Spark Structrued Streaming源码分析--(四)ProgressReporter每个流处理进度计算、StreamQueryManager管理运行的流
- 一、 ProgressReporter每个流处理进度计算
- 1、ProgressReporter示例数据及分析
- 2、ProgressReporter计算当前批次流信息的过程
- 二、 StreamQueryManager管理sparkSession中运行的所有流
一、 ProgressReporter每个流处理进度计算
1、ProgressReporter示例数据及分析
ProgressReporter是每个StreamExecution持有的特性:
abstract class StreamExecution(
xxx )
extends StreamingQuery with ProgressReporter with Logging {}在当前批次计算完成并写出到sink后,会调用ProgressReporter的finishTrigger()方法,统计当前批次的运行时长、处理数据量、offset信息等,是监控流处理性能的一个重要类。每个批次统计出来的信息及解析如下(updateProgress()方法会在日志中直接打印):
Streaming query made progress: {
// ProgressReporter定义的id,实现在StreamExecution,可以读取offset/metadata文件的id内容,没有读取到则是创建流的时候生成,可以用于流的恢复
"id" : "98693db5-2285-4d5c-829a-e22b637dc43f",
// 当前流的运行id,流创建的时候,生成的随机uuid
"runId" : "f3b0ad00-b033-42b2-a364-8c4a666e73fd",
// 通过dataStreamWriter.queryName(name)设置的内容,可用于识别流
"name" : "FileSink with nodeIndex:2_6, createTable:",
// 时间戳,为机器时间,不是输入数据json解析出来的时间
"timestamp" : "2018-08-30T06:03:50.000Z",
// 批次号,每运行一个批次,+1
"batchId" : 108654,
// 上个trigger结束到当前trigger开始期间,输入的数据总量,本次设定为10s
"numInputRows" : 310854,
// numInputRows除以10s得到的数据
"inputRowsPerSecond" : 31085.4,
// numInputRows除以triggerExecution得到的速度
"processedRowsPerSecond" : 111817.9856115108,
"durationMs" : {
// 数据写出到sink用时,重要的性能指标
"addBatch" : 2674,
"getBatch" : 2,
"getOffset" : 33,
"queryPlanning" : 38,
"triggerExecution" : 2780,
"walCommit" : 32
},
"eventTime" : {
// watermark设定字段的各项指标
"avg" : "2018-08-24T00:14:32.963Z",
"max" : "2018-08-30T14:03:00.000Z",
"min" : "1970-01-01T00:00:00.000Z",
// 数据中计算出来的水印时间
"watermark" : "2018-08-30T14:02:00.000Z"
},
// stateStore的状态,需要关注聚合数据量和占用的内存,100个最近version,实际每个stateStore所用内存为(memoryUsedBytes/32分区)x100
"stateOperators" : [ {
"numRowsTotal" : 169184,
"numRowsUpdated" : 27670,
"memoryUsedBytes" : 125625783
} ],
// kafka source的开始、结束offset,流与流join则有多个source,当前示例为一个
"sources" : [ {
"description" : "KafkaSource[Subscribe[NginxLogTopic]]",
"startOffset" : {
"NginxLogTopic" : {
"8" : 13674827351,
"2" : 13674826934,
"5" : 13712751413,
"4" : 13674827290,
"7" : 13674832434,
"1" : 13674832486,
"9" : 13674832435,
"3" : 13674832458,
"6" : 23882070074,
"0" : 13674827347
}
},
"endOffset" : {
"NginxLogTopic" : {
"8" : 13674858434,
"2" : 13674858004,
"5" : 13712782514,
"4" : 13674858374,
"7" : 13674863510,
"1" : 13674863561,
"9" : 13674863508,
"3" : 13674863568,
"6" : 23882101186,
"0" : 13674858417
}
},
"numInputRows" : 310854,
"inputRowsPerSecond" : 31085.4,
"processedRowsPerSecond" : 111817.9856115108
} ],
// sink输出端,每个流只有一个sink
"sink" : {
"description" : "FileSink[hdfs://SERVICE-HADOOP-52e8d84c83d0475b8c709e410142a383/application/streaming_checkpoint/FileSinkData_Aggregate]"
}
}StreamExection和子类MicroBatchExecution用到的成员变量,大部分都在ProgressReporter中定义,其余private关键字的,主要用于流计算状态的统计:
protected def id: UUID
protected def runId: UUID
protected def name: String
protected def triggerClock: Clock
protected def logicalPlan: LogicalPlan
protected def lastExecution: QueryExecution
protected def newData: Map[BaseStreamingSource, LogicalPlan]
protected def availableOffsets: StreamProgress
protected def committedOffsets: StreamProgress
protected def sources: Seq[BaseStreamingSource]
protected def sink: BaseStreamingSink
protected def offsetSeqMetadata: OffsetSeqMetadata
protected def currentBatchId: Long
protected def sparkSession: SparkSession
// 以下Timestamp相关的变量,在startTrigger()和finishTrigger()中被设置
private var currentTriggerStartTimestamp = -1L
private var currentTriggerEndTimestamp = -1L
private var lastTriggerStartTimestamp = -1L
private val currentDurationsMs = new mutable.HashMap[String, Long]()
/** Holds the most recent query progress updates. Accesses must lock on the queue itself. */
// 保存最近的流处理状态统计信息
private val progressBuffer = new mutable.Queue[StreamingQueryProgress]()StreamingQueryProgress即我们列出的示例所在的对象:
class StreamingQueryProgress private[sql](
val id: UUID,
val runId: UUID,
val name: String,
val timestamp: String,
val batchId: Long,
val durationMs: ju.Map[String, JLong],
val eventTime: ju.Map[String, String],
val stateOperators: Array[StateOperatorProgress],
val sources: Array[SourceProgress],
val sink: SinkProgress) extends Serializable {2、ProgressReporter计算当前批次流信息的过程
- 在batch计算开始时(MicroBatchExecution
runActiveStream()方法),调用startTrigger(),主要是一些timestamp相关变量的设置:
/** Begins recording statistics about query progress for a given trigger. */
protected def startTrigger(): Unit = {
logDebug("Starting Trigger Calculation")
lastTriggerStartTimestamp = currentTriggerStartTimestamp
currentTriggerStartTimestamp = triggerClock.getTimeMillis()
currentStatus = currentStatus.copy(isTriggerActive = true)
currentDurationsMs.clear()
}- 在batch计算结束时,调用finishTrigger():
① 统计输入的数据量及watermark:extractExecutionStats()
② 计算运行时长
③ 生成每个source的offset和数据量信息:Seq[SourceProgress]
④ 生成一个newProgress: StreamingQueryProgress对象
⑤ 生成sinkProgress: SinkProgress
⑥ 调用updateProgress()保存和显示。
finishTrigger()代码及分析:
/** Finalizes the query progress and adds it to list of recent status updates. */
protected def finishTrigger(hasNewData: Boolean): Unit = {
currentTriggerEndTimestamp = triggerClock.getTimeMillis()
// 统计输入的数据量及watermark
val executionStats = extractExecutionStats(hasNewData)
// 计算运行时长
val processingTimeSec =
(currentTriggerEndTimestamp - currentTriggerStartTimestamp).toDouble / 1000
val inputTimeSec = if (lastTriggerStartTimestamp >= 0) {
(currentTriggerStartTimestamp - lastTriggerStartTimestamp).toDouble / 1000
} else {
Double.NaN
}
logDebug(s"Execution stats: $executionStats")
// 生成每个source的offset和数据量信息:Seq[SourceProgress]
val sourceProgress = sources.map { source =>
val numRecords = executionStats.inputRows.getOrElse(source, 0L)
new SourceProgress(
description = source.toString,
startOffset = committedOffsets.get(source).map(_.json).orNull,
endOffset = availableOffsets.get(source).map(_.json).orNull,
numInputRows = numRecords,
inputRowsPerSecond = numRecords / inputTimeSec,
processedRowsPerSecond = numRecords / processingTimeSec
)
}
// 生成sinkProgress
val sinkProgress = new SinkProgress(sink.toString)
// 生成newProgress: StreamingQueryProgress对象
val newProgress = new StreamingQueryProgress(
id = id,
runId = runId,
name = name,
timestamp = formatTimestamp(currentTriggerStartTimestamp),
batchId = currentBatchId,
durationMs = new java.util.HashMap(currentDurationsMs.toMap.mapValues(long2Long).asJava),
eventTime = new java.util.HashMap(executionStats.eventTimeStats.asJava),
stateOperators = executionStats.stateOperators.toArray,
sources = sourceProgress.toArray,
sink = sinkProgress)
// 调用updateProgress()保存和显示
if (hasNewData) {
// Reset noDataEventTimestamp if we processed any data
lastNoDataProgressEventTime = Long.MinValue
updateProgress(newProgress)
} else {
val now = triggerClock.getTimeMillis()
if (now - noDataProgressEventInterval >= lastNoDataProgressEventTime) {
lastNoDataProgressEventTime = now
updateProgress(newProgress)
}
}
currentStatus = currentStatus.copy(isTriggerActive = false)
}上述六个步骤,除第一步:统计输入的数据量及watermark外,其余都比较简单,这里分析下第一步对应的代码:
extractExecutionStats()方法返回的是一个ExecutionStats结构:
case class ExecutionStats(
inputRows: Map[BaseStreamingSource, Long],
stateOperators: Seq[StateOperatorProgress],
eventTimeStats: Map[String, String])对应的debug数据:
private def extractExecutionStats(hasNewData: Boolean): ExecutionStats = {
val hasEventTime = logicalPlan.collect { case e: EventTimeWatermark => e }.nonEmpty
// 从offsetSeqMetadata中获取watermarkTimestamp,其内部分别保存了系统时间和数据wm的毫秒数
val watermarkTimestamp =
if (hasEventTime) Map("watermark" -> formatTimestamp(offsetSeqMetadata.batchWatermarkMs))
else Map.empty[String, String]
// SPARK-19378: Still report metrics even though no data was processed while reporting progress.
// 获取StateStore的状态数据,其方法内部用到的StateStoreWriter,主要实现就是StateStoreSaveExec,上一篇文章有讲解
val stateOperators = extractStateOperatorMetrics(hasNewData)
if (!hasNewData) {
return ExecutionStats(Map.empty, stateOperators, watermarkTimestamp)
}
// LogicalRDD与source的映射
val logicalPlanLeafToSource = newData.flatMap { case (source, logicalPlan) =>
logicalPlan.collectLeaves().map { leaf => leaf -> source }
}
// 调用logicalPlan.collectLeaves()方法,获取逻辑执行计划中的开始节点,即source中,通过getBatch(),创建的DataFrame对应的底层LogicalRDD列表
val allLogicalPlanLeaves = lastExecution.logical.collectLeaves() // includes non-streaming
// 调用executedPlan.collectLeaves()方法,获取物理执行计划中的开始节点,即RDDScanExec的列表
val allExecPlanLeaves = lastExecution.executedPlan.collectLeaves()
// 逻辑执行计划和物理执行计划进行关联,case (lp, ep)中, lp是逻辑节点,ep是物理节点SparkPlan,操作的结果是完成ep -> source(物理执行计划到source的映射)
val numInputRows: Map[BaseStreamingSource, Long] =
if (allLogicalPlanLeaves.size == allExecPlanLeaves.size) {
val execLeafToSource = allLogicalPlanLeaves.zip(allExecPlanLeaves).flatMap {
case (lp, ep) => logicalPlanLeafToSource.get(lp).map { source => ep -> source }
}
