【JavaWeb·1】MySQL数据库使用方法
MySQL
数据库引言
需求:存储一条数据,牛牛–38–99.0
1、Java程序中:借助 JVM 内存变量,对数据进行存储
(1)将数据存储在对应变量中:局部变量、成员变量(对象)、数组、集合
- 栈空间:局部变量
- 堆空间:对象
(2)缺点:利用JVM存储数据,JVM一旦关闭,则空间被回收,空间里的数据也会丢。这种存储数据的方式,没有达到持久化。
2、利用 IO 流技术,将数据存储在文件中
(1) 利用 IO 的输出流,将 JVM 中临时数据写入到文件中,同时还可以利用IO的输入流,将文件中的数据读取到 JVM 内存。
(2) 优点:数据可以持久化
(3) 缺点:
- 数据不安全
- 文件中数据类型单一,统一数据类型处理为String
- 文件存储的数据量小
- 不支持多线程操作(不支持多用户操作)
数据库
1、数据库:Database,简称DB,是存储和管理数据的一种软件,提供对数据的增删改查等操作。
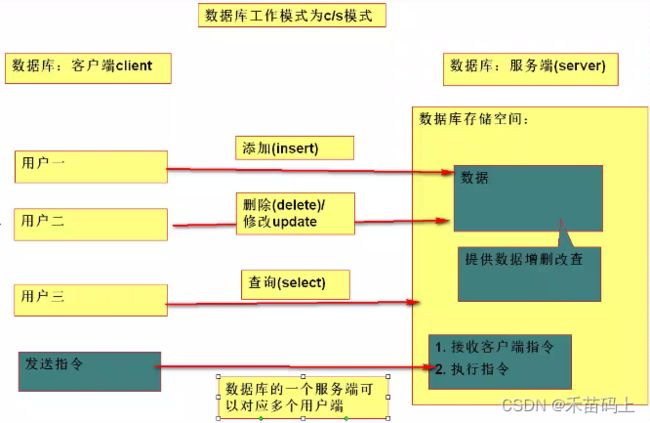
2、数据库的工作模式:数据库服务端(server)-客户端(Client),简称为c/s模式。
(1) 数据库的客户端:发送指令
(2) 数据库的服务端:接受指令、执行指令
注意:一个服务端可以对应多个客户端
3、数据库的分类
(1) 关系型数据库
- 关系型数据库是由多张能互相连接的二维表组成的数据库。
oracle:oracle公司的数据库产品(甲骨文)
MySQL:MySQL公司,被sun公司收购,后被 oracle 收购
db2:IBM
sqlServer:微软
(2) 非关系型数据库
mogondb redis等
4、数据库常见概念
(1) 表:table,用于存储数据
employees:员工表,存储员工信息
departments:部门表,存储员工部门信息
(2) 行:row,代表一条数据,例如一行为一个学生的信息,一行为一个员工的信息
(3) 列/字段:colum,代表当前列数据的含义
MySQL数据库
1、安装MySQL服务器【接受指令、执行指令】
安装MySQL服务器:
- 安装路径不要带中文
- 安装数据库密码记住,后期用到
检测MySQL服务器:
任务管理器–>服务–>关注MySQL服务,只有服务器开着才能接收指令
2、MySQL常用客户端
(1) MySQL自带客户端:MySQL服务器安装后自带数据库客户端
(2) 第三方客户端:Navicat,简称大黄。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fnP29EsE-1655475751122)(C:\Users\72442\AppData\Roaming\Typora\typora-user-images\image-20220614203648769.png)]
SQL
SQL通用语法
SQL:(structure Query Language)结构化查询语言
作用:操作(增删改查)数据库中某个用户下的表中数据,客户端往服务端发送的指令。
- SQL语句可以单行或多行书写,以分号结尾。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
- 注释
- 单行注释: – 注释内容 或 #注释内容(MySQL特有)
- 多行注释:/* 注释 */
- DDL:操作数据库,表等。
- DML:对表中的数据进行增删改
- DQL:对表中的数据进行查询
- DCL:对数据库进行权限控制
DDL: 操作数据库 表
DDL——操作数据库
查询
SHOW DATABASES;
创建
创建数据库
CREATE DATABASE 数据库名称;
创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称;
删除
删除数据库
DROP DATABASE 数据库名称;
删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称;
使用数据库
USE 数据库名称;
DDL——操作表
查询表
查询当前数据库下所有表名称
SHOW TABLES;
查询表结构
DESC 表名称; //查询表的结构信息
创建表
CREATE TABLE 表名(
字段名1 数据类型1,
字段名2 数据类型2,
);
删除表
删除表
DROP TABLE 表名;
删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;
修改表
修改表名
ALTER TABLE 表名 RENAME 新的表名;
添加一行
ALTER TABLE 表名 ADD 列名 数据类型;
修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型
修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
删除列
ALTER TABLE 表名 DROP 列名;
