MySql数据库
数据库 简析
SQL语句分类
数据库定义语言DDL:
DDL(Data Definition Language),用来定义数据库对象:数据库,表,列。关键字:create, alter, drop 等DDL数据定义语言 主要定义结构的
(创建(create)一个结构, 修改(alter)一个结构, 删除(drop 摧毁)一个结构)
数据操作语言DML:
简称DML(Data MAnipulation Language), 用来对数据库中表的记录进行更新.
关键字: insert, delete, update等
多内容上进行操作(数据) 数据操作语言DML 你对一条数据的操作 添加(INSERT) 修改(UPFDATE) 删除(DELETE)
数据控制语言DCL:
DCL(Data Control Language), 用来定义 数据库 的访问权限和安全级别,及创建用户. 权限操作(DBA)
root 用户 MySQL中最高的胡数据库管理账户
数据查询语言
DQL(Data Query Language),用来查询数据库中标的记录. 关键字: select, from, where 等 查询(SELECT)
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾
- 可使用空格和缩进来增强语句可读性
- MySQL数据库的SQL语句不区分大小写,关键字建议用大写,例: SELECT * FROM user;
- 同样可以使用/**/的方式完成注释,也可以用 --注释
MySQL的数据类型
| 类型 | 描述 |
|---|---|
| int | 整型 |
| double | 浮点型 |
| varchar | 字符串型 |
| date | 日期类型,格式为yyyy-MM-dd,只有年月日没有时分秒 |
详细数据类型如下表:

DDL之数据库操作:database
创建数据库
格式:
* create database 数据库名;
* create database 数据库名 character set 字符集;
例如:
#创建数据库 数据库数据编码采用的是安装数据库时指定的默认编码 utf8
create database webdb_00;
#创建数据库 并指定数据库中数据的编码
create database webdb_01 character set utf8;
查看数据库
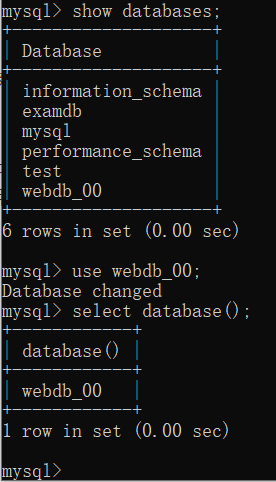
查看数据库中所有数据库
show databases;
查看某个数据库定义的信息:
show create database 数据库名;
show create database webdb_00;
删除数据库
drop database 数据库名称;
drop database webdb_00;
使用数据库
| 查看正在使用数据库
select database();
| 使用某个数据库
use 数据库名;
use webdb_01;
DDL之表操作:table
创建表
格式:
create table 表名(
字段名 类型(长度) [约束],
字段名 类型(长度) [约束],
... ...
);
类型:
varchar(n) 字符串
int 整形
double 浮点
date 时间
timestamp 时间戳
约束:
primary key 主键, 被主键修饰字段汇总的数据,不能重复、不能为null
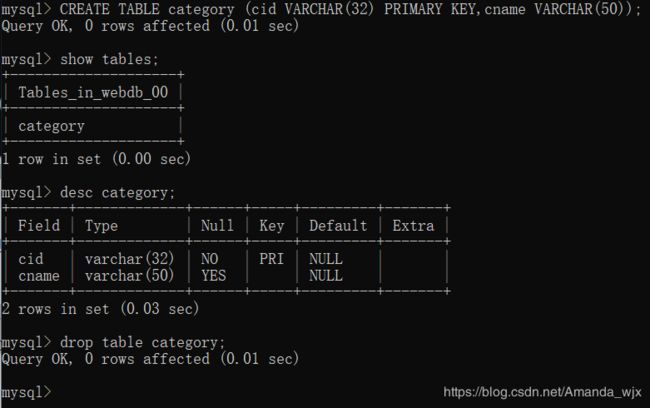
创建一张物品类别表,此处需注意:表都是在不同的数据库中,需先指定要使用的数据库
use webdb_00;
指定完数据库就可以创建自己的表了
CREATE TABLE category (cid VARCHAR(32) PRIMARY KEY,cname VARCHAR(50));
查看表
查看数据库中的所有表:
show tables;
查看表结构:
desc 表名;
desc category
删除表:
格式: drop table 表名;
drop table category;
修改表结构格式:
- alter table 表名 add 列名 类型(长度) [约束];
作用:修改表添加列
例:为商品类别表添加一个新的字段为 分类描述 varchar(20)
alter table category add `desc` varchar(20);
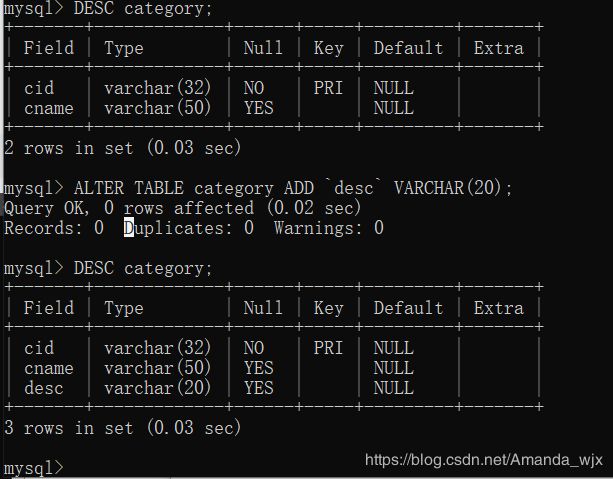
注意:DESC 是SQL关键字,想要用这个关键字做列明必须用 进行转移,它在Esc键下面.
