如何理解Keras中的TimeDistributed层并在LSTM中使用
老规矩,主要框架译自How to Use the TimeDistributed Layer for Long Short-Term Memory Networks in Python~,中间加了一点点自己的理解。
长短时记忆网络(LSTMs)是一种流行且功能强大的循环神经网络(RNN)。它们很难配置和应用于任意序列预测问题,即使使用定义良好且“易于使用”的接口(如Python中的Keras深度学习库中提供的接口)也是如此。Keras中出现这种困难的一个原因是使用了TimeDistributed包装器层,并且需要一些LSTM层返回序列而不是单个值。
在本教程中,您将发现为序列预测配置LSTM网络的不同方法、TimeDistributed层所扮演的角色以及如何正确使用它。
完成本教程后,您将知道:
- 如何设计一个用于序列预测的一对一LSTM。
- 如何在没有TimeDistributed层的情况下设计多对一LSTM进行序列预测。
- 如何利用TimeDistributed层设计多对多LSTM进行序列预测。
让我们开始吧。
教程概述
本教程分为五个部分;它们是:
- TimeDistributed层
- 序列学习问题
- 用于序列预测的一对一LSTM
- 用于序列预测的多对一LSTM(没有TimeDistributed)
- 用于序列预测的多对多LSTM (TimeDistributed)
TimeDistributed层
LSTMs功能强大,但是很难使用和配置,尤其是对于初学者。附加的复杂性是TimeDistributed层(和前TimedistributedDense层),它被神秘地描述为一个层包装器:
这个包装器允许我们对输入的每个时间片应用一个层。
您应该如何以及何时在LSTMs中使用这个包装器?
当您搜索关于Keras GitHub问题和StackOverflow上的包装器层的讨论时,这种混淆就更加复杂了。
例如,在“When and How to use TimeDistributedDense”一文中,fchollet (Keras的作者)解释道:
TimeDistributedDese对三维张量的每个时间步长应用相同的Dense(全连接)操作。
如果您已经了解TimeDistributed层的用途以及何时使用它,那么这是非常有意义的,但是对初学者毫无帮助。
本教程的目的是通过一些工作示例来澄清使用带有LSTMs的TimeDistributed包装器的困惑,您可以查看、运行和使用这些示例来帮助您具体理解。
序列学习问题
我们将使用一个简单的序列学习问题来演示TimeDistributed层。
在这个问题中,序列[0.0,0.2,0.4,0.6,0.8]一次作为一个输入,然后必须作为输出返回,一次作为一个项。把它看作是学习一个简单的回声程序。我们给出0.0作为输入,我们希望看到0.0作为输出,对序列中的每一项重复执行。我们可以直接生成这个序列如下:
from numpy import array
length = 5
seq = array([i/float(length) for i in range(length)])
print(seq)运行此示例将打印生成的序列:
![]()
该示例是可配置的,如果您愿意,稍后还可以自己处理较长/较短的序列。请在评论中告诉我你的结果。
用于序列预测的一对一LSTM
在我们深入研究之前,重要的是证明这个序列学习问题可以分段学习。也就是说,我们可以将问题重新构造为序列中每个项的输入-输出对的数据集。给定0,网络应该输出0,给定0.2,网络必须输出0.2,以此类推。
这是该问题最简单的公式,它要求将序列分解为输入-输出对,并对序列进行一次一步预测,然后在网络外部收集序列。输入-输出对如下:

LSTMs的输入必须是三维的(三维的结构是[样本批大小,滑窗大小,特征数量],详细介绍可以参考博客lstm数据格式与老鼠屎的旧博文Keras实战:基于LSTM的股价预测方法)。
图1 RNN结构图(摘抄自lstm数据格式)
图2 batch结构图(摘抄自lstm数据格式)
图3 LSTM输入训练过程(摘抄自lstm数据格式)
因此,其输入格式为[batch,n_steps,n_input]。

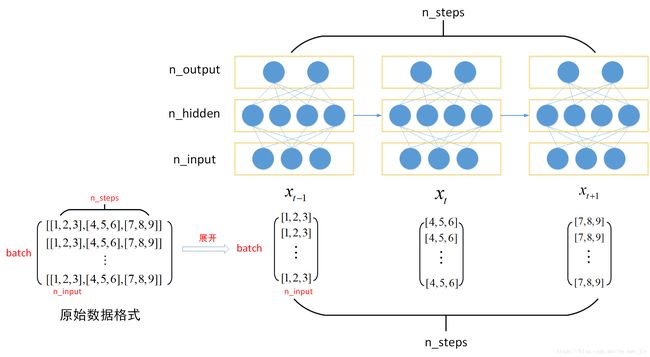
我们可以用5个样本,1个时间步长,1个特征将二维序列重新塑造成三维序列。我们将输出定义为5个带有1个特性的示例。
X = seq.reshape(5, 1, 1)
y = seq.reshape(5, 1)我们将网络模型定义为具有1个输入和1个时间步长。第一个隐藏层将是一个具有5个单元的LSTM。输出层为1输出的全连接层。该模型将采用有效的Adam优化算法和均方误差损失函数进行拟合。批处理大小被设置为epoch中的样本数量,以避免必须使LSTM有状态并手动管理状态重置,尽管在每个样本显示到网络后更新权重也可以轻松地做到这一点。
完整的代码清单如下:
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# prepare sequence
length = 5
seq = array([i/float(length) for i in range(length)])
X = seq.reshape(len(seq), 1, 1)
y = seq.reshape(len(seq), 1)
# define LSTM configuration
n_neurons = length
n_batch = length
n_epoch = 1000
# create LSTM
model = Sequential()
model.add(LSTM(n_neurons, input_shape=(1, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
# train LSTM
model.fit(X, y, epochs=n_epoch, batch_size=n_batch, verbose=2)
# evaluate
result = model.predict(X, batch_size=n_batch, verbose=0)
for value in result:
print('%.1f' % value)运行示例首先打印已配置网络的结构。我们可以看到LSTM层有140个参数。根据输入数(1)和输出数(隐层5个单元5个)计算,如下(这个地方可以参考老鼠屎的旧博文Keras实战:基于LSTM的股价预测方法):
n = 4 * ((inputs + 1) * outputs + outputs^2)
n = 4 * ((1 + 1) * 5 + 5^2)
n = 4 * 35
n = 140我们还可以看到,全连接层只有6个参数表示输入的数量(前一层的5个输入为5个)、输出的数量(层中1个神经元为1个)和偏置。
n = inputs * outputs + outputs
n = 5 * 1 + 1
n = 6 
网络正确地学习预测问题。

用于序列预测的多对一LSTM(没有TimeDistributed)
在本节中,我们将开发一个LSTM来一次性输出序列,尽管没有TimeDistributed包装层。LSTMs的输入必须是三维的。我们可以用1个样本,5个时间步长,1个特征将二维序列重新塑造成三维序列。我们将把输出定义为一个包含5个特性的示例。
X = seq.reshape(1, 5, 1)
y = seq.reshape(1, 5)您马上就可以看到,必须稍微调整问题定义,以支持在没有TimeDistributed包装器的情况下进行序列预测的网络。具体来说,输出一个向量,而不是一步一步地构建一个输出序列。这种差别听起来可能很细微,但对于理解TimeDistributed包装器的角色很重要。
我们将定义模型为一个输入,包含5个时间步骤。第一个隐藏层将是一个具有5个单元的LSTM。输出层为5个神经元的全连接层。
# create LSTM
model = Sequential()
model.add(LSTM(5, input_shape=(5, 1)))
model.add(Dense(length))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())接下来,我们将模型只适用于500个epoch,对于训练数据集中的单个样本,批处理大小为1。
# train LSTM
model.fit(X, y, epochs=500, batch_size=1, verbose=2)综上所述,完整的代码清单如下所示。
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# prepare sequence
length = 5
seq = array([i/float(length) for i in range(length)])
X = seq.reshape(1, length, 1)
y = seq.reshape(1, length)
# define LSTM configuration
n_neurons = length
n_batch = 1
n_epoch = 500
# create LSTM
model = Sequential()
model.add(LSTM(n_neurons, input_shape=(length, 1)))
model.add(Dense(length))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
# train LSTM
model.fit(X, y, epochs=n_epoch, batch_size=n_batch, verbose=2)
# evaluate
result = model.predict(X, batch_size=n_batch, verbose=0)
for value in result[0,:]:
print('%.1f' % value)运行示例首先打印已配置网络的summary。我们可以看到LSTM层有140个参数,如上一节所示。

LSTM单元已经损坏,每个输出一个值,提供一个5个值的向量作为全连接层的输入。时间维度或序列信息已被丢弃并分解为一个包含5个值的向量。
我们可以看到,全连接的输出层有5个输入,预计输出5个值。我们可以将需要学习的30个权重解释如下:
n = inputs * outputs + outputs
n = 5 * 5 + 5
n = 30模型拟合良好,打印出预测序列前的打印损耗信息。
序列被正确地复制,但是作为单个块而不是逐步地通过输入数据。我们可能使用了一个Dense层作为第一个隐藏层,而不是LSTMs,因为这种LSTMs的使用并没有充分利用它们在序列学习和处理方面的全部能力。
![]()
用于序列预测的多对多LSTM (TimeDistributed)
在本节中,我们将使用TimeDistributed层来处理LSTM隐藏层的输出。
当使用TimeDistributed包装层时,有两个关键点需要记住:
- 输入必须(至少)是3D的。这通常意味着您需要在TimeDistributed包装Dense层之前配置最后一个LSTM层来返回序列(例如,将“return_sequences”参数设置为“True”)。
- 输出将是3D的。这意味着,如果您的TimeDistributed包装Dense层是您的输出层,并且您正在预测一个序列,那么您将需要将y数组调整为一个3D向量。
那么究竟什么是TimeDistributed层呢?原谅我念了很久才懂一点点~这里引用一下When and How to use TimeDistributedDense中EdwardRaff的回答(TimeDistributed层的意义):
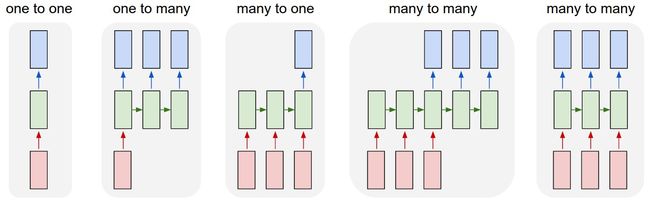
RNNs are capable of a number of different types of input / output combinations, as seen below.
The
TimeDistributedDenselayer allows you to build models that do the one-to-many and many-to-many architectures. This is because the output function for each of the "many" outputs must be the same function applied to each timestep. TheTimeDistributedDenselayers allows you to apply that Dense function across every output over time. This is important because it needs to be the same dense function applied at every time step.If you didn't not use this, you would only have one final output - and so you use a normal dense layer. This means you are doing either a one-to-one or a many-to-one network, since there will only be one dense layer for the output.
关于其作用,Keras官方 API解释地更为简单粗暴:
keras.layers.TimeDistributed(layer)这个封装器将一个层应用于输入的每个时间片。
输入至少为 3D,且第一个维度应该是时间所表示的维度。
考虑 32 个样本的一个 batch, 其中每个样本是 10 个 16 维向量的序列。 那么这个 batch 的输入尺寸为
(32, 10, 16), 而input_shape不包含样本数量的维度,为(10, 16)。你可以使用
TimeDistributed来将Dense层独立地应用到 这 10 个时间步的每一个:# 作为模型第一层 model = Sequential() model.add(TimeDistributed(Dense(8), input_shape=(10, 16))) # 现在 model.output_shape == (None, 10, 8)输出的尺寸为
(32, 10, 8)。在后续的层中,将不再需要
input_shape:model.add(TimeDistributed(Dense(32))) # 现在 model.output_shape == (None, 10, 32)输出的尺寸为
(32, 10, 32)。
TimeDistributed可以应用于任意层,不仅仅是Dense, 例如运用于Conv2D层:model = Sequential() model.add(TimeDistributed(Conv2D(64, (3, 3)), input_shape=(10, 299, 299, 3)))
这里可以结合上面的图3进行理解。相信我,读10遍以上,意思慢慢地就了解了。
下面继续我们的教程。我们可以定义输出的形状为1个样本,5个时间步长,1个特征,就像输入序列一样,如下:
y = seq.reshape(1, length, 1)通过将“return_sequences”参数设置为true,我们可以定义LSTM隐藏层来返回序列,而不是单个值。
model.add(LSTM(n_neurons, input_shape=(length, 1), return_sequences=True))这使得每个LSTM单元返回一个由5个输出组成的序列,在输入数据中的每个时间步对应一个输出,而不是像前面示例中那样只返回一个输出值。
我们还可以使用输出层上的TimeDistributed将一个完全连接的Dense层封装为一个输出。
model.add(TimeDistributed(Dense(1)))输出层中的单个输出值是关键。它强调,我们打算为输入中的每个时间步从序列中输出一个时间步。碰巧我们一次要处理输入序列的5个时间步长。
TimeDistributed通过在LSTMs输出上应用相同的Dense层(相同的权重),每次执行一个步骤来实现这个技巧。这样,输出层只需要一个到每个LSTM单元的连接(加上一个偏置)。
因此,需要增加培训期的数目,以应付较小的网络能力。为了匹配第一个一对一的例子,我将它从500加倍到1000。
综上所述,下面提供了完整的代码清单。
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import LSTM
# prepare sequence
length = 5
seq = array([i/float(length) for i in range(length)])
X = seq.reshape(1, length, 1)
y = seq.reshape(1, length, 1)
# define LSTM configuration
n_neurons = length
n_batch = 1
n_epoch = 1000
# create LSTM
model = Sequential()
model.add(LSTM(n_neurons, input_shape=(length, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
# train LSTM
model.fit(X, y, epochs=n_epoch, batch_size=n_batch, verbose=2)
# evaluate
result = model.predict(X, batch_size=n_batch, verbose=0)
for value in result[0,:,0]:
print('%.1f' % value)运行这个示例,我们可以看到所配置网络的结构。我们可以看到,在前面的示例中,LSTM隐藏层中有140个参数。
全连接的输出层则完全不同。事实上,它与一对一的例子完全匹配。对于前一层的每个LSTM单元,一个神经元有一个权值,加上一个偏置输入。
这做了两件重要的事:
- 允许按照定义问题的方式构造和学习问题,即一个输入对应一个输出,将每个时间步骤的内部流程分开。
- 通过要求更少的权重来简化网络,这样一次只处理一个时间步长。
一个简单的全连接层应用于前一层提供的序列中的每个时间步长,以构建输出序列。

我们可以用时间步长和TimeDistributed层作为第一个示例中实现一对一网络的更紧凑的方法来考虑问题的框架。它甚至可能在更大的范围内更有效(空间或时间方面)。
进一步的阅读
下面是一些关于TimeDistributed层的资源和讨论,您可能想深入其中。
- TimeDistributed Layer in the Keras API
- TimeDistributed code on GitHub
- The difference between ‘Dense’ and ‘TimeDistributedDense’ of ‘Keras’ on StackExchange
- When and How to use TimeDistributedDense on GitHub
参考资料:
文中已标明,但是再次感谢!
How to Use the TimeDistributed Layer for Long Short-Term Memory Networks in Python
lstm数据格式
Keras实战:基于LSTM的股价预测方法
When and How to use TimeDistributedDense on GitHub
TimeDistributed Layer in the Keras API