创建表【精】
1、建表语法
create table 表名(
字段名 数据类型[约束][默认值]
字段名 数据类型[约束][默认值]
字段名 数据类型
)
注意:最后一个字段后面不加逗号
2、常用数据类型
(1) 数值类型:
int:整数,4B,存储的数据范围:-2147483648——2147483647
double:小数,双精度,8B
(2) 字符串类型
char(n):固定长度字符串,空间分配效率高,空间利用率低
char(5):字符串的长度固定为5 不足5时会用null进行填充
‘abc'实际长度为5
varchar(n):不固定长的字符串
varchar(5):最大长度为5
’abc‘实际长度为3
存储:手机号(固定长度11位,建议使用char(11))
账户用户名(长度不固定。varchar(50))
身份证号(固定长度为18位,char(18))
(3)日期类型
date:年月日,默认的格式:yyyy-MM-dd
datetime:年月日时分秒 yyyy-MM-dd HH:mm:ss
TIMETAMP:年月日时分秒,时间戳
(4) 布尔类型:mysql中不支持
利用int中的 1代表true 0代表false
利用char(1)中'y'代表true,'n' 代表false
利用char(3)中的'是'代表true,'否'代表false
注意;在utf-8中汉字占2-3个字节
3、默认值
(1) 作用:表示该字段不给数据时,系统会根据指定的内容默认赋值。
(2) 语法:
字段名 数据类型 default 值
(3) 注意:指定默认值时,必须和当前字段数据类型一致
约束【重】
(1) 主键约束:primary key,pk
作用:用于标识表中每行数据唯一、非空。(学号、工号等)
特点:唯一、非空
语法:字段名 数据类型 primary key
注意:实际开发时,通常每一张表都会设置一个主键列。
(2) 唯一约束:unique,un
作用:用于表示该字段中的内容不允许重复。例如:身份证号、手机号
特点:唯一、可以为空
语法:字段名 数据类型 unique
(3) 非空约束:not null,nn
作用:用于标识该字段中的内容不能为空,必须有内容
例如:学生名、用户名
特点:不能为空,可以重复
语法:字段名 数据类型 not null
(4) 外键约束:简称fk
作用:用于标识当前字符的值不能随意输入,需要跟从于另一张表的主键列或是唯一列。
注意:设置外键列的表称为从表,被从表指定的表称为主表,从表中外键列数据跟从主表中的指定列的数据
特点:可以重复,可以为空。
语法:references 主表表名(主表中主键名/唯一列名)
-- 班级表信息:班级编号-主键、班级名称
CREATE TABLE t_class(
clz_id INT(11) NOT NULL PRIMARY KEY,
clz_name varchar(50) NOT NULL
);
-- 学合表信息:学生学号-主键、姓名、性别(int:0-男,1-女)、邮箱、出生日期、身份证号-唯一、所在班级编号
create table t_student(
stu_id INT(11) NOT NULL PRIMARY KEY,
stu_name varchar(50) not null,
sex int(11)DEFAULT 1,
email VARCHAR(60) DEFAULT null,
cardNum char(18) Default null,
clz_id int(11) default null,
foreign key(clz_id) references t_class(clz_id)
);
DML: 数据 增删改
DML——添加
给指定的列添加数据
INSERT INTO 表名 (列名1, 列名2) VALUES(值1, 值2);
-- 这种添加数据的语法,可以对表内部分字段内容添加,但是选择字段必须包含表中主键和非空字段
-- 后面给定值的顺序、数据、个数和前面一致
-- 给定值时,需要遵循对应字段约束(唯一、非空、主键、外键)
给全部列添加数据
INSERT INTO 表名 VALUES(值1, 值2);
-- 此种语法必须为表中所有的字段一一添加数据
-- values()中值的顺序、个数、数据类型,取决于表结构中的顺序个数类型。
-- 给指定列添加数据
INSERT INTO stu (id, NAME) VALUES(1, '张三');
-- 给所有列添加数据
-- 给所有列添加数据,列名的列表可以省略
INSERT INTO stu (
id,
NAME,
gender,
birthday,
score,
email,
tel,
STATUS
)
VALUES
(
2,
'李四',
'男',
'1999-11-11',
88.88,
'[email protected]',
'153384905980',
1
);
实际开发时,不用开发人员手动维护主键的唯一性,一般用navicat的自动递增维护
【实际项目中,采用UUID等算法进行维护主键唯一】
DML——修改
修改表数据
UPDATE 表名 SET 字段名 = 值1 WHERE 过滤条件;
-- 修改数据
-- 将张三的性别改为女
UPDATE stu SET gender = '女' WHERE NAME = '张三';
-- 注意,如果update语句没有where条件,会将表中数据全部修改!
注意:
1、修改新的值需要对应字段数据类型
2、修改时需要遵循字段约束
DML——删除
delete 删除数据
DELETE FROM 表名 WHERE 条件; -- 删除符合过滤条件的所有数据
-
删除数据时,根据开发需求设定过滤条件,若没有加过滤条件,删除所有数据
-
删除语句中如果不加过滤条件,则将所有数据都删除,一条一条删除,效率低
-
给定一个id删除,最多删除一条数据
-
利用其它字段进行过滤(不唯一)可能会同时删除多条数据
-
当删除的某行数据为其他表中外键列引入的数据时,删除失败。
delete from t_clazz where clz_id = 3
- 第一种:删除被占用的子项中所有的数据
- 第二种:将占用的子表数据修改到其他数据中,更新一下。
-- 删除张三记录
DELETE FROM stu WHERE NAME = '张三';
truncate table删除
truncate table 表名;
【本质】直接将存储数据的空间清除掉进而删除数据,删除数据的效率比delete高
DQL: 数据 查询
select ... from 表名
a. select 确定查询到字段(列)
b. from 确定数据的来源(哪个表)
1、查询表中部分字段内容
(1) 语法:select 字段名1,字段名2,字段名3 from 表名
-- 查询所有员工工号、姓名、工资
select employee_id,first_name,salary from employees;
(2) 注意:每个字段之间以逗号隔开,最后一个查询字段无需逗号隔开
2、查询表中所有字段内容
(1) 第一个解决方案:将表中所有字段一一罗列进行查询
(2) 第二个解决方案:利用 * 查询
-- 查询表中所有字段信息
select * from employees;
a. *代表表中所有字段
b. 使用*的优缺点:
方便查询所有的字段内容
使用*查询效率相对较低,实际开发时,*可读性不高。
3、对表中查询字段/列起别名:as
(1) 语法:select 字段名,字段名2 as 别名 字段名3 别名 from 表名
(2) 注意:起别名时,as可以省略
-- 查询员工信息:工号、名、工资
select employee_id,first_name as 名,salary from employees
4、字符串的拼接:concat
(1) 语法:select 字段名,concat(字段名1,字段名2,“字符串”) 别名,字段名 from 表名
(2) 注意:MySQL中的concat可以将多个字符串进行拼接,而且字符串常量既可以使用 " " 也可以使用 ’ ’ 。
-- 查询员工信息:工号、姓名(姓+名)、工资
select employee_id,concat(first_name,"...",last_name) 姓名,salary from employees
5、对查询结果内容进行运算
(1) 常见运算:+ - * /
(2) 注意:
- 在计算除法时,分母如果为0,则结果为null
- 数值类型才可以。
-- 查询员工工号、工资、年薪
select employee_id,first_name,salary*12 年薪 from employees
6、条件查询(过滤查询)where
(1) 语法:select 字段名1,字段名2 from 表名 where 过滤条件
(2) 作用:对查询的每条数据进行条件判断,对符合条件的数据保存到查询结果中
(3) 等值判断
-- 查询工资为17000的员工信息
select * from employees where salary=17000
注意:MySQL中的判断是用=
(4) 不等值判断:!= > < >= <=
select * from employees where salary>10000
(5) 多条件查询 and(并且) or(或者)
select * from employees where salary>10000 AND salary<20000
注意:and等价于Java中的 &&,or 等价于||
(6) 区间查询:between 起始值 and 终止值【包含边界值】
select * from employees where salary between 10000 and 20000
(7) 枚举查询 in
– 查询60、70、80部门的员工信息
第一种方案【冗余】
select * from employees where department_id=60 or department_id=70 or department_id=80
第二种方案:枚举查询,降低代码冗余
select * from employees where department_id in(60,70,80)
(8) 对null值处理 is null / is not null
-- 查询员工表中没有提成的员工信息
select * from employees where commission_pct is NULL
-- 查询员工表中有提成的员工信息
select * from employees where commission_pct is not NULL
【重点】
-- 查询佣金(commission_pct)为 0 或为 NULL 的员工信息
select * from employees where (commission_pct=0) or (commission_pct is null);
-- 查询入职日期在 1997-5-1 到 1997-12-31 之间的所有员工信息
select * from employees where hiredate between '1997-5-1'and'1998-12-31';
(9) 模糊查询:like(像)
-
语法:select 字段名 from 表名 where 字段名 like ‘字符串格式’
-
常见的字符串格式:字符串常量、通配符
-- 查询 姓为king的员工信息 用的常量,约等于是=了
select * from employees where last_name like 'King';
常见通配符
- _:代表任意一个字符
- %:代表 0~n 个字符
常见的通配符字符串的格式
以a开头 like ‘a%’
-- 查询 姓为 K 开头的员工信息
select * from employees where last_name like 'K%';
以a结尾 like ‘%a’
-- 查询 姓为 g 结尾的员工信息
select * from employees where last_name like '%g';
包含a like ‘%a%’
-- 查询 姓中包含 i 的员工信息
select * from employees where last_name like '%i%';
某个字符串为3位 like ‘___’ – 一个下划线代表一位
select * from employees where last_name like '___';
某个字符串至少3位
like '___%' like '%___' like '%___%'
select * from employees where last_name like '___%';
某个字符串包含a字符,a字符前面有3位,a字符后面有2位
like '___a__'
select * from employees where last_name like '___a__';
7、排序 order by
(1) 语法:select 字段名 from 表名 where 过滤条件 order by 字段名 排序规则
(2) 排序规则(没有指定排序规则,默认为升序排序)
- asc 升序,从小到大排序
- desc 降序,从大到小排序
-- 查询所有员工信息(工号、名、工资)按照工资从高到低排序(降序)
select employee_id,salary from employees order by salary desc;
-- 查询工资大于1w 按照工资升序排列
select * from employees where salary > 10000 order by salary asc;
注意:where 在 order by 之前
【注意】设置第二排序
-- 查询工号、名字、工资,按照工资升序排列,若工资相同,按照工号降序排列
-- 设置第二排序规则即可用,隔开
select employee_id,first_name,salary from employees ORDER BY salary asc,employee_id desc;
8、dual 哑表
(1) dual:不代表任何一张表,没有实际开发应用业务,内部为一个只有一行一列的表。可以将select 字段名 from 语法补充完整
(2) 出现的场景:当要查询的数据不来自于任何一张表时,为了补充select …from的语法完整性,可以使用 dual 作为填充。
-- 查询系统时间 dual 没有实际含义,用于补充查询语句结构
select now() 时间 from dual;
函数
函数:执行特定功能的一段代码,体现功能。
单行函数
(1) 单行函数:只要有一条数据,函数执行一次,同时产生一个对应的结果(看到一条数据,执行一次)
-- 查询员工名的长度
select first_name,length(first_name) 名长度 from employees
(3) 常见的单行函数
| 函数名 | 作用 |
|---|---|
| now() | 获取当前系统时间 |
| length(‘字符串’)/length(字段名) | 获取长度 |
组函数
(1) 组函数:作用在提前分好的小组数据上,只有一个小组数据,则组函数执行一次,产生对应的一个结果。
(2) 常见组函数
| 函数名 | 作用 |
|---|---|
| sum(列名) | 对指定的列求和 |
| avg(列名) | 对指定的列求平均值 |
| min(列名) | 对指定的列求最小值 |
| max(列名) | 对指定的列求最大值 |
-- 查询所有员工的最高工资 把整个表看成一个小组
select max(salary) 最高工资 from employees;
-- 查询所有员工平均工资
select avg(salary) 平均工资 from employees;
注意:如果在使用组函数时,没有对表数据进行分组,则整张表默认为一组。
(3) 组函数:count(列名)
| 函数名 | 作用 |
|---|---|
| count(列名) | 对查询结果中指定列/字段 不为空的数据进行统计,null不计数 |
| count(*) | 统计查询的 条数 |
-- 查询员工人数
select count(employee_id) from employees;
-- 查询员工表中有提成的员工人数
select count(commission_pct) from employees;
注意: count(列名) 查询个数,sum(列名)为求和
-- 统计查询条数
select count(*) from employees;
分组 group by
1、语法
select 字段名 from 表名 where 过滤条件 group by 分组依据 order by 排序
查询各个部门最高工资
-- 分组,确定分组依据:department_id
-- 根据需求确定组函数
select MAX(salary) from employees group by department_id;
-- 统计各个岗位人数
select count(*),job_id from employees group by job_id;
-- 统计各个部门各个岗位的平均工资
SELECT
avg(salary),
department_id 部门,
job_id 岗位
FROM
employees
GROUP BY
department_id,
job_id;
having的应用
(1) 语法:select…from…where 对分组之前的数据进行过滤
group by … having 对分组之后的数据进行过滤
(2) 作用:having对分组之后的数据进行过滤,作用在group by后面
(3) 注意:having中可以使用组函数,但是where中不能使用组函数
-- 统计各部门平均工资,只显示1w以上
-- 确定分组的依据:group by department_id
-- 确定需求确定的hi用组函数:avg(salary)
-- 确定过滤:分组以后产生结果再过滤
select avg(salary),department_id from employees GROUP BY department_id HAVING avg(salary) > 10000;
-- 统计80、90部门的总工资及部门id
-- 第一
select sum(salary),department_id 部门 from employees GROUP BY department_id HAVING department_id in(80,90);
-- 第二
select sum(salary),department_id 部门 from employees where department_id in(80,90) Group By department_id;
(4) 面试题目:简述 where 和 having 区别
-
where是对分组之前的数据进行过滤
having是对分组之后的数据进行过滤
-
having中可以使用组函数
where中不可以使用组函数
-
如果进行过滤时,where过滤和having过滤都可以实现对应需求时,建议优先使用where进行过滤,提高效率
-
只有对分组之后的结果进行过滤时,才使用having
执行顺序
from:确定数据的来源
where:对原始数据进行过滤,符合条件的才留下
group by:根据需求进行分组
having:对分组之后的结果进行过滤
select:确定查询内容
order by:根据指定的字段及规则进行排序
子查询
1、子查询:在一个查询语句执行过程中,使用了另一个查询语句的结果
注:把子查询SQL放在主查询SQL语句中
(1) 子查询简单理解:在一条select语句中嵌套另一条select语句
(2) 定义在外面select称为主查询;定义在里面的select称为子查询
2、第一种情况:子查询的结果为单个值
(1) 若子查询结果为单个值,可将子查询结果作为过滤条件,参与大于、小于等运算
-- 分步骤书写!!!!
