueIsEmpty(const Queue *pq);
/* 操作:确定队列中的项数 */
/* 前提条件:pq 指向之前被初始化的队列 */
/* 后置条件:返回队列中的项数 */
int QueueItemCount(const Queue *pq);
/* 操作:在队列末尾添加项 */
/* 前提条件:pq指向之前被初始化的队列;Item 是要被添加在队列末尾的项 */
/* 后置条件:如果队列不为空,item 将被添加在队列的末尾,该函数返回 true;否则,队列不改变,该函数返回 false */
bool EnQueue(Item item,Queue *pq);
/* 操作:从队列的开头删除项 */
/* 前提条件:pq 指向之前被初始化的队列 */
/* 后置条件:如果队列不为空,队列首端的 item 将被拷贝到 *pitem 中,并被删除,且函数返回 true;
如果该操作使得队列为空,则重置队列为空;如果队列在操作前为空,该函数返回 false */
bool DeQueue(Item *pitem, Queue *pq);
/* 操作:情况队列 */
/* 前提条件:pq 指向之前被初始化的队列 */
/* 后置条件:队列被清空 */
void EmptyTheQueue(Queue *pq);
#endif // _QUEUE_H_
/* queue.c -- Queue 类型的实现 */
#include "queue.h"
#include
#include
/* 局部函数 */
static void CopyToNode(Item item, Node *pn);
static void CopyToItem(Node *pn, Item *pi);
void InitializeQueue(Queue *pq)
{
pq->front = pq->rear = NULL;
pq->items = 0;
}
bool QueueIsFull(const Queue *pq)
{
return pq->items == MAXQUEUE;
}
bool QueueIsEmpty(const Queue *pq)
{
return pq->items == 0;
}
int QueueItemCount(const Queue *pq)
{
return pq->items;
}
bool EnQueue(Item item,Queue *pq)
{
Node *pnew;
if(QueueIsFull(pq))
return false;
pnew = (Node *)malloc(sizeof(Node));
if(pnew == NULL)
{
fprintf(stderr,"Unable to allocate memory!\n");
exit(EXIT_FAILURE);
}
CopyToNode(item,pnew);
pnew->next = NULL;
if(QueueIsEmpty(pq))
pq->front = pnew; /* 项位于队列的首端 */
else
pq->rear->next = pnew; /* 链接到队列的尾端 */
pq->rear = pnew; /* 记录队列尾端的位置 */
pq->items++; /* 队列项数加 1 */
return true;
}
bool DeQueue(Item *pitem, Queue *pq)
{
Node *pt;
if(QueueIsEmpty(pq))
return false;
CopyToItem(pq->front,pitem);
pt = pq->front;
pq->front = pt->next;
free(pt);
pq->items--;
if(pq->items == 0)
pq->rear = NULL;
return true;
}
/* 清空队列 */
void EmptyTheQueue(Queue *pq)
{
Item dummy;
while(!QueueIsEmpty(pq))
DeQueue(&dummy,pq);
}
/* 局部函数 */
static void CopyToNode(Item item, Node *pn)
{
pn->item = item;
}
static void CopyToItem(Node *pn, Item *pi)
{
*pi = pn->item;
}
17.3.4 测试队列
在重要程序中使用一个新的设计之前,应该先测试该设计。测试的一种方法是,编写一个小程序。这样的程序称为驱动程序(driver),其唯一的用途是进行测试。
/* use_q.c -- 驱动程序测试 Queue 接口 */
#include
#include "hotel.h"
int main(int argc,char *argv[])
{
Queue line;
Item temp;
char ch;
InitializeQueue(&line);
puts("Testing the Queue interface. Type a to add a value.");
puts("type d to delete a value, and type q to quit.");
while((ch = getchar()) != 'q')
{
if(ch != 'a' && ch != 'd')
continue;
if(ch == 'a')
{
printf("Integer to add: ");
scanf("%d",&temp);
if(!QueueIsFull(&line))
{
printf("Putting %d into queue\n",temp);
EnQueue(temp,&line);
}
else
puts("Queue is full!");
}
else
{
if(QueueIsEmpty(&line))
puts("Nothing to delete!");
else
{
DeQueue(&temp,&line);
printf("Removing %d from queue\n",temp);
}
}
printf("%d items in queue\n",QueueItemCount(&line));
puts("Type a to add, d to delete, q to quit: ");
}
EmptyTheQueue(&line);
puts("Bye!");
return 0;
}
下面是一个运行示例。除了这样测试,还应该测试当队列已满后,实现是否能正常运行。
Testing the Queue interface. Type a to add a value.
