AudioTrack相关记录
深入剖析Android音频之AudioTrack
播放声音能够用MediaPlayer和AudioTrack,两者都提供了java API供应用开发人员使用。尽管都能够播放声音。但两者还是有非常大的差别的。当中最大的差别是MediaPlayer能够播放多种格式的声音文件。比如MP3。AAC,WAV,OGG。MIDI等。
MediaPlayer会在framework层创建相应的音频解码器。而AudioTrack仅仅能播放已经解码的PCM流,假设是文件的话仅仅支持wav格式的音频文件,由于wav格式的音频文件大部分都是PCM流。AudioTrack不创建解码器。所以仅仅能播放不需要解码的wav文件。
当然两者之间还是有紧密的联系,MediaPlayer在framework层还是会创建AudioTrack,把解码后的PCM数流传递给AudioTrack。AudioTrack再传递给AudioFlinger进行混音,然后才传递给硬件播放,所以是MediaPlayer包括了AudioTrack。使用