【并行计算-CUDA开发】【视频开发】ffmpeg Nvidia硬件加速总结
2017年5月25日
0. 概述
FFmpeg可通过Nvidia的GPU进行加速,其中高层接口是通过Video Codec SDK来实现GPU资源的调用。Video Codec SDK包含完整的的高性能工具、源码及文档,支持,可以运行在Windows和Linux系统之上。从软件上来说,SDK包含两类硬件加速接口,用于编码加速的NVENCODE API和用于解码加速的NVDECODE API(之前被称为NVCUVID API)。从硬件上来说,Nvidia GPU有一到多个编解码器(解码器又称硬件加速引擎),它们独立于CUDA核。从视频格式上来说,编码支持H.264、H.265、无损压缩,位深度支持8bit、10bit,色域空间支持YUV 4:4:4和4:2:0,分辨率支持最高8K;解码支持MPEG-2、VC1、VP8、VP9、H.264、H.265、无损压缩,位深度支持8 bit、10bit、12bit,色域空间支持YUV 4:2:0,分辨率支持最高8K。Video Codec SDK已经被集成在ffmpeg工程中,但是ffmpeg对编解码器配置参数较少,如果需要充分的发挥编解码器特性,还需要直接使用SDK进行编程。 
Nvidia编码器与CPU上的x264的性能对比与质量对比如下图所示,性能以每秒钟编码帧数为参考指标,质量以PSNR为参考指标。 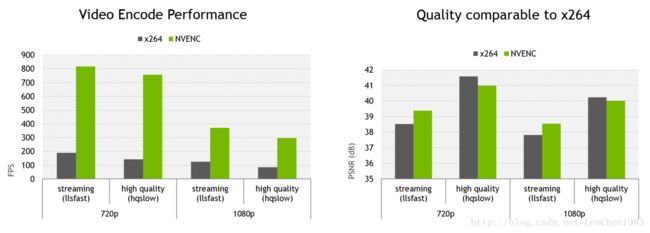
可看出性能方面Nvidia编码器是x264的2~5倍,质量方面对于fast stream场景来说Nvidia编码器优于x264,高质量场景来说低于x264,但没有说明是哪款Nvidia的产品,以及对比测试的x264运行平台的CPU的型号及平台能力。下图可以看出对于1080P@30fps,NVENC可支持21路的编码或9路的高质量编码。 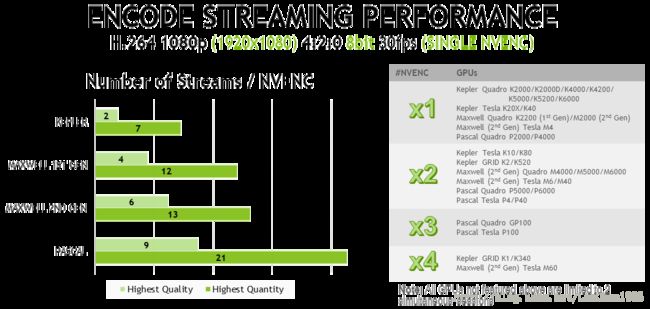
不同型号的GPU的编码的能力表格如下: 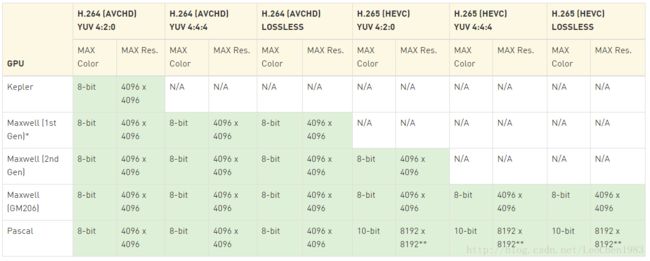
Nvidia解码器性能指标如下图所示,不过只有两款Tesla的产品。 
解码的能力表格如下: 
1. 安装驱动与SDK
1.1 前期准备
需要关闭所有开源的显示驱动
vi /etc/modprobe.d/blacklist.conf
添加
blacklist amd76x_edac
blacklist vga16fb
blacklist nouveau
blacklist nvidiafb
blacklist rivatv
1.2 驱动安装
(1). 删除原来的驱动
apt-get remove –purge nvidia*
(2). 官方下载run文件的驱动进行安装
service lightdm stop
chmod 777 NVIDIA-linux-x86_64-367.44.run
./NVIDIA-Linux-x86_64-367.44.run
service lightdm start
reboot
(2). 驱动安装验证
运行nvidia-smi,有如下输出则安装成功 
问题1:如果重启之后发现图形界面进不去,发生了循环登录,说明视频驱动没有安装完全,需要重装驱动,保险的方法是联网安装
console中执行
apt-get remove –purge nvidia-*
add-apt-repository ppa:graphics-drivers/ppa
apt-get update
service lightdm stop
apt-get install nvidia-375 nvidia-settings nvidia-prime
nvidia-xconfig
apt-get install mesa-common-dev //安装缺少的库
apt-get install freeglut3-dev
update-initramfs -u
reboot
1.3 SDK安装
(1). 官方下载run文件的驱动进行安装
cuda_8.0.44_linux.run –no-opengl-libs //不需要opengl支持
apt-get install freeglut3-dev build-essential libx11-dev
apt-get install libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa
apt-get install libglu1-mesa-dev
gedit ~/.bashrc
添加
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
gedit /etc/ld.so.conf.d/cuda.conf
添加
/usr/local/cuda/lib64
/lib
/lib32
/lib64
/usr/lib
/user/lib32
sudo ldconfig
(2). SDK安装验证
运行nvcc -V,有如下输出则安装成功。 
2. Sample测试
2.1 Sample编译
进入Samples目录,运行make,如果没有安装OpenGL相关库,则NvDecodeGL会编译不通过
每个工程的含义可参考《NVIDIA_Video_Codec_SDK_Samples_Guide》
NvEncoder: 基本功能的编码
NvEncoderCudaInterpo: CUDA surface的编码
NvEncoderD3D9Interpo: D3D9 surface的编码,Linux下没有
NvEncoderLowLatency: 低延时特征的使用,如帧内刷新与参考图像有效性(RPI)
NvEncoderPerf: 最大性能的编码
NvTranscoder: NVENC的转码能力
NvDecodeD3D9: 视频解码D3D9显示,Linux下没有
NvDecodeD3D11: 视频解码D3D11显示,Linux下没有
NvDecodeGL: 视频解码OpenGL显示
2.2 Sample测试
参见《NVIDIA_Video_Codec_SDK_Samples_Guide》
问题2:如果运行例子后显示libcuda.so failed!
在/usr/lib/x86_64-linux-gnu下制作链接libcuda.so,链接至libcuda.so.375.26
3. ffmpeg结合
3.1 ffmpeg编译
3.1.1 前期工作
确保Video_Codec_SDK_7.1.9/Samples/common/inc 目录下有基本的头文件
确保Video_Codec_SDK_7.1.9/Samples/common/lib/linux/x86_64 目录下有libGLEW.a
3.1.2 configure命令
configure \
--enable-version3 \
--enable-libfdk-aac \
--enable-libmp3lame \
--enable-libx264 \
--enable-nvenc \
--extra-cflags=-I/root/workspace/Video_Codec_SDK_7.1.9/Samples/common/inc \
--extra-ldflags=-L/root/workspace/Video_Codec_SDK_7.1.9/Samples/common/lib/linux/x86_64 \
--enable-shared \
--enable-gpl \
--enable-postproc \
--enable-nonfree \
--enable-avfilter \
--enable-pthreads- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.1.2 make
运行make & make install
3.2 ffmpeg测试
运行ffmpeg -codecs|grep nvenc
显示一下信息说明
ffmpeg version 3.0.git Copyright (c) 2000-2016 the FFmpeg developers
built with gcc 5.4.0 (Ubuntu 5.4.0-6ubuntu1~16.04.1) 20160609
configuration: --enable-version3 --enable-libfdk-aac --enable-libmp3lame --enable-libx264 --enable-nvenc --extra-cflags=-I/workspace/Video_Codec_SDK_7.1.9/Samples/common/inc --extra-ldflags=-L/workspace/Video_Codec_SDK_7.1.9/Samples/common/lib/linux/x86_64 --enable-shared --enable-gpl --enable-postproc --enable-nonfree --enable-avfilter --enable-pthreads
libavutil 55. 29.100 / 55. 29.100
libavcodec 57. 54.100 / 57. 54.100
libavformat 57. 48.100 / 57. 48.100
libavdevice 57. 0.102 / 57. 0.102
libavfilter 6. 57.100 / 6. 57.100
libswscale 4. 1.100 / 4. 1.100
libswresample 2. 1.100 / 2. 1.100
libpostproc 54. 0.100 / 54. 0.100
DEV.LS h264 H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10 (encoders: libx264 libx264rgb h264_nvenc nvenc nvenc_h264 )
DEV.L. hevc H.265 / HEVC (High Efficiency Video Coding) (encoders: nvenc_hevc hevc_nvenc )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
其中前缀含义如下:
前缀含义
D….. = Decoding supported
.E…. = Encoding supported
..V… = Video codec
..A… = Audio codec
..S… = Subtitle codec
…I.. = Intra frame-only codec
….L. = Lossy compression
…..S = Lossless compression
3.3 编解码器使用方法
h265编码测试
(1). ffmpeg -s 1920x1080 -pix_fmt yuv420p -i BQTerrace_1920x1080_60.yuv -vcodec hevc_nvenc -r 60 -y 2_60.265
(2). ffmpeg -s 1920x1080 -pix_fmt yuv420p -i BQTerrace_1920x1080_60.yuv -vcodec hevc_nvenc -r 30 -y 2_30.265
h264编码测试
(3). ffmpeg -s 1920x1080 -pix_fmt yuv420p -i BQTerrace_1920x1080_60.yuv -vcodec h264_nvenc -r 60 -y 2_60.264
(4). ffmpeg -s 1920x1080 -pix_fmt yuv420p -i BQTerrace_1920x1080_60.yuv -vcodec h264_nvenc -r 30 -y 2_30.264
h264转h265
(5). ffmpeg -i 1_60.264 -vcodec hevc_nvenc -r 60 -y 2_60_264to265.265
(6). ffmpeg -i 1_30.264 -vcodec hevc_nvenc -r 30 -y 2_30_264to265.265
h265转h264
(7). ffmpeg -i 1_60.265 -vcodec h264_nvenc -r 60 -y 2_60_265to264.264
(8). ffmpeg -i 1_30.265 -vcodec h264_nvenc -r 30 -y 2_30_265to264.264
3.4 程序开发使用方法
av_find_encoder_by_name(“h264_nvenc”);
av_find_encoder_by_name(“hevc_nvenc”);
4. 辅助工具
watch -n 1 nvidia-smi
以1秒钟为间隔来查看GPU资源占用情况
5. 实测结果
5.1 硬件性能
本人用Geforce GTX1070与Tesla P4进行了测试,两者都是Pascal架构。
(1). GTX1070的硬件信息如下(deviceQuery显示):
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1070"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 8110 MBytes (8504279040 bytes)
(15) Multiprocessors, (128) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1683 MHz (1.68 GHz)
Memory Clock rate: 4004 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 5 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = GeForce GTX 1070
Result = PASS- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
(2). P4的硬件信息如下:
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla P4"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 7606 MBytes (7975862272 bytes)
(20) Multiprocessors, (128) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1114 MHz (1.11 GHz)
Memory Clock rate: 3003 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 5 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = Tesla P4
Result = PASS- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
5.2 实验结果
(1). GTX1070
| | hevc编码 | h264编码 | h264转h265 | h265转h264 |
| 60fps | 387fps(6.45x) | 430fps(7.17x) | 348fps(5.79x) | 170fps(2.84x) |
| 30fps | 345fps(11.5x) | 429fps(14.3x) | 318fps(10.6x) | 94fps(3.13x) |
(2). P4
| | hevc编码 | h264编码 | h264转h265 | h265转h264 |
| 60fps | 235fps(3.91x) | 334fps(5.57x) | 217fps(3.63x) | 171fps(2.85x) |
| 30fps | 212fps(7.07x) | 322fps(10.7x) | 198fps(6.59x) | 94fps(3.14x) |
5.3 实验分析
虽然在硬件性能上,P4比GTX1070显存略少,主频略低,CUDA的数量多出了33%,但从实验结果上看除了h265->h264结果持平外,P4表现都要逊色于GTX1070,这和官网所言“编解码器独立于CUDA核”相一致。
6. 源码分析
