基于谱减法的音频信号噪声抑制的Matlab和C语言分别实现并对比
一、语音和噪声
1、冲激噪声
冲激噪声的时域波形是类似于冲激函数那样的窄脉冲,常见的消除冲激噪声的方式有两种:
(1)对带噪语音信号的幅值求均值,将该均值作为判断的标准,超过该标准的视作噪声,在时域将其滤除
(2)当噪声不太密集的时候,可以通过某些点内插的方法避开或者平滑掉冲激点,从而从语音信号中去掉冲击噪声。
2、周期噪声
常见的噪声是50Hz的交流电产生的周期噪声。在频谱图上展现为离散的窄谱。可以采用陷波器将其去除掉
3、宽带噪声
说话时同时伴随着呼吸引起的噪声、随机噪声源产生的噪声以及量化噪声等都可视为宽带噪声。宽带噪声的特点是噪声频谱遍布于整个语音信号频谱中,一般采用非线性方法滤除。
4、语音干扰
干扰语音和待传语音信号同时在一个信道中传输所造成的语音干扰。区别有用语音和干扰语音的基本方法是利用其基音差别。一般情况下两种语音的基音不同,也不成整数倍,因此可以用梳妆滤波器提取基音和各谐波。
二、谱减法
处理宽带噪声的最通用技术是谱减法。它利用语音信号的短时平稳特性,从带噪语音的短时谱值中减去噪声的短时谱,从而得到纯净语音的频谱,达到语音增强得目的。
谱减法包括幅度谱减法和功率谱减法: 幅度谱减法就是在频域中从带噪语音的幅度谱上减去噪声的幅度谱作为语音信号的幅度谱;功率谱减法则是从带噪语音的功率谱中减去噪声的功率谱, 得到纯净语音的功率谱估计, 通过开方运算得到幅度谱。由于人耳对语音频谱分量的相位感知不敏感, 因此这些算法都是在幅度上进行的修正, 相位部分则保持不变, 仍然使用带噪语音的相
位。
谱减法通过从带噪语音的短时谱估值中减去噪声的短时谱来达到语音增强得目的, 算法简单且容易实现。但在减去噪声谱后, 还会有些较大功率谱分量的剩余部分, 在频谱上呈现出随机出现的尖峰,在听觉上形成残留噪声。这种噪声具有一定的节奏性起伏感,被称之为“音乐噪声”。
三、Matlab实现谱减法
使用Matlab对语音信号进行分析,首先对原始语音信号进行加噪处理(高斯随机噪声),然后使用谱减法去噪。
% 选择.wav音频文件
[fname,pname]=uigetfile(...
{'*.wav';'*.*'},...
'Input wav File');
[x,fs] = audioread(fullfile(pname,fname));
x = x(1:8912,1); % 如果是双声道,取单通道
N = length(x); % 帧长
max_x = max(x);
noise_add = random('norm', 0, 0.1*max_x, [N,1]);
% 添加高斯噪声
y = x + noise_add;
noise_estimated = random('norm', 0, 0.1*max_x, [N,1]);
fft_y = fft(y);
fft_n = fft(noise_estimated);
E_noise = sum(abs(fft_n)) / N;
mag_y = abs(fft_y);
phase_y = angle(fft_y); % 保留相位信息
mag_s = mag_y - E_noise;
mag_s(mag_s<0)=0;
% 恢复
fft_s = mag_s .* exp(1i.*phase_y);
s = ifft(fft_s);
subplot(311);plot(x);ylim([-1.5,1.5]);title('原始干净信号');
subplot(312);plot(y);ylim([-1.5,1.5]);title('加噪信号');
subplot(313);plot(real(s));ylim([-1.5,1.5]);title('谱减法去噪后信号');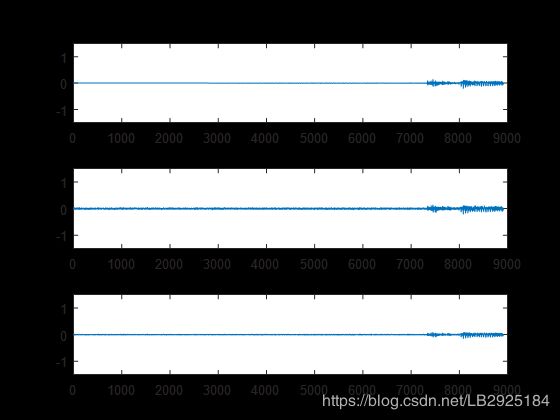
通过图片可知,原始语音加入高斯随机噪声后,波形发生明显改变,通过谱减法能够比较好的抑制音频信号的噪声,不过经过谱减法后信号波形的幅度会减小。
四、C语言实现谱减法
#include
#include
#include
#define WL 256 // 窗长
#define P 10 // 预测系数
#undef pi
#define pi 3.1415926535897932384626434
#define PI 3.1415926
#define winsize 256
#define tempsize winsize/2
#define buffsize winsize*10
typedef struct{
double real;
double img;
}complex;
unsigned int f=0;
unsigned int c=0;
complex noise[winsize];
double buff_r[buffsize];
double buff_w[buffsize];
double temp[tempsize];
complex x[winsize];
complex y[winsize];
int hr=0;
complex W[winsize];
complex W1[winsize];
double x_abs[winsize];
double y_abs[winsize];
double noise_abs[winsize];
void fft(complex *x,int size_x,complex *W); /*快速傅里叶变换*/
void ifft(complex *x,int size_x,complex *W1);
double angle(complex a); //
void add(complex ,complex ,complex *); /*复数加法*/
void mul(complex ,complex ,complex *); /*复数乘法*/
void sub(complex ,complex ,complex *); /*复数减法*/
void change(complex *x,int size_x); /*数组转置*/
double abs1(complex a);
void hamming(complex hw[]);
int ReadWaveFile( char *fn,int *fs,short **dat );
int ReadWaveFile(
char *fn, // I: 文件名
int *fs, // O: 文件大小
short **dat // O: 语音数据
)
{
FILE *fp;
int dsize;
if ((fp = fopen(fn,"rb+")) == NULL) {
fprintf(stderr,"%s: No such file \n", fn);
return(-1);
}
fseek(fp, 0L, SEEK_END);
dsize = ftell(fp)/2;
fseek(fp, 0L, SEEK_SET);
if ((*dat = (short *)malloc(sizeof(short)*dsize)) == NULL) {
fprintf(stderr,"Memory Error \n");
return(-1);
}
if (fread(*dat, sizeof(short), dsize, fp) != (unsigned int)dsize) {
free(*dat);
return(-1);
}
fclose(fp);
*fs = dsize;
return(0);
}
void hamming(complex hw[])
{
double x;
int i;
for(i=0;i0 ){
j=j<<1;
j|=(k&1);
k=k>>1;
}
if(j>i){
temp=x[i];
x[i]=x[j];
x[j]=temp;
}
}
}
void ifft(complex *x,int size_x,complex *W1)
{
int i=0,j=0,k=0,l=0,jk=0;
complex up,down,product;
change(x,size_x);
for(i=0;ireal=a.real+b.real;
c->img=a.img+b.img;
}
void mul(complex a,complex b,complex *c){
c->real=a.real*b.real - a.img*b.img;
c->img=a.real*b.img + a.img*b.real;
}
void sub(complex a,complex b,complex *c){
c->real=a.real-b.real;
c->img=a.img-b.img;
}
double abs1(complex a){
double t;
t = (a.real)*(a.real)+(a.img)*(a.img);
return (double) sqrt(t);
}
/**************************主程序*****************************/
void main(void)
{
double wavin[7680], wavout[7680];
complex S[60][256],voice[256];
complex noise1[256];
double noise_foward15frame[15][256];
double am_noise[256];
int fs=8000;
double sum[15][256],voice_timedomain[60][256];
double phase[256];
double am_signal[256];
double am_voice[256];
int frame_len=256,step_len=128,n_frame=15,wav_length=7680,i,j,size_x=256,nifrm,ifrm;
int kk=0,n=1;
for(i=0;i 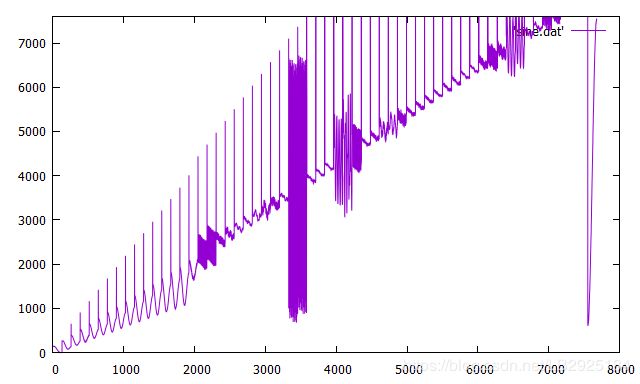
将音频数据写入.dat文件中,用gnuplot使用 plot [0:8000] [-2:7600] 'sine.dat' with line dashtype 1 u 1:2命令调用.dat画图,因数据将近8000个画出的图不是很明显看出,可通过调节相关参数使图像更加可视化。
五、几种改进的谱减算法
(1)非线性谱减
Berouti等人提出的谱减算法,假设了噪声对所有的频谱分量都有同等的影响,继而只用了一个过减因子来减去对噪声的过估计。现实世界中的噪声并非如此,这意味着可以用一个频率相关的减法因子来处理不同类型的噪声。
(2)多带谱减法
在多带算法中,将语音频谱划分为N个互不重叠的子带,谱减法在每个子带独立运行。将语音信号分为多个子带信号的过程可以通过在时域使用带通滤波器来进行,或者在频域使用适当的窗。通常会采用后一种办法,因为实现起来有更小的运算量。
多带谱减与非线性谱减的主要区别在于对过减因子的估计。多带算法针对频带估计减法因子,而非线性谱减算法针对每一个频点,导致频点上的信噪比可能有很大变化。这种剧烈变化是谱减法中所遇到的语音失真(音乐噪声)的原因之一。相反,子带信噪比变化则不会特别剧烈。
(3)MMSE谱减算法
上面的方法中,谱减参数alpha和beta通过实验确定,无论如何都不会是最优的选择。MMSE谱减法能够在均方意义下最优地选择谱减参数。
(4)扩展谱减法
基于自适应维纳滤波与谱减原理的结合。维纳滤波用于估计噪声谱,然后从带噪语音信号中减去该噪声谱。
(5)自适应增益平均的谱减
谱减法中导致音乐噪声的两个因素在于谱估计的大范围变化以及增益函数的不同。对于第一个问题,Gustafsson等人建议将分析帧划分为更换小的子帧以得到更低分辨率的频谱。子帧频谱通过连续平均以减小频谱的波动。对于第二个问题Gustafsson等人提出使用自适应指数平均,在时间上对增益函数做平滑。此外,为了避免因使用零相位增益函数导致的非因果滤波问题,Gustafsson等人建议在增益函数中引入线性相位。
(7)基于感知特性的谱减
前面提到的方法,谱减参数要么是通过实验计算短时信噪比得到,要么是通过最优均方误差得到,均没有考虑听觉系统的特性,该算法的主要目的是使残余噪声在听觉上难以被察觉。利用了人类听觉系统改进系统的可懂度(即人耳的掩蔽效应)。