哈夫曼压缩(一)——英文文本
本文主要介绍如何实现哈夫曼压缩以及提高哈夫曼压缩过程的读写速率,对于哈夫曼树的概念及其构造则没有介绍,感兴趣的朋友可以先百度一下了解相关知识。
一、哈夫曼压缩原理
哈夫曼压缩是一种无损的压缩算法,在压缩过程中不会损失信息熵,因此常用哈夫曼算法去压缩一些重要的文件资料。
哈夫曼压缩是通过采用特定长度的位序列去替代原来的个体符号(如字节)。对于一些高频率出现的字节,使用短字节表示,而对于一些低频率出现的字节,则采用较长的位序列来代替,这从而降低整个文本的位序列长度,达到压缩目的。
二、哈夫曼压缩与解压缩过程
要实现哈夫曼压缩,我们需要做如下工作:
1、读取文本;
2、统计文本中各字节出现的次数;
3、根据第二步统计出来结果构造哈夫曼树;
4、生成哈夫曼编码;
5、将文件转换为哈夫曼编码格式的字节文件;
6、写入哈夫曼编码。
哈夫曼解压缩是压缩的逆过程,其主要步骤如下:
1、读取压缩文件;
2、还原哈夫曼编码;
3、根据哈夫曼编码还原文件。
三、哈夫曼压缩
压缩思路:
1、int [ ] byteCount和String [ ] charCode
创建两个数组分别保存各字节出现的次数和哈夫曼编码,由于本文压缩的是英文文本,只需要用基础ASCII码(0-127),所以数组长度均设为128位,利用数组索引来存储对应的字节,索引位置的值存储相应信息;
2、采用优先队列来构建哈夫曼树,通过调用poll( )方法可快速构建哈夫曼树,需要注意的是,这里需要加入一个比较器,重写compare()方法,采用按字节出现次数排序(从小到大);
3、读写数据时采用字节缓冲流加字节数组的方法提高读写效率,减少对磁盘文件的操作;
4、本文将编码文件与文件编码合并后一起生成字节文件后,再一次性写入压缩文件;
5、生成字节文件时,最后一个字节不足8位时,加0补齐8位生成字节写入;
6、压缩文件格式:
本文压缩文件分为三段,分别为:
a.各字节编码长度( 0-127);
b.末位补0数(128);
c.字节编码文件(含编码字节);
7、整型数据转换为字节方法:new Integer( int value).byteValue。
package com.liao.Huffman0830v1;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Comparator;
import java.util.PriorityQueue;
public class HufTree {
private static final int LEN = 128;
private int[] byteCount = new int[LEN];// 统计各字节出现次数
private String[] charCode = new String[LEN];// 记录各字节哈夫曼编码
private PriorityQueue nodeQueue = new PriorityQueue<>(LEN, new Comparator() {
@Override
public int compare(hufNode o1, hufNode o2) {
return o1.count - o2.count;// 按次数排序
}
});
// 成员内部类
private static class hufNode {
private hufNode lchild;// 左分支
private hufNode rchild;// 右分支
private String str;// 记录字符
private int count;// 统计次数
// 构造方法
public hufNode(String str, int count) {
super();
this.str = str;
this.count = count;
}
}
// 主函数
public static void main(String[] args) {
File file = new File("file\\01.txt");
File file2 = new File("file\\压缩文件.txt");
new HufTree().compress(file, file2);// 压缩文件
System.out.println("原文件大小:" + file.length() + "b");
System.out.println("压缩文件大小:" + file2.length() + "b");
}
// 压缩文件
private void compress(File file, File file2) {
byte[] bs = readFile(file);// 读取文件
countChar(bs);// 统计词频
hufNode root = createTree();// 创建哈夫曼树
generateCode(root, "");// 生成哈夫曼编码
printCode();// 打印哈夫曼编码
writeFile(bs, file2);// 写入压缩文件
}
// 将文件转换为字节数组保存
private byte[] readFile(File file) {
byte[] bs = new byte[(int) file.length()];// 创建字节数组
BufferedInputStream bis = null;// 声明字节缓冲流
try {
bis = new BufferedInputStream(new FileInputStream(file));
bis.read(bs);// 将文件读取到字节数组中
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null)
bis.close();// 关闭输入流
} catch (IOException e) {
e.printStackTrace();
}
}
return bs;
}
// 统计词频
private void countChar(byte[] bs) {
for (int i = 0, length = bs.length; i < length; i++) {
byteCount[bs[i]]++;
}
}
// 创建哈夫曼树
private hufNode createTree() {
for (int i = 0; i < LEN; i++) {
if (byteCount[i] != 0) {// 使用优先队列保存
nodeQueue.add(new hufNode((char) i + "", byteCount[i]));
}
}
// 构建哈夫曼树
while (nodeQueue.size() > 1) {
hufNode min1 = nodeQueue.poll();// 获取并移除队列头元素
hufNode min2 = nodeQueue.poll();
hufNode result = new hufNode(min1.str + min2.str, min1.count + min2.count);
result.lchild = min1;
result.rchild = min2;
nodeQueue.add(result);// 加入左节点
}
