并发算法是多核时代开始流行的技术趋势,比如tbb,ppl都提供了大量有用的并发算法。
经典算法中,排序是一个很适合采用分治法并发的场合,比如快速排序。
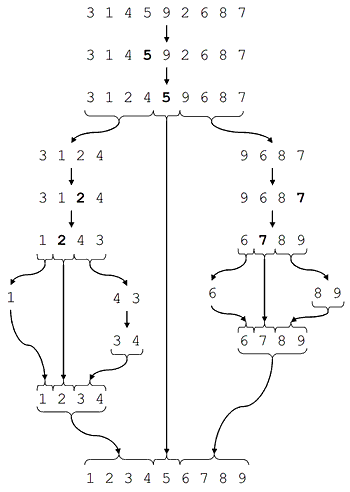
常规的快速排序,先在数组中选取一个基准点,将数组分区为小于基准点和大于基准点(相同的数可以到任一边),对分区的子数组递归的执行分区的操作,当子数组长度为1时退出递归。此时数组就完成了排序过程。
int partition(int* array, int left, int right)
{
int index = left;
int pivot = array[index];
swap(array[index], array[right]);
for (int i=left; i pivot) // 降序
swap(array[index++], array[i]);
}
swap(array[right], array[index]);
return index;
}
void qsort(int* array, int left, int right)
{
if (left >= right)
return;
int index = partition(array, left, right);
qsort(array, left, index - 1);
qsort(array, index + 1, right);
}
对快排的过程分析可以发现,分区以及对子数组排序的过程均可以并发执行,这里首先对数组进行分区,生成分区数组,为了保证不同分区不受到影响需要先完成分区再进行排序。
template void parallel_sort(container & _container)template
void partition_less(std::vector * vless, container * _container, key privot){
for(size_t i = 0; i < (*_container).size(); i++){
if ((*_container)[i] < privot){
vless->push_back((*_container)[i]);
}
}
}
template
void partition_more(std::vector * vmore, container * _container, key privot){
for(size_t i = 0; i < (*_container).size(); i++){
if ((*_container)[i] >= privot){
vmore->push_back((*_container)[i]);
}
}
}
在完成分区之后,递归执行排序操作,并将排序好的分区重新写入待排序数组。
template
int sort_less(container * _container, std::vector & vless, boost::atomic_uint32_t * depth){
parallel_sort_impl(&vless, *depth);
for(size_t i = 0; i < vless.size(); i++){
(*_container)[i] = vless[i];
}
return 0;
}
template
int sort_more(container * _container, std::vector & vmore, boost::atomic_uint32_t * depth){
parallel_sort_impl(&vmore, *depth);
size_t pos = (*_container).size()-vmore.size();
for(size_t i = 0; i < vmore.size(); i++){
(*_container)[i+pos] = vmore[i];
}
return 0;
}
template
void parallel_sort_impl(container * _container, boost::atomic_uint32_t & depth){
if (_container->size() < threshold || depth.load() > processors_count()){
std::sort(_container->begin(), _container->end());
}else{
key privot = (*_container)[_container->size()/2];
std::vector vless, vmore;
auto partition_result = std::async(std::launch::async, partition_less, &vless, _container, privot);
partition_more(&vmore, _container, privot);
partition_result.get();
auto result = std::async(std::launch::async, sort_less, _container, vless, &depth);
sort_more(_container, vmore, &depth);
result.get();
}
}
by 浅水清流 via ifeve.com