大白话5分钟带你走进人工智能-第31节集成学习之最通俗理解GBDT原理和过程
目录
1、前述
2、向量空间的梯度下降:
3、函数空间的梯度下降:
4、梯度下降的流程:
5、在向量空间的梯度下降和在函数空间的梯度下降有什么区别呢?
6、我们看下GBDT的流程图解:
7、我们看一个GBDT的例子:
8、我们看下GBDT不同版本的理解:
1、前述
从本课时开始,我们讲解一个新的集成学习算法,GBDT。
首先我们回顾下有监督学习。假定有N个训练样本,![]() , 找到一个函数 F(x),对应一种映射使得损失函数最小。即:
, 找到一个函数 F(x),对应一种映射使得损失函数最小。即:
![]()
如何保证最小呢?就是通过我们解函数最优化的算法去使得最小,常见的有梯度下降这种方式。
2、向量空间的梯度下降:
我们想想在梯度下降的时候,更新w是怎么更新的呢,先是随机找到一个w0,然后举根据梯度下降的迭代公式:
![]()
详细解释下这个公式,其中
![]()
意思是把损失函数先对w进行求导,得到一个导函数,或者说得到一组导函数,因为w是多元函数,得到了一组导函数之后,再把Wn-1这一组w带进去,得到一组值,这组值我们称作梯度,把梯度加个负号就是负梯度,乘一个λ是学习率。 这个公式整体的意思是 我只要把w加上一个L对于w的负梯度,把![]() 作为∆w,加到原来的w上,新产生出来的w就是比原来的w要好一些,能让损失函数更小一些,这就是对于w参数的一个提升。所以接下来我们的迭代步骤就是w1=w0+△w0,w2=w1+△w1=w0+△w0+△w1,这里是把w2用w1表示出来。w3=w2+△w2=w0+△w0+△w1+△w2,....所以最终的wn可以表达为wn=w0+△w1+△w2+...+△w(n-1)。一般情况下我们初始的时候w0=0。所以最后可以表达为
作为∆w,加到原来的w上,新产生出来的w就是比原来的w要好一些,能让损失函数更小一些,这就是对于w参数的一个提升。所以接下来我们的迭代步骤就是w1=w0+△w0,w2=w1+△w1=w0+△w0+△w1,这里是把w2用w1表示出来。w3=w2+△w2=w0+△w0+△w1+△w2,....所以最终的wn可以表达为wn=w0+△w1+△w2+...+△w(n-1)。一般情况下我们初始的时候w0=0。所以最后可以表达为
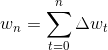
这就是向量空间的梯度下降的过程。所谓向量空间的梯度下降,为什么叫做向量空间的梯度下降,因为w是一组向量,我们是在w上给它往下降所以称为向量空间的梯度下降。
3、函数空间的梯度下降:
这里面的F*在假如逻辑回归里面就是1/1+e^-z。在其他算法里各自对应其损失函数。对于决策树来说,树其实也是有损失函数的,比如我们之前在后剪枝的时候,通常做法就是,拿测试集或者验证集去检验一下我cancel掉叶子节点会不会变好一点,但实际上还有另一种减枝方式,就是根据损失函数来的,别管损失函数是什么,它是一个L,L跟x有关的,跟叶子节点的数量T有关,表达为L (x,T)。T相当于一个正则项,叶子节点算的数量越多,它的损失函数就越大,它不想让树太复杂了,通过剪枝剪一次去去看损失函数,是上升了还是下降了,如果损失函数下降了,剪枝就承认它,以后就都不要节点了,所以说对于决策树本身是可以定义一个损失函数的,只不过定义出来它意义不大,只能在剪枝的时候看看用来效果怎么样,因为我们知道损失函数是用来评估结果的,评估你的模型到底怎么样的,那我们剪枝的时候拿它进行一个评估也是一个比较科学的方法,但是训练的过程中是用不到损失函数,因为你不知道怎么分裂可以影响到损失函数,所以训练的时候基本都没有提损失函数,而是用基尼系数,信息熵这种变通的方式。另一方面,树的损失函数也不能直接使用梯度下降来下降这个损失函数,按原来的做法我们有一堆w把空先给你留好了,然后你找到一组最好的w让损失函数最小就可以了,但树按照这个思路怎么来呢,应该是找到所有可能性的树,挑出一个能使损失函数最小的树,按理说应该这么做,但是这么做不现实,因为树有无穷多个,所以我们采用其它方式得到一个近似最好的可能性。所以对与单纯的决策树我们一般不适用损失函数。
