【论文笔记】An End-to-End Model for QA over KBs with Cross-Attention Combining Global Knowledge
一、概要
该文章发于ACL 2017,在Knowledge base-based question answering (KB-QA)上,作者针对于前人工作中存在没有充分考虑候选答案的相关信息来训练question representation的问题,提出了一个使用Cross-Attention机制的神经网络模型来针对于候选答案的不同方面信息来训练模型;并且训练知识库的全局信息学习,在一定程度上减轻的the out of vocabulary (OOV)问题,最终在数据集 WEBQUES- TIONS上取得不错的效果。
二、模型方法
2.1 模型简介
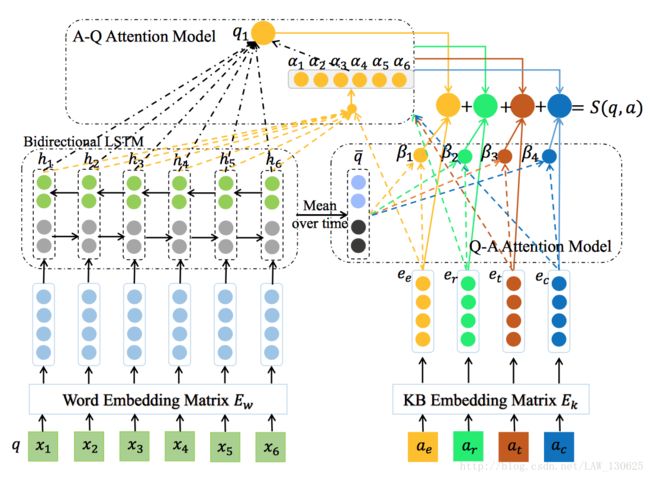
KB-QA的目标是给出一个用自然语言表达的问题,返回在实体集合A作为问题的答案。本文的模型如下图所示,首先使用Freebase API识别出问题中的实体,在知识库中找到候选答案,然后使用Attention机制的神经网络针对候选答案的answer entity、answer relation、answer type、以及answer context四个方面分别训练对应的question representation和及其representation,最后使用相似度得分来选出最终的答案。本文的方法与Li Dong等人提出的方法非常类似,具体可看:【论文笔记】Question Answering over Freebase with Multi-Column Convolutional Neural Networks,但其实大有不同,比如/business/board member 和/location/country 都是表示答案类型,但是因为它们的Attention不同,最后得到的question representation也会不同。

2.2 Question Representation
首先,我们需要获取到问题中每个词的representation,假设存在问题 q=(x1,x2,...,xn) , xi 表示问题中的第i个单词,如下图所示,我们通过look up在 Ew∈Rd×vw 中获得每个单词的embeddings, Ew∈Rd×vw 是随机初始化的矩阵,并在模型虚拟立案过程中训练,d表示单词representation的维度, vw 表示所有问题单词集合的元素的个数,然后将这些词向量传入LSTM中,LSTM模型已经被证明在许多NLP问题上表现得非常好,同时为了考虑到每个词的前后词汇的信息,这里使用了双向LSTM,LSTM的隐藏单元输出维度为d/2,最后将双向LSTM的输出连接起来,即得到维度为d的向量。
2.3 Answer aspect representation
在答案方面,直接通过KB embedding 矩阵 Ek∈Rd×vk 获得上面提到四个方面的embedding,其中 vw 表示KB中词表的大小, Ek 也随着模型训练而不断学习优化,我们将answer entity , answer relation , answer type,以及answer context分别表示为 ae、ar、at、ac ,其对应的embedding分别表示为 ee、er、et、ec ,值得注意的是answer context 来自于知识库中的多个方面,可以表示为 (c1,c2,...,cn) ,我们先通过 Ek 获得KB embeddings为: (ec1,ec2,...,ecn) ,最后算它们的平均embeddings,即: ec=1n∑ni=1eci 。
2.4 Cross-Attention model
①Answer-towards-question(A-Q) attention
这是本文最关键的一部分,根据答案的 ei∈(ee、er、et、ec) ,可以对LSTM中输出的word representation hj 给予不同的权重,即不同的关注度,其计算方法如下:
其中 aij 表示第i个词的Attention权重,n为问题的单词个数, W∈R2d×1 为中间矩阵,b为偏置值,然后这些Attention权重被用来与对应的词向量计算得到句子语义向量,即:
最后问题和候选答案的相似度计算方法如下:
②Question-towards-answer(Q-A) attention
直觉上的,不同的问题在应该也有相关方面的重点,即对于四个不同的答案方面应该也有不同的Attention,那么最终的loss函数计算公式为:
其中 βei 就是答案各个方面得分的权重。
2.5 Training
首先对于训练集中的question-answer pairs (q, a),对于候选答案集 Cq 可以分别为正确答案集 Pq 和错误答案集 Nq ,对于每一个正确答案 a∈Pq ,随机在 Nq 选择k个错误答案组成进行训练,构造的loss函数为:
其中 [z]+ =max(0, z),那么我们的目标是训练使得正确答案的得分比错误答案得分超出 γ ,综合可以的目标函数为:
最终使用stochastic gradient descent (SGD)进行训练模型。
在测试阶段,直接在候选答案中计算每个候选答案的得分:
值得注意的是因为存在问题可能不止有一个正确答案,所以设置一个标准来作为选择最终答案的标准,即为:
同时为了处理the out of vocabulary (OOV),即在候选答案可能从未在训练集中出现过,本文使用TransE对整个知识库进行训练,通过轮流训练KB-QA模型和TranE的方式训练并共用Embedding矩阵 Ek ,每训练一个epoch的KB-QA,那么就训练100个epoch的TransE,通过这样可以充分使用了整个知识库的特性,预先对每一个知识库实体都进行了训练,使得相似实体的分布式表达也很相似;其具体训练方法是假设存在三元组事实(s, p, o),使用黑体 (s, p, o) 表示它们的embeddings,那么它们应该尽量满足: (s + p ≈ o) ,换种方式,可以定义d(s+p, o) 为 ∥s + p − o∥22 ,那么TransE应最小化下面的loss函数:
三、实验结果


上面第一个图中可以看出本文的方法取得了不错的成绩,虽然存在另外一个很高的成绩,但是那里使用到了大量的手动特征,并且这些特征是基于训练集中观察得到的,而本文的方法完全基于数据训练而来,所以更具有普遍性,所以与那个结果不具有对比性。在第二个图中,颜色越深代表权重越大,可以看出在答案的各个方面,每个词代表的权重很符合我们人类的思维。
四、结论与思考
本文针对于KB-QA任务,提出了一个新的使用Attention机制的神经网络,根据不同的答案的类型基于问题中不同单词的权重,这种思维很符合人类的思维,并且使用TransE对整个知识库进行训练,一定程度解决了OOV问题,与其它基于NN的方法相比,本文提出的方法可以实现更好的性能。
五、个人思考
①首先感叹一下Attention机制的强大,在本文中其思想更是体现得非常的妙,但是结果没有取得很大的突破,如果加上CNN在前期进行特征的提取,以及在候选答案的representation也使用神经网络训练,效果会不会更好?但是模型可能会很大吧。。。
参考文献
①An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge