storm流程——storm
相关参考资料链接:
storm框架入门
《storm入门》
storm是一个分布式的,可靠的,容错的数据流处理系统。它会把工作任务委托给不同类型的组件,每个组件负责处理一项简单特定的任务。Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。
1.storm的基本概念:
(1)spout 龙卷,读取原始数据为bolt提供数据;
(2)bolt 雷电,从spout或其它bolt接收数据,并处理数据,处理结果可作为其它bolt的数据源或最终结果;
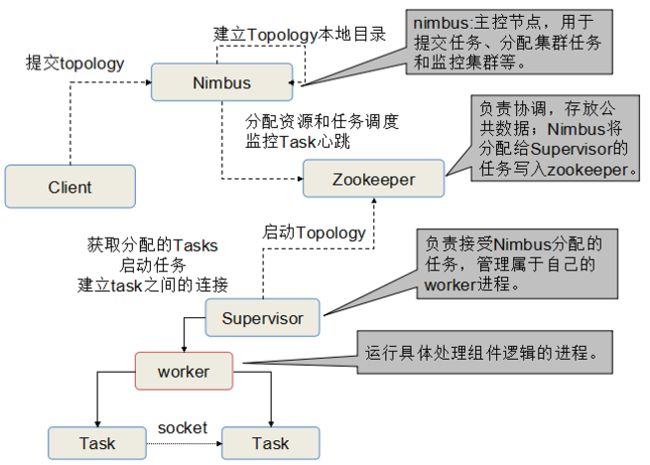
(3)nimbus 雨云,主节点的守护进程,负责提交任务,为工作节点分发任务和监控集群;
(4)supervisor 主管,工作节点的进程,负责接收来自nimbus的任务,管理属于自己的worker进程;
(5)worker 工人,运行具体处理组件逻辑的进程;
(6)task 任务,worker中每一个spout/bolt的线程称为一个task.
(7)topology 拓扑结构,Storm的一个任务单元,一个topology是由一组Spout组件(数据源)和Bolt组件(数据操作)通过Stream Groupings进行连接的图;
(8)define field(s) 定义域,由spout或bolt提供,被bolt接收。
(9)stream 小溪,是Storm中的一个核心概念,Storm将输入的数据看成流,它是以tuple为单位组成的一条有向无界的数据流;
(10)tuple 元组,是在Spout和Bolt传递信息的基本单位,tuple可以理解成键值对,其中,键就是在定义在declareStream方法中的Fields字段,而值就是在emit方法中发送的Values字段。
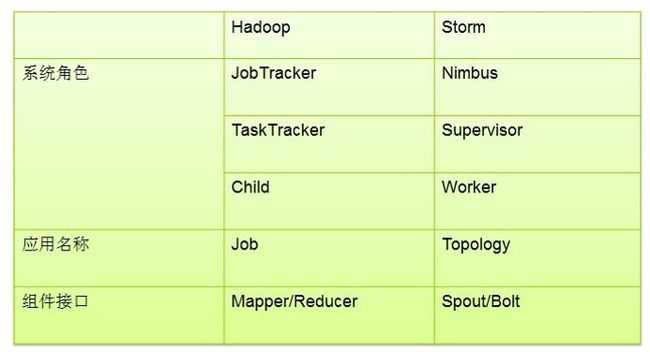
2.storm和hadoop的对比:
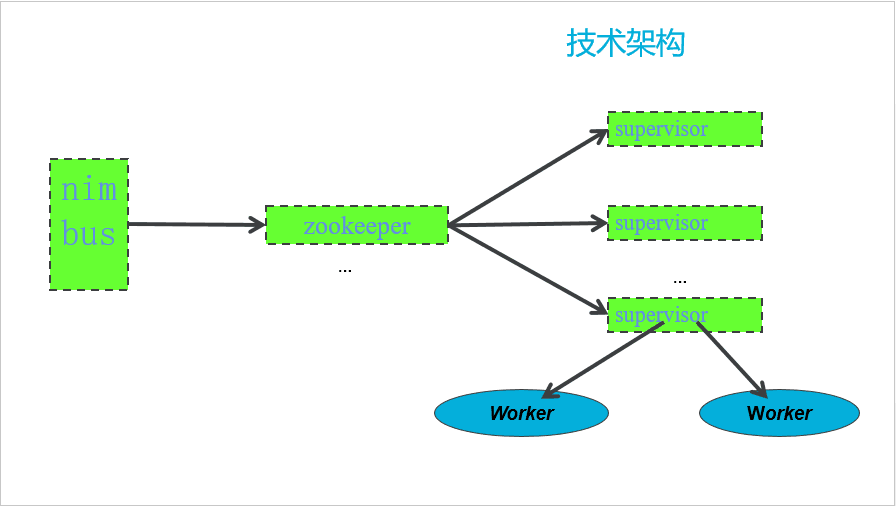
3.storm的工作流程:
客户端——提交topology——>nimbus——分配资源和任务调度——>zookeeper<——启动topology——supervisor——获取分配的tasks,启动任务——>worker——>task
4.worker,executor,task的关系:
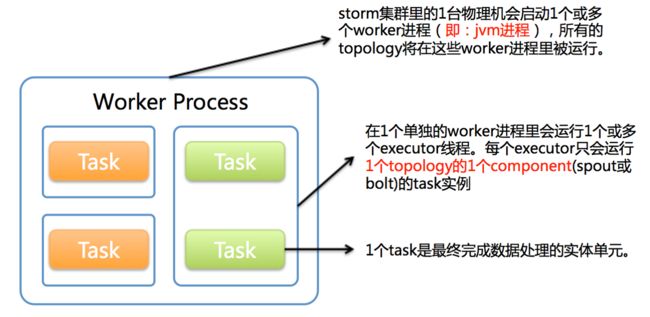
(1)一台机器起一个或多个worker进程,所有的topology在这些worker进程里运行;
(2)一个worker进程里会运行一个或多个executor线程,每个executor只会运行一个topology的一个component(spout或bolt)的task实例;
(3)一个task是最终完成数据处理的实体单元。
5.stream groupings:消息的分组方法。(6种)
(1)随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple;
(2)字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务;
(3)全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用;
(4)全局分组(Global grouping):全部流都分配到bolt的同一个任务。
(5) 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能);
(6) 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
常用随机分组和字段分组。
6.代码举例:
(1)spout:消息产生源, spout组件的实现可以通过继承BaseRichSpout类或者其他*Spout类来完成,也可以通过实现IRichSpout接口来实现。
public static class MySpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
//自己定义输入的数据
@Override
public void nextTuple() {
String[] sentences = new String[] { "the cow jumped over the moon", "an apple a day keeps the doctor away","four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
String[] strs = sentence.split(" ");
String str = strs[_rand.nextInt(strs.length)];
_collector.emit(new Values(str));
}
// 先初始化open方法
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
// 定义发送的字段(发送的域,即键值对的键)
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}· open()方法:
当一个task被初始化的时候会调用此open()方法。一般都会在此方法中对发送tuple的对象SpoutOutputCollector和配置对象TopologyContext初始化。(把要初始化的东西放这里)
_collector = collector;· declareOutputFields()方法:
用于声明当前spout的tuple发送流,stream流的定义是通过OutputFieldsDeclare.declareStream方法完成的,其中的参数包括了发送的域Fields。(在这里定义要发送的键值对的“键”)
declarer.declare(new Fields("word"));//定义键为:word· nextTuple()方法
这是spout类中最重要的一个方法。发射一个tuple到topology都是通过这个方法来实现的。(在这里发送tuple,发送定义好的“键”和“值”)
_collector.emit(new Values(“定义好的value对象”));//发送tuple· getComponentConfiguration()方法
此方法用于声明针对当前组件的特殊的Configuration配置。
public Map<String, Object> getComponentConfiguration() {
if(!_isDistributed) {
Map<String, Object> ret = new HashMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3);//这里便是设置了topology中当前Component的线程数量上限。
return ret;
} else {
return null;
}
}(2)bolt: 接收者,bolt类接收由Spout或者其他上游bolt类发来的tuple,对其进行处理。bolt组件的实现可以通过继承BasicRichBolt类或者IRichBolt接口来完成。
public static class MyBolt extends BaseRichBolt {
Map counts = new HashMap();
OutputCollector _collector;
@Override
public void execute(Tuple tuple) {
//从发送来的tuple中取出“键”:word(spout中定义好的)
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
_collector.emit(new Values(word, count));
}
//与spout中的open()类似
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
//用于声明当前bolt发送的tuple中包含的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
} · prepare()方法
此方法和spout中的open()方法类似,为bolt提供了OutputCollector,用来从bolt中发送tuple。bolt中tuple的发送可以在prepare方法中、execute方法中、cleanup等方法中进行,一般都是些在execute中。
_collector = collector;· declareOutputFields()方法
用于声明当前bolt发送的tuple中包含的字段,和spout中类似。
declarer.declare(new Fields("word", "count"));· execute()方法
对tuple的处理在这里进行,结果的发送通过emit()方法来完成。emit()方法有两种情况:
1)emit()中有一个参数:此参数为直接发送到下游bolt的tuple;
2)emit()中有两个参数:第一个参数为旧的tuple的输入流,第二个参数为发往下游bolt的新tuple流,即,如果下游的bolt处理tuple失败,则会向上传递到当前bolt,当前bolt根据旧的tuple流继续往上游传递,申请重发失败的tuple,保证tuple处理的可靠性。
这两种情况要根据自己的场景来确定。
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void execute(Tuple tuple) {
_collector.emit(new Values(tuple.getString(0) + "!!!"));
}· getComponentConfiguration()方法
和spout类一样,在bolt中也可以有getComponentConfiguration方法。
public Map<String, Object> getComponentConfiguration() {
Map<String, Object> conf = new HashMap<String, Object>();
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, emitFrequencyInSeconds);
return conf;
}此例定义了从系统组件“_system”的“_tick”流中发送tuple到当前bolt的频率,当系统需要每隔一段时间执行特定的处理时,就可以利用这个系统的组件的特性来完成。
(3)topology运行:
单词统计示例流程图:
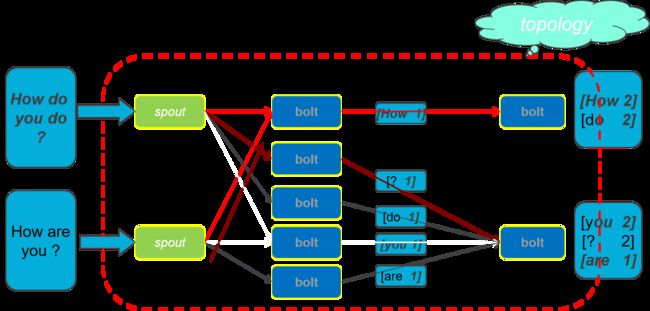
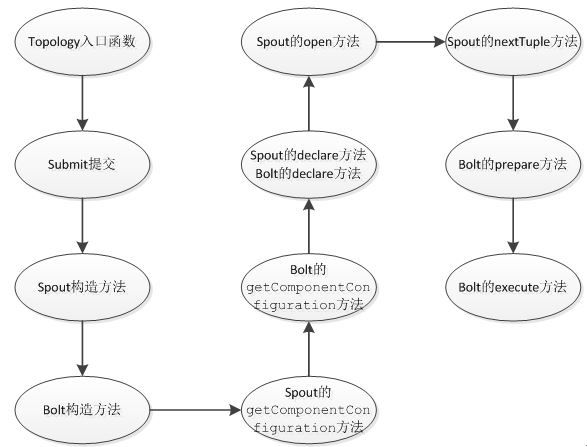
topology整个流程示例图:
main()方法:
public static void main(String[] args)
throws AlreadyAliveException, InvalidTopologyException, InterruptedException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MySpout(), 5);
builder.setBolt("bolt", new MyBolt(), 8).fieldsGrouping("spout", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}· 在setSpout()方法和setBolt()方法中:
1)第一个参数是当前的Component组件的stream流ID号;
2)第二个参数是具体的Component实现类的构造;
3)第三个参数是当前Component的并行执行的线程数目,storm会根据这个数字的累加和来确定topology的task数目,即executor的设置;
4)最后的小尾巴*Grouping是指的一个stream应如何分配数据给bolt上面的task。
· topology的运行方式:
1)本地运行
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();2)集群运行
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());