但是一旦变成了集成学习,我们又可以把损失函数又让它重出江湖了。对于决策树我们不能使用梯度下降的方式,因为在决策树里面损失函数就像一个黑盒,没有具体的参数通过损失函数供我们优化。但是对于集成学习则可以使用,因为集成学习对应着很多树。首先决策树是根据选取的特定条件由根节点开始逐级分裂,直到满足纯度要求或达到预剪枝设置的停止而形成的一种树。那如何选取特定条件? 常见的有:GINI系数, Entropy,最小二乘MSE。而回归树就是每次分裂后计算分裂出的节点的平均值, 将平均值带入MSE损失函数进行评估。而GBDT是一种决策树的提升算法 ,通过全部样本迭代生成多棵回归树, 用来解决回归预测问题(迭代生成的每棵树都是回归树),通过调整目标函数也可以解决分类问题。传统的回归问题损失函数是:
![]()
yi是真实的样本的结果,y^是预测的结果。而在集成学习里面,y^就是我们每一次的预测的G(x),所以现在我们的损失函数变成yi和大G(x)的一个损失函数了,因此集成学习里面损失函数表达式为L=L(yi,G)。我虽然不能写出来具体的损失函数,但是肯定是关于yi和G的一个表达式,我想找到一个最好的大G(x),一步去找,找不到,怎么办,我就分步去找,最开始找到一个G0(x),它一般不是能让损失函数最小的,我知道有梯度下降这个工具,能让它更接近损失函数最低点一些。我们希望损失函数下降,希望每一次能找到一个新的G(x),就像向量空间梯度下降中更新w一样,我们希望找到一个新的w,w是损失函数改变的原因,现在变成了每一次的G(x)是损失函数改变的原因,每一次的G(x)的改变一定会改变损失函数,G(x)只要它能改变损失函数,损失函数不是上升就是下降。怎么着能让它损失函数降低呢?我们知道最终的G(x)是一堆g(x)相加,换一个角度来讲,第一步迭代我们得到了一个G1(x)=g1(x),第二步迭代我们得到了G2(x)=G1(x)+g2(x),第三步就是G3(x)=G2(x)+g3(x),注意这个形式,集成树的每一步迭代形式和梯度下降每一步的迭代形式似乎很像,我们注意观察,在梯度下降里,每一步迭代所要加的△w只要是前一项的值带到损失函数里面的负梯度![]() ,就可以让损失函数变得更小。而我现在所谓的集成学习一轮一轮的迭代,第一轮我想加上一个g1(x),第二轮我想再加上g2(x),第三轮我想再加上g3(x),根据梯度下降的原则,加上的每一个g(x)等于什么的时候能够让集成学习的损失函数越来越小呢?能不能也让它等于损失函数对于上一次的预测整体的结果G(x)这个东西的负梯度?这样损失函数一定会也是下降的。我把G(x)当做一个整体来看待,类似于原先的w变量。反正都是让损失函数改变的原因。这种梯度下降的过程就称为函数空间的梯度下降过程。函数空间的梯度下降是什么意思呢?因为在函数空间中这个函数它写不出来是由什么w组成的,它的最小单位就是这个弱分类器本身,所以我们只能在函数空间进行梯度下降。
,就可以让损失函数变得更小。而我现在所谓的集成学习一轮一轮的迭代,第一轮我想加上一个g1(x),第二轮我想再加上g2(x),第三轮我想再加上g3(x),根据梯度下降的原则,加上的每一个g(x)等于什么的时候能够让集成学习的损失函数越来越小呢?能不能也让它等于损失函数对于上一次的预测整体的结果G(x)这个东西的负梯度?这样损失函数一定会也是下降的。我把G(x)当做一个整体来看待,类似于原先的w变量。反正都是让损失函数改变的原因。这种梯度下降的过程就称为函数空间的梯度下降过程。函数空间的梯度下降是什么意思呢?因为在函数空间中这个函数它写不出来是由什么w组成的,它的最小单位就是这个弱分类器本身,所以我们只能在函数空间进行梯度下降。