2) alter table 表名 modify 列名 类型(长度) 约束;
作用:修改表格列的类型长度及约束.
例:为商品类别表字段进行修改,类型varchar(50) 添加约束 not null(该字段的值不能为null)
ALTER TABLE category MODIFY `desc` VARCHAR(50) NOT NULL;

3) ALTER TABLE 表名 CHANGE 旧列名 新列名 类型(长度) 约束;
作用:修改表修改列名
例:为商品类别表的分类修改名称字段进行更换,更换为: cdesc varchar(30)
ALTER TABLE category CHANGE `desc` cdesc VARCHAR(30);

4) ALTER TABLE 表名 DROP 列名;
作用:修改表删除列
例:删除商品分类中cdesc这列
ALTER TABLE category DROP cdesc;

5) RENAME TABLE 表名 TO 新表名;
作用:修改表名
例:为if诶类表category改成producttype
RENAME TABLE category TO producttype;

想先操作更方便可以尝试下载 Navicat客户端
DML数据操作语言
插入表记录:INSERT
语法:
– 向表中插入某些字段
INSERT INTO 表(字段1,字段2,字段3…) VALUES(值1,值2,值3…);
– 向表中插入所有字段,字段的顺序为创建表时的顺序
INSERT INTO 表 VALUES(值1,值2,值3…);
注意:
值或字段必须对应,个数相同,类型相同
值的数据大小必须在字段的长度范围内
除了数值类型外,其他字段类型的值必须用引号引起(建议单引号);
如果要插入空值,可以不写字段,或插入NULL
案例:
SELECT * FROM category;
-- 修改商品分类表表名
RENAME TABLE producttype TO category;
-- 添加数据
-- 标准写法为列于值一一对应
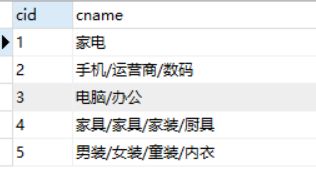
INSERT INTO category (cid,cname) VALUES (1,'家电');
-- 简易写法(值的顺序必须和列顺序一致)
INSERT INTO category VALUES (2,'手机/运营商/数码');
-- 便捷写法(一次性插入多条语句可以共享前置语法)
INSERT INTO category VALUES (3,'电脑/办公'),(4,'家巨/家具/家装/厨具'),(5,'男装/女装/童装/内衣');
更新记录表 : update
用来修改指定条件的数据,将满足条件的记录指定列修改为指定值
语法:
– 更新所有记录的指定字段
UPDATE 表名 SET 字段名 = 值, 字段名 = 值, …;
– 更新符合条件记录的指定字段
UPDATE 表名 SET 字段名=值 , 字段名=值 , … WHERE 条件;
注意 :
列名的类型与修改的值要一致
修改值的时候不能超过最大长度
除了数值类型外,其他用引号
代码:
-- 将家电更新为 美妆/个护清洁/宠物
UPDATE category SET cname = '美妆/个护清洁/宠物' WHERE cname = '家电';
-- 将ID为5的数据更新为 男鞋/运动/户外
UPDATE category SET cname = '男鞋/运动/户外' WHERE cid = 5;
注意:更新的时候一定要按照某种条件更新,因为更新全表数据这种需求根本就没有
删除记录: DELETE
删除分两种情况:
删除的是表中部分数据: DELETE FROM 表名 WHERE 条件;
删除表中全部数据: DELETE FROM 表名; 或 TRUNCATE TABLE 表名;
面试题:
假设表中有一亿条数据,当删除表中所有数据时,使用哪种方案
A.DELETE FROM 表;
B.TRUNCATE TABLE 表;
答案: B
解析:当删除数据表中的数据的时候,
DELETE FROM 表 数据DML语句 数据操纵语言 是从表中吧数据一条一条的删除,很慢
TRUNCATE TABLE 数据DDL语句 数据定义语言 它不管表中有多少记录,它会先摧毁这个表结构,然后重建表结构,所以删除数据很快
但是需要注意个问题,如果你要是误操作的话 delete from 是有可能恢复的 但是 truncate table是恢复不了的
代码:
-- 删除ID为1 的数据'
DELETE FROM category WHERE cid = 1;
-- 删除商品类别表的所有数据
DELETE FROM category;
-- 摧毁商品类别表的表结构后重建 截断
TRUNCATE TABLE category;
SQL约束
主键约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
主键的意义与作用
主键:表中经常有一个列或多列的组合,其值能唯一地标识表中的每一行。这样的一列或多列称为表的主键,通过它可强制表的实体完整性。当创建或更改表时可通过定义 PRIMARY KEY 约束来创建主键。
一个表只能有一个 PRIMARY KEY 约束,而且 PRIMARY KEY 约束中的列不能接受空值。由于 PRIMARY KEY 约束确保唯一数据,所以经常用来定义标识列。
作用:
1)保证实体的完整性;
2)加快数据库的操作速度
3) 在表中添加新记录时,DBMS会自动检查新记录的主键值,不允许该值与其他记录的主键值重复。
4) DBMS自动按主键值的顺序显示表中的记录。如果没有定义主键,则按输入记录的顺序显示表中的记录。
添加主键约束
