Redis集群的方案总结:客户端Sharding/Redis Cluster/Proxy
转载:redis sentinel设计与实现
转载:分布式一致性算法(一)一致性哈希算法(consistent hashing)
转载:Jedis下的ShardedJedis(分布式)使用方法(一)
转载:分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
转载:Codis集群的搭建与使用
转载:Twemproxy 介绍与使用
一、Redis集群
由于Redis出众的性能,其在众多的移动互联网企业中得到广泛的应用。Redis在3.0版本前只支持单实例模式,虽然现在的服务器内存可以到100GB、200GB的规模,但是单实例模式限制了Redis没法满足业务的需求(例如新浪微博就曾经用Redis存储了超过1TB的数据)。Redis的开发者Antirez早在博客上就提出在Redis 3.0版本中加入集群的功能,但3.0版本等到2015年才发布正式版。各大企业在3.0版本还没发布前为了解决Redis的存储瓶颈,纷纷推出了各自的Redis集群方案。这些方案的核心思想是把数据分片(sharding)存储在多个Redis实例中,每一片就是一个Redis实例。
二、再论一致性哈希
分布式一致性算法(一)一致性哈希算法(consistent hashing)
三、Redis集群的简单方案:Redis Sharding
1. Redis Sharding
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。
客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则,把对Key的访问转发到不同的Redis实例中,最后把返回结果汇集。这种方案的模式如图1所示。
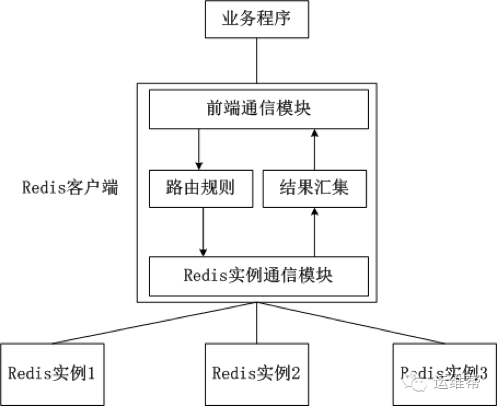
客户端分片的好处是所有的逻辑都是可控的,不依赖于第三方分布式中间件。开发人员清楚怎么实现分片、路由的规则,不用担心踩坑。
客户端分片方案有下面这些缺点。
1. 这是一种静态的分片方案,需要增加或者减少Redis实例的数量,需要手工调整分片的程序。
2. 可运维性差,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。
3. 在不同的客户端程序中,维护相同的分片逻辑成本巨大。例如,系统中有两套业务系统共用一套Redis集群,一套业务系统用Java实现,另一套业务系统用PHP实现。为了保证分片逻辑的一致性,在Java客户端中实现的分片逻辑也需要在PHP客户端实现一次。相同的逻辑在不同的系统中分别实现,这种设计本来就非常糟糕,而且需要耗费巨大的开发成本保证两套业务系统分片逻辑的一致性。
2. Redis Sharding的扩容问题
Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。当然,Redis Sharding这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,毕竟还是会有key匹配不到而丢失,这时需要键值迁移。
作为轻量级客户端sharding,处理Redis键值迁移是不现实的,这就要求应用层面允许Redis中数据丢失或从后端数据库重新加载数据。但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。有没有其它手段改善这种情况?
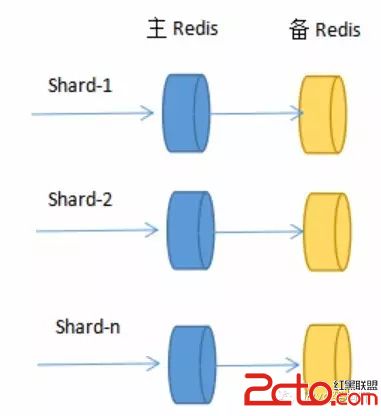
Redis作者给出了一个比较讨巧的办法–presharding,即预先根据系统规模尽量部署好多个Redis实例,这些实例占用系统资源很小,一台物理机可部署多个,让他们都参与sharding,当需要扩容时,选中一个实例作为主节点,新加入的Redis节点作为从节点进行数据复制。数据同步后,修改sharding配置,让指向原实例的Shard指向新机器上扩容后的Redis节点,同时调整新Redis节点为主节点,原实例可不再使用。
这样,我们的架构模式变成一个Redis节点切片包含一个主Redis和一个备Redis。在主Redis宕机时,备Redis接管过来,上升为主Redis,继续提供服务。主备共同组成一个Redis节点,通过自动故障转移,保证了节点的高可用性。则Sharding架构演变成:
3. Redis Sentinel模式实现故障转移
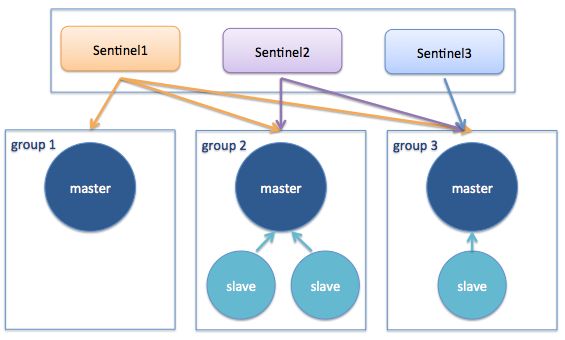
Redis 2.8版开始正式提供名为Sentinel的主从切换方案,Sentinel用于管理多个Redis服务器实例,主要负责三个方面的任务:
1. 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2. 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3. 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
特殊状态的Redis
一个Sentinel就是一个运行在特殊状态下的Redis,以至于可以用启动Redis Server的方式启动Sentinel。不过Sentinel有自己的命令列表,它支持的命令不多。
配置Redis主节点,自动发现从节点
Sentinel运行起来后,会根据配置文件的"sentinel monitor
自动发现监控同一个group的其他Sentinel
Sentinel连接Redis节点,会创建两条对节点的连接,一条用来向节点发送命令,另一条用来订阅“__sentinel__:hello”频道(hello频道)发来的消息,这个频道用做Gossip协议发现其他监控此Redis节点的Sentinel。每个Sentinel会定时向频道发送消息,然后也会接收到其他Sentinel从hello频道发来的消息,消息的格式如下:
sentinel_ip,sentinel_port,sentinel_runid,current_epoch,master_name,master_ip,master_port,master_config_epoch(127.0.0.1,26381,99ce8dc79e55ce9de040b0cd13d152900db9a7e1,24,mymaster2,127.0.0.1,8000,0)。推送消息
Sentinel在监控Redis和其他Sentinel的时候,发现的异常以及完成的操作都会通过Publish的方式推送出去,客户端想了解Sentinel的处理结果,只要订阅相应的消息类型即可。Sentinel使用的推送方式用的是Redis现有的Pub/Sub方式。Sentinel基本上会把它整个处理流程都推送出来,然而客户端一般只要关注主从切换的消息即可。
故障检查
Sentinel会跟group的每个节点以及监控同一个group的其他Sentinel保持心跳,Sentinel会定时向这些节点发送Ping命令,然后等待Pong命令回复。如果一段时间没有收到Pong命令。Sentinel就会主观的认为该节点离线。对于其他Sentinel和group内的slave挂了,Sentinel检测到他们离线也不需要做什么事情,只是简单的推送一条+sdown的消息。如果检测到master离线,Sentinel就要确定是否需要进行主从切换。此时Sentinel会向其他Sentinel发送is-master-down-by-addr命令(命令格式:SENTINEL IS-master-DOWN-BY-ADDR
Sentinel间投票选leader
Sentinel认为master客观下线了,就开始故障转移流程,故障转移的第一步就是竞选leaderSentinel采用了Raft协议实现了Sentinel间选举Leader的算法,不过也不完全跟论文描述的步骤一致。Sentinel集群运行过程中故障转移完成,所有Sentinel又会恢复平等。Leader仅仅是故障转移操作出现的角色。
故障转移
Sentinel一旦确定自己是leader后,就开始从slave中选出一个节点来作为master。如果依据选择流程没有选出可用的slave,leader Sentinel会终止本次故障转移。
如果选择出了可用的slave,那么leader Sentinel会给该slave发送slaveof no one命令,表示该slave不再复制其他节点,成为了master。然后leader Sentinel就会一直等待选出slave的INFO信息里面确认了自己的master身份。如果等待超时了,leader Sentinel只得终止本次故障转移。
如果选出的slave确认了自己的master身份,leader Sentinel会让其他slave复制新的master,由于初次复制会带来很大的IO开销,Sentinel有个parallel_syncs参数,用来确定一次让多少个slave复制新master。一个slave复制master如果超过10s,leader Sentinel会重新发送复制命令。如果在指定的故障转移时间内还没有完成全部的复制工作,leader Sentinel就会忽略那些没复制的slave。leader Sentinel只是向这些slave发送一次复制命令,不等待他们复制成功就直接完成了全部故障转移工作。