最开始不管用什么方法,已经得到了第一代G0(x),这时能算出来损失函数,它是能让损失函数结果最小的那个G(x)吗?应该不是。我们希望把它修改修改,让它变好一些,能让损失函数降低。我令G1(x)=G0(x)加上损失函数对于G0的负梯度,即
![]()
即G1(x)=G0(x)+∆G0,此时的G1(x)就能比G(x)让损失函数变得更低一些了。然后依次G2(x)去迭代。G2(x)=G1(X)+∆G1,∆Gt应该等于损失函数L对于Gt的梯度,即
![]()
只要每次加上的都是∆Gt这么个东西,每一步带入各自的∆Gt,第一次带入∆G0,第二次带入∆G1,以此类推,就能保证最后得到的G一次比一次的能够让损失函数变小。一直到GT(X)=GT-1(X)+∆GT-1。此时GT(X)就是我们最终要得到的GT(X)。表达如下:
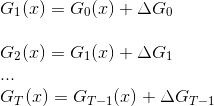
这里面每一步的所加的∆G不就是集成学习里边每一步加的弱分类器g(x)吗,第一次你希望加上一个g1(x),第二次加上一个g2(x),一直加到gt(x),最终的大Gt(x)等于什么呢,假设G0(x)=g0(x)=0,Gt(x)=g0(x)+g1(x)+g2(x)……一直加到gt-1(x),这不就是一个另一个视角看的集成学习嘛。对于最小二乘损失函数来说,损失函数是:
![]()
对y^求偏导就是2(y-y^),通常在前面还有个学习率,假如学习率是1/2的话那么会和2相乘抵消,所以最后的求导结果是y-y^,对于我们的集成学习来说y^就是上一步的整体的预测结果Gt-1(x)。所以集成学习的损失函数对G(x)的求导结果就是:
![]()
所以在t轮我们应该训练出的gt(x)的预测结果应该等于![]() 。对于决策树算法来说的话,即为以
。对于决策树算法来说的话,即为以![]() 为新的标签,x为feature,拟合一颗新的决策树。通过这种方式,来训练的G(x),就叫做GBDT。
为新的标签,x为feature,拟合一颗新的决策树。通过这种方式,来训练的G(x),就叫做GBDT。
4、梯度下降的流程:
说了这么多,到底什么是梯度下降?所谓梯度下降,也就是对于任何一个函数来说,只要这个函数是个凸函数,它的自变量是x,也就是说这个函数受x改变而改变,你只要瞎蒙出来一代x,你接下来不停的去迭代,每次迭代的准则就是加上一个函数对上一代自变量的求导,即负梯度,表达为xn=xo-∂F/∂x ,这么不停的迭代,最终得到的x就能够找到F(x)的最小值,这个东西就叫做梯度下降。
梯度下降和L-BFGS一样,它就是一个算法,一个函数关于一个变量的算法。每次我就让这个函数加上关于自变量的负梯度,就能让函数越来越小。所以我不限制这个变量到底是w还是G,只要你这个东西能真真切切地影响我的大小,我去求你的负梯度,就能让你越降越低。这就是随机梯度下降算法的过程。它是不挑食的。
你优化的内容就是你去调整的内容,在函数性模型里,真真正正影响损失函数大小的是w,所以我去调整w,让w始终朝着负梯度的方向去改变,最终就能让损失函数降到最低。而在带着树的集成学习里面,最小的能够调整的单位没有w了,你只能调整你加进来那棵小树,所以你就去优化这棵小树,让你新加进来的小树的预测结果尽量等于函数空间上的负梯度方向。
其实它比向量空间的梯度下降的运算量至少是要少的,为什么呢?因为在向量空间中,w是一个向量,它要求一系列偏导,而在函数空间的梯度下降中,此时的变量就是一个数,所以就是一个求导数的概念了,也就是一维空间的梯度下降,每次加上一个数。
5、在向量空间的梯度下降和在函数空间的梯度下降有什么区别呢?