type d to delete a value, and type q to quit.
a
Integer to add: 40
Putting 40 into queue
1 items in queue
Type a to add, d to delete, q to quit:
a
Integer to add: 20
Putting 20 into queue
2 items in queue
Type a to add, d to delete, q to quit:
a
Integer to add: 55
Putting 55 into queue
3 items in queue
Type a to add, d to delete, q to quit:
d
Removing 40 from queue
2 items in queue
Type a to add, d to delete, q to quit:
d
Removing 20 from queue
1 items in queue
Type a to add, d to delete, q to quit:
d
Removing 55 from queue
0 items in queue
Type a to add, d to delete, q to quit:
d
Nothing to delete!
0 items in queue
Type a to add, d to delete, q to quit:
q
Bye!
17.4 链表和数组
许多编程问题,如创建一个简单链表或队列,都可以用链表(指的是动态分配结构的序列链)或数值来处理。每种形式都有其优缺点,所以要根据具体问题的要求来决定选择哪一种形式。表总结了链表和数组的性质。
| 数据形式 | 优点 | 缺点 |
|---|---|---|
| 数组 | C 直接支持,提供随机访问 | 在编译时确定大小,插入和删除元素很费时 |
| 链表 | 运行时确定大小,快速插入和删除元素 | 不能随机访问,用户必须提供编译支持 |
接下来,详细分析插入和删除元素的过程。在数值中插入元素,必须移动其他 元素腾出空位插入新元素。新插入的元素离数组开头越近,要被移动的元素越多。然而,在链表中插入节点,只需给两个指针赋值。类似地,从数组中删除一个元素,也要移动许多相关的元素。但是从链表中删除节点,只需重新设置一个指针并释放被删除节点占用的内存即可。
接下来,考虑如何访问元素。对数组而言,可以使用数组下标直接访问该数组中的任意元素,这叫做随机访问(random access)。对链表而言,必须从链表首节点开始,逐个节点移动到要访问的节点,这叫做顺序访问(sequential access)。当然,也可以顺序访问数组。只需按顺序递增数组下标即可。在某些情况下,顺序访问足够了。例如,显示链表中的每一项,顺序访问就不错。其他情况用随机访问更合适。
假设要查找链表中的特定项。一种算法是从列表的开头开始按顺序查找,这叫做顺序查找(sequential search)。如果项并未按某种顺序排序,则只能顺序查找。如果待查找的项不在链表里,必须查找完所有的项才知道该项不在链表中(在这种情况下可以使用并发编程,同时查找列表中的不同部分)。
我们可以先排序列表,以改进顺序查找。这样,就不必查找排在待查找项后面的项。例如,假设在一个按字母排序的列表中查找 Susan。从头开始查找每一项,直到 Sylvia 都没有查找到 Susan。这时就可以退出查找,因为如果 Susan 在列表中,应该排在 Sylvia 前面。平均下来,这种方法查找不在列表中的项的时间减半。
对于一个排序的列表,用二分查找(binary search)比顺序查找好得多。下面分析二分查找的原理。首先,把待查找的项称为目标项,而且假设列表中的各项按字母排序。然后,比较列表的中间项和目标项。如果两者相等,查找结束;假设目标项在列表中,如果中间项排在目标项前面,则目标项一定在后半部分项中;如果中间项在目标项后面,则目标项一定在前半部分项中。无论哪种情况,两项比较的结果都确定了下次查找的范围只有列表的一半。接着,继续使用这种方法,把需要查找的剩下一半的中间项与目标项比较。同样,这种方法会确定下一次查找的范围是当前查找范围的一半。以此类推,直到找到目标项或最终发现列表中没有目标项。这种方法非常有效率。假如有 127 个项,顺序查找平均要进行 64 次比较才能找到目标项或发现不在其中。但是二分查找最多只用进行 7 次比较。第 1 次比较剩下 63 项进行比较,第 2 次比较剩下 31 项进行比较,以此类推,第 6 次剩下最后 1 项进行比较,第 7 次比较确定剩下的这个项是否是目标项。一般而言,n 次比较能处理有 2n - 1 个元素的数组。所以项数越多,越能提醒二分查找的优势。
用数组实现二分查找很简单,因为可以使用数组下标确定数组中任意部分的中点。只要把数组的首元素和尾元素的索引相加,得到的和再除以 2 即可。例如,内含 100 个元素的数组,首元素下标是 0,尾元素下标是 99,那么用于首次比较的中间项的下标应为 (0 + 99) / 2,得 49(整数除法)。如果比较的结果是下标为 49 的元素在目标项的后面,那么目标项的下标应在 0 ~ 48 的范围内。所以,第 2 次比较的中间项的下标应为 (0 + 48) / 2,得 24。如果中间项与目标项的比较结果是,中间项在目标项前面,那么第 3 次比较的中间项下标应为 (25 + 48) / 2,得 36。这体现了随机访问的特性,可以从一个位置跳至另一个位置,不用一次访问两位置之间的项。但是,链表只支持顺序访问,不提供跳至中间节点的方法。所以在链表中不能使用二分查找。
如前所述,选择何种数据类型取决于具体的问题。如果因频繁地插入和删除项导致经常调整大小,而且不需要经常查找,选择链表会更好。如果只是偶尔插入或删除项,但是经常进行查找,使用数组会更好。
17.5 二叉查找树
二叉查找树是一种结合了二叉查找策略的链接结构。二叉树的每个节点都包含一个项和两个指向其他节点(称为子节点)的指针。图演示了二叉查找树中的节点是如何链接的。二叉树中的每个节点都包含两个子节点 —— 左节点和右节点,其顺序按照如下规定确定:左节点的项在父节点的项前面,右节点的项在父节点的项后面。这种关系存在于每个有子节点的节点中。进一步而言,所以可以追溯其祖先回到一个父节点的左节点的项,都在该父节点项的前面:所有以一个父节点的右节点为祖先的项,都在该父节点项的后面。图中的树以这种方式储存的数据也以等级或层次组织。一般而言,每级都有上一级和下一级。如果二叉树是满的,那么每一级的节点数都是上一级节点数的两倍。
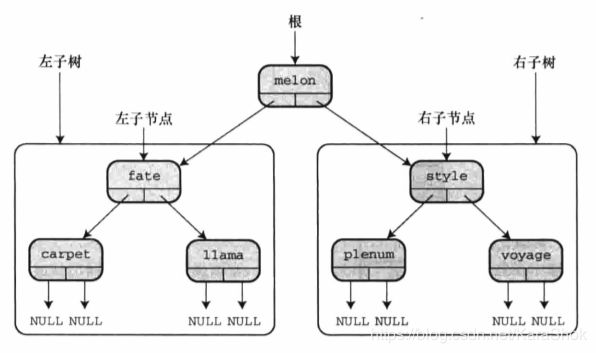
二叉查找树中的每个节点是其后代节点的根,该节点与其后代节点构成称了一个子树(subtree)。如上图所示,包含单词 fate、carpet 和llama 的节点构成了整个二叉树的左子树,而单词 voyage 是 style-plenum-voyage 子树的右子树。
假设要在二叉树中查找一个项(即目标项)。如果目标项的根节点项的前面,则只需查找左子树;如果目标项在根节点项的后面,则只需查找右子树。因此,每次比较就排除半个树。假设查找左子树,这意味着目标项与左子节点项比较。如果目标项在左子节点项的前面,则只需查找其后代节点的左半部分,以此类推。与二分查找类似,每次比较都能排除一半的可能匹配项。
二叉查找树在链式结构中结合了二分查找的效率。但是,这样编程的代价是构建一个二叉树比创建一个链表更复杂。下面我们在下一个 ADT 项目中创建一个二叉树。
17.5.1 二叉树 ADT
和前面一样,先从概括地定义二叉树开始。该定义假设数不包含相同的项。许多操作与链表相同,区别在于数据层次的安排。下面建立一个非正式的树定义:
1、类型名:二叉查找树
2、类型属性:二叉树要么是空节点的集合(空树),要么是有一个根节点的节点集合。每个节点都有两个子树,叫做左子树和右子树。每个子树本身也是一个二叉树,也有可能是空树。二叉查找树是一个有序的二叉树,每个节点包含一个项,左子树的所有项都在跟节点项的前面,右子树的所有项都在根节点项的后面。
3、类型操作;初始化数为空、确定树是否为空、确定树是否已满、确定树中的项数、在树中添加一个项、在树中删除一个项、在树中查找一个项、在树中访问一个项、清空树。
17.5.2 二叉查找树接口
原则上,可以用多种方法实现二叉查找树,甚至可以通过操控数组下标用数组来实现。但是,实现二叉查找树是直接的方法是通过指针动态分配链式节点。因此我们这样定义:
typedef SOMETHING Item;
typedef struct trnode {
Item item;
struct trnode * left;
struct trnode * right;
} Trn;
typedef struct tree {
trnode * root;
int size;
} Tree;
每个节点包含一个项、一个指向左子节点的指针和一个指向右子节点的指针。可以把 Tree 定义为指向 trnode 的指针类型,因为只需要知道根节点的位置就可以访问整个树。然而,使用有成员大小的结构能很方便地记录树的大小。
我们要开发一个维护 Nerfville 宠物俱乐部的花名册,每一项都包含宠物名和宠物的种类。程序清单就是该花名册的接口。我们把数的大小限制为 10,较小的树便于在树已满时测试程序的行为是否正确。当然,你也可以把 MAXITEMS 设置为更大的值。
/* tree.h -- 二叉查找树(树不允许有重复的项) */
#include
#ifndef _TREE_H_
#define _TREE_H_
/* 根据具体情况重新定义 Item */
#define SLEN 20
typedef struct item {
char petname[SLEN];
char petkind[SLEN];
} Item;
#define MAXITEMS 10
typedef struct trnode {
Item item;
struct trnode * left; /* 指向左分支的指针 */
struct trnode * right; /* 指向右分支的指针 */
} Trnode;
typedef struct tree {
Trnode * root; /* 指向根节点的指针 */
int size; /* 数的项数 */
} Tree;
/* 函数原型 */
/* 操作:把数初始化为空 */
/* 前提条件:ptree 指向一个树 */
/* 后置条件:数被初始化为空 */
void InitializeTree(Tree * ptree);
/* 操作:确定树是否为空 */
/* 前提条件:ptree 指向一个树 */
/* 后置条件:如果数已满,该函数返回 true;否则,返回 false */
bool TreeIsEmpty(const Tree * ptree);
/* 操作;确定树的项数 */
/* 前提条件:ptree 指向一个树 */
/* 后置条件:返回树的项数 */
bool TreeIsFull(const Tree * ptree);
/* 操作:确定树的项数 */
/* 前提条件:ptree 指向一个树 */
/* 后置条件:返回树的项数 */
int TreeItemCount(const Tree * ptree);
/* 操作:在树中添加一个项 */
/* 前提条件:pi 是待添加项的地址,ptree 指向一个已初始化的树 */
/* 后置条件:如果可以添加,该函数将在树中添加一个项,并返回 true;否则,返回 false */
bool AddItem(const Item * pi, Tree * ptree);
/* 操作;在树中查找一个项 */
/* 前提条件:pi 指向有一个项,ptree 指向一个已初始化的树 */
/* 后置条件:如果在树中添加一个项,该函数返回 true;否则,返回 false */
bool InTree(const Item * pi, const Tree * ptree);
/* 操作;从树中删除一个项 */
/* 前提条件:pi 是删除项的地址,ptree 指向一个已初始化的树 */
/* 后置条件:如果从树中成功删除一个项,该函数返回 true;否则,返回 false */
bool DeleteItem(const Item *pi, Tree * ptree);
/* 把函数应用于树中的每一项 */
/* 前提条件:ptree 指向一个树,pfun 指向一个函数,该函数接受一个 Item 类型的参数,并无返回值 */
/* 后置条件:pfun 指向的这个函数为树中的每一项执行一次 */
void Traverse(const Tree * ptree, void(*pfun)(Item iten));
/* 操作:删除树中的所有内容 */
/* 前提条件;ptree 指向一个已初始化的树 */
/* 后置条件:树为空 */
void DeleteAll(Tree * ptree);
#endif // _TREE_H_
/* tree.c --树的支持函数 */
#include "tree.h"
#include
#include
#include
/* 局部数据类型 */
typedef struct pair {
Trnode * parent;
Trnode * child;
} Pair;
/* 局部函数的原型 */
static Trnode * MakeNode(const Item * pi);
static bool ToLeft(const Item * i1, const Item * i2);
static bool ToRight(const Item * i1, const Item * i2);
static void AddNode(Trnode * new_node, Trnode * root);
static void InOrder(const Trnode * root, void(*pfun)(Item item));
static Pair SeekItem(const Item * pi, const Tree * ptree);
static void DeleteNode(Trnode **ptr);
static void DeleteAllNodes(Trnode * root);
/* 函数定义 */
void InitializeTree(Tree * ptree)
{
ptree->root = NULL;
ptree->size = 0;
}
bool TreeIsEmpty(const Tree * ptree)
{
if(ptree->root == NULL)
return true;
else
return false;
}
bool TreeIsFull(const Tree * ptree)
{
if(ptree->size == MAXITEMS)
return true;
else
return false;
}
int TreeItemCount(const Tree * ptree)
{
return ptree->size;
}
bool AddItem(const Item * pi, Tree * ptree)
{
Trnode * new_node;
if(TreeIsFull(ptree))
{
fprintf(stderr,"Tree is full\n");
return false; /* 提前返回 */
}
if(SeekItem(pi,ptree).child != NULL)
{
fprintf(stderr,"Attempted to add duplicate item\n");
return false; /* 提前返回 */
}
new_node = MakeNode(pi); /* 指向新节点 */
if(new_node == NULL)
{
fprintf(stderr,"Couldn't create node\n");
return false; /* 提前返回 */
}
/* 成功创建了一个新节点 */
ptree->size++;
if(ptree->root == NULL) /* 情况 1:树为空,新节点为树的根节点 */
/* 情况 2:树不为空,在树中添加新节点 */
ptree->root = new_node;
else
AddNode(new_node,ptree->root);
return true; /* 成功返回 */
}
bool InTree(const Item * pi, const Tree * ptree)
{
return (SeekItem(pi,ptree).child == NULL) ? false : true;
}
bool DeleteItem(const Item *pi, Tree * ptree)
{
Pair look;
look = SeekItem(pi,ptree);
if(look.child == NULL)
return false;
if(look.parent == NULL) /* 删除根节点项 */
DeleteNode(&ptree->root);
else if(look.parent->left == look.child)
DeleteNode(&look.parent->left);
else
DeleteNode(&look.parent->right);
ptree->size--;
return true;
}
void Traverse(const Tree * ptree, void(*pfun)(Item iten))
{
if(ptree != NULL)
InOrder(ptree->root,pfun);
}
void DeleteAll(Tree * ptree)
{
if(ptree != NULL)
DeleteAllNodes(ptree->root);
ptree->root = NULL;
ptree->size = 0;
}
/* 局部函数 */
static Trnode * MakeNode(const Item * pi)
{
Trnode * new_node;
new_node = (Trnode *)malloc(sizeof(Trnode));
if(new_node != NULL)
{
new_node->item = *pi;
new_node->left = NULL;
new_node->right = NULL;
}
return new_node;
}
static bool ToLeft(const Item * i1, const Item * i2)
{
int compl;
if((compl = strcmp(i1->petname,i2->petname)) < 0)
return true;
else if(compl == 0 && strcmp(i1->petkind,i2->petkind) < 0)
return true;
else
return false;
}
static bool ToRight(const Item * i1, const Item * i2)
{
int compl;
if((compl = strcmp(i1->petname,i2->petname)) > 0)
return true;
else if(compl == 0 && strcmp(i1->petkind,i2->petkind) > 0)
return true;
else
return false;
}
static void AddNode(Trnode * new_node, Trnode * root)
{
if(ToLeft(&new_node->item,&root->item))
{
if(root->left == NULL) /* 空子树 */
root->left = new_node; /* 把节点添加到此处 */
else
AddNode(new_node,root->left); /* 否则处理该子树 */
}
else if(ToRight(&new_node->item,&root->item))
{
if(root->right == NULL)
root->right = new_node;
else
AddNode(new_node,root->right);
}
else /* 不允许有重复项 */
{
fprintf(stderr,"location error in AddNode()\n");
exit(EXIT_FAILURE);
}
}
static void InOrder(const Trnode * root, void(*pfun)(Item item))
{
if(root != NULL)
{
InOrder(root->left,pfun);
(*pfun)(root->item);
InOrder(root->right,pfun);
}
}
static Pair SeekItem(const Item * pi, const Tree * ptree)
{
Pair look;
look.parent = NULL;
look.child = ptree->root;
if(look.child == NULL)
return look; /* 提前返回 */
while(look.child != NULL)
{
if(ToLeft(pi,&(look.child->item)))
{
look.parent = look.child;
look.child = look.child->left;
}
else if(ToRight(pi,&(look.child->item)))
{
look.parent = look.child;
look.child = look.child->right;
}
else /* 如果前两种情况都不满足,则必定是相等的情况 */
break;
}
return look; /* 成功返回 */
}
static void DeleteNode(Trnode **ptr) /* ptr 是指向目标节点的父节点指针成员的地址 */
{
Trnode * temp;
if((*ptr)->left == NULL)
{
temp = *ptr;
*ptr = (*ptr)->right;
free(temp);
}
else if((*ptr)->right == NULL)
{
temp = *ptr;
*ptr = (*ptr)->left;
free(temp);
}
else /* 被删除的节点有两个子节点 */
{
for(temp = (*ptr)->left; temp->right != NULL; temp = temp->right) /* 找到重新连接右子树的位置 */
continue;
temp->right = (*ptr)->right;
temp = *ptr;
*ptr = (*ptr)->left;
free(temp);
}
}
static void DeleteAllNodes(Trnode * root)
{
Trnode * pright;
if(root != NULL)
{
pright = root->right;
DeleteAllNodes(root->left);
free(root);
DeleteAllNodes(pright);
}
}
/* use_q.c -- 使用二叉查找树*/
#include
#include
#include
#include "tree.h"
char menu(void);
void addpet(Tree * pt);
void droppt(Tree * pt);
void showpets(const Tree * pt);
void findpet(const Tree * pt);
void printItem(Item item);
void uppercase(char * str);
char * s_gets(char * st, int n);
int main(int argc,char *argv[])
{
Tree pets;
char choice;
InitializeTree(&pets);
while((choice = menu()) != 'q')
{
switch(choice)
{
case 'a': addpet(&pets);
break;
case 'l': showpets(&pets);
break;
case 'f': findpet(&pets);
break;
case 'n': printf("%d pets in club\n",TreeItemCount(&pets));
break;
case 'd': droppt(&pets);
break;
default : puts("Switching error");
}
}
DeleteAll(&pets);
puts("Bye!");
return 0;
}
char menu(void)
{
int ch;
puts("Nerfville Pet Club Membership Program");
puts("Enter the letter corresponding to your choice:");
puts("a) add a pet l) show list of pets");
puts("n) number of pets f) find pets");
puts("d) delete a pet q) quit");
while((ch = getchar()) != EOF)
{
while(getchar() != '\n')
continue;
ch = tolower(ch);
if(strchr("alrfndq",ch) == NULL)
puts("Please enter an a, l, f, n, d or q:");
else
break;
}
if(ch == EOF)
ch = 'q';
return ch;
}
void addpet(Tree * pt)
{
Item temp;
if(TreeIsFull(pt))
puts("No room in the club!");
else
{
puts("Please enter name of pet:");
s_gets(temp.petname,SLEN);
puts("Please enter pet kind:");
s_gets(temp.petkind,SLEN);
uppercase(temp.petname);
uppercase(temp.petkind);
AddItem(&temp,pt);
}
}
void droppt(Tree * pt)
{
Item temp;
if(TreeIsEmpty(pt))
{
puts("No enteries!");
return;
}
puts("Please enter name of pet you wish to delete:");
s_gets(temp.petname,SLEN);
puts("Please enter pet kind:");
puts("Please enter pet kind:");
s_gets(temp.petkind,SLEN);
uppercase(temp.petname);
uppercase(temp.petkind);
printf("%s the %s ",temp.petname,temp.petkind);
if(DeleteItem(&temp,pt))
printf("is dropped from the club.\n");
else
printf("is not a member.\n");
}
void showpets(const Tree * pt)
{
if(TreeIsEmpty(pt))
puts("No enteries!");
else
Traverse(pt,printItem);
