阿里巴巴大数据之路读书分享
阿里巴巴大数据之路读书分享
文章目录
- 阿里巴巴大数据之路读书分享
- 前言
- 阿里巴巴大数据系统的体系架构图及介绍
- 数据采集层
- 数据采集
- 数据传输
- 数据计算层
- 离线数据开发
- 实时数据开发
- 数据服务层
- 数据应用
- 数据模型
- 模型体系架构
- 模型实施
- 维表设计
- 事实表设计
- 规范定义
- 结语
前言
《阿里巴巴大数据之路》业内公认好书,几乎人手一本,奈何绝版了。托公司的福,有幸拜读此书。特分享下本人的所读所感。
本人将借用两张图来介绍此书,其一阿里巴巴的大数据系统的体系架构图,有利于系统全面了解阿里巴巴的数据平台。其二模型实施过程图,也是与本人现从事的工作密切相关。
阿里巴巴大数据系统的体系架构图及介绍
阿里巴巴的大数据系统的体系架构图,从图中可以清晰地看到数据体系主要划分为数据采集层、数据计算层、数据服务层及数据应用层,使人对数据体系有个整体的概念。后面的内容就是围绕这张图展开的。
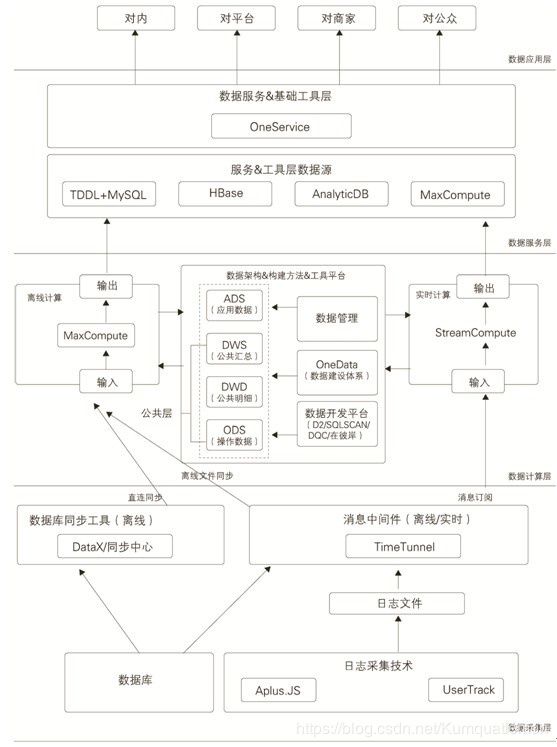
数据采集层
数据采集
阿里巴巴数据采集体系包括量大体系:Web端和App端,Aplus.JS是Web端的日志采集方案;UserTrack是App端的日志采集方案。
Web端日志采集介绍了,浏览器页面日志采集和交互日志采集,交互日志采集(即 “黄金令牌”)是一个开放的基于HTTP协议的日志服务。
无线客户端日志采集采用采集SDK来完成,移动端日志采集根据不同的用户行为分成不同的事件,基于常规分析把事件分为页面事件和控件点事件及其他特殊场景。
相比于阿里大多公司对于数据采集的现状:由于长期经营线下,对于web,app等的主动采集能力是偏弱的,一般数据管理部门对于web或app端的采集基本是源端推送过来的文件,对于采集没有实际主导权,同时无论是web的js脚本还是app的sdk,实际上都是有一定的技术门槛。
数据传输
阿里巴巴的数据同步分为批量同步与实时同步,批量同步结构化数据采用DataX框架进行同步,实时数据同步采用TimeTunnel中间件进行解析同步数据库系统binlog日志或归档日志等。在数据同步过程中对一些问题进行了处理,值得借鉴:
1.现在分库分表越来越多,对于数据同步的配置越加复杂,阿里巴巴的TDDL分布式数据库访问引擎,通过建立中间状态的逻辑表来整合统一分库分表的访问。
2.数据同步过程中相似且重复的工作特别多,阿里巴巴通过oneClick产品,真正实现了数据的一键化和批量化同步,一键完成DDL和DML的生成,数据的冒烟测试以及生产环境中的测试等。
3.数据时间漂移的处理:多获取一部分第二天的数据(比如跨日以后的15分钟),然后根据可以判断业务时间的字段,过滤,排序等方式来得到需要的数据。
数据计算层
离线数据开发
1.离线计算平台Maxcompute。Maxcompute由SQL、MR、Graph、Spark、R、Volume组件组成。
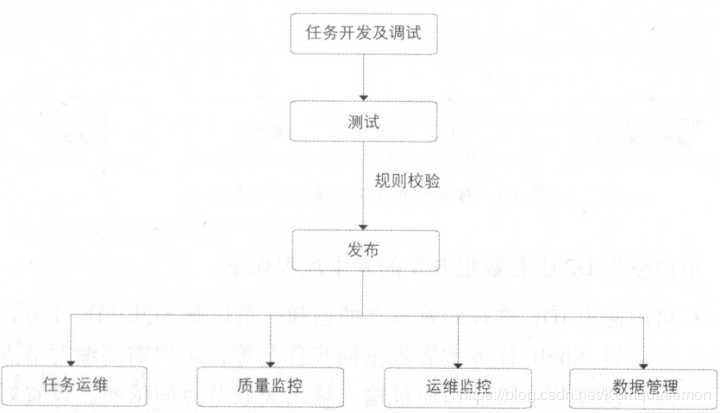
2.统一开发平台有在云端(D2)、SQLSCAN、调度运维系统、DQC、在彼岸几大功能模块组成。
其中D2是集成任务开发、调试及发布、生产任务调度及大数据运维、数据权限申请及管理功能的一站式数据开发平台,并能承担数据分析工作台的功能。
SQLSCAN结合D2对代码进行规制检测,具体包括代码规范类检测,如表命名规则、生命周期、注释等。代码质量检测,如调度参数、分母0、NULL值等。代码性能检测,如分区、大表、重复计算等。分强弱两类规则,强规则打断执行,弱规则只是提示。
DQC数据质量监控,常见DQC监控主键监控、表数据量及波动监控、重要字段非空监控、重要枚举字段离散值监控、指标值波动监控、业务规则监控等。分强弱两类规则,强规则打断执行,弱规则只是提示。
在彼岸提供数据测试功能,主要验证数据是否符合预期。具体包括数据对比、数据分布、数据脱敏。
调度系统分为调度引擎(phoenix Engine)和执行引擎(Alisa)两个子系统,调度引擎负责工作流规划,管理任务管理到任务就绪状态,执行引擎则负责后面的具体任务执行动作,管理包括执行,成功,失败重试等等状态变化。
实时数据开发
阿里巴巴基于TimeTunnel来进行实时数据的采集,原理和Kafka等消息中间件类似,采用StreamCompute进行流式处理,跟Storm,Stream也类似。对于实时统计的问题,阿里巴巴提的些方案值得借鉴。
1.去重指标精确去重可以通过数据倾斜来进行处理,把一个节点的内存压力分到多个节点,在模糊去重的前提下,可以采用相关的去重算法,把内存使用量降到千分之一甚至万分之一,布隆过滤器就是一种,其简单来讲就是不保存明细数据,只保留明细数据对应哈希值的标记位,当然会出现哈希值碰撞的情况。
2.数据倾斜对去重值进行分桶。
3.事务处理,提供数据自动ACK、失败重发以及事务信息机制。通过超时时间、事务信息、备份机制保证数据的完整性。
4.由于实时任务大多是多线程处理的,意味着数据存储必须能够较好的支持多并发读写,并且延时需要在毫秒级才能满足实时的性能要求,一般使用Hbase,Tair等列式数据存储系统。
5.实时模型跟离线模型的建模理念是一致的,比如阿里的流式模型分为五层,ODS层、DWD层、DWS层、ADS层及DIM层,关于每层的含义在会在后续模型模块进行介绍。
数据服务层
数据服务平台可以叫数据开放平台,数据部门产出海量数据,如何能方便高效地开放出去,是我们一直要解决的难题,在没有数据服务的年代,阿里的数据开放的方式简单、粗暴,一般是直接将数据导出给对方,我们也是。
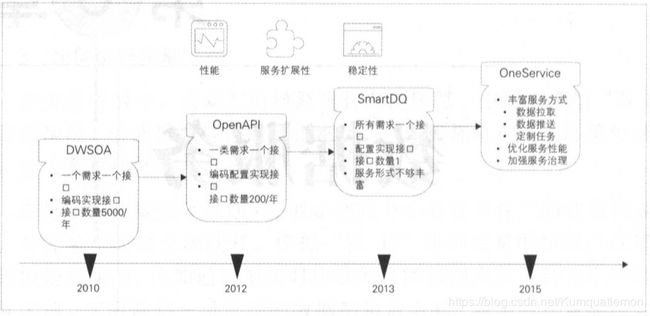
阿里的数据开放经历四个阶段,DWSOA、OpenAPI、SmartDQ和OneService。
1、DWSOA:一个需求一个接口,编码实现接口。明显问题是烟囱式开发,很难沉淀共性数据,灵活性不高,扩展性差,复用率低,随着业务需求的增加,接口的数量大幅增加。
2、OpenAPI:一类需求一个接口,配置实现接口,接口数量200/年。相比上一种方式,这种方式有效收敛了数量。缺点数据维度是非可控的,随着数据的深度使用,OpenAPI显然会急剧增加,维护映射的压力会很大。
3、SmartDQ:支撑标准的SQL,这降低了数据服务的维护成本。传统的方式查问题需要查源码,确认逻辑,而SmartDQ只需要检查SQL的工作量,并可以开放给业务方通过写SQL的方式对外提供服务,SmartDQ封装了跨域数据源和分布式查询功能,通过逻辑表屏蔽了底层的物理表细节,不管是HBASE还是MySQL,是单表还是分库分表,这极大简化了操作的复杂度。缺点SQL无法解决复杂的业务逻辑,SmartDQ其实只能满足简单的查询服务需求。
4、OneService:OneService主要是提供多种服务类型来满足客户需求,分别是OneService-SmartDQ、OneService-Lego、OneService-iPush、OneService-uTiming。
5、看阿里还搞了数据挖掘中台,挺让人惊叹,阿里将数据挖掘中台数据分为三层:特征层(FDM)、中间层和应用层(ADM),其中中间层包括个体中间层(IDM)和关系中间层(RDM)感兴趣的可以看下。
数据应用
阿里主要介绍了对外的数据产品平台生意参谋和服务于内部的数据产品平台。
生意参谋本质上就是为自己的渠道提供的增值服务,进而实现“数据赋能商家”这一重要理念。
当前阿里的数据产品平台,包括PC和APP版本,共有四个层次,即数据监控、专题分析、应用分析及数据决策。
数据模型
数据建模在这本书占据了三分之一篇幅,可见其重要性。关于模型的分层每个行业都可以基于自己的实际去划分,没有所谓的最佳实践。
阿里选择了以Kimball的维度建模为核心理念的模型方法论,同时进行了一定的升级和扩展,构建了阿里巴巴集团的公共层模型数据架构体系。
模型体系架构
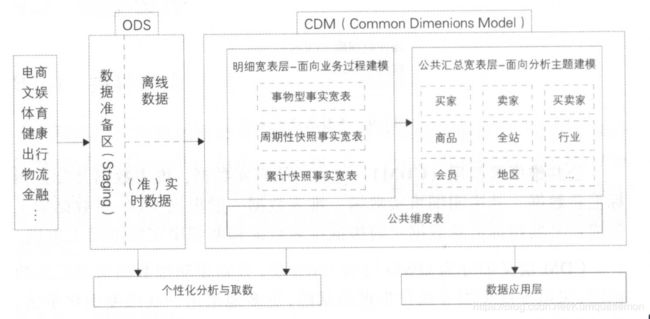
阿里的模型分为三层:操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),模型层包括明细数据层(DWD)和汇总数据层(DWS)。
ODS:把操作系统数据几乎无处理的存放到数据仓库系统中。
CDM:又细分为DWD和DWS,分别是明细数据层和汇总数据层,采用维度模型方法作为理论基础,更多采用一些维度退化方法,将维度退化至事实表中,减少事实表和维表的关联,提高明细数据表的易用性,同时在汇总数据层,加强指标的维度退化,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性。
ADS:存放数据产品个性化的统计指标数据,根据CDM与ODS加工生成。
模型设计基本原则:
1.高内聚低耦合,业务想近相关高概率同时访问的放一起
2.核心模型与扩展模型分离,扩展模型支持少量的个性化需要
3.公共处理逻辑下沉及单一,公共处理逻辑不出现在上层及多次存在
4.成本与性能平衡,适当退化维度冗余数据
5.数据可回滚,多次运行结果不变
6.一致性,字段命名及含义一致
7.命名清洗可理解,表名
模型实施
OneData是阿里的模型设计理论,我觉得写得很好,你看完这部分,基本会搞清楚维度建模的各个步骤,强烈建议结合维度和事实表建模进行精读,主要步骤如下:
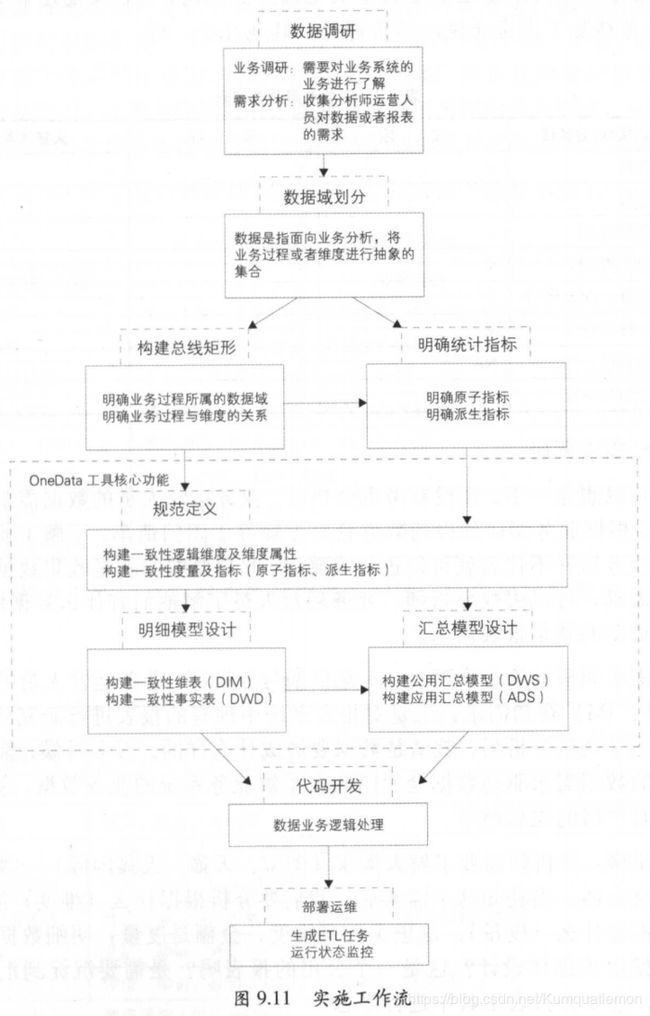
数据调研:业务调研需要对业务系统的业务进行了解,需求分析则是收集分析师运营人员对数据或者报表的需求,报表需求实际是最现实的建模需求的基础。
架构设计:分为数据域划分和构建总线矩阵,数据域划分是指面向业务分析,将业务过程或者维度进行抽象的集合,业务过程可以概括为一个个不可拆分的行为事件,如下单、支付等。构建总线矩阵需要明确每个数据域下游哪些业务过程,业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
规范定义:规范定义主要定义指标体系,包括原子指标、修饰词、时间周期和派生指标,关于指标的规范定义阿里有单独的一节描述,很多时候细节决定成败,最重要的还是有一个统一、规范、可共享的体系。全公司以统一的方式、理解、分类、数据,才能有更完善的可用的数据模型。
模型设计:模型设计主要包括维度及属性的规范定义、维表、明细事实表和汇总事实表的模型设计。
维表设计
维度,业务所处的环境描述为维度,维度所包含的列成为维度属性。
维度设计步骤:确定主维度->确定相关维度->确定维度属性
维度整合与拆分:
垂直整合,来源包含相同的数据集,只是存储的信息不同,垂直拆分反之(拆信息)
水平整合,来源表包含不同的数据集,生成新的维度键,水平拆分反之(拆分类)
缓慢变化维,维度是会发生变化的,通常pt=0取最新值,保留多条,添加字段区分,快照
极限存储,处理缓慢变化维,适合大数据量变化又不是特别频繁的情况。极限存储的一个总体思想就是通过给表记录设定生命周期的方式,减少重复存储的那些记录。在上层做一个视图,对极限存储表进行查询。保留全量数据,全量数据分成当前更新记录和未更新记录,历史更新过的记录称为死亡记录。
查询语句比较:
原访问当天数据 select * from A where ds=20160601;
等价于
select * from A_EXST where start_dt<=20160601 and end_dt>20160601;
微型维度,某一维度列过度增长->拆分->微型维度
特殊维度,
1、具有递归层次的层次结构扁平化、层次桥接表
2、多值维度 放多个字段中,桥接表 分组key
杂项维度,不能没有偶尔要用的,合并到一张表生成代理键
事实表设计
事实表设计原则:
尽可能包含所有与业务相关的事实
只选择与业务相关的事实
分可加和不可加组件
声明粒度
一个事实表中不能有多个不同粒度的事实
单位一致
null值处理
使用退化维度提高事实表的易用性
具体实施:声明粒度->确定维度->确定事实->冗余维度
事实表分类
事务事实表(可加,单事务事实表、多事务事实表
周期快照事实表,通常以维度形式声明粒度 卖家/买家 时间
累计快照事实表,数据不断更新,多业务过程日期
无事实的事实表,会员浏览日志
聚集性事实表,公共汇总层
规范定义
阿里数据仓库建设一直在强调规范定义,从下面这张派生指标解释既可以看出其规范的全面且易于理解

结语
阿里巴巴大数据架构之所以是行业学习的风向标,我觉得最大的原因是与时俱进的站在技术的前沿。致敬福娃的辛勤智慧,向智者看齐!!