全部故障转移工作完成后,leader Sentinel就会推送+switch-master消息,同时重置master,重置操作会释放掉原来master全部的slave对象和监听该master的其他Sentinel对象,然后创建出新的slave对象。
客户端处理流程
客户端可以通过Sentinel获得group的信息。官方给出了客户端操作的推荐方式。看了下Jedis的实现,基本就是按照官方的操作流程进行的。首先客户端配置监听该group的全部Sentinel。连接第一个Sentinel,如果连不上就重新连接下一个,直到连上一个Sentinel。
连上Sentinel后,发送SENTINEL get-master-addr-by-name master-name命令可以得到该group的master,如果该Sentinel返回了null,那就重复上面的流程,重新连接下一个Sentinel。
得到group的master后,连上master,发送ROLE命令,确认该master自身确实是作为master在运行。这个确认是必须的,如果Sentinel和group网络分区了,那么该Sentinel认为的master就不会变化了,而group如果出现主从切换,此时Sentinel就拿不到真实的master了。如果ROLE得到的不再是master了,客户端需要重复最前面的流程,重新连接下一个Sentinel。
确认好master的ROLE也是master后,客户端可以从每个Sentinel上订阅消息。一般客户端只要关心+switch-master即可,这个消息会告诉客户端发生了主从切换,并把新老master的ip、port都推送在消息里。客户端根据新的master,发送ROLE命令确认后,就可以和新的master通信了。
有些客户端希望把读流量分给slave,那么可以通过SENTINEL slaves master-name命令来获得该group下的slave列表。
如果客户端需要重连master,那么建议按照初始化连接的方式重新从Sentinel获取master。
如果采用连接池的方式,官方建议在每次有连接断开需要重连的时候所有的连接都关闭,从而重建连接池。这么做也是为了防止新的连接获取的master跟原来不一致了。
客户端还可以通过SENTINEL sentinels
4. Jedis Sharding:ShardedJedis和ShardedJedisPool的使用
Java redis客户端驱动jedis已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
1、采用一致性哈希算法(consistent hashing),将key和节点name同时hashing,然后进行映射匹配,采用的算法是MURMUR_HASH。采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
2.为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟化出160个虚拟节点进行散列。根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
3.ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
ShardedJedis的使用方法除了配置时有点区别,其他和Jedis基本类似,有一点要注意的是 ShardedJedis不支持多命令操作,像mget、mset、brpop等可以在redis命令后一次性操作多个key的命令,具体包括哪些,大家可以看Jedis下的 MultiKeyCommands 这个类,这里面就包含了所有的多命令操作。很贴心的是,Redis作者已经把这些命令从ShardedJedis过滤掉了,使用时也调用不了这些方法,大家知道下就行了。好了,现在来看基本的使用
//设置连接池的相关配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(2);
poolConfig.setMaxIdle(1);
poolConfig.setMaxWaitMillis(2000);
poolConfig.setTestOnBorrow(false);
poolConfig.setTestOnReturn(false);
//设置Redis信息
String host = "127.0.0.1";
JedisShardInfo shardInfo1 = new JedisShardInfo(host, 6379, 500);
shardInfo1.setPassword("test123");
JedisShardInfo shardInfo2 = new JedisShardInfo(host, 6380, 500);
shardInfo2.setPassword("test123");
JedisShardInfo shardInfo3 = new JedisShardInfo(host, 6381, 500);
shardInfo3.setPassword("test123");
//初始化ShardedJedisPool
List infoList = Arrays.asList(shardInfo1, shardInfo2, shardInfo3);
ShardedJedisPool jedisPool = new ShardedJedisPool(poolConfig, infoList);
//进行查询等其他操作
ShardedJedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set("test", "test");
jedis.set("test1", "test1");
String test = jedis.get("test");
System.out.println(test);
......