创建表时,在字段描述处,声明指定字段为主键:
create table persons(
pid int PRIMARY key,
pname varchar(30),
sex VARCHAR(1),
age int,
pfrom varchar(50)
)
自动增长列
我们通常希望在每次插入新记录时,数据库自动生成字段的值。
我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整形,自动增长列必须为键(一般是主键)。
下列 SQL 语句把 “persons” 表中的 “pid” 列定义为 auto_increment 主键
create table persons(
pid int PRIMARY key AUTO_INCREMENT,
pname varchar(30),
sex VARCHAR(1),
age int,
pfrom varchar(50)
)
向persons添加数据时,可以不为pId字段设置值,也可以设置成null,数据库将自动维护主键值:
-- 标准写法
insert into persons (pname,sex,age,pfrom) values ('孙建国','男',35,'北京市');
-- 简易写法
insert into persons values (null,'赵文明','男',24,'河北省');
扩展:默认AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下列 SQL 语法:
/*前面没有改,后面再加的记录从100开始*/
ALTER TABLE Persons AUTO_INCREMENT=100
INSERT INTO persons VALUES (NULl,'赵晓华','女',24,'河北省');
SELECT * FROM persons;

非空约束
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
下面的 SQL 语句强制所有列不接受 NULL 值:
create table persons(
pid int not null PRIMARY key AUTO_INCREMENT,
pname varchar(30) not null,
sex VARCHAR(1) not null,
age int not null,
pfrom varchar(50) not null
)
注意 : 主键如果标记为primary key 就已经不为null了,所以此处not null 可以省略;
DQL数据查询语言:用来查询数据库中标的记录. 关键字: select, from, where等
创建商品表product ,商品编号PID(主键,自增) 商品名称PNAME 商品价格PRICE 商品类别C_ID
添加测试数据:
INSERT INTO product VALUES(null,' 联想(Lenovo)威6 14英寸商务轻薄笔记本电脑(i7-8550U 8G 256G PCIe SSD FHD MX150 Win10 两年上门)鲨鱼灰',5999,1);
INSERT INTO product VALUES(null,'联想(Lenovo)拯救者Y7000 15.6英寸游戏笔记本电脑(英特尔八代酷睿i5-8300H 8G 512G GTX1050 黑)',5999,1);
INSERT INTO product VALUES(null,'三洋(SANYO)9公斤智能变频滚筒洗衣机 臭氧除菌 空气洗 WiFi智能 中途添衣 Magic9魔力净',2499,1);
INSERT INTO product VALUES(null,'海尔(Haier) 滚筒洗衣机全自动 10公斤变频 99%防霉抗菌窗垫EG10014B39GU1',2499,1);
INSERT INTO product VALUES(null,'雷神(ThundeRobot)911SE炫彩版 15.6英寸游戏笔记本电脑(I7-8750H 8G 128SSD+1T GTX1050Ti Win10 RGB IPS)',6599,1);
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
INSERT INTO product VALUES(null,'真维斯JEANSWEST t恤男 纯棉圆领男士净色修身青年打底衫长袖体恤上衣 浅花灰 M',35,2);
INSERT INTO product VALUES(null,'PLAYBOY/花花公子休闲裤男弹力修身 秋季适中款商务男士直筒休闲长裤 黑色适中款 31(2.4尺)',128,2);
INSERT INTO product VALUES(null,'劲霸男装K-Boxing 短版茄克男士2018新款休闲舒适棒球领拼接青年夹克|FKDY3114 黑色 185',362,2);
INSERT INTO product VALUES(null,'Chanel 香奈儿 女包 2018全球购 新款蓝色鳄鱼皮小牛皮单肩斜挎包A 蓝色',306830,3);
INSERT INTO product VALUES(null,'皮尔卡丹(pierre cardin)钱包真皮新款横竖款男士短款头层牛皮钱夹欧美商务潮礼盒 黑色横款(款式一)',269,3);
INSERT INTO product VALUES(null,'PRADA 普拉达 女士黑色皮质单肩斜挎包 1BD094 PEO V SCH F0OK0',28512,3);
INSERT INTO product VALUES(null,'好想你 干果零食 新疆特产 阿克苏灰枣 免洗红枣子 玛瑙红500g/袋',21.9,4);
INSERT INTO product VALUES(null,'三只松鼠坚果大礼包1588g每日坚果礼盒干果组合送礼火红A网红零食坚果礼盒8袋装',128,4);
INSERT INTO product VALUES(null,'三只松鼠坚果炒货零食特产每日坚果开心果100g/袋',32.8,4);
INSERT INTO product VALUES(null,'洽洽坚果炒货孕妇坚果零食恰恰送礼每日坚果礼盒(26g*30包) 780g/盒(新老包装随机发货)',149,4);
INSERT INTO product VALUES(null,'今之逸品【拍3免1】今之逸品双眼皮贴双面胶美目舒适隐形立显大眼男女通用 中号160贴',9.9,5);
INSERT INTO product VALUES(null,'自然共和国 原自然乐园 芦荟舒缓保湿凝胶300ml*2(约600g)进口补水保湿舒缓晒后修复面膜',72,5);
INSERT INTO product VALUES(null,'欧莱雅LOREAL 男士火山岩控油清痘洁面膏100ml(洗面奶男 清洁毛孔 祛痘 男士洗面奶)',38.9,null);
INSERT INTO product VALUES(null,'阿拉丁 aladdin 144-62-7 无水草酸 O107180 草酸,无水 500g',88.1,null);
INSERT INTO product VALUES(null,'远东电缆(FAR EAST CABLE)BVVB 2*2.5平方国标家装照明插座用2芯硬护套铜芯电线装潢明线 100米',473,null);
DEL语法: SELECT [DISTINCT] * | 列名,列名 FROM 表 WHERE 条件;
- 查询所有的商品
SELECT * FROM PRODUCT;
- 查询商品名和商品价格
SELECT PNAME , PRICE FROM PRODUCT;
- 别名查询 使用的关键字是 AS (AS路省略)
-- 表别名
SELECTE P.PNAME , P.PRICE FROM PRODUCT P;
-- 列别名
-- 列别名 的第一种用途 更清楚的标记这一列是什么, 但是因为是中文标记 不常用
SELECT PNAME 商品名称 FROM PRODUCT;
-- 正常就是为了简化列名
SELECT PNAME C1 FROM PRODUCT;
- 去掉重复值
SELECT DISTINCT PRICE FROM PRODUCT;
- 查询结果是表达式(运算查询) : 将所有商品的价格 + 10 元进行显示
SELECT PNAME , PRICE 价格,(PRICE + 10) 包邮价 FROM PRODUCT;
条件查询
| 比较运算符 | < > <= >= = <> | 大于、小于、大于(小于)等于、不等于 |
|---|---|---|
| BETWEEN…AND | 显示在某一区间的值(含头含尾) | |
| IN(set) | 显示在in列表中的值,例: IN(100,200) | |
| LIKE ‘张pattern’ | 模糊查询 , LIKE语句中 , % 代表零个或多个任意字符 , _ 代表一个字符 , 例 FIRST_NAME LIKE ‘_A%’; | |
| IS NULL | 判断是否为空 | |
| 逻辑运算符 | AND | 多个条件同时成立 |
| OR | 多个条件任意成立 | |
| NOT | 不成立,例:WHERE NOT(SALARY > 100); |
-- 查询商品名称为“三只松鼠坚果炒货零食特产每日坚果开心果100g/袋”的商品所有信息:
SELECT * FROM PRODUCT WHERE PNAME = '三只松鼠坚果炒货零食特产每日坚果开心果100g/袋';
-- 查询价格为299 商品
SELECT * FROM PRODUCT WHERE PRICE = 299;
-- 查询价格表示800的所有商品
-- 最正常写法
SELECT * FROM PRODUCT WHERE PRICE != 800;
-- 诡异写法
SELECT * FROM PRODUCT WHERE PRICE <> 800;
-- 很不正常写法
SELECT * FROM PRODUCT WHERE NOT(PRICE = 800);
-- 查询商品价格大于10000的所有商品信息
SELECT * FROM PRODUCT WHERE PRICE > 10000;
-- 查询商品激昂2000到20000之间的所有商品
-- 标准写法
SELECT * FROM PRODUCT WHERE PRICE >= 2000 AND PRICE <= 10000;
-- 简易写法 效果一样
SELECT * FROM PRODUCT WHERE PRICE BETWEEN 2000 AND 10000;
-- 查询商品价格等于2000或大于10000的所有商品
SELECT * FROM PRODUCT WHERE PRICE > 10000 OR PRICE < 2000;
-- 查询含有'霸'字的所有商品
SELECT * FROM PRODUCT WHERE PNAME LIKE '%霸%';
-- 查询以'三'开头的所有商品
SELECT * FROM PRODUCT WHERE PNAME LIKE '三%';
-- 查询第二个字为'想'的所有商品
SELECT * FROM PRODUCT WHERE PNAME LIKE '_想%';
-- 商品有分类的商品
SELECT * FROM PRODUCT WHERE C_ID IS NOT NULL;
排序查询
通过ORDER BY语句,可以将查询出的结果进行排序.暂时放置在SELECT语句的最后.