集成在ffmpeg框架内的视频编解码器需要定义一个AVCodec结构体包含(私有结构体AVClass、三个函数等)
6.1 h264部分
(1). 结构体(nvenc_h264.c)
AVCodec ff_h264_nvenc_encoder = {
.name = "h264_nvenc",
.long_name = NULL_IF_CONFIG_SMALL("NVIDIA NVENC H.264 encoder"),
.type = AVMEDIA_TYPE_VIDEO,
.id = AV_CODEC_ID_H264,
.init = ff_nvenc_encode_init, //初始化函数
.encode2 = ff_nvenc_encode_frame, //编码函数
.close = ff_nvenc_encode_close, //关闭函数
.priv_data_size = sizeof(NvencContext), //内部数据结构,见nvenc.h
.priv_class = &h264_nvenc_class, //私有结构体
.defaults = defaults,
.capabilities = AV_CODEC_CAP_DELAY,
.caps_internal = FF_CODEC_CAP_INIT_CLEANUP,
.pix_fmts = ff_nvenc_pix_fmts,
};
static const AVClass h264_nvenc_class = {
.class_name = "h264_nvenc",
.item_name = av_default_item_name,
.option = options, //编码器选项参数在这个AVOption结构体中
.version = LIBAVUTIL_VERSION_INT,
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意还有两个AVCodec,一个名字叫nvenc、一个叫nvenc_h264,对应三大函数与h264_nvenc是一样的
(2). 处理函数(nvenc.c)
av_cold int ff_nvenc_encode_init(AVCodecContext *avctx)
{
NvencContext *ctx = avctx->priv_data; //读入私有结构体
...
//下面是一些nvenc的api
nvenc_load_libraries
nvenc_setup_device
nvenc_setup_encoder
nvenc_setup_surfaces
nvenc_setup_extradata
...
}
int ff_nvenc_encode_frame(AVCodecContext *avctx, AVPacket *pkt,
const AVFrame *frame, int *got_packet)
{
...
if (frame) {
inSurf = get_free_frame(ctx); //来一帧
...
res = nvenc_upload_frame(avctx, frame, inSurf);//编一帧
...
}
}
av_cold int ff_nvenc_encode_close(AVCodecContext *avctx)
{
...
//一些free和destroy的工作
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
6.2 h265部分
(1). 结构体(nvenc_hevc.c)
AVCodec ff_hevc_nvenc_encoder = {
.name = "hevc_nvenc",
.long_name = NULL_IF_CONFIG_SMALL("NVIDIA NVENC hevc encoder"),
.type = AVMEDIA_TYPE_VIDEO,
.id = AV_CODEC_ID_HEVC,
.init = ff_nvenc_encode_init, //初始化函数
.encode2 = ff_nvenc_encode_frame, //编码函数
.close = ff_nvenc_encode_close, //关闭函数
.priv_data_size = sizeof(NvencContext), //内部数据结构,见nvenc.h
.priv_class = &hevc_nvenc_class, //私有结构体
.defaults = defaults,
.pix_fmts = ff_nvenc_pix_fmts,
.capabilities = AV_CODEC_CAP_DELAY,
.caps_internal = FF_CODEC_CAP_INIT_CLEANUP,
};
static const AVClass hevc_nvenc_class = {
.class_name = "hevc_nvenc",
.item_name = av_default_item_name,
.option = options,//编码器选项参数在这个AVOption结构体中
.version = LIBAVUTIL_VERSION_INT,
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意还有一个AVCodec,一个叫nvenc_hevc,对应三大函数与h264_nvenc是一样的
(2) 处理函数(nvenc.c)
同h264的处理函数