val sourceToNumInputRows = execLeafToSource.map { case (execLeaf, source) =>
// RDDScanExec的"numOutputRows"信息,即当前source的输入数据量
val numRows = execLeaf.metrics.get("numOutputRows").map(_.value).getOrElse(0L)
source -> numRows
}
// 所有source输入数据量相加
sourceToNumInputRows.groupBy(_._1).mapValues(_.map(_._2).sum) // sum up rows for each source
} else {
Map.empty
}
// 从EventTimeWatermarkExec的eventTimeStats累加器中(e.eventTimeStats.value),获取watermark信息
val eventTimeStats = lastExecution.executedPlan.collect {
case e: EventTimeWatermarkExec if e.eventTimeStats.value.count > 0 =>
val stats = e.eventTimeStats.value
Map(
"max" -> stats.max,
"min" -> stats.min,
"avg" -> stats.avg.toLong).mapValues(formatTimestamp)
}.headOption.getOrElse(Map.empty) ++ watermarkTimestamp
ExecutionStats(numInputRows, stateOperators, eventTimeStats)
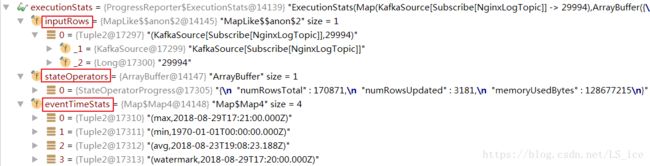
}上述方法中,因为”numOutputRows”输入数据量在物理执行计划中,所以需要进行一系列的映射,实现ep(物理节点) –> lp(逻辑节点) –> source的查找过程,调试信息为:

二、 StreamQueryManager管理sparkSession中运行的所有流
StreamQueryManager中定义的active()方法,用于获取所有运行的流StreamingQuery:
def active: Array[StreamingQuery] = activeQueriesLock.synchronized {
activeQueries.values.toArray
}activeQueries列表里面保存的都是StreamingQuery,接口定义如下:
trait StreamingQuery {
def name: String
def id: UUID
def runId: UUID
def sparkSession: SparkSession
def isActive: Boolean
def exception: Option[StreamingQueryException]
def status: StreamingQueryStatus
def recentProgress: Array[StreamingQueryProgress]
def lastProgress: StreamingQueryProgress
@throws[StreamingQueryException]
def awaitTermination(): Unit
@throws[StreamingQueryException]
def awaitTermination(timeoutMs: Long): Boolean
def processAllAvailable(): Unit
def stop(): Unit
def explain(): Unit
def explain(extended: Boolean): Unit
}可以看到StreamingQuery 与id、name、lastProgress相关的接口定义,都在ProgressReporter中有实现。StreamingQuery的子类StreamingQueryWrapper,实现了对批量、连续处理类型StreamExecution的包装,代码如下,比较简单:
// _streamingQuery即被代理的MicroBatchExecution或ContinuousExecution
class StreamingQueryWrapper(@transient private val _streamingQuery: StreamExecution)
extends StreamingQuery with Serializable {
def streamingQuery: StreamExecution = {
/** Assert the codes run in the driver. */
if (_streamingQuery == null) {
throw new IllegalStateException("StreamingQuery cannot be used in executors")
}
_streamingQuery
}
override def name: String = {
streamingQuery.name
}
override def id: UUID = {
streamingQuery.id
}
override def runId: UUID = {
streamingQuery.runId
}
override def awaitTermination(timeoutMs: Long): Boolean = {
streamingQuery.awaitTermination(timeoutMs)
}
override def stop(): Unit = {
streamingQuery.stop()
}
override def lastProgress: StreamingQueryProgress = {
streamingQuery.lastProgress
}
override def explain(extended: Boolean): Unit = {
streamingQuery.explain(extended)
}
override def recentProgress: Array[StreamingQueryProgress] = {
streamingQuery.recentProgress
}
override def status: StreamingQueryStatus = {
streamingQuery.status
}
}