NOIP2017模拟赛(3) 总结
前言:最近这段时间太颓,没有及时写总结,赶紧补过。。。
a 自动机
题目描述
有一个程序自动机,可以运行一个程序S次。 第一次运行时,给你一个字符串input作为输入, 之后的每次运行的输入数据就是前一次运行之后的输出。Input都是小写字母. 这里说的程序只包含小写字母和字符’$’. 每次运行程序后的输出是把输入的字符串替换程序的字符’$’ ,因此输出的也是字符串。例如:如果第一输入的字符串是 “a” ,而我们的程序是 “$meric$”, 那么第一运行后输出是:”america”. 第二次运行时,把 “america” 作为输入, 输出将是:”americamericamerica”, 就这样运行S次, 所以S很大的话,输出将是:
“americamericamericamericamericamericamericamericamericamericamericamericamericamericamerica….”。
现在给出第一次输入的字符串input, 给你程序program 和要运行的次数S, 那么运行S次后, 输出将会非常的长,我们只需要你输出的第min个字符到第max个字符 (下标从1开始). 如果超出了最后输出的总长度的部分, 那么用’-‘代替那部分.
输入格式
多组测试数据。
第一行:一个整数ng,表示有ng组测试数据。
每组测试数据格式如下:
第一行:三个整数: S、min、max。 1 <= S, min <= 1000000000,
min <= max <= min+99.
第二行: 字符串input
第三行: 字符串program. 其中input和program都是小写字母或’$’, 长度不超过50。注意:program的第一字符肯定是’$’。
输出格式
一个字符串,运行S次后,程序机最后输出的第min个字符到第max个字符。
ng行,每行对应一组测试数据。
输入样例
2
6 1 35
a
$meric$
1 1 20
top
$coder
输出样例
americamericamericamericamericameri
topcoder————
解题思路(模拟+递归)
这题值得我好好总结一番。
首先这是一题比较麻烦的模拟。考试时我死活没想到怎么做,想到了一点关于递归方面的东西但是却不会怎么完善所有细节。于是我写了一个没分的暴力。我实在太菜了。。知道考完试后我也迟迟没有将这题该出来,直到最近才终于改完。
由于操作次数S很大,故不能直接做那么多次。这题的突破口就在于pro中第一个字符保证是‘$’。这有什么用呢?我们想想,如果第一个是‘$’,而且Max不超过1e9 + 99,那么一旦有一个以上个‘$’,字符串的长度就在以至少倍增级别的速度增长,操作三十次就一定能达到Max长度了,而第一个字符又是‘$’,则第三十次变换中我们最前面的‘$’里面的第几个字符是什么是确定的。就是说往后再做到S次(即使是1e9次),前面的那部分的确定了位置的字串一定满足题目要求的长度,答案一定在里面。
然后我们就只需要做三十次就行了嘛。我们不能直接模拟地操作30次(空间爆炸),但可以预先算出每次操作后的字符串的长度 f[t] ,而且我们还知道第 t 次操作的’$’中的串的长度就是上一轮的串的长度即 f[t−1] ,注意做30次后长度可能超过int,所以如果长度超过Max就没用了,直接让其为Max+1就行了。(一开始我就在这里被坑了)。算完 f 后就从高层向底层dfs找我们要查的那段区间就行了。这里我们可以直接拿区间去找,但这样万分麻烦。在教练的点醒后,我终于发现Min与Max的差很小,可以for然后每次找一个,这样递归时就容易判断很多了,递归时答案可能在pro中,也可能在in中。
ps:注意边界条件。
上面的简洁巧妙的作法只解决了一部分问题,还有就是只有一个‘$’的情况没有处理,这个非常简单。只需要模拟,类似于找循环节。
输出‘-’的情况就是如果要找的位置比操作S后生成的字符串的长度还后的情况。
然后这题总结来说就是一个很有技巧的递归和一个较难写的模拟(虽然代码很短),下次做题时一定要理智分析,找到转化问题的路径,并发现题目中的突破点(这题是第一个一定是’$’),然后要多写一些细节多、难实现的程序才能不再出现连签到题都爆零的情况。
代码
#include b 基因测试
题目描述
现代的生物基因测试已经很流行了。现在要测试色盲的基因组。有N个色盲的人和N个非色盲的人参与测试。
基因组包含M位基因,编号1至M。每一位基因都可以用一个字符来表示,这个字符是‘A’、’C’、’G’、’T’四个字符之一。
例如: N = 3, M = 8。
色盲者1的8位基因组是: AATCCCAT
色盲者2的8位基因组是: ACTTGCAA
色盲者3的8位基因组是: GGTCGCAA
正常者1的8位基因组是: ACTCCCAG
正常者2的8位基因组是: ACTCGCAT
正常者3的8位基因组是: ACTTCCAT
通过认真观察研究,生物学家发现,有时候可能通过特定的连续几位基因,就能区分开是正常者还是色盲者。
例如上面的例子,不需要8位基因,只需要看其中连续的4位基因就可以判定是正常者还是色盲者,这4位基因编号分别是:
(第2、3、4、5)。也就是说,只需要看第2,3,4,5这四位连续的基因,就能判定该人是正常者还是色盲者。
比如:第2,3,4,5这四位基因如果是GTCG,那么该人一定是色盲者。
生物学家希望用最少的连续若干位基因就可以区别出正常者和色盲者,输出满足要求的连续基因的最少位数。
输入格式
第一行,两个整数: N和M。 1 <= N <= 500, 3 <= M <= 500。
接下来有N行,每一行是一个长度为M的字符串,第i行表示第i位色盲者的基因组。
接下来又有N行,每一行是一个长度为M的字符串,第i行表示第i位正常者的基因组。
输出格式
一个整数。
输入样例
3 8
AATCCCAT
ACTTGCAA
GGTCGCAA
ACTCCCAG
ACTCGCAT
ACTTCCAT
输出样例
4
解题思路(二分套二分+哈希)
这题是本次比赛三题中最简单的一题。首先要看懂题意,然后我们直接二分答案+字符串哈希就可以轻松解决。(并不轻松,这是我第一次写字符串哈希,以前也没有学过,yy了好久,还好1A了。。)
那我们二分答案后判断就用hash值。这里一开始我想用map或treap,最后干脆写了个sort+二分查找(反正都不超时啊)。细节什么的都在于字符串hash是否熟练,我就调了挺久。然后其他大神有些直接一个二分套hash就行了(完美作法),还有的发现了显然的单调性并直接尺取代替二分,更有人用AC自动机去匹配进而判断(不用写简单的hash)。
这题就到这里了。ps:hash可能冲突,但是我们用双hash即用选两个键值作为mod数就能有效地避免(almost)出现此情况。
代码
#include c 新建道路
题目描述
有n个结点,编号1至n,一开始没有边。现在总共要新建m条边,构成一个图。每一条新建的边都是无向边。但是要满足如下的条件:
1、选择两个不同编号的结点X和Y,在X和Y之间建立一条边,前提是两个结点的编号的差不超过给定的参数k,即 0 < ABS(X-Y) <= k。注意:允许在A和B之间建立多条边(即两个结点之间可以有重边)。
2、当最终建完m条边之后,对于任意的一个结点i,与结点i相连的边共有偶数条。注意:0也被认为是偶数。