-- 查询工资 大于 平均工资的员工信息
-- 求平均工资avg(salary)
select avg(salary) from employees;
-- 过滤 salary > avgSalary
select * from employees where salary > avg(salary)
-- 合成
select * from employees where salary > (select avg(salary) from employees)
3、第二种情况:子查询的结果为N行1列
(1) 子查询结果为多行1列【产生多个数值】则可以将结果参与主查询的 in 运算
-- 查询与姓‘King’在同一个部门的员工信息
-- 查询姓'King'员工在哪个部门
select department_id from employees where last_name='King'
-- 查询部门员工信息
select * from employees where department_id in(80,90);
-- 合成
select * from employees where department_id in(select department_id from employees where last_name='King')
分页查询【重】
1、应用场景:将数据库中的查询结果按照每页显示的条数进行查询。
2、语法:
select...from ...where...group by...having...order by...limit m,n
参数说明:
m:代表查询的起始条数,默认为查询结果进行编号,编号从0开始
n:代表查询的条数
-- 查询员工工资最高的前五名员工信息
select * from employees order by salary desc limit 0,5
表连接
1、表连接:查询内容来源于两张表或是 n 张表时,需要将2张表或是n张表连接成一张大表进行查询。
注意:进行表连接时,一定要注意要有连接条件。
2、表连接的结果
(1) 表连接之后的字段数等于所有表中的字段数之和。
(2) 表连接之后的行数取决于表连接的类型。
(3) 表连接之后如果出现同名的字段时,可以借助表名.字段名,进行区分。
3、表连接的类型:内连接、外连接(左外连接、右外连接)
内连接【重点】
(1) 语法
select 字段名1,字段名2 from 表名1 join 表名2 on 连接条件
-- 查询员工信息:工号、姓名、工资、部门名称
SELECT
employee_id,
CONCAT(first_name, '-', last_name) 姓名,
salary,
department_name 部门名称
FROM
employees e -- 起别名比较方便
JOIN departments d ON e.department_id = d.department_id;
(2) 特点
- 必须符合指定的连接条件
- 左表 + 右表同时符合连接条件的数据才能留下
- 不管左表还是右表,只要不符合连接条件,都不会被留下。
外连接
(1) 左外连接:left outer join – outer可以省略
语法
select ... from 表名1 left join 表名2 on 连接条件
-- 查询员工信息:工号、姓名、工资、部门名称
SELECT
employee_id,
first_name,
salary,
e.department_id,
department_name
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id
特点:
- 以左表为主,只要在左表中出现的数据,最终结果内都会留下
- 最终:左表+右表同时符合连接条件的数据,加上左表中不符合连接条件的数据
- 注意:右表没有匹配成功的数据不留
(2) 右外连接:right outer join --outer可以省略
语法
select...from
表名1 right join 表名2 on 连接条件
特点:
- 右外连接是以右表为主,只要在右表中出现的数据一定会在结果中被留下。
- 最终留下的数据:左表+右表同时符合连接条件的 + 右表中不符合连接条件的。
- 注:左表中没有匹配成功的数据不留。
多表连接
可以将3张以及以上的表进行连接,两两依次连接即可
-- 查询员工工号 姓 部门名称 部门所在位置 涉及三张表
SELECT
employee_id,
last_name,
department_name,
city
FROM
employees e
JOIN departments d ON e.department_id = d.department_id
JOIN locations l ON d.location_id = l.location_id