} finally {
//使用后一定关闭,还给连接池
if(jedis!=null) {
jedis.close();
} 四、Redis集群的折中方案:中间件实现的Redis集群
1. Twemproxy
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。
当然,Twemproxy本身也是单点,需要用Keepalived做高可用方案。通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和在redis性能有一定的损失(twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。不熟悉twemproxy的同学,如果玩过nginx反向代理或者mysql proxy,那么你肯定也懂twemproxy了。其实twemproxy不光实现了redis协议,还实现了memcached协议,什么意思?换句话说,twemproxy不光可以代理redis,还可以代理memcached。
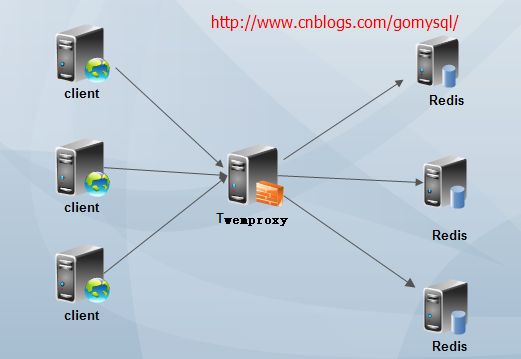
但是从上面我们可以看到这样以来Twemproxy就成了单点,所以通常会结合keepalived来实现Twemproxy的高可用。架构图如下:
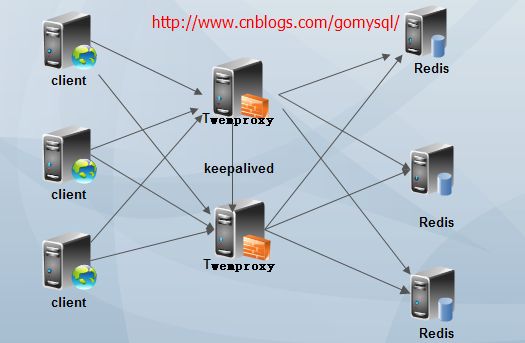
上面的架构通常只有一台Twemproxy在工作,另外一台处于备机,当一台挂掉以后,vip自动漂移,备机接替工作。
2. Codis
Codis是一个分布式的Redis解决方案(豌豆荚),对于上层的应用来说,连接Codis Proxy和连接原生的Redis Server没有明显的区别(不支持的命令列表),上层应用可以像使用单机的Redis一样使用,Codis底层会处理请求的转发,不停机的数据迁移等工作,所有后边的一切事情,对于前面客户端来说是透明的,可以简单的认为后边连接是一个内存无限大的Redis服务。

以上我们可以看到codis-proxy是单个节点的,因为我们可以通过结合keepalived来实现高可用:
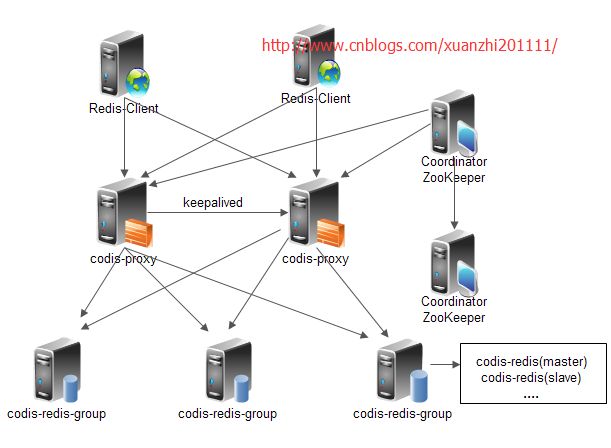
其系统中包含的组件如下:
codis-proxy : 是客户端连接的Redis代理服务,codis-proxy 本身实现了Redis协议,表现得和一个原生的Redis没什么区别(就像Twemproxy),对于一个业务来说,可以部署多个codis-proxy,codis-proxy本身是没状态的。
codis-config :是Codis的管理工具,支持包括,添加/删除Redis节点,添加/删除Proxy节点,发起数据迁移等操作,codis-config本身还自带了一个http server,会启动一个dashboard,用户可以直接在浏览器上观察Codis集群的状态。
codis-server:是Codis项目维护的一个Redis分支,基于2.8.13开发,加入了slot的支持和原子的数据迁移指令,Codis上层的codis-proxy和codis-config只能和这个版本的Redis交互才能正常运行。
ZooKeeper :用来存放数据路由表和codis-proxy节点的元信息,codis-config发起的命令都会通过ZooKeeper同步到各个存活的codis-proxy
具体搭建过程见Codis集群的搭建与使用。
五、Redis集群的官方方案:Redis Cluster
Redis 3正式推出了官方集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。
redis的集群分区,最主要的目的都是在移除、添加一个节点时对已经存在的缓存数据的定位影响尽可能的降到最小。redis将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点, 比如说:
1. 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
