【包】dpdk、ettercap、netmap、netsniff-ng
(1)测试openstack架构下,相同租户不同子网之间的通信:数据包需要经过路由器,br-int作为二层网桥,没有学习功能。
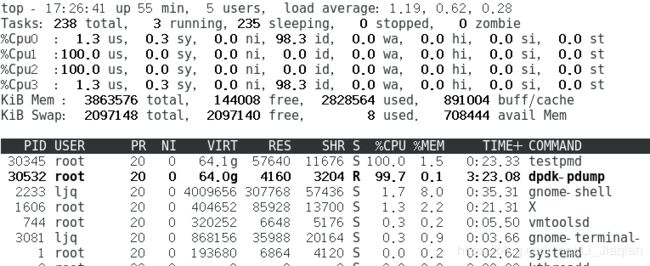
(2)测试使用dpdk的抓包工具dpdk-pdump,分析dpdk的优化方式以及cpu占用率高的原因。
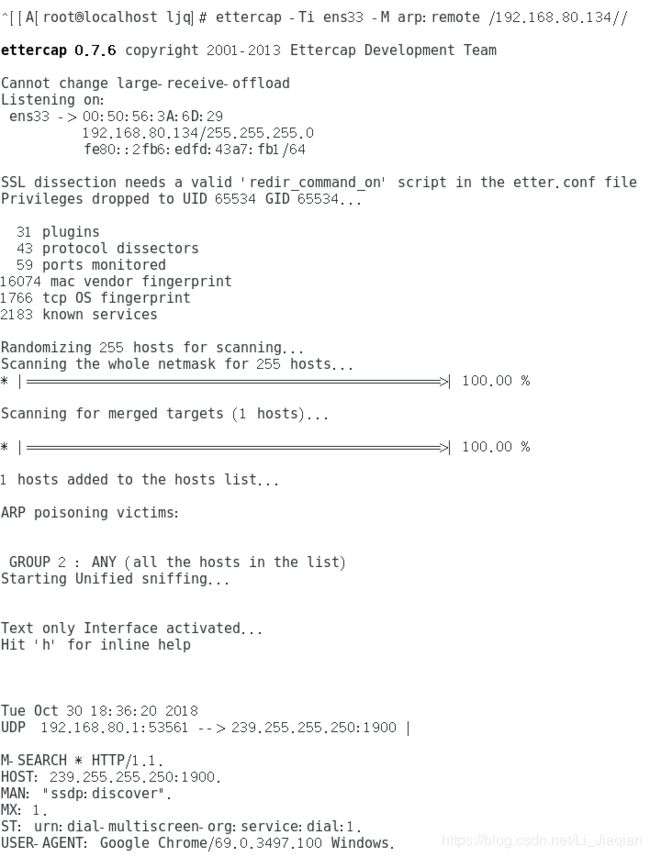
(3)安装使用网络抓包工具ettercap。
(4)配置使用netmap网络架构,与tcpdmup对比抓包效率。
(5)配置使用netsniff-ng工具,与tcpdump对比抓包效率。
一.openstack相同租户、不同子网的通信
1.openstack-vswitch有“normal”和“flow”两种模式,normal是普通的linux桥(例如br-int),flow模式的bridge根据流表(flow table)来进行转发(例如br-tun)。br-int是二层网桥,不具有学习功能,最终利用actions=NORMAL处理。数据包从虚拟机发出,进入br-int,若目标虚拟机与源虚拟机的vlan tag相同,则数据包不会再进入br-tun,由br-int直接转发;否则,br-int给该数据包添加上vlan tag,进入br-tun,br-tun再将vlan tag转化为tunnel id,进入vxlan通道,判断是通向另一个虚拟节点或是通向网络节点。

2. 尝试添加流表项,仍然需要经过网络节点的路由器。
3.可以总结,除了以下两种情况数据包不进入网络节点,其余情况均属于跨子网的数据流向,需要进入网络节点处理:
(1)相同租户,相同主机,相同子网,由主机的br-int直接处理;
(2)相同租户,不同主机,相同子网,数据包经由两主机之间的通道传输,不进入网络节点。
二.dpdk
1.抓包函数:dpdk-pdump,dpdk-pdump作为dpdk的次级进程运行,能够启用或禁用dpdk端口上的数据包捕获功能,dpdk-pdump只能与数据包捕获框架已经初始化的应用程序配合使用,初始化的数据包捕获框架的应用程序(testpmd)作为服务器,具有数据包捕获功能的应用程序(dpdk-pdump)作为客户端,服务器将收发的数据包从dpdk端口发送到客户端。即,使用pdump必须先运行testpmd作为主要应用程序。
./testpmd -c 0x3 -n 4 -- -i
./dpdk-pdump -- --pdump “port=0,queue=*,rx-dev=/tmp/rx.pcap,tx-dev=/tmp/tx.pcap”
只有testpmd输入start后,dpdk-pdump才可以抓到包,rx.pcap和tx.pcap中才会有数据写入。使用tcpdump -r命令,读取rx.pcap和tx.pcap中的数据:

2.cpu占用率:
dpdk采用轮询,而不是中断机制,因此cpu占用经常为100%。于是有文章提出了基于状态的混合轮询机制。若某段时间处于平稳的高流量状态,则选择轮询模式,禁止中断,避免陷入中断频繁相应环节。若某段时间网络数据流量很低或没有数据传输,轮询方式就会出现高速端口下低负荷运行,加重cpu的负载。因此可以使用混合中断轮询驱动进行传输控制。高负载情况下使用轮询,保证数据不丢包,低负载情况下使用中断,保证cpu的其他工作。

可以看出主要是lcore-slave-1在占用cpu: dpdk采用多核编程代替多线程模型,环境初始化函数(dpdk-18.08\lib\librte_eal\linuxapp\eal.c)rte_eal_init()的最后有遍历系统中所有cpu的代码:
- RTE_LCORE_FOREACH_SLAVE(i),创建两个pipe,通知开始执行线程,为每个核创建一个线程。
- 线程回调函数:eal_thread_loop,修改线程名称(lcore-slave-i——testpmd中占用cpu最多的线程),得到当前线程id,将该线程绑定在cpu上,等待通过pipe发过来的执行指令,如果执行完成,则开始下一次等待。从pipe读到命令,写入pipe确认,执行线程工作函数。
- 所谓多核编程就是每个核上有一个线程,平时该线程处于等待(sleep)状态,如果有通过pipe发送信号,则开始执行这个核上的函数,通过rte_eal_mp_remote_launch给线程发送命令并执行。
- rte_eal_mp_remote_launch:如果当前核上的线程不是wait状态,则说明正在执行其他任务,则退出,如果是wait状态,则将信号发送给核。
- rte_eal_remote_launch:保存在这个核上需要执行的函数以及参数,开始发送命令、执行任务,等待回复。
3.以helloworld为例:首先调用rte_eal_init初始化参数,rte_eal_cpu_init设置每个线程lcore_config的相关分析,其中CPU_ZERO以及CPU_SET是设置相关cpu亲和性的接口,使得线程或进程在某个给定的cpu上尽量长时间地运行而不被迁移到其他处理器,迁移频率小,产生的负载小,提高了cpu缓存的命中率,减少内存访问的损耗,提高程序运行的速度,每个核可以专注地处理一件事情,资源被充分使用,减少了同步的损耗。
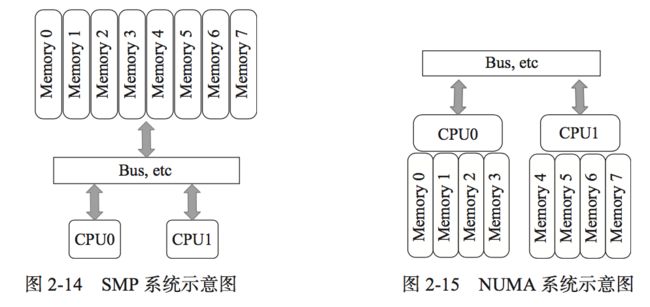
4.dpdk的优化:(1)likely以及unlikely的使用,分支预测,指令跳转;(2)指令预取,硬件预取(底层硬件预取单元根据一定条件自动激活预取,如果访问的数据结构没有规律,那么硬件预取将会占用更多的带宽,不一定提高程序运行效率)、软件预取(PREFETCH0-PREFETCH2,PREFETCHNTA,把即将用到的数据从内存中加载到缓存中,后期直接命中缓存,减小了从内存直接读取的 延迟,减小了cpu的等待时间,rte_prefetch_non_temporal与PREFETCH0对应,将数据存放在一级缓存中,使用完一次可以被淘汰)(3)缓存相关:定义一个变量是,要与cache line对齐,防止变量所占空间跨line,则可能需要多次内存加载核存储,dpdk避免多个核访问同一个内存地址或者数据结构,可以避免与其他核共享数据,减少因错误的数据共享而导致的cache一致性的开销。(4)本地内存:SMP(对称多处理系统):所有cpu共享全部资源,所有cpu平等,没有主从关系,内存是统一寻址的(UMA),cpu和内存,cpu之间是通过一条总线连接起来的。但是:扩展能力有限,随着cpu数目的增加,系统总线成为瓶颈,cpu与内存之间的通信延迟加大。于是出现了NUMA(非一致性存储器访问):cpu和内存拥有更小的延迟与更大的带宽,整个cpu可以作为一个整体,任何cpu都可以访问,跨本地内存访问比本地内存访问慢一些,每个cpu都可以有本地总线。(在rte_pktmbuf_pool_create:根据该线程所在的socket_id去创建线程,在rte_eth_rx_queue_setup以及rte_eth_tx_queue_setup:根据socket_id取创建端口的收发队列,在rte_ring_create:根据socket_id去创建无锁环形buffer)。
5.cpu亲和性:进程要在指定的cpu上尽量长时间地运行而不被迁移到其他处理器,通过处理器关联可以将虚拟处理器映射到一个或多个物理处理器上,即把一个程序绑定到一个物理cpu上。在越来越多核心的cpu上,让各个cpu核心各自干专门的事情,从而提高工作效率。通过配置linux的内核参数,使dpdk占用的cpu不参与调度,使dpdk应用独占cpu。
Step1:设置isolcpus,使在机器启动时,线程默认不占用该cpu;
- /etc/default/grub,在GRUB_CMDLINE_LINUX_DEFAULT变量中添加isolcpus=(cpu核)
- grub2-mkconfig -o /boot/grub2/grub.cfg(centos中使上述生效)
- 重启
- 下图使cpu1和cpu2不被其他进程调用

