MySQL学习第二天
以下基础知识为转载:
1 高级查询
1.1 排序
通过order by语句,可以将查询出的结果进行排序。放置在select语句的最后。
格式:
SELECT * FROM 表名 ORDER BY 排序字段ASC|DESC;
ASC 升序 (默认)
DESC 降序
1.2 聚合
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,他是对查询后的结果的列进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
count;sum;avg;max;min;
1.3 分组
分组查询是指使用group by字句对查询信息进行分组。
格式:
SELECT 字段1,字段2… FROM 表名GROUP BY分组字段 HAVING 分组条件;
分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
having与where的区别:
having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
having后面可以使用统计函数过滤数据
where后面不可以使用统计函数。
1.4 分页
分页查询在项目开发中常见,由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式。例如数据共有30条,每页显示5条,第一页显示1-5条,第二页显示6-10条。
格式:
SELECT 字段1,字段2… FROM 表明 LIMIT M,N
M: 整数,表示从第几条索引开始,计算方式 (当前页-1)*每页显示条数
N: 整数,表示查询多少条数据
SELECT 字段1,字段2… FROM 表名 LIMIT 3,5
SELECT 字段1,字段2… FROM 表名 LIMIT 5,5
2 SQL约束
2.1 主键约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录,每条记录中被主键约束 约束的字段不能相同。
主键必须是唯一的值。
主键列不能是 NULL 值。
每个表都应该有且只能有一个主键。
2.1.1 添加主键约束
方式一:创建表时,在字段描述处,声明指定字段为主键:
方式二:创建表时,在constraint约束区域,声明指定字段为主键:
格式:[constraint 名称] primary key (字段列表)
关键字constraint可以省略,如果需要为主键命名,constraint不能省略,主键名称一般没用。
字段列表需要使用小括号括住,如果有多字段需要使用逗号分隔。声明两个以上字段为主键,我们称为联合主键。
方式三:创建表之后,通过修改表结构,声明指定字段为主键:
ALTER TABLE Persons ADD [CONSTRAINT 名称] PRIMARY KEY (字段列表)
2.2 自动增长列
我们通常希望在每次插入新记录时,数据库自动生成字段的值。
我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整形,自动增长列必须为键(一般是主键)。
2.3 非空约束NOT NULL
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
2.4 唯一约束
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
2.5 默认值约束
在添加数据中,如果该字段不指定值,采用默认值处理
3 内连接外连接
用在多表查询时。
- 内连接查询(使用的关键字 inner join – inner可以省略)
隐式内连接:select * from A,B where 条件;
显示内连接:select * from A inner join B on 条件; - 外连接查询(使用的关键字 outer join – outer可以省略)
左外连接:left outer join
select * from A left outer join B on 条件;
右外连接:right outer join
select * from A right outer join B on 条件;
4 子查询
子查询:一条select语句结果作为另一条select语法一部分(查询条件,查询结果,表等)。
select …查询字段 … from …表… where … 查询条件
**
接下来是一个例子:
**
**
①创建两个表:
dept: 部门表
deptno(primary key), dname, loc
emp: 员工表
empno(primary key), ename, job, mgr(references emp(empno)), sal,
deptno(references dept(deptno))
说明:
员工表有2个外键,一个是deptno字段,关联到部门表的deptno,
一个是mgr,即所属管理者,关联到自己表的eompno字段**
create table dept(
deptno varchar(20) primary key,
dname varchar(20),
loc varchar(20)
);
create table emp(
empno varchar(20) primary key ,
ename varchar(20),
job varchar(20),
mgr varchar(20),
sal float,
deptno varchar(20)
);
②向表里面插入数据:
INSERT INTO dept (deptno, dname, loc) VALUES (‘1001’, ‘研发部’, NULL);
INSERT INTO dept (deptno, dname, loc) VALUES (‘1002’, ‘市场部’, NULL);
INSERT INTO dept (deptno, dname, loc) VALUES (‘1003’, ‘人事部’, NULL);
INSERT INTO dept (deptno, dname, loc) VALUES (‘1004’, ‘秘书部’, NULL);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘1’, ‘螺纹’, ‘软件设计师&&部门经理’, ‘1’, 12000, ‘1001’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘10’, ‘大飞机’, ‘check’, ‘4’, 4000, ‘1002’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘11’, ‘王秘书’, ‘总经理秘书’, NULL, 4000, ‘1004’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘2’, ‘张三’, ‘Java工程师’, ‘1’, 8000, ‘1001’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘3’, ‘李丑’, ‘check’, ‘1’, 5000, ‘1001’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘4’, ‘金勾’, ‘市场部经理’, ‘4’, 7000, ‘1002’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘5’, ‘韬二’, ‘销售’, ‘4’, 6000, ‘1002’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘6’, ‘帅李’, ‘check’, ‘1’, 5500, ‘1001’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘7’, ‘李蟀’, ‘check’, ‘4’, 3000, ‘1002’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘8’, ‘刘一’, ‘Java工程师’, ‘1’, 7500, ‘1001’);
INSERT INTO emp (empno, ename, job, mgr, sal, deptno) VALUES (‘9’, ‘李斯’, ‘check’, ‘4’, 6000, ‘1004’);
③接来是查询语句
#列出‘张三’所在部门的每个员工的姓名与员工号
SELECT
ename AS 姓名,
deptno AS 部门号
FROM
emp
WHERE
deptno = (
SELECT
deptno
FROM
emp
WHERE
ename = ‘螺纹’
);

#列出每个员工的姓名,工作,部门号,部门名
SELECT
e.ename AS 姓名,
e.job AS 工作,
e.deptno AS 部门号,
d.dname AS 部门名
FROM
emp e
INNER JOIN dept d
WHERE
e.deptno = d.deptno;
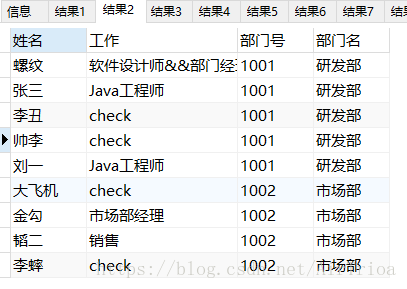
#列出emp中工作为‘check’的员工的姓名,工作,部门号,部门名
SELECT
e.ename AS 姓名,
e.job AS 工作,
e.deptno AS 部门号,
d.dname AS 部门名
FROM
emp e
INNER JOIN dept d
WHERE
e.deptno = d.deptno
AND e.job = ‘check’;

#对于emp中有管理者的员工,列出姓名,管理者姓名(管理者外键为mgr)
SELECT
FIRST .ename AS 姓名,
SECOND .ename AS 管理者姓名
FROM
emp FIRST
INNER JOIN emp SECOND
WHERE
FIRST .mgr = SECOND .empno;

#对于dept表,列出所有部门名,部门号,同时列出各部门工作为“check”的员工名和工作
SELECT
dname AS 部门名,
dept.deptno AS 部门号,
ename AS 员工名,
job AS 工作
FROM
dept,
emp
WHERE
dept.deptno = emp.deptno
AND job = ‘check’;

#11.对于工资高于本部门平均水平的员工,列出部门号,姓名,工资,按部门号排序
SELECT
FIRST .deptno AS 部门号,
FIRST .ename AS 姓名,
FIRST .sal AS 工资
FROM
emp FIRST
WHERE
FIRST .sal > (
SELECT
avg(sal)
FROM
emp SECOND
WHERE
FIRST .deptno = SECOND .deptno
)
ORDER BY
FIRST .deptno;

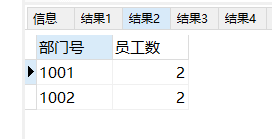
#12.对于emp,列出各个部门中平均工资高于本部门平均水平的员工数和部门号,按部门号排序
SELECT
TABLE_times.部门号 AS 部门号,
COUNT(TABLE_times.姓名) AS 员工数
FROM
(
SELECT
FIRST .deptno AS 部门号,
FIRST .ename AS 姓名,
FIRST .sal AS 工资
FROM
emp FIRST
WHERE
FIRST .sal > (
SELECT
avg(sal)
FROM
emp SECOND
WHERE
FIRST .deptno = SECOND .deptno
)
) TABLE_times
GROUP BY
TABLE_times.部门号
ORDER BY
TABLE_times.部门号;
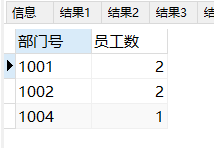
#13.对于emp中工资高于本部门平均水平,人数多于一人的,列出部门号,人数,按部门号排序
SELECT
t.部门号 AS 部门号,
t.员工数 AS 员工数
FROM
(
SELECT
TABLE_times.部门号 AS 部门号,
COUNT(TABLE_times.姓名) AS 员工数
FROM
(
SELECT
FIRST .deptno AS 部门号,
FIRST .ename AS 姓名,
FIRST .sal AS 工资
FROM
emp FIRST
WHERE
FIRST .sal > (
SELECT
avg(sal)
FROM
emp SECOND
WHERE
FIRST .deptno = SECOND .deptno
)
) TABLE_times #临时表命名
GROUP BY
TABLE_times.部门号
) t #临时表命名
WHERE
t.员工数 > 1
ORDER BY
t.部门号;
#14对于emp低于自己工资至少5人的员工,列出其部门号,姓名,工资和工资少于自己的人数
SELECT
FIRST .deptno AS 部门号,
FIRST .ename AS 员工名,
(
SELECT
COUNT(SECOND .sal)
FROM
emp SECOND
WHERE
FIRST .sal > SECOND .sal
) AS 人数
FROM
emp FIRST
WHERE
(
SELECT
COUNT(SECOND .sal)
FROM
emp SECOND
WHERE
FIRST .sal > SECOND .sal
) > 5;

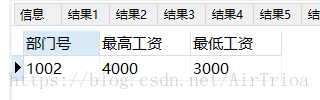
#3对于emp中最低工资小于5000的部门,列出job为‘check’的员工的部门号,最低工资,最高工资
SELECT DISTINCT
deptno AS 部门号,
max(sal) AS 最高工资,
min(sal) AS 最低工资
FROM
emp
WHERE
deptno IN (
SELECT
deptno
FROM
(
SELECT
MIN(sal) AS ms,
deptno
FROM
emp
GROUP BY
deptno
HAVING
ms < 4000
) a
)
AND job = ‘check’;