格式:
SELECT * FROM 表名 ORDER BY 排序字段 ASC | DESC;
ASC 升序(默认)
DESC 降序
- 使用价格排序(降序)
-- 使用价格排序(降序)
SELECT * FROM PRODUCT ORDER BY PRICE DESC;
-- 2.在价格排序(降序)的基础上,以分类排序(降序)
SELECT * FROM PRODUCT ORDER BY PRICE DESC , C_ID DESC;
-- 3.显示商品的价格(去重复),并排序(降序)
SELECT DISTINCT PRICE FROM PRODUCT ORDER BY PRICE DESC;
聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
说白了,聚合查询就是先把表的数据聚在一起,统一进行计算后,再得出一个结果的查询方式;
聚合函数:
COUNT: 统计指定列不为NULL的记录行数;
SUM: 计算指定列的数值和.若指定列类型表示数值类型,内蒙计算结果为0;
MAX:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN: 计算指定列的最小值,若指定列是字符串类型,那么使用字符串排序运算;
AVG: 计算指定列的平均值,若指定列类型表示数值类型,那么计算结果为0;
-- 查询商品的总条数
SELECT COUNT(*) FROM PRODUCT; -- 这样统计效率不高 * 一整行数据 很多字节查询慢
SELECT COUNT(1) FROM PRODUCT; -- 优化措施
SELECT COUNT(PID) FROM PRODUCT; -- PID 主键 PRIMARY KEY --> 约束 / 索引
-- count(*) count(1) count(主键) √
-- 查询价格大于2000商品的总条数
SELECT COUNT(*) FROM PRODUCT WHERE PRICE >2000;
-- sum( ) 求和 ROUND() -- 求整(四舍五入函数)
SELECT ROUND(SUM(PRICE),2) FROM PRODUCT; --2 即两位小数,没有后面的2就是整数
-- 查询分类为 1 的所有商品的总和
SELECT COUNT(*) FROM PRODUCT WHERE C_ID = 1;
-- 查询分类为2所有商品的平均价格
SELECT AVG(PRICE) FROM PRODUCT WHERE C_ID = 2;
-- 查询商品的最大价格和最小价格
SELECT MIN(PRICE),MAX(PRICE) FROM PRODUCT;
**分组查询:**分组查询是指使用group by字句对查询信息进行分组。
格式:
SELECT 字段1,字段2 … FROM 表名 GROUP BY 分组字段 HAVING 分组条件;
分组操作中的HAVING子语句,是用于在分组后对数据进行过滤的,作用类似于WHERE语句
WHERE 和 HAVING的区别参考链接
HAVING和WHERE的区别:
HAVING所属在分组后度is护具进行过滤
WHERE是在分组前对数据进行过滤
HAVING后面可以使用分组函数(统计函数)
WHERE后面不可以使用分组函数
-- 统计各个分类商品的个数
SELECT C_ID ,COUNT(*) FROM PRODUCT GROUP BY C_ID;
-- 统计各个分类商品的个数,且只显示个数大于3的信息
SELECT C_ID ,COUNT(*) FROM PRODUCT GROUP BY C_ID HAVING COUNT(*) > 3;
多表操作(多表查询)
表与表至今的关系
一对多 关系: 在 从表(多)创建一个字段,字段作为外键指向主表(一)的主键.
常见示例:客户和订单,商品与商品的分类,部门与员工 ,班级和学生

设计步骤:
- 确定 设计的实体
- 确定 实体间的关系
- 做好 主外键关联 (先写主键表 再写外键表)
一对一关系: 就比如 身份证号对着学生学号,一对一创建成一张表就行了
多对多关系: 需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键
外键约束
外键特点:
从表外键的值是对主表主键的引用
从表外键类型,必须与主表主键类型一致
声明外键约束
语法:
ALTER TABLE 从表 ADD [CONSTRAINT] [外键名称] FOREIGN KEY(从表外键字段名) REFERENCES 主表 (主表的主键);
[外键名称] 用于删除外键约束的,一般建议 “_fk” 结尾
ALTER TABLE 从表 DROP FOREIGN kEY 外键名称
使用外键目的: 保证数据完整性
一对多操作
- 分析;
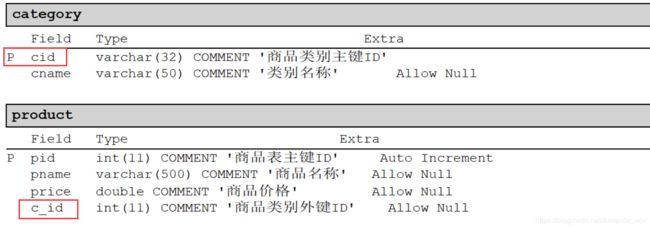
category分类表,为一方,也就是主表,必须提供主键cid
products商品表,为多方,也就是从表,必须提供外键c_id
-- 向商品类别表中添加数据
insert into category (cname) values ('男装/女装/童装/内衣'),('女鞋/箱包/珠宝/钟表'),('食品/酒类/生鲜/特产'),('美妆/个护清洁/宠物');
SELECT * FROM category;
SELECT * FROM product;
-- 向商品表中添加数据
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
INSERT INTO product VALUES(null,'真维斯JEANSWEST t恤男 纯棉圆领男士净色修身青年打底衫长袖体恤上衣 浅花灰 M',35,2);
INSERT INTO product VALUES(null,'PLAYBOY/花花公子休闲裤男弹力修身 秋季适中款商务男士直筒休闲长裤 黑色适中款 31(2.4尺)',128,2);
INSERT INTO product VALUES(null,'劲霸男装K-Boxing 短版茄克男士2018新款休闲舒适棒球领拼接青年夹克|FKDY3114 黑色 185',362,2);
INSERT INTO product VALUES(null,'Chanel 香奈儿 女包 2018全球购 新款蓝色鳄鱼皮小牛皮单肩斜挎包A 蓝色',306830,3);
INSERT INTO product VALUES(null,'皮尔卡丹(pierre cardin)钱包真皮新款横竖款男士短款头层牛皮钱夹欧美商务潮礼盒 黑色横款(款式一)',269,3);
INSERT INTO product VALUES(null,'PRADA 普拉达 女士黑色皮质单肩斜挎包 1BD094 PEO V SCH F0OK0',28512,3);
INSERT INTO product VALUES(null,'好想你 干果零食 新疆特产 阿克苏灰枣 免洗红枣子 玛瑙红500g/袋',21.9,4);
INSERT INTO product VALUES(null,'三只松鼠坚果大礼包1588g每日坚果礼盒干果组合送礼火红A网红零食坚果礼盒8袋装',128,4);
INSERT INTO product VALUES(null,'三只松鼠坚果炒货零食特产每日坚果开心果100g/袋',32.8,4);
INSERT INTO product VALUES(null,'洽洽坚果炒货孕妇坚果零食恰恰送礼每日坚果礼盒(26g*30包) 780g/盒(新老包装随机发货)',149,4);
INSERT INTO product VALUES(null,'今之逸品【拍3免1】今之逸品双眼皮贴双面胶美目舒适隐形立显大眼男女通用 中号160贴',9.9,5);
INSERT INTO product VALUES(null,'自然共和国 原自然乐园 芦荟舒缓保湿凝胶300ml*2(约600g)进口补水保湿舒缓晒后修复面膜',72,5);
多表查询
交叉连接查询
-- 多表查询
-- 交叉连接查询(得到的是两个表的乘积)
-- 语法: SELECT * FROM A,B;
-- 商品类别 5条数据
select count(*) from category;
-- 商品 18条数据
select count(*) from product;
-- 交叉查询 90条数据
select count(*) from product,category;
-- 详细数据
SELECT * FROM category,product;
笛卡尔积:
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员[3] 。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。

数据库表连接数据行匹配时所遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
笛卡尔积或有 很多重复值,所以我们要解决笛卡尔积的问题,即精确关联条件,去掉不必要的数据!
内连接查询(关键字 inner join – inner可省略)
隐式内连接:select * from A,B where 条件;
-- 内连接查询(关键字 inner join -- inner可省略)
-- 隐式内连接
SELECT * FROM CATEGORY,PRODUCT WHERE category.CID = PRODUCT.C_ID;
-- 起别名
SELECT * FROM CATEGORY C,PRODUCT P WHERE C.CID = P.C_ID;
显示内连接:select * from A inner join B on 条件; (推荐写法)
-- 显示内连接
SELECT * FROM CATEGORY C INNER JOIN PRODUCT P ON C.CID = P.C_ID
内连接原理 : 内连接根据我们连接条件大大的缩小的笛卡尔积的范围;在内连接中只有主外键能够关联上的数据才能被查询出来!
-- 内连接问题
-- 向商品类别表插入一条数据
INSERT INTO CATEGORY VALUES(NULL,'手机/运营商/数码');
-- 现在商品类别表中有5个类别
SELECT * FROM CATEGORY;
-- 当关联查询是
SELECT DISTINCT C.* FROM CATEGORY C INNER JOIN PRODUCT P ON C.CID = P.C_ID;
-- 只能查询出3个类别,这是为什么呢?
-- 这是因为商品表中就就只有五个类别能和商品类别表匹配,所以内连接把能匹配的数据都查询出来了,
外连接查询(使用关键字 outer join – outer可以省略)
外连接可以把关联查询的两张表的一张表作为主表,另外一张作为从表,而外链接使用保证主表的数据完整;
左外连接:left outer join
select * from A left outer join B on 条件;
-- 外连接可以把关联查询的两张表的一张表作为主表,另外一张作为从表,而外链接使用保证主表的数据完整;
SELECT * FROM CATEGORY C LEFT JOIN PRODUCT P ON C.CID = P.C_ID ORDER BY C.CID DESC;
SELECT DISTINCT C.*FROM CATEGORY C LEFT JOIN PRODUCT P ON C.CID = P.C_ID;
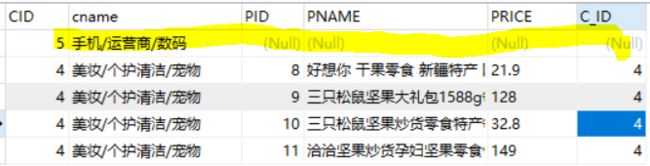

查询原理 : 左外连接查询是以left关键字左边的表为基准表,保证左表数据完整,如果右表没有与左表数据匹配的记录,那么右表将以一条null数据填充查询结果,保证左表的完整
右外连接:right outer join
右外链接与左外链接正好相反,它是保证右表数据完整;
此处需要注意一个问题就是所有的右外链接都能转为左外链接,所以右外链接应用并不广泛
SELECT * FROM A RIGHT OUTER JOIN B ON 条件;
各类连接查询区别总结

-- 多表查询综合案例
-- 查询价格在一万以内名字中包含 '想' 的商品
SELECT * FROM CATEGORY C,PRODUCT P WHERE C.CID = P.C_ID AND P.PRICE <=10000 AND P.PNAME LIKE '%想%';
-- 隐式内连接是借助where条件来设定关联关系,所以这样如果一旦where条件变多整体关联关系就很难把控,并且表越多,隐式内连接关联就越乱,所以这种方案我们并不采纳
-- 显式内连接 分工明确 不容易写乱套
SELECT * FROM CATEGORY C
INNER JOIN PRODUCT P ON C.CID = P.C_ID -- 此处设置管理
WHERE P.PRICE < 10000 AND P.PNAME LIKE '%想%'; -- 此处设置条件
-- 左外连接:
SELECT C.CNAME,COUNT(P.C_ID) GS FROM CATEGORY C
LEFT JOIN PRODUCT P ON C.CID = P.C_ID
GROUP BY C.CNAME;
-- 此处不能写 count(*) 如果写count(*) 手机/运营商/数码将会是1 因为确实有一条记录与之对应虽然记录里的数据都是null
-- 但是如果你统计外检表的任意一个列 count() 会忽略null值所以就是0了
子查询
-- 子查询
-- 定义一条select语句结果作为另一条select语法一部分(查询条件,查询结果,表等
-- 语法:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
-- 案例 : 查询和海尔洗衣机同样价格的商品
-- 第一步 : 找到海尔洗衣机
select * from product p where p.pname like '%海尔%洗衣机%';
-- 第二步 : 记住价格 2499
-- 第三步 : 根据价格查询
select * from product p where p.price = 2499;
-- 子查询 三部整合一步
