清华大学姚期智团队:Scaling Nakamoto Consensus to Thousands of Transactions per Second
文章目录
- 摘要
- 1. Introduction
- 2. Conflux架构
- 3. 共识协议
- 4. 共识算法
- 5. 安全性假设
- 6. 系统实现
- 7. 实验
- 7.1 throughput 交易通量
- 7.2 确认时间
- 7.3 扩展性
摘要
conflux的设计思想:在不抛弃所有分叉块的前提下,用DAG图来算出区块顺序。这里有一个比较关键的地方是,不像我们知道的所有必须先确定交易顺序,再确定区块顺序的设计思路,conflux是先把区块顺序算出来,再决定要保留哪些交易
conflux性能:在亚马逊ec2上模拟了20k全节点,达到5.76GB/h的吞吐量以及在4.5-7.4的交易确认时间(由于中本聪是概率性共识,这个交易确认时间是指<0.01%被颠覆的可能花的时间),对于典型的比特币交易来说,这个处理能力相当于每秒6400笔交易。并且conflux共识的瓶颈已经不再是协议本身了,而是单个节点的处理能力。(Q:所有的共识协议不都是这样的吗?硬件越好,处理能力当然越强)
1. Introduction
中本聪共识的问题:
- 只有一个参与者赢得挖矿竞争 :就是同时挖出来的区块,只有一个是最终放到区块链里的,剩下的分叉块都会被抛弃;
- 确认时间长是必要的:就是确认时间这么长,是为了抵御攻击,比如一个块后面再连着十个区块,才认为交易可信;
已有共识协议差不多都是从以下两方面来改进的:
- 减少共识参与者的数量:例如bitcoin-NG,周期性选一个leader出来负责出块
- 选出一部分参与人作为committee,运行BFT算法:这种方法在参与人之间划分了阶层(就是权力不对等),与去中心化思想违背。比如algorand,stellar
2. Conflux架构
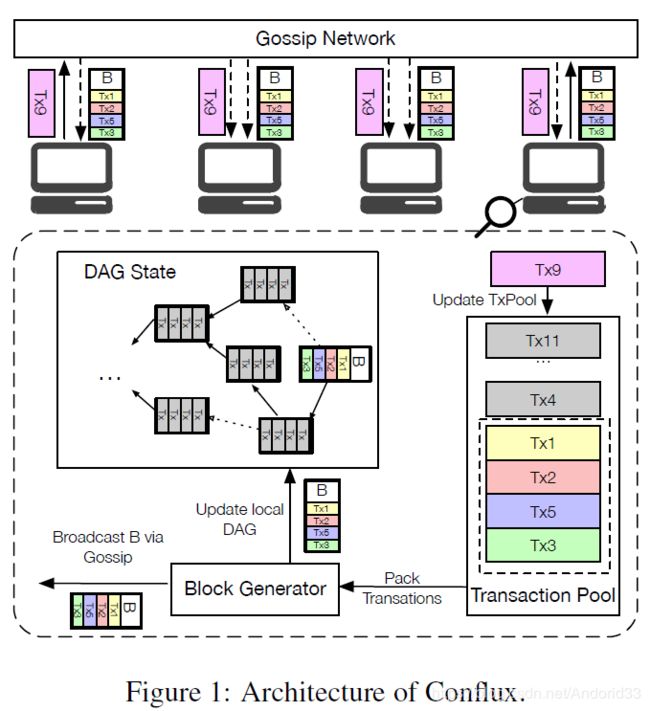
运行过程:
- 交易tx9广播到所有节点上(用的bitcoin core里的gossip网络,做了修改)
- 节点把新收到的交易,tx9,放到自己的交易池中
- 节点通过block generator 打包交易,生成区块(区块产生用的POW算法)
- 区块生成后,相关交易从缓冲池中删去,更新本地的DAG图
- 把区块广播给其他节点并把区块广播给其他节点
3. 共识协议

核心思想:1. 先确定区块顺序,再确定交易顺序;2. 有冲突或双花的交易,只处理第一个,剩下的抛弃
重要概念:
- Parent edge(实线):除了创始快,每个块都有且只有一个outgoing的parent edge,例如C到A,F到B
- Reference edge(虚线):每个区块有多个reference edge,代表了区块的时间产生先后顺序(happen-before关系),例如E到D
- Pivot Chain:在parent tree中,从创始块到叶子块选一个主链出来,主链的选取用了GHOST算法,GHOST算法不是计算最长链,而是计算子树尺寸最大的链,例如主链是Genesis,A,C,E,H,而不是最长链Genesis,B,F,J,I,K,因为A的子树包含的区块比B的子树更多?(A的子树包含D,G,C,E,H5个,B的子树包含F,J,I,K4个)
- Generating new block:产生新块的时候,节点先用本地DAG图算一个主链出来,新块指向主链的最后一个块,作为parent edge,同时检查其他没有指向边的块(就是除父块以外的所有叶子块),新块向这些块链接reference edge,例如新块指向H parent edge,指向K reference edge
- Epoch: 主链上每个块负责一个epoch,这个块可reach的区块就属于这个epoch,例如J可以被H reach,但不能被E reach,所以J属于H的epoch
- Block total order:对区块排序时,首先对不同的epoch进行排序,再去同一个epoch内的排序,如果同一个epoch中的块不存在偏序关系(就是happen-before关系),就根据区块的ID大小排序,例如图上的区块顺序是Genesis,A(A epoch),B,C(C epoch),D,F,E(E epoch,D的hash比F小),G,J,I,H(H epoch, G的哈希比J小),K
- Transaction total order:根据Block total order,剔除冲突交易,生成交易顺序,例如,交易顺序是TX0,TX1,TX2,TX3,TX4(B区块),TX4(G区块),但是TX3和TX2是冲突的双花交易,TX4(G区块)是TX4(B区块)重复的交易,所以最终顺序是TX0,TX1,TX2,
TX3,TX4(B区块),TX4(G区块)
安全性分析:如果攻击者想要颠覆TX4(B区块),那就必须生成一个顺序排在B区块之前的区块,因此他生成一个包含TX4的区块,并指向genesis block,但这个区块没有child,根据epoch的定义,他只能放在最后。
4. 共识算法
DAG图:
G = < B , g , P , E > G =<B,g,P,E> G=<B,g,P,E>
B B B: 区块集合
g g g: genesis block
P P P: 区块到 parent block的映射函数,即 P ( b ) P(b) P(b)就是b的parent block,genesis的 P ( g ) P(g) P(g)为空(为什么需要P,因为E中包含了所有了边,但没有对parent 和 reference edge做区分)
E E E: 边集合,包含parent 和 reference edge,例如 e = < b , b ′ > e=<b,b'> e=<b,b′>
函数定义:
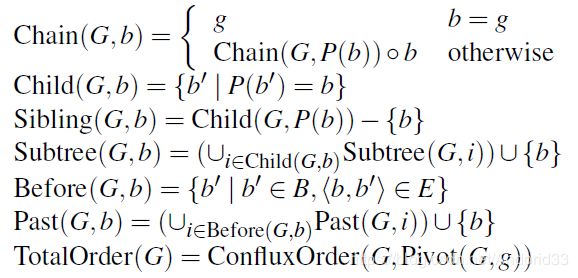
Chain(G,b): 在G中,从创始块到b区块的主链(GHOST算法)
Child(G,b): b区块的所有孩子集合,只包含parent edge的那些
Sibiling(G,b): b的兄弟姐妹,也是只涉及parent edge
Subtree(G,b): b的子树,包含b本身
Before(G,b): b指向的区块,包含parent edge和reference edge,他们都有happen-before的关系
Past(G,b):b之前的所有区块集合,包括b,即所有在b之前的区块
TotalOrder(G): G里所有区块的排序
具体算法:
1. Pivot(G,b): 返回主链的最后一个区块(在例子的图中,Pivot(G,g) = H)

这里面就是GHOST协议的主要思想,即不是通过最长链来选main chain,而是选拥有子树区块最多的那条链,通过迭代,直到计算到叶子节点
在上面的图例中,计算Pivot(G,g),在6步中,g的孩子有A,B, 7-8步中,A的子树区块总个数是a,c,d,e,h,g,6个,B的子树个数 b,f,j,i,k5个,所以A被返回,继续比较A的子树 D,G,C, C被返回,最后选出了H
2. conflux中节点不断执行的主循环,即共识操作

2-6为节点收到其他节点发来的更新信息后的动作:更新自己的本地DAG图,将G广播给其他节点(虽然伪代码里这么写,但是节点并不会发所有的G,具体实现当中只会发差额的G)
7-11为节点自己产生了新块以后的动作:首先把自己本地的主链的最后一个块a算出来,用Pivot(G,g)算法,然后第9行中t是当前所有还没有入边的区块,创建新区块b到这些区块的边,第10行添加新区块b到a的parent edge.
3. confluxOrder():算出G中从创始快到主链中的某个区块a的区块顺序
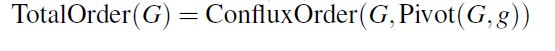
从这里可以看出,pivot(G,g)返回的是主链上的最后一个块,confluxOrder(G,pivot(G,g))也就是整个DAG图的区块顺序排序,即totalOrder(G)

算法是从后往前递归来算的,首先找到a的parent,将a的parent的conflux order赋值给L,然后来计算a这个epoch(主链上的每个块划分了自己的epoch)当中的区块顺序
第5行 B Δ B_\Delta BΔ代表a这个epoch中的所有区块,排序时,首先找到没有出边的区块,对这些进行排序,然后剔除,再排序。还是用上面那个图来看,例如现在对H epoch里的区块G,H,J,I排序,没有出边的块有G,J,根据哈希进行排序,那就是G,J,把他们放到L中(11行) 然后剔除这两个区块(12行),对剩下的H,I排序,剔除了G,J后,I已经没有出边了,但是H还有(H指向I),因此这个epoch当中的顺序就是G,J,I,H
接下来同样的办法对epoch E当中的区块排序,直到排到创始块结束(2-3行)
5. 安全性假设
区块产生速率:
λ h \lambda_h λh: 诚实honest节点的区块产生速率
λ a \lambda_a λa: 恶意attacker节点的区块产生速率
λ = λ h + λ a \lambda = \lambda_h+\lambda_a λ=λh+λa 总速率等于两个相加
λ a = q × λ h \lambda_a = q\times\lambda_h λa=q×λh
0 ≤ q < 1 0\le q<1 0≤q<1
就是和比特币系统安全性一样的假设,诚实节点出块更快
**网络传输限制:**d-Synchronous
诚实节点在时间 t+d 内可以把消息传输给其他节点
6. 系统实现
在比特币之上修改的代码,bitcoin core v0.16.0 实现了conflux和GHOST算法,作为对比
区块头:包含了reference edge
Gossip网络:比特币只广播最长链上的区块,其他分叉块不广播,修改了传输协议,支持广播所有区块,当conflux节点收到一个区块时,用广度优先算法遍历DAG,更新遍历区块的合法性(就是收到了这个区块的所有past block,才能参与conflux共识,如果B指向A,A还没收到,那就没法做共识了)
检测旧区块(stale block,可能是腐败区块?):stale block就是指攻击者恶意生成的区块,这些区块的时间戳有问题,有的提前生成,有的故意修改成之前的时间。增加了节点周期性和其他节点进行时间同步,计算出一个返回时间的中值,如果新收到的区块时间早于中值的前11个块(没看懂是前11个区块的时间还是推算前11个区块的时间),或者晚于中值时间的两个小时后,就删掉
节点启动:为了进行DAG信息的同步,增加了四个接口,gettips,tips,getchains,chains
7. 实验
环境:在800台8核亚马逊虚拟机上,每台模拟25个全节点,带宽限制在20Mbps,为了模拟网络延迟,插入人工延迟(城市间延迟度量inter-city latency,每个虚拟机作为一个城市),每个全节点平均和十个随机节点相连
DAG的计算开销和POW相比可忽略不计
一个区块的大小最多只有960KB
7.1 throughput 交易通量
实验环境:400台虚拟机上跑10k(一万,模拟比特币规模)全节点,改变配置 1)区块20s产生速度下,调整区块大小限制,从1MB增大到8MB 2)区块大小在4MB的限制下,调整产生速率从5s到80s


纵轴是块利用率,论文中所说,共识协议的吞吐量和三个因素相关:区块大小,区块产生速度,块利用率
比特币和GHOST都有分叉,所以利用率不高,区块大小增大和产生速度增大时,废块会更多,(我理解:前者是因为冲突交易多了,后者是因为同时产生的区块多了),但是conflux计算了所有的区块,所以利用率一直是1
在4MB/5s时,吞吐量是2.88GB/h
7.2 确认时间
区块的确认时间:指的是 <0.01%的可能性被颠覆所需要的时间
实验环境:假设敌手占有20%的算力

- GHOST和conflux的确认时间很接近,这是因为他们都是用的相同的主链选取算法,即GHOST协议
- 第一张图只有1MB,2MB的条件下,比特币才有值,这是因为4MB及以上的区块大小时,比特币无法完成确认了,因为分叉太严重;同理,第二张图也只有在80s的情况下才有确认时间,因为出块速度过快,分叉太多无法完成确认
7.3 扩展性
实验条件:1)改变全节点数量,在4MB/10s的条件下从2.5k扩展到20k;2)改变带宽,在4MB/2.5s的条件下从20Mbps到40Mbps
扩展带宽:增加带宽到40Mbps,10k全节点时(没有图,只有数据,因为4MB/2.5s这个出块速率时,网络传输量激增,带宽成为了主要的限制因素,因此提升带宽到40),吞吐量在5.76GB/h,平均确认时间是5.68分钟,如果以比特币的交易大小来衡量的话,每秒处理的交易时6400笔(不过这个类比是没有什么意义的,因为文中说了,4MB/2.5s这个出块速率比特币根本无法完成交易确认,只是提供给读者一个直观上的概念吧)
扩展节点

- 节点大小从2.5k扩展到20k的时候,确认时间是差不多的,说明节点扩展性好
- 节点从2.5k扩展到20k的时候,网络直径(network diameter,就是说传播一笔交易让99%的节点都收到花费的时间)基本是线性增加,这个比较正常,在20k全节点的时间,传播时间平均是10.7分钟
原文链接: Scaling Nakamoto Consensus to Thousands of Transactions per Second.