}
void findpet(const Tree * pt)
{
Item temp;
if(TreeIsEmpty(pt))
{
puts("No enteries!");
return;
}
puts("Please enter name of pet you wish to find:");
s_gets(temp.petname,SLEN);
puts("Please enter pet kind:");
s_gets(temp.petkind,SLEN);
uppercase(temp.petname);
uppercase(temp.petkind);
printf("%s the %s ",temp.petname,temp.petkind);
if(InTree(&temp,pt))
printf("is a member.\n");
else
printf("is not a member.\n");
}
void printItem(Item item)
{
printf("Pet: %-9s Kind: %-19s\n",item.petname,item.petkind);
}
void uppercase(char * str)
{
while(*str)
{
*str = toupper(*str);
str++;
}
}
char * s_gets(char * st, int n)
{
char * ret_val;
char *find;
ret_val = fgets(st,n,stdin);
if(ret_val)
{
find = strchr(st,'\n');
if(find)
*find = '\0';
else
while(getchar() != '\n')
continue;
}
return ret_val;
}
该程序把所有字母都转换为大写字母,所有 SNUFFY、Snuffy 和 sunffy 都被视为相同。下面是该程序的一个运行示例;
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
a
Please enter name of pet:
Quincy
Please enter pet kind:
pig
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
a
Please enter name of pet:
Bennie Haha
Please enter pet kind:
parrot
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
a
Please enter name of pet:
Hiram Jinx
Please enter pet kind:
domestic cat
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
n
3 pets in club
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
l
Pet: BENNIE HAHA Kind: PARROT
Pet: HIRAM JINX Kind: DOMESTIC CAT
Pet: QUINCY Kind: PIG
Nerfville Pet Club Membership Program
Enter the letter corresponding to your choice:
a) add a pet l) show list of pets
n) number of pets f) find pets
d) delete a pet q) quit
q
Bye!
17.5.3 树的思想
二叉查找树也有一些缺陷。例如,二叉查找树只有在满员(或平衡)时效率最高。查找不平衡的树并不比查找链表要快。
避免串状树的方法之一是在创建树时多加注意。如果树或子树的一边或另一边太不平衡,就需要重新排列节点使之恢复平衡。一次类似,可能在进行删除操作后要重新排列树。俄国数学家发明了一种算法来解决这个问题。根据他们的算法创建的树称为 AVL 树。所以创建一个平衡的树所花费的时间更多,但是这样的树可以确保最大化搜索效率。
17.6 其他说明
我们涵盖了 C 语言的基本特性,但是只是简要介绍了库。ANSI C 库中包含多种有用的函数。绝大部分实现都针对特定的系统提供扩展库。基于 Windows 的编译器支持 Windows 图形接口。Macintosh C 编译器提供访问 Macintosh 工具箱的函数,以便编写具有标准 Macintosh 接口或 iOS 系统的程序产品。与此类似,还有一些工具用于创建 Linux 程序的图形接口。
17.7 关键概念
一种数据类型通过以下几点来表征:如果构建数据、如何储存数据、有哪些可能的操作。抽象数据类型(ADT)以抽象的方式指定构成某种类型特征的属性和操作。从概念上看,可以分两步把 ADT 翻译成一种特定的编程语言。第 1 步是定义编程接口。在 C 中,通过使用头文件定义类型名,并提供与允许的操作相应的函数原型来实现。第 2 步是实现接口。在 C 中,可以用源代码文件提供与函数原型相应的函数定义来实现。
17.8 本章小结
链表、队列和二叉树是 ADT 在计算机程序设计中常用的示例。通常用动态内存分配和链式结构来实现它们,但有时用数组来实现会更好。
当使用一种特定类型(如队列或树)进行编程时,要根据类型接口来编写程序。这样,在修改或改进实现时就不用更改使用接口的那些程序。
17.9 复习题
1、定义一种数据类型涉及哪些内容?
2、为什么程序清单只能沿一个方向遍历链表?如果修改 struct film 定义才能沿两个方向遍历链表?
3、什么是 ADT?
4、QueueIsEmpty() 函数接受一个指向 queue 结构的指针作为参考,但是也可以将其编写成接受一个 queue 结构作为参数。这两种方式各有什么优缺点?
5、栈(stack)是链表系列的另一种数据形式。在栈中,只能在链表的一端添加和删除项,项被 “压入” 栈和 “弹出” 栈。因此,栈是一种 LIFO(即后进先出 last in first out)结构。
a、设计一个栈 ADT;
b、为栈设计一个 C 编程接口,例如 stack.h 头文件。
6、在一个含义 3 个项的分类列表中,判断一个特定项是否在该列表中,用顺序查找和二叉查找方法分别需要最多多少次?当列表中有 1023 个项时分别是多少次?65535 个项时分别是多少次?
7、假设一个程序用本章介绍的算法构造了一个储存单词的二叉查找树。假设根据下面所列的顺序输入单词。请画出每种情况的树:
a、nice food roam dodge gate office wave
b、wave roam office nice gate food dodge
c、food dodge roam wave office gate nice
d、nice roam office food wave gate dodge
8、考虑复习题 7 构造的二叉树,根据本章的算法,删除单词 food 之后,各树是什么样子?
17.10 编程练习
1、修改程序清单,让该程序既能正序也能逆序显示电影列表。一种方法是修改链表的定义,可以双向遍历链表。另一种方法是用递归。
2、假设 list.h 使用下面的 list 定义:
typedef struct list {
Node * head; /* 指向 list 的开头 */
Node * end; /* 指向 list 的末尾 */
} List;
重写 list.c 中的函数以适应新的定义,并通过 films.c 测试最终的代码。
3、假设 list.h 使用下面的 list 定义:
#define MAXSIZE 100
typedef struct list {
Item entries[MAXSIZE]; /* 内含项的数组*/
int items; /* list 中的项数 */
} List;
重写 list.c 中的函数以适应新的定义,并通过 films.c 测试最终的代码。
4、重写 list.c,用两个队列模拟两个摊位。
5、编写一个程序,提示用户输入一个字符串。然后该程序把该字符串的字符逐个压入一个栈(参见复习题 5),然后从栈中弹出这些字符,并显示它们。结果显示为该字符串的逆序。
6、编写一个函数接受 3 个参数:一个数组名(内含已排序的整数)、该数组的元素个数和待查找的整数。如果待查找的整数在数组中,那么该函数返回 1;如果该数不在数组中,该函数则返回 0。用二分查找法实现。
7、编写一个程序,打开和读取一个文本文件,并统计文件中每个单词出现的次数。用改进的二叉查找树储存单词及其出现的次数程序在读入文件后,会提供一个有 3 个选项的菜单。第 1 个选项是列出所有的单词和出现的次数。第 2 个选项是让用户输入一个单词,程序报告该单词在文件中出现额次数。第 3 个选项是退出。
8、修改宠物店俱乐部程序,把所有同名的宠物都储存在一个节点中,当用户选择查找宠物时,程序询问用户该宠物的名字,然后列出该名字的所有宠物(及其种类)。