CRNN+CTC介绍以及验证码识别的应用
卷积神经网络
卷积神经网络主要由一下5种结构组成:
- 输入层。输入层是整个网络结构的输入,在处理图像的卷积神经网络结构中, 它一般代表了一张图片的像素矩阵。可以使用一个三维矩阵来代表一张图片,三维矩阵中的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道(channel)。比如黑白图片的深度为1,而在RGB色彩模式下,图像深度为3。
- 卷积层。卷积层是一个卷积神经网络中最为重要的部分。和传统的全连接层不同,卷积层中每一个结点的输入只是上一层神经网络中的一小块,这一小块常用的大小有3X3,或者5X5。一般来说,通过卷积层处理过的节点矩阵会变得更深。
- 池化层(Pooling)。池化层神经网络结构不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层的个数,从而达到减少整个神经网络参数的目的。
- 全连接层。在经过多轮卷积层和池化层的处理之后,在卷积神经网络的最后一般会是1~2层全连接层来给到最后的分类结果。我们可以将卷积层和池化层堪称自动图像特征提取的过程。在特征提取结束后,仍然需要使用全连接层来完成分类任务。
- Softmax层。Softmax层主要用于分类问题。通过Softmax层,可以得到当前例属于不同种类的概率分布情况。
卷积层
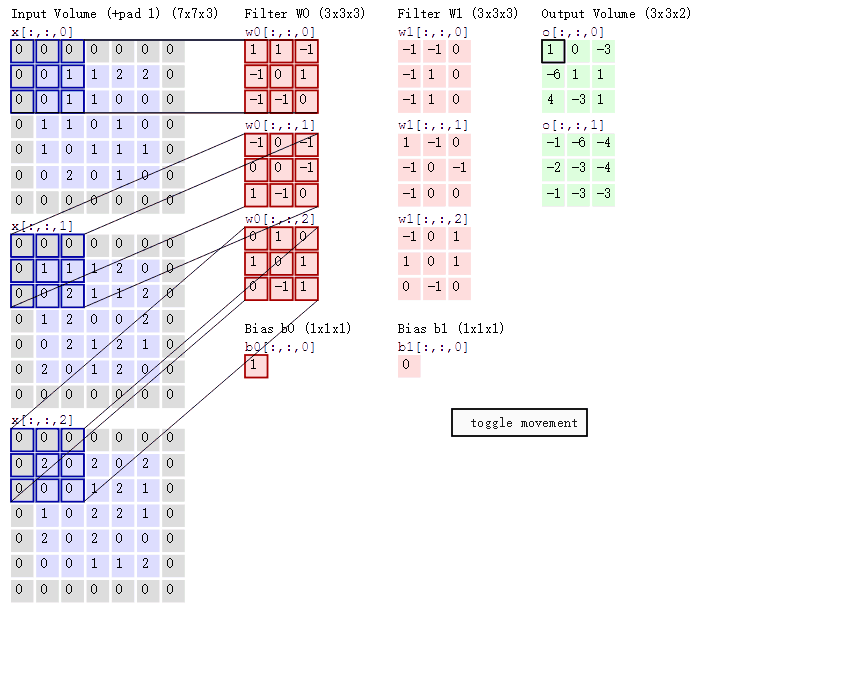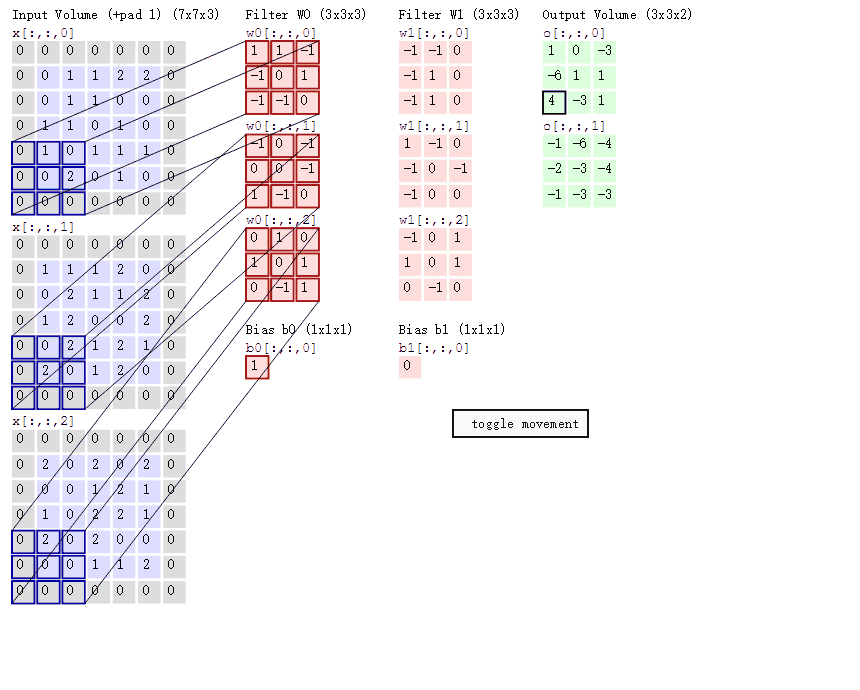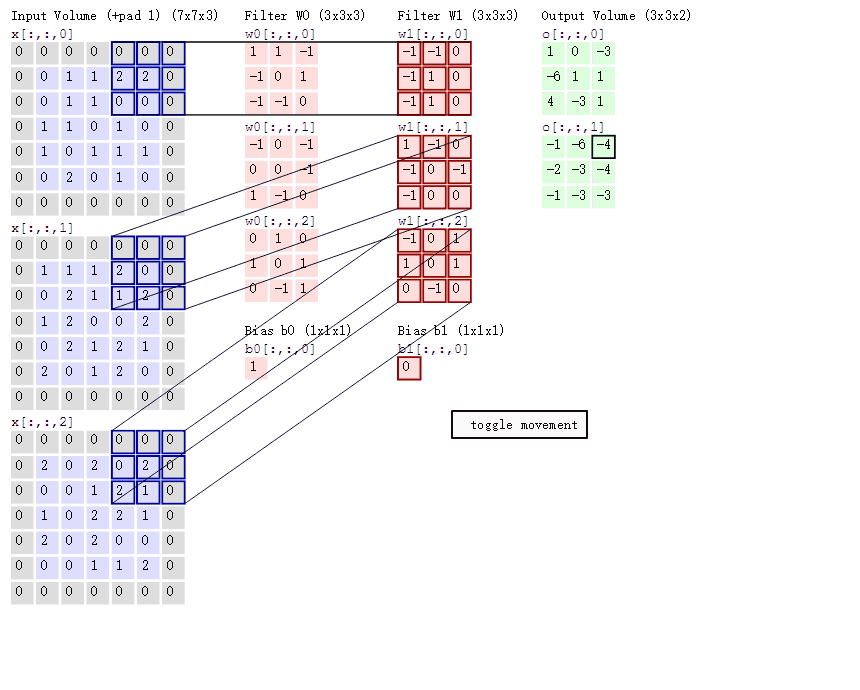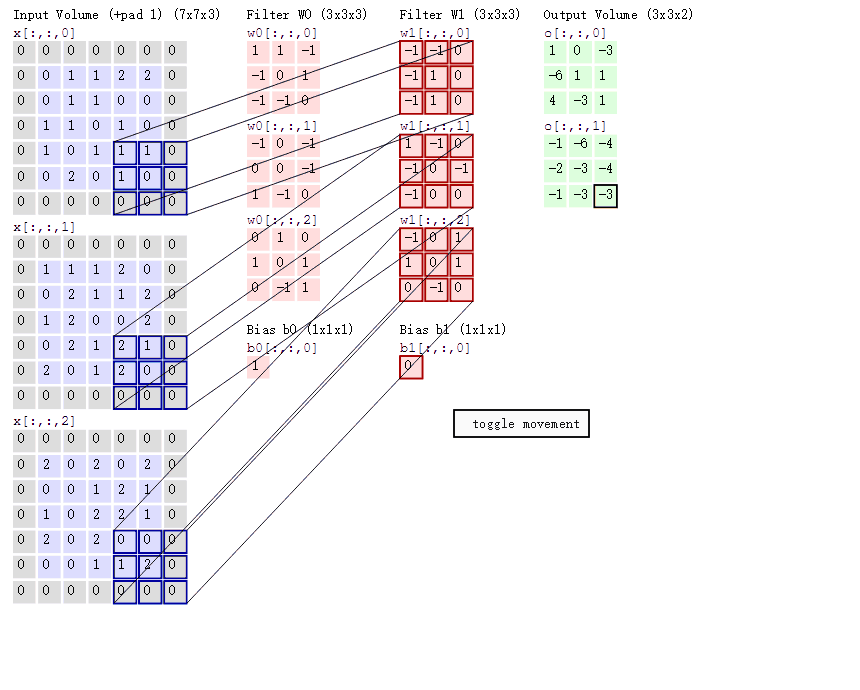
- 两个神经元,即深度depth=2,意味着有两个卷积核。
- 取3*3的局部数据,数据窗口每次移动2个步长,即stride=2。
- padding方式 same 使用0填充边框
- 左边是输入(773中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的卷积核Filter w0、Filter w1
- 最右边则是两个不同的输出
padding 存在的意义在于 为了不丢弃原图信息,padding出来的pixel的值都是0,不存在噪音问题。
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。
tensorflow卷积实现: tf.nn.conv2d()
conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=None,
data_format=None,
name=None
)
- input:输入图片,格式为[batch,长,宽,通道数],长和宽比较好理解,batch就是一批训练数据有多少张照片,通道数实际上是输入图片的三维矩阵的深度,如果是普通灰度照片,通道数就是1,如果是RGB彩色照片,通道数就是3,当然这个通道数完全可以自己设计。
- filter:就是卷积核,其格式为[长,宽,输入通道数,输出通道数],其中长和宽指的是本次卷积计算的“抹布”的规格,输入通道数应当和input的通道数一致,输出通道数可以随意指定。一般卷积深度是在增大的。
- strides: 是步长,一般情况下的格式为[1,长上步长,宽上步长,1],所谓步长就是指抹布(卷积核)每次在长和宽上滑动多少会停下来计算一次卷积。这个步长不一定要能够被输入图片的长和宽整除。
- padding: 是卷积核(抹布)在边缘处的处理方法。
那么具体的卷积方法用一个实例来解释:
(1)输入的数据是[100,80,100,4]的数据,经过的卷积核是[8,8,4,32],步长为[1,4,4,1]策略是valid,那么首先输入的batch=100是不会变的,深度4要变成输出的32,输入图片长度80要在长为8的卷积核下以步长4划过一次,那么抹布的右边缘所处的像素点横坐标应当依次是8,12,16,20……80一共19次计算,所以输出结果的长应当是19,同理,输出结果的宽应当是24,因此输出结果的形状应当是[100,19,24,32]
(2)将第一步的结果输入卷积核[4,4,32,64],步长调整为[1,2,2,1],模式依旧是valid,那么输出结果是[100,9,11,64]
(3)将第二步的结果输入卷积核[3,3,64,128],步长调整为[1,1,1,1],模式调整为same,那么输出结果是[100,9,11,128]
池化层
max_pooling

上图所展示的是max_pooling即取区域最大。上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:[[6, 8], [3,4]]。
avg_pooling
avg_pooling即取区域的平均值,上图的经过avg_pooling得到的结果就是
[[ 13 4 \frac{13}{4} 413, 21 4 \frac{21}{4} 421], [ 2 2 2, 2 2 2]]
tensorflow pooling实现: tf.nn.max_pool() 池化层
tf.nn.max_pool(value, ksize, strides, padding, name=None)
- value : 需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
- ksize: 池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
- strides: 和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
- padding : 和卷积类似,可以取’VALID’ 或者’SAME’. 返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式. padding='VALID’时,无自动填充。padding='SAME’时,自动填充,池化后保持shape不变。
作用 :池化层的输入一般来源于上一个卷积层,主要作用是提供了很强的鲁棒性(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。
卷积神经网络层级结构

上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车。
RNN
为什么需要RNN
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
网络结构
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
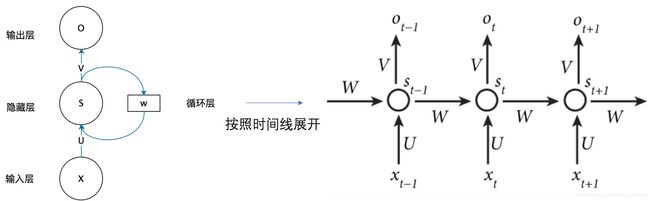
- x是一个向量,它表示输入层的值
- s是一个向量,它表示隐藏层的值
- U是输入层到隐藏层的权重矩阵
- o也是一个向量,它表示输出层的值
- V是隐藏层到输出层的权重矩阵
基本神经元
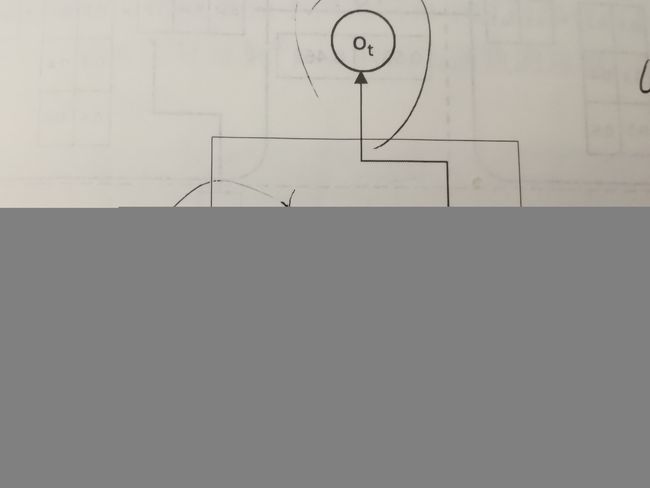
神经元计算

CTC LOSS
- 计算LOSS
知乎链接 - decode,获取最优路径
# 束搜索(Beam Search)
def beam_decode(y, beam_size=10):
T, V = y.shape
log_y = np.log(y)
beam = [([], 0)]
for t in range(T):
new_beam = []
for prefix, score in beam:
for i in range(V): # for every state
new_prefix = prefix + [i]
new_score = score + log_y[t, i]
new_beam.append((new_prefix, new_score))
# top beam_size
new_beam.sort(key=lambda x: x[1], reverse=True)
beam = new_beam[:beam_size]
return beam
知乎链接
构建CRNN+CTC网络
数据预处理
定义X,Y
inputs = tf.placeholder(tf.float32, [None, 100, 32, 1], name='inputs')
targets = tf.sparse_placeholder(tf.int32, name='targets')
batch_size = tf.shape(inputs)[0]
构建CNN网络
def CNN(inputs):
"""
:param inputs: shape [?, 100, 32, 1]
:return:
"""
# conv1 : [?, 100, 32, 64]
conv1 = tf.layers.conv2d(inputs=inputs, filters=64, kernel_size=(3, 3), strides=(1,1), padding="same",
activation=tf.nn.relu)
# pool1 : [?, 50, 16, 64]
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# pool1 : [?, 50, 16, 128]
conv2 = tf.layers.conv2d(inputs=pool1, filters=128, kernel_size=(3, 3), strides=(1,1), padding="same",
activation=tf.nn.relu)
# pool2 : [?, 25, 8, 128]
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# conv3 : [?, 25, 8, 256]
conv3 = tf.layers.conv2d(inputs=pool2, filters=256, kernel_size=(3, 3), strides=(1,1), padding="same",
activation=tf.nn.relu)
# 处理数据 易于训练
bnorm1 = tf.layers.batch_normalization(conv3)
# conv4 : [?, 25, 8, 256]
conv4 = tf.layers.conv2d(inputs=bnorm1, filters=256, kernel_size=(3, 3), padding="same",
activation=tf.nn.relu)
# pool3 : [?, 25, 4, 256]
pool3 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=[1, 2], padding="same")
# pool3 : [?, 25, 4, 512]
conv5 = tf.layers.conv2d(inputs=pool3, filters=512, kernel_size=(3, 3), padding="same",
activation=tf.nn.relu)
# Batch normalization layer
bnorm2 = tf.layers.batch_normalization(conv5)
# conv6: [?, 25, 4, 512]
conv6 = tf.layers.conv2d(inputs=bnorm2, filters=512, kernel_size=(3, 3), padding="same",
activation=tf.nn.relu)
# conv6: [?, 25, 2, 512]
pool4 = tf.layers.max_pooling2d(inputs=conv6, pool_size=[2, 2], strides=[1, 2], padding="same")
# conv7: [?, 24, 1, 512]
conv7 = tf.layers.conv2d(inputs=pool4, filters=512, kernel_size=(2, 2), padding="valid",
activation=tf.nn.relu)
return conv7
处理 CNN OUT
# 初始化CNN
cnn_output = CNN(inputs)
# rnn 神经元数量
max_char_count = tf.shape(cnn_output)[1]
# 计算sequence_length inputs的第一个维度是batch_size
batch_size = tf.shape(inputs)[0]
sequence_length = tf.fill([tf.shape(inputs)[0]], value=max_char_count, name='seq_len')
使用双向LSTM, 构建RNN网络
def BidirectionnalRNN(inputs, seq_len):
"""
Bidirectionnal LSTM Recurrent Neural Network part
"""
with tf.variable_scope(name_or_scope='bidirectional-rnn-1'):
# Forward
lstm_fw_cell_1 = rnn.BasicLSTMCell(256)
# Backward
lstm_bw_cell_1 = rnn.BasicLSTMCell(256)
inter_output, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_1, lstm_bw_cell_1, inputs, seq_len, dtype=tf.float32)
# 拼接LSTM inter_output: [?, 24, 512]
inter_output = tf.concat(inter_output, 2)
with tf.variable_scope(name_or_scope='bidirectional-rnn-2'):
# Forward
lstm_fw_cell_2 = rnn.BasicLSTMCell(256)
# Backward
lstm_bw_cell_2 = rnn.BasicLSTMCell(256)
# 拼接LSTM inter_output: [?, 24, 512]
outputs, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_2, lstm_bw_cell_2, inter_output, seq_len, dtype=tf.float32)
outputs = tf.concat(outputs, 2)
return outputs
初始化CRNN网络
crnn_model = BidirectionnalRNN(cnn_output, sequence_length)
初始化全连接网络
# Flatten batch_size logits : [?, 512]
logits = tf.reshape(crnn_model, [-1, 512])
# 全连接层权重 NUM_CLASSES: 0-9 a-Z 36分类 + 1 blank字符 = 37
W = tf.Variable(tf.truncated_normal([512, config.NUM_CLASSES], stddev=0.1), name="W")
# 全连接层偏置
b = tf.Variable(tf.constant(0., shape=[config.NUM_CLASSES]), name="b")
# 外积 logits
logits = tf.matmul(logits, W) + b
# 还原 batch_size维度
logits = tf.reshape(logits, [-1, max_char_count, config.NUM_CLASSES])
# 最后输出 第一列与第二列置换 为了求ctc_loss
logits = tf.transpose(logits, (1, 0, 2))
计算predict
# 定义tensor map
label_text = tf.contrib.lookup.HashTable(
tf.contrib.lookup.KeyValueTensorInitializer(tf.constant(config.ALPHABET_INDEX, dtype=tf.int64),
tf.constant(config.ALPHABET, dtype=tf.string)),
default_value='-'
)
# beam_width为选取的最优路径个数
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, sequence_length, beam_width=100,
top_paths=1, merge_repeated=False)
# 转化为sparse_tensor
dense_decoded = tf.sparse_tensor_to_dense(decoded[0], default_value=-1)
predict_out = label_text.lookup(dense_decoded, name='prediction')
定义ctc loss
# loss [?] 一维 batch_size 长度
loss = tf.nn.ctc_loss(targets, logits, sequence_length)
# 求平均值
cost = tf.reduce_mean(loss)
定义优化器
# 学习率为0.0001 学习率概念可去学习梯度下降
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cost)
定义精确率
accuracy = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
加入tensorboard summary视图
tf.summary.scalar('loss', cost)
tf.summary.scalar('accuracy', accuracy)
summary_merged = tf.summary.merge_all()
init 变量
inits = [tf.global_variables_initializer(), tf.tables_initializer()]
训练结果:

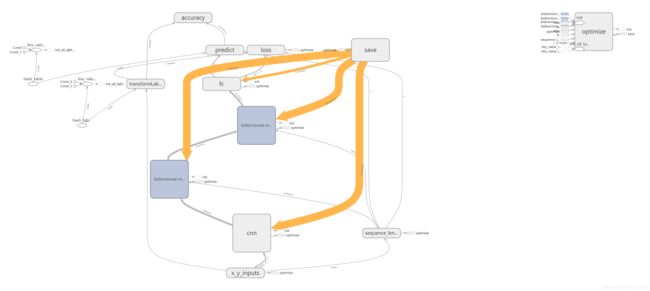
github-CRNN地址