return nodeQueue.peek();// 返回根节点
}
// 生成哈夫曼编码
private void generateCode(hufNode root, String s) {
// 叶子节点
if (root.lchild == null && root.rchild == null) {
// 保存至编码数组对应位置
charCode[(int) root.str.charAt(0)] = s;
}
if (root.lchild != null) {// 左边加0
generateCode(root.lchild, s + "0");
}
if (root.rchild != null) {// 右边加1
generateCode(root.rchild, s + "1");
}
}
// 写入压缩文件 :1、各字节编码长度 2、各字节编码 3、编码后的文件
private void writeFile(byte[] bs, File file2) {
BufferedOutputStream bos = null;// 声明字符缓冲流
try {
// 创建字符缓冲流
bos = new BufferedOutputStream(new FileOutputStream(file2));
// 写入各字节编码长度
String binaryCode = writeCodeLength(file2, bos);
// 字节数组文件转码成二进制文件
String binaryFile = transFile(bs);
// 合并二进制编码及文件
String codeAndFile = binaryCode + binaryFile;
// 生成字节并写入合并后二进制文件
generateFile(bos, codeAndFile);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bos != null)
bos.close();// 关闭输入流
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 写入各字节编码长度
private String writeCodeLength(File file2, BufferedOutputStream bos) throws IOException {
StringBuilder sb = new StringBuilder();// 创建字符缓冲流
for (int i = 0; i < LEN; i++) {
if (charCode[i] == null) {
bos.write(0);
} else {
sb.append(charCode[i]);// 存储哈夫曼编码
bos.write(charCode[i].length());
}
}
return sb.toString();// 返回各字节哈夫曼编码
}
// 文件转码
private String transFile(byte[] bs) {
StringBuilder sb = new StringBuilder();
for (int i = 0, length = bs.length; i < length; i++) {
sb.append(charCode[bs[i]]);
}
return sb.toString();
}
// 生成字节文件
private void generateFile(BufferedOutputStream bos, String codeAndFile) throws IOException {
int lastZero = 8 - codeAndFile.length() % 8;// 补0数
int len = codeAndFile.length() / 8 + 1;// 取商+1
if (lastZero != 8) {// 余数不为0,则补加1位
len = len + 1;
for (int i = 0; i < lastZero; i++) {
codeAndFile += "0";// 加0补齐8位
}
}
// 创建字符数组,保存字节
byte[] bv = new byte[len];
bv[0] = new Integer(lastZero).byteValue();
for (int i = 1; i < len; i++) {
// 先将8位01字符串二进制数据转换为十进制整型数据,再转为一个byte
byte bytes = new Integer(changeString(codeAndFile.substring(0, 8))).byteValue();
bv[i] = bytes;// 加入到数组中
codeAndFile = codeAndFile.substring(8);// 去除前8个字节
}
// 写入文件
bos.write(bv);
}
// 8位01字符串转换为十进制整型数据
private int changeString(String str) {
return (int) (str.charAt(0) - 48) * 128 + (str.charAt(1) - 48) * 64 + (str.charAt(2) - 48) * 32
+ (str.charAt(3) - 48) * 16 + (str.charAt(4) - 48) * 8 + (str.charAt(5) - 48) * 4
+ (str.charAt(6) - 48) * 2 + (str.charAt(7) - 48);
}
// 打印编码
private void printCode() {
for (int i = 0; i < LEN; i++) {
if (charCode[i] != null) {
System.out.println("(" + i + "," + (char) i + "," + byteCount[i] + "," + charCode[i] + ","
+ charCode[i].length() + ")");
}
}
}
} 四、哈夫曼解压缩
解压缩思路:
1、利用String类的substring()方法和Arrays类的copyOfRange方法对字符串进行复制及截取;
2、利用BigInteger类的 new BigInteger(1, byte [ ]).toString(2)方法将字节数组转换为二进制字符串形式;
package com.liao.Huffman0830v1;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.Arrays;
public class Decompress {
private final static int LEN = 128;// 编码字节个数
private String[] charCode = new String[LEN];
// 主函数
public static void main(String[] args) {
File file = new File("file\\压缩文件.txt");
File file3 = new File("file\\解压文件.txt");
new Decompress().decompress(file, file3);
System.out.println("解压前文件大小:" + file.length() + "b");
System.out.println("解压后文件大小:" + file3.length() + "b");
}
// 解压文件
private void decompress(File file, File file3) {
// 读取文件
byte[] bs = readFile(file);
// 获取各字节编码长度并返回哈夫曼编码总长度
int codeLengths = getCodeLength(bs);
// 截取记录哈夫曼编码长度部分
byte[] CodeLength = Arrays.copyOfRange(bs, 0, LEN);
// 末位补0数
int lastZero = bs[LEN];
// 截取二进制数据部分
bs = Arrays.copyOfRange(bs, LEN+1, bs.length);
// 将字节数组转换为二进制字符串
String codeAndFile =processData(bs);
// 截取编码表部分
String binaryCode = codeAndFile.substring(0, codeLengths);
// 截取文件部分(增补0)
String binaryFile = codeAndFile.substring(codeLengths, codeAndFile.length() - lastZero);
// 还原编码表
restoreCode(binaryCode, CodeLength);
// 将二进制文件转换为字节数组
byte[] byteArray = restoreFile(binaryFile);
// 写入文件
writeFile(file3, byteArray);
}
// 将文件转换为字节数组保存
private byte[] readFile(File file) {
byte[] bs = new byte[(int) file.length()];// 创建字节数组
BufferedInputStream bis = null;// 声明字节缓冲流
try {
bis = new BufferedInputStream(new FileInputStream(file));
bis.read(bs);// 将文件读取到字节数组中
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null)
bis.close();// 关闭输入流
} catch (IOException e) {
e.printStackTrace();
}
}
return bs;
}
//数据处理(转为二进制)
private String processData(byte [] bs) {
//将数据转换为二进制
String codeAndFile =new BigInteger(1, bs).toString(2);
//判断首位是否需要补0
if(bs[0]>0) {
//转为二进制,根据位数得到补0数
int firstZero=8-Integer.toBinaryString(bs[0]).length();
for(int i=0;i byteList = new ArrayList<>();// 创建字节队列保存读取字节
for (int i = 0; i < binaryFile.length(); i++) {
String charcode = binaryFile.substring(0, i + 1);
for (int j = 0; j < LEN; j++) {
if (charcode.equals(charCode[j])) {
byteList.add(new Integer(j).byteValue());
// 更新参数
binaryFile = binaryFile.substring(i + 1);
i = 0;
break;
}
}
}
// 将字节队列数据转移至数组中
byte[] byteArray = new byte[byteList.size()];
for (int i = 0, len = byteList.size(); i < len; i++) {
byteArray[i] = byteList.get(i);
}
return byteArray;
}
// 写入文件
private void writeFile(File file3, byte[] byteArray) {
BufferedOutputStream bos = null;
try {
bos = new BufferedOutputStream(new FileOutputStream(file3));
bos.write(byteArray);
bos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
五、测试类
通过压缩文件与解压缩文件内容对比测试压缩是否成功:
package com.liao.Huffman0830v1;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
File file1 = new File("file\\001.txt");
File file2 = new File("file\\解压文件.txt");
File file3 = new File("file\\压缩文件.txt");
BufferedInputStream bis1 = new BufferedInputStream(new FileInputStream(file1));
BufferedInputStream bis2 = new BufferedInputStream(new FileInputStream(file2));
byte[] bs1 = new byte[(int) file1.length()];
byte[] bs2 = new byte[(int) file2.length()];
bis1.read(bs1);
bis2.read(bs2);
bis1.close();
bis2.close();
System.out.println(Arrays.equals(bs1, bs2) );
System.out.println("原文件大小:" + file1.length() / 1000 + "kb" + "----" + "压缩文件大小:"
+ file3.length() / 1000 + "kb");
}
}
测试结果:
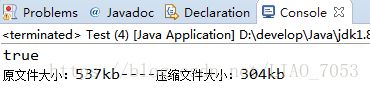
根据测试结果,可以看出文件压缩成功,压缩率约为57% 。
六、注意事项
1、本文只适用于英文文本压缩,对于中文文本压缩,下篇会介绍;
2、本文基本上都是用一个字符串或字节数组保存整篇文档,然后再进行读写操作(获得更高效的读写速率),对于较大的文件(超过100Mb)可考虑将文件分成若干段再进行相关操作;
3、为进一步提高压缩与解压缩效率,可考虑使用多线程,但须注意数据同步的问题。