Step2:通过单独设置线程的cpu亲和性可以指定线程占用cpu。
- 将dpdk-pdump线程规定运行在cpu2上


- 运行testpmd,使之运行在cpu1上
6.进程之间的master和slave线程互发字符串,使用simple_mp作为primary以及secondary通信:


三.Ettercap
1.Ettercap是一种网络抓包软件,Ettercap有两种运行方式,UNIFIED:以中间人方式嗅探,同时嗅探A和B,数据在A和B之间传输会经过C,C可以分析数据。BRIDGED在双网卡情况下,嗅探网卡之间的数据包。
2.Ettercap的工作方式有五种,IPBASED,根据源IP-port和目的IP-port捕获数据包;MACBASED,根据源MAC和目的MAC捕获数据包;ARPBASED,基于ARP欺骗,利用Arp欺骗在交换局域网内监听两个主机之间的通信(全双工);SMARTARP,利用ARP欺骗,监听交换网上某主机与其余已知主机(主机表)的通信(全双工);PUBLICARP,监听交换网上某主机与其余已知主机的通信(半双工)。
3.Ettercap -G:图形界面
(1)扫描,获取主机列表:

(2)将探测到的主机加入目标主机列表,可以探测到目标主机的连接状况:

(3)扫描到的数据各参数:

4.命令行:-T 控制台模式下,-i指定端口,-M中间人形式,arp双向欺骗
四.Netmap
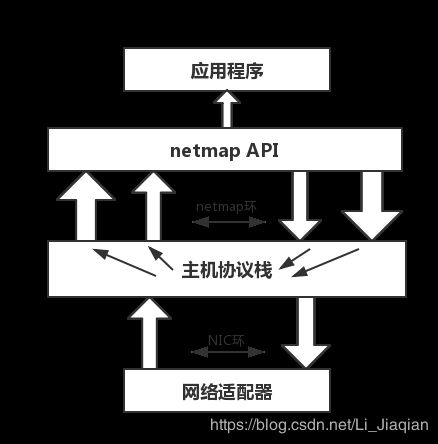
1.Netmap是一个基于零拷贝思想的高速网络I/O架构,能够在千兆或万兆网卡上高速收发包,同时有效节省cpu等资源,网卡通过循环队列(NIC环)管理数据包的传输,每个网卡至少维护一对NIC环,分别用来管理发送和接受两个方向的数据包。网卡管理的是内核的内存空间,零拷贝通过DBA(直接缓存访问)技术,使应用程序直接跑在内核态,或者是将内核中的数据包缓存区直接暴露给用户。
2.网卡运行在netmap模式下,NIC环会与主机协议栈断开,netmap拷贝一份NIC环(netrmap环),同时netmap维护另一对环,用来与主机协议栈交互,这些环所指向的用于存储数据包内容的缓存位于共享空间,网卡直接将数据包存入这些缓存,应用程序可以通过调用netmap API访问netmap环中的数据包。同时由于有netmap环这个介质,netmap不会将网卡寄存器和内核的关键内存区域暴露给应用程序,因此用户态的用户程序不会导致os崩溃,所以相对于其他的一些零拷贝架构,netmap更加安全。
3.有论文测试libpcap和netmap下的libpcap的抓包性能,基于netmap的libpcap的性能更优,但是实验对比,netmap和tcpdump抓包率都很理想,netmap的cpu占用率更高。
五.Netsniff-ng
Netsniff-ng是一个使用零拷贝机制的linux网络工具包。抓包率、占用cpu、内存均比tcpdump高。


