Python爬虫——爬取阳光高考网高校信息
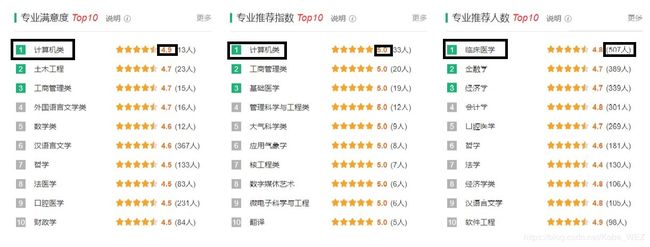
在本次学习中主要爬取的内容如下
就简单粗暴直接献上代码吧
import requests
import time
import json
from bs4 import BeautifulSoup
def get_one_page():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
num1=0
num2=0
num3=0
for n in range(0, 8):
offset = n * 20
url = 'https://gaokao.chsi.com.cn/sch/search.do?searchType=1&ssdm=44&start=0' + str(offset)
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html5lib")
hello = soup.find_all('td', class_="js-yxk-yxmc")
for i in range(len(hello)):
one=hello[i].a.text.strip()
two=hello[i].a['href']
wez="https://gaokao.chsi.com.cn"+two
print(one)
r = requests.get(wez, headers=headers)
soup = BeautifulSoup(r.text, "lxml")
nihao = soup.find_all('table', class_="zy-lsit")[0]
print("专业满意度top10:")
name = nihao.find_all('div', class_="overf")
number = nihao.find_all('span', class_="avg_rank")
data1 = []
data2 = []
data3 = []
school_data1 = []
for j in range(len(name)):
school=one
three = name[j].text.strip()
four = number[j].text.strip()
num1+=1
data1.append([school,three,four,num1])
for each in data1:
school_data1.append({
"id": each[0],
"type": each[1],
"score": each[2],
"num": each[3]
})
with open('type1.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(school_data1, indent=2, ensure_ascii=False))
print("专业推荐指数top10:")
nihao2 = soup.find_all('table', class_="zy-lsit")[1]
name2 = nihao2.find_all('div', class_="overf")
number2 = nihao2.find_all('span', class_="avg_rank")
for j in range(len(name2)):
school = one
five = name2[j].text.strip()
six = number2[j].text.strip()
num2 += 1
data2.append([school, five, six, num2])
print(school,five, six, num2)
school_data2=[]
for each in data2:
school_data2.append({
"id":each[0],
"type":each[1],
"score":each[2],
"num":each[3]
})
with open('type2.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(school_data2, indent=2, ensure_ascii=False))
print("专业推荐人数top10:")
nihao3 = soup.find_all('table', class_="zy-lsit")[2]
name3 = nihao3.find_all('div', class_="overf")
number3 = nihao3.find_all('span', class_="vote_num_detail")
for j in range(len(name3)):
school = one
seven = name3[j].text.strip()
eight = number3[j].text.strip()
num3 += 1
data3.append([school, seven, eight, num3])
print(school,seven, eight, num3)
school_data3 = []
for each in data3:
school_data3.append({
"id": each[0],
"type": each[1],
"score": each[2],
"num": each[3]
})
with open('type3.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(school_data3, indent=2, ensure_ascii=False))
print("\n")
time.sleep(1)
if __name__ == '__main__':
get_one_page()
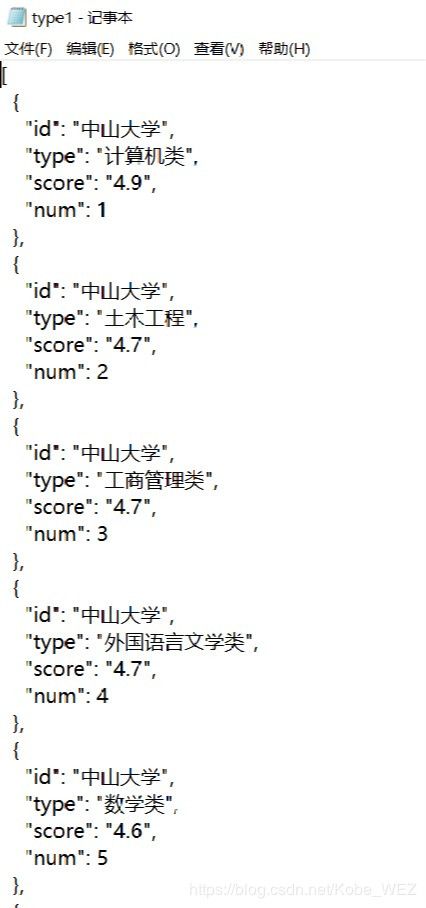
保存到json文件后显示如下