select * from product p where p.price =
(select p.price from product p where p.pname like '%海尔%洗衣机%');
-- 查询所有商品的商品类别名称
select * from category where cid in (select DISTINCT c_id from product);
-- 上面这条SQL语句子查询部分返回了多条记录,这种子查询叫做单行多列子查询;
-- 还有的时候会把查询结果当成临时表存储起来然后在查询结果基础上再进行查询
select * from (
select p.*,c.cname from product p inner join category c on p.c_id = c.cid
) a where a.price > 10000
-- 上面这条语句就是把一个查询结果直接封装为一个虚拟表a表 然后在封装的虚拟表a表的基础上又做查询 这种子查询叫做 多行多列子查询;
实现:分类和商品
-- 清空商品类别表和商品表信息(不清空的话是创建不了外键约束的)
TRUNCATE TABLE PRODUCT;
TRUNCATE TABLE CATEGORY;
--
-- 清空商品表和类别表(不请空创建不了外键约束
TRUNCATE TABLE PRODUCT;
TRUNCATE TABLE CATEGORY;
-- 设置商品表的外键id不为NULL
ALTER TABLE PRODUCT MODIFY C_ID INT NOT NULL;
-- 修改商品表分类表的主键(商品分类 表主键是VARCHAR的不能和匹配,必须修改
ALTER TABLE CATEGORY MODIFY CID INT NOT NULL AUTO_INCREMENT;
-- 添加约束
ALTER TABLE PRODUCT ADD CONSTRAINT FK_PRODUCT_CID FOREIGN KEY (C_ID) REFERENCES CATEGORY(CID);
实战-2018年北京市高考成绩管理与分析系统数据库实战
数据库介绍
- 数据库名称 : examdb
- 数据库字符集 : utf8 排序方式 : utf8_general_ci
- 表结构说明 :
a.地区表area:存储北京所有区 a_id 地区ID a_name 地区名称

b.学校表school:保存个区域的学校信息 sc_id 学校主键ID sc_name 学校名称 a_id 区域外键
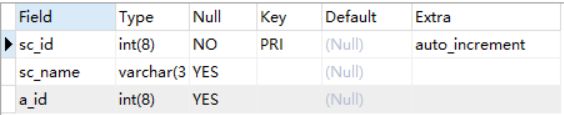
c.学生表student:存储学生信息 s_id 学生编号 是)name 学生姓名 s_sex 性别:0(女)1(男)
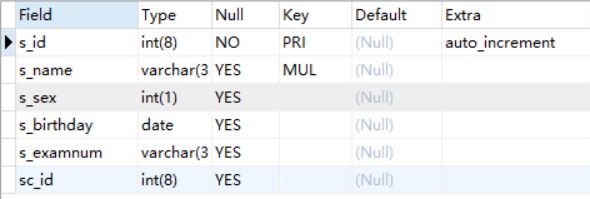
d.考试科目表subject su_id学科ID su_name学科名称 1:语文 2:数学 3:英语 4:综合

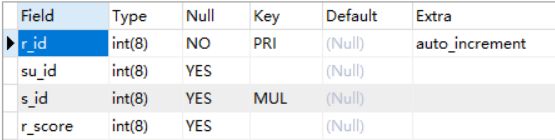
e. 考试成绩表result:保存考试成绩 r_id考试成绩ID su_id学科ID s_id 学生ID r_score考试分数
- 表关系说明 :
a. 一个地区有多个学校,所以地区表和学校表是一对多关系
b. 一个学校有多个学生,所以学校表和学生表是一对多关系
c. 一个学生有多个考试结果,所以学生表和考试成绩表是一对多关系
d. 一个考试科目下有多个考试成绩,所以考试科目表和考试成绩表示一对多关系
导入SQL脚本
- 创建examdb数据库

- 导入脚本
右键数据库–>运行SQL文件–>找到文件路径–>开始
数据库文件地址:
查询实战练习
查询各表数据基本情况
SELECT * FROM 表名
查询各表数据总量
SELECT COUNT(*) FROM 表名
分页查询数据:
适合数据量很大的表
MySQL查询语句汇总使用LIMIT子句限制结果集

位置偏移量:指结果集中第几条数据开始显示(第1条记录的文职偏移量是0)
例:
-- 查找1-5条学生数据
SELECTE * FROM student LIMIT 0,5
-- 查询5-10条学生数据
select * from student LIMIT 5,5
总结规律 :
根据上面的查询规律,我们可以假设 如果我一共有 10 条数据的话 每页展示5条 那么上面的这个查询就是每页展示的数据量;
也就是说我们无意之间完成了一个分4页展示的案例;
所以总结规律我们可以得出一个算法:
如果想完成一个分页,我们必须知道以下几个参数
- 总数据量 总条数 totalCount
- 每页展示的数据量 页容量 pageSize
- 一共有多少页 总页数 totalPage
- 当前页数 页码 pageIndex
根据以上参数我们能得出以下公式: - totalPage总页数 = totalCount总条数%pageSize页容量==0? totalCount/pageSize: totalCount/pageSize+1;
- limit的第一个参数 = (pageIndex页码-1)*pageSize页容量;
- limit的第二个参数 = pageSize;
连接: