这篇文章介绍自定义一个估算器(分类器)Estimator的完整流程。
请先参照鸢尾花iris案例并完成练习。
自定义Custom Estimator和预制Pre-made Estimator
在上面iris的案例中我们使用了tensorflow里面自带的深度神经网络分类器tf.estimator.DNNClassifie。这些tensorflow自带的estimator称为预制估算器Pre-made Estimator(预创建的Estimator)。
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir=models_path,
config=ckpt_config) #
Tensorflow允许我们自己创建更加灵活的Custom Estimator。自定义Estimator是tf.estimator.Estimator()方法生成,能够像预制Estimator一样使用。

结构概览
从表面看,我们的Estimator应该具有DNNClassifier一样的功能
- 创建的时候接收一些参数,如feature_columns、hidden_units、n_classes等
- 具有train()、evaluate()、predict()三个方法用来训练、评价、预测
如上所说,我们使用 tf.estimator.Estimator()方法来生成自定义Estimator,它的语法格式是
tf.estimator.Estimator(
model_fn, #模型函数
model_dir=None, #存储目录
config=None, #设置参数对象
params=None, #超参数,将传递给model_fn使用
warm_start_from=None #热启动目录路径
)
模型函数model_fn是唯一没有默认值的参数,它也是自定义Estimator最关键的部分,包含了最核心的算法。model_fn需要一个能够进行运算的函数,它的样子应该长成这样
my_model(
features, #输入的特征数据
labels, #输入的标签数据
mode, #train、evaluate或predict
params #超参数,对应上面Estimator传来的参数
)
神经网络层Layers
model_fn应该怎么运作?下图展示了iris案例的情况
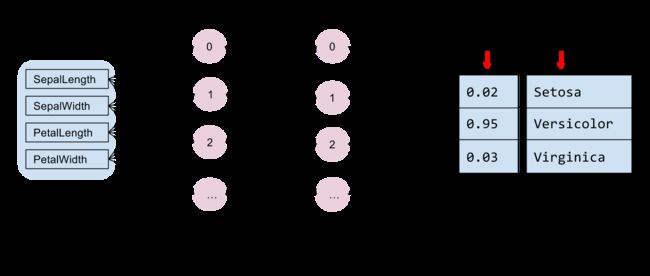
从这个图中我没看到的结构:
- 输入层Input Layer,数据从这里进入
- 隐藏层Hidden Layer,2个,每层包含多个节点,数据流经这里,被推测规律
- 输出层Output Layer,将推测的结果整理显示出来
我们并不需要手工实现隐藏层的算法和工作原理,Tensorflow已经为我们设计好。我们需要的只是创建这些神经网络层,并确保它们按照正常的顺序连接起来,至于其中如何推算演绎的魔法就完全交给tensorflow就可以了。
mode_fn需要完成的就是创建和组织这些神经层。
编写model_fn
对应我们创建Estimator时候的参数
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir=models_path,
config=ckpt_config)
这些参数都会被Estimator打包放在params超参数中,传递给model_fn,所以我们用下面的代码在model_fn内创建网络层
import tensorflow as tf
#自定义模型函数
def my_model_fn(features,labels,mode,params):
#输入层,feature_columns对应Classifier(feature_columns=...)
net = tf.feature_column.input_layer(features, params['feature_columns'])
#隐藏层,hidden_units对应Classifier(unit=[10,10]),2个各含10节点的隐藏层
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
#输出层,n_classes对应3种鸢尾花
logits = tf.layers.dense(net, params['n_classes'], activation=None)
输入层Input Layer
在上面代码中,我们使用这行代码创建输入层
net = tf.feature_column.input_layer(features, params['feature_columns'])
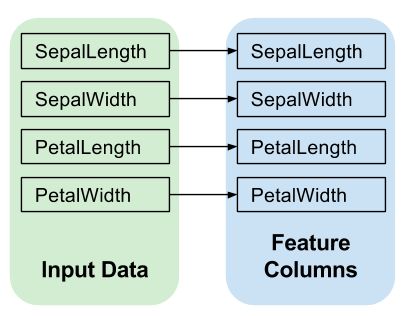
如下图所示,Input Layer把输入的数据features填充到特征列params['feature_column']里面,稍后它会被继续传递到隐藏层hidden layer:
隐藏层Hidden Layer
我们使用循环为hidden_unit列表([10,10])创建了2个隐藏图层,每个图层的神经元节点unit都等于10.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
我们注意到上面的输入层叫做net(暂时叫net0),for循环里的隐藏层也叫net(暂叫net1)而且参数里还有net(net2),示意代码如下
#仅供示意
net0 = tf.feature_column.input_layer...
for units ...
net1 = tf.layers.dense(net2, ...)
实际运行到隐藏层第一层(for循环第一次)的时候,我们创建隐藏层net1,并把net0作为参数输入到net1的,也就是隐藏第一层中关联了输入层:
input_net0=...#创建输入层
hidden_net1=tf.layers.dense(input_net0,...) #创建隐藏层1
然后for第二次循环的时候我们又关联了第一个隐藏层hidden_net1:
hidden_net2=tf.layers.dense(hidden_net1,...) #创建隐藏层2
这样逐层传递就形成了链条,数据沿着链条进行流动Flow和处理
intputLayer - hiddenLayer1 - hiddenLayer2 - ...

输出层Output Layer
我们使用了这行代码创建输出层,请注意net!
logits = tf.layers.dense(net, params['n_classes'], activation=None)
仍然是链条的延续!
但是activation这里改为了None,不再激活后续的部分,所以输出层就是链条的终点。
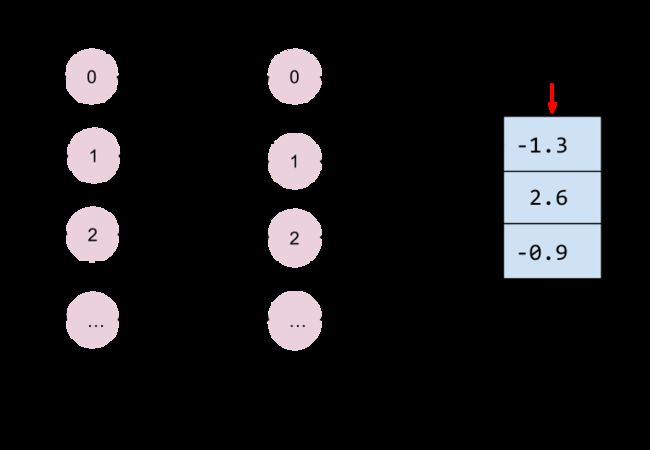
请注意这里的[-1.3,2.6,-0.9]表示了某朵花的测量数据分别属于三种分类的可能性,但是这里的数字很奇怪,甚至还有负数...稍后我们会对它们进行转化。
训练train、评价evaluate和预测predict
前面我们知道,自定义的估算分类器必须能够用来执行my_classifier.train()、my_classifier.evaluate()、my_classifier.predict()三个方法。
但实际上,它们都是model_fn这一个函数的分身!
上面出现的model_fn语法:
my_model(
features, #输入的特征数据
labels, #输入的标签数据
mode, #train、evaluate或predict
params #超参数,对应上面Estimator传来的参数
)
注意第三个参数mode,如果它等于"TRAIN"我们就执行训练:
#示意代码
my_model(..,..,"TRAIN",...)
如果是“EVAL”就执行评价,“PREDICT”就执行预测。
我们修改my_model代码来实现这三个功能:
def my_model_fn(features,labels,mode,params):
#输入层,feature_columns对应Classifier(feature_columns=...)
net = tf.feature_column.input_layer(features, params['feature_columns'])
#隐藏层,hidden_units对应Classifier(unit=[10,10]),2个各含10节点的隐藏层
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
#输出层,n_classes对应3种鸢尾花
logits = tf.layers.dense(net, params['n_classes'], activation=None)
#预测
predicted_classes = tf.argmax(logits, 1) #预测的结果中最大值即种类
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis], #拼成列表[[3],[2]]格式
'probabilities': tf.nn.softmax(logits), #把[-1.3,2.6,-0.9]规则化到0~1范围,表示可能性
'logits': logits,#[-1.3,2.6,-0.9]
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
#损失函数
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
#训练
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1) #用它优化损失函数,达到损失最少精度最高
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step()) #执行优化!
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
#评价
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op') #计算精度
metrics = {'accuracy': accuracy} #返回格式
tf.summary.scalar('accuracy', accuracy[1]) #仅为了后面图表统计使用
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)
如上面所示,请将预测Predict需要放在最先编写,否则可以引发后续错误。
下面我们分别详解三个方法的代码
预测Predict
因为预测最后我们需要返回花的种类label,还希望知道这个预测有多精确,所以在预测部分的代码里面,首先取到三种花可能性最大的一个predicted_classes即[-1.3,2.6,-0.9]中的2.6;然后把它转成列表格式[[2.6]];同时把logit得到的[-1.3,2.6,-0.9]转化为表示0~1可能性的小数[0.01926995 0.95198274 0.02874739]
predicted_classes = tf.argmax(logits, 1) #预测的结果中最大值即种类
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis], #拼成列表[[3],[2]]格式
'probabilities': tf.nn.softmax(logits), #把[-1.3,2.6,-0.9]规则化到0~1范围,表示可能性
'logits': logits,#[-1.3,2.6,-0.9]
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
注意最后一句,我们返回return的是一个EstimatorSpec对象,下面的训练predict和评价evaluate也都返回EstimatorSpec形式的对象,但是参数不同,请留意。
我们可以使用以下代码在单独文件测试tf.newaxis和tf.nn.softmax对数据转化的作用
import tensorflow as tf
a=tf.constant([2.6],name='a')
b=a[:,tf.newaxis]
a2=tf.constant([-1.3,2.6,-0.9],name='a')
b2= tf.nn.softmax(a2)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run(b))
print(session.run(b2))
输出
[[2.6]]
[0.01926995 0.95198274 0.02874739]
损失函数Loss
损失函数是Tensorflow中神经网络的重要概念,简单说,它能够计算出我们模型的偏差程度,结果越大,我们的模型就偏差越大、离正确也远、也越不准确、越糟糕。
为了降低损失,我们可以使用更多更好的数据,还可以设计更好的优化方法,来优化改进模型,让损失变为最小。
训练神经网络模型的目标就是把偏差损失降为最小,机器学习就是一批一批数据反复分析计算反复尝试,不断的利用优化方法,想尽办法把Loss的值降到最小的过程。
优化方法设计的越好好,损失也就越少,精度也就越高。
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
这里我们使用了tensorflow提供的稀疏柔性最大交叉熵sparse_softmax_cross_entropy来计算损失程度,它对于分类问题很有效,DNNClassifier也使用了这个方法。
训练Train
我们在训练部分代码中,创建了优化器optimizer,然后使用它尝试将我们的损失函数loss变为最小minimize:
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1) #用它优化损失函数,达到损失最少精度最高
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step()) #执行优化!
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
评价Evaluate
我们使用下面的代码来评价预测结果prediction和test数据中植物学家标记的数据是否足够吻合:
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op') #计算精度
metrics = {'accuracy': accuracy} #返回格式
tf.summary.scalar('accuracy', accuracy[1]) #仅为了后面图表统计使用
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)
因为我们希望能够评价后知道模型的精度,所以首先使用tf.metrics.accuracy方法对比植物学家的标记labels和批量预测结果predicted_classes([[-1.3,2.6,-0.9],...]),
导入数据
相关文件可以从百度云这里下载 密码:y3id
经过上面的过程,我们创建了估算分类器的核心部分model_fn,接下来我们继续添加以下代码,导入数据备用。具体解释请参照鸢尾花iris案例
import os
import pandas as pd
FUTURES = ['SepalLength', 'SepalWidth','PetalLength', 'PetalWidth', 'Species']
SPECIES = ['Setosa', 'Versicolor', 'Virginica']
dir_path = os.path.dirname(os.path.realpath(__file__))
train_path=os.path.join(dir_path,'iris_training.csv')
test_path=os.path.join(dir_path,'iris_test.csv')
train = pd.read_csv(train_path, names=FUTURES, header=0)
train_x, train_y = train, train.pop('Species')
test = pd.read_csv(test_path, names=FUTURES, header=0)
test_x, test_y = test, test.pop('Species')
创建分类器
继续添加代码,使用model_fn来生成自定义分类器(请注意最后几行):
feature_columns = []
for key in train_x.keys():
feature_columns.append(tf.feature_column.numeric_column(key=key))
#创建自定义分类器
classifier = tf.estimator.Estimator(
model_fn=my_model, #注意这里!
params={
'feature_columns': feature_columns,
'hidden_units': [10, 10],
'n_classes': 3,
})
训练模型
添加下面代码开始训练模型
#针对训练的喂食函数
batch_size=100
def train_input_fn(features, labels, batch_size):
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
dataset = dataset.shuffle(1000).repeat().batch(batch_size) #每次随机调整数据顺序
return dataset.make_one_shot_iterator().get_next()
#开始训练
classifier.train(
input_fn=lambda:train_input_fn(train_x, train_y, 100),
steps=1000)
评价模型
添加下面的代码可以对模型进行评价并打印出精度
#针对测试的喂食函数
def eval_input_fn(features, labels, batch_size):
features=dict(features)
inputs=(features,labels)
dataset = tf.data.Dataset.from_tensor_slices(inputs)
dataset = dataset.batch(batch_size)
# return dataset
return dataset.make_one_shot_iterator().get_next()
#评估我们训练出来的模型质量
eval_result = classifier.evaluate(
input_fn=lambda:eval_input_fn(test_x, test_y,batch_size))
print(eval_result)
进行预测
添加以下代码让用我们的模型可以进行交互预测
#支持100次循环对新数据进行分类预测
for i in range(0,100):
print('\nPlease enter features: SepalLength,SepalWidth,PetalLength,PetalWidth')
a,b,c,d = map(float, input().split(',')) #捕获用户输入的数字
predict_x = {
'SepalLength': [a],
'SepalWidth': [b],
'PetalLength': [c],
'PetalWidth': [d],
}
#进行预测
predictions = classifier.predict(
input_fn=lambda:eval_input_fn(predict_x,
labels=[0,],
batch_size=batch_size))
#预测结果是数组,尽管实际我们只有一个
for pred_dict in predictions:
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(SPECIES[class_id],100 * probability)
模型的恢复与保存设置
修改创建估算分类器的代码设置model_dir模型保存与自动恢复,并设定日志打印
tf.logging.set_verbosity(tf.logging.INFO)
models_path=os.path.join(dir_path,'mymodels/')
#创建自定义分类器
classifier = tf.estimator.Estimator(
model_fn=my_model_fn,
model_dir=models_path,
params={
'feature_columns': feature_columns,
'hidden_units': [10, 10],
'n_classes': 3,
})
TensorBoard信息板
打开新的命令行工具窗口,使用下面的命令启动信息板:
tensorboard --logdir=~/desktop/iris/mymodels
这里的~/desktop/iris/models应该和上面配置的model_dir=models_path完全一致,正常情况会输出很多信息,并在最后显示类似下面的提示
TensorBoard 1.6.0 at http://xxx-xxx-xxx.local:6006 (Press CTRL+C to quit)
把这段http://xxx-xxx-xxx.local:6006复制到浏览器窗口,或者复制http://localhost:6006/就可以打开TensorBoard信息板,这里包含了很多关于模型的性能质量等方面的图表:
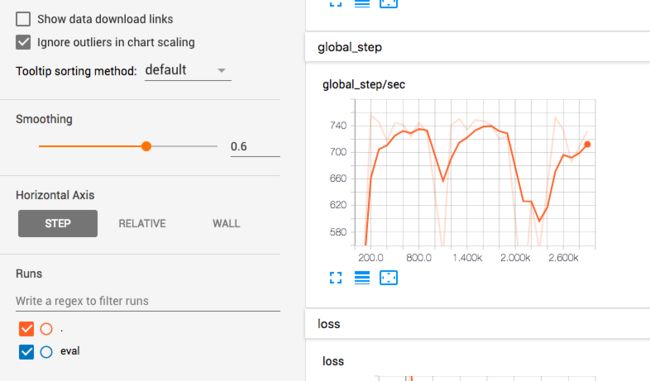
关于TensorBoard更多内容可以点右上角的问号打开Github上的项目详细说明。
上面的代码和相关文件可以从百度云这里下载 密码:y3id
探索人工智能的新边界
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,感谢转发~
END