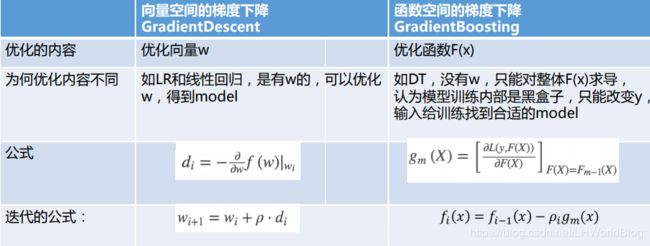
详细解释下:
首先向量空间的梯度下降,翻译是GradientDescent,函数空间的梯度下降,翻译是GradientBoosting,说明是用在Boosting里面的。其次向量空间的梯度下降优化内容是w,而函数空间优化函数F(x) ,为什么优化内容不同,向量空间如LR和线性回归,是有w的,可以优化w,得到model。而函数空间中,如DT,没有w,只能对整体F(x)求导, 认为模型训练内部是黑盒子 只能改变预测值 y^, 输入给训练找到合适的model。向量空间中是对w求导,即
![]()
而函数空间是直接对整体F(x)求导,即
![]()
这里面直接对F(x)求导,并且把上一代的F(x)值给带进去。迭代公式也发生了变化。
向量空间中是![]() ,函数空间中是
,函数空间中是![]() 。
。
6、我们看下GBDT的流程图解:

解释下上面流程:
首先训练集x0和y0,我在原始的训练集上训练一个比较弱的决策树,长成了一棵树。这是第一个模型1。通过预测的结果把训练集上的标签转化为X1,Y1。原来Adaboost是改变数据的权重,现在GBDT是改变Y的标签,然后再训练第二个模型,再改变标签。反复迭代下去,将所有的预测结果综合作为最后的预测结果,这就是GBDT的流程。
7、我们看一个GBDT的例子:
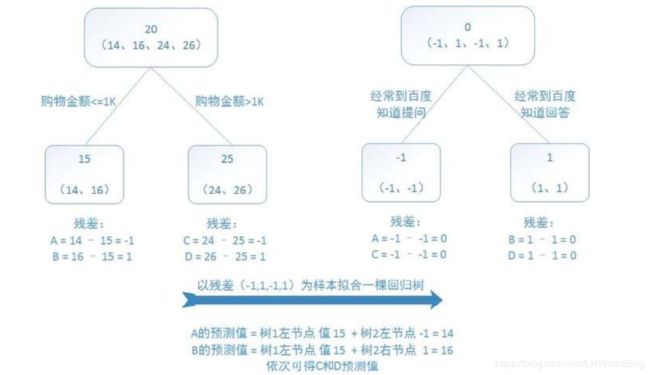
假如用购物金额和是否经常去百度知道提问这两个条件作为x去判断这个人的年龄,训练的时候我有四条数据,分别是14岁,16岁,24岁和26岁。
我上来想训练出一棵回归树来,在根节点的时候平均值是20。接下来回归树怎么训练?拿什么评估参数?拿mse,抱得最紧的放到一起。此时给它一分为二,我发现购物金额小于等于1000和大于1000,能够把14,16分到左边,24和26分到右边。这个树我人为的限制它只允许你有两层。现在左边这个节点输出的结果通通是15,假如4条样本数据分别对应编号是A,B,C,D的话,此时y^A,y^B等于15,y^C,y^D 等于25。
此时y^与真实的y之间有没有残差?有残差,我们知道负梯度就是残差。接下来我想训练第二棵树,第二棵树希望输出结果是负梯度,也就是我希望输出结果是残差。那么我就想要把残差当做label放回到原来去,那么对于这四条数据,它们的y原来是14,16,24,26,咱现在就变成-1,+1,-1,+1 。怎么来的?本来是14,预测成了15,y- y^等于-1;那么原来是24变成25了,它也是-1。
接下来我再根据经常到百度提问作为条件进行一次分类,回归树是不管你的label的,我就想把最接近的给凑到一起去,所以接下来就把两个-1凑到一起了,把两个+1凑到一起了。那么第二代的y^A就等于-1,y^B等于1。因为这两个1分到一起,它们平均值也是1就预测准了。 y^C等于-1,y^D 等于+1。
现在两棵树训练完了,最终我们来一条数据,比如说来一条数据14,它要怎么来做预测?把它丢到第一个树里面,得到一个15;再丢到第二棵树里面,得到一个-1,最终的G=15-1=14,得到一个正确的预测结果。
8、我们看下GBDT不同版本的理解:
GBDT直观的来看,就是说比如这个人90岁,第一个数给它预测成了78岁,还剩12岁,第二棵树就把12岁作为标准预测,结果它只预测到了十岁,还差两岁。第三个树又根据两岁作为标准,此时再次预测为1.5,第四个树根据0.5作为标准预测结果为0.5,最后四棵数加到一起正好是90,每次拟合的都是残差,这是简单版的理解GBDT的过程。
核心版的理解是为什么每次要预测残差,因为对于回归问题来讲,刚好负梯度等于残差,所以去预测的是残差。因为你的mse带着平方求导就是残差。通常F(x)在相加的时候,会给这残差也乘一个缩水的学习率,比如0.1。第二次虽然预测出12,我只给你加上1.2,防止你走过了,下次从78就变成79.2了,还差一大截的,你第三个再照样去努力预测,再给乘一个缩水系数,跟咱们的梯度下降的学习率是一模一样的。
这个实际上是原始的GBDT应对回归问题的时候,可以使用简单的把y level做一个替换,去重新训练的这么一种方式。但是对于分类问题,它就不好使了,所以xgboost提供了一个最终版的解决方案。