2. 与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线,从而保证集群的可用性。
1. Redis Cluster的架构
Redis 集群键分布算法使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 它们的编号为0、1、2、3……16382、16383,这个槽是一个逻辑意义上的槽,实际上并不存在。redis中的每个key都属于这 16384 个哈希槽的其中一个,存取key时都要进行key->slot的映射计算。
和memcached一样,redis也采用一定的算法进行键-槽(key->slot)之间的映射。memcached采用一致性哈希(consistency hashing)算法进行键-节点(key-node)之间的映射,而redis集群使用集群公式来计算键 key 属于哪个槽:
HASH_SLOT(key)= CRC16(key) % 16384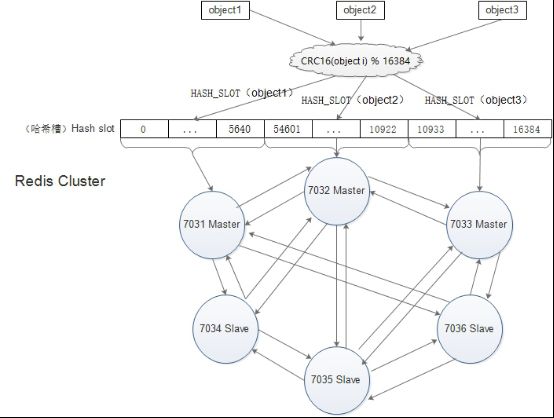
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上(哈希槽),cluster 负责维护。
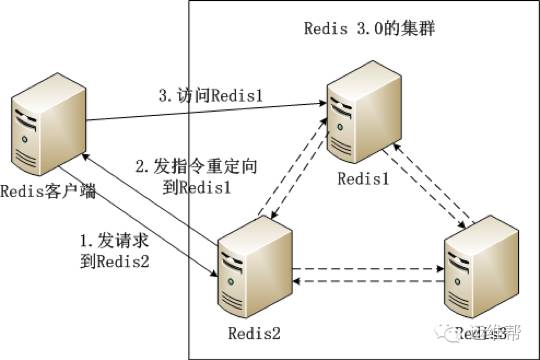
Redis集群内的机器定期交换数据,工作流程如下。
(1) Redis客户端在Redis2实例上访问某个数据。
(2) 在Redis2内发现这个数据是在Redis3这个实例中,给Redis客户端发送一个重定向的命令。
(3) Redis客户端收到重定向命令后,访问Redis3实例获取所需的数据。
2. Redis-cluster投票:容错
(1) 领着投票过程是集群中所有master参与,如果半数以上master节点与其中一个master节点通信超时(cluster-node-timeout),认为当前master节点挂掉.
(2) 什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error)CLUSTERDOWN The cluster is down)错误。
3. Redis的问题
Redis 3.0的集群方案有以下两个问题。
1. 一个Redis实例具备了“数据存储”和“路由重定向”,完全去中心化的设计。这带来的好处是部署非常简单,直接部署Redis就行,不像Codis有那么多的组件和依赖。但带来的问题是很难对业务进行无痛的升级,如果哪天Redis集群出了什么严重的Bug,就只能回滚整个Redis集群。
2. 对协议进行了较大的修改,对应的Redis客户端也需要升级。升级Redis客户端后谁能确保没有Bug?而且对于线上已经大规模运行的业务,升级代码中的Redis客户端也是一个很麻烦的事情。
综合上面所述的两个问题,Redis 3.0集群在业界并没有被大规模使用。
六、云服务器上的集群服务
国内的云服务器提供商阿里云、UCloud等均推出了基于Redis的云存储服务。这个服务的特性如下。
(1)动态扩容
用户可以通过控制面板升级所需的Redis存储空间,扩容的过程中服务部不需要中断或停止,整个扩容过程对用户透明、无感知,这点是非常实用的,在前面介绍的方案中,解决Redis平滑扩容是个很烦琐的任务,现在按几下鼠标就能搞定,大大减少了运维的负担。
(2)数据多备
数据保存在一主一备两台机器中,其中一台机器宕机了,数据还在另外一台机器上有备份。
(3)自动容灾
主机宕机后系统能自动检测并切换到备机上,实现服务的高可用。
(4)实惠
很多情况下为了使Redis的性能更高,需要购买一台专门的服务器用于Redis的存储服务,但这样子CPU、内存等资源就浪费了,购买Redis云存储服务就很好地解决了这个问题。
有了Redis云存储服务,能使App后台开发人员从烦琐运维中解放出来。App后台要搭建一个高可用、高性能的Redis服务,需要投入相当的运维成本和精力。如果使用云存储服务,就没必要投入这些成本和精力,可以让App后台开发人员更专注于业务。