问题是:总共可以构造出多少种不同的图?答案模1000000007。构出来的图可以是不连通的图,如果构出来的图的边有交叉,这些交叉边理解为互不干扰。
输入格式
一行,三个整数:n,m,k。 1 <= n <= 30, 0 <= m <= 30, 1 <= k <= 8。
输出格式
一个整数。
输入、输出样例
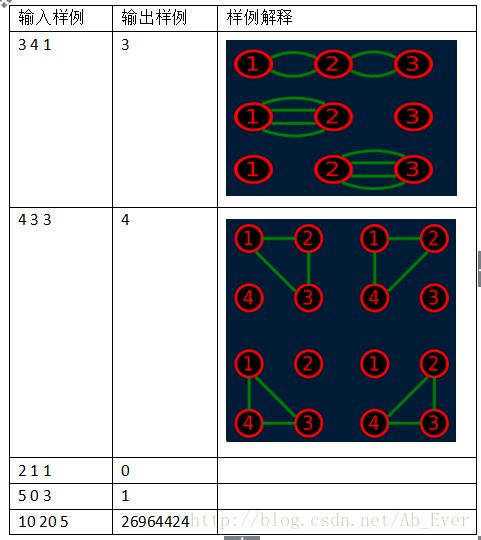
解题思路(集合动态规划)
这题一看K那么小就让我想到状压dp。然后在考场上我就开始yy。
我们肯定要记的状态是包括当前点i在内的与后面K个点的奇偶性(偶数记为0,奇数记为1),然后我就想了很久,不知道该记什么其他的东西。我知道肯定要记前i个点,连了j条边,然后记那K+1个点的状态。然后我就不会转移了,想到要枚举连边什么的(这是最大的错误),时间又承受不了,细节又多,考试时间又快结束了,所以我就放弃了此题。
后来想想,其实这题的dp模型很明显,几乎人人都知道,实现起来也很简单(有两个人当场A了此题),只是有些难想,考试时不能冷静快速分析,对时间的把握也不够恰当。
后来重做这题,听了讲评,发现我们只记这三维是不够的,还需要再记多一个才更好。而且,最关键的一点是,转移要想着一位一位的来,不要一次转移很多。这正是dp的优美之处,一位位来,但包含了所有有用的状态,节省了空间,又简洁,但关键就是很难想。我们考虑再记一个小k,代表在连j条边下,当前i连完的的最后一个点的后一个(或者说k之前的点我都与i连好了)。那么我们为什么要这么记呢?这样支持一位一位的转移,而且处理好细节,不重不漏,代码也很简短。
我们令 f[i][j][k][s] 为当前做到第 i 个点,由此向后面连边(连前面就重了),已经连完了 j 条边,且现在可以连的最左边的点是从 i 开始数的第 k 个,包括 i 在内向后的 K+1 (注意这里是大 K ,至于为什么可以想想,如果写成 k 会怎样呢,跟转移有关)个点的奇偶性状态。很清楚了,怎样转移呢?
①如果第 k+1 个也可以连边,我们可以考虑不理 k 了,直接让最左边的可连点右移。此时奇偶性状态不变。就是
②如果不满足①,即当前 k 不能再右移了, i 已经连完所有边了,而且 i 的那一位状态为0(偶数),我们就将 i 扔掉,状态跑去 i+1 , s 右移, k 重置为1。
为什么一定要等 k 不能向右的时候才能将 i 右移呢,这里也是个细节,如果不这样做的话会算重!!我们想想,这样会导致一样的状态重复贡献,可以想像以下,一个状态通过不同“场合”贡献到另外状态上去(每次决策都重复转移了),这较难讲清楚,总之,要注意这种情况。
③前面两种都没连边,这里就该连了吧。没错!如果连边不出界,就连,注意每次只连一条边,但 i,k 都没变,还是能连多条,所以通过分解,将转移次数”变多”,就反而更好实现,反而省时间。状态中 i 与 i+k 的奇偶性变了。
f[i][j+1][k][s ^ 1 ^ (1<<k)]+=f[i][j][k][s];
一开时状态就不用说了,最后输出的是 f[n−1][m][1][0] 。(其实并不一定要是这个)。复杂度 O(N2∗K∗2K) .
总结的话,就是求方案数的题首先想到dp,然后理智yy一发后(思维很关键),想好子问题,状态怎么记才不少且科学,决策有几种,然后别忘了mod。说是这样说,希望以后的dp题我能尽可能做出来~~。。
代码(才35行)
#include 1][k][s^1^(1<printf("%d\n", f[n-1][m][1][0]);
return 0;
} 总结
这次的比赛考得十分失败,要吸取教训,锻炼思维,同时希望能花更多的时间投入到其中去,提高效率很关键。

此刻的你是不是正流露出孤独
不知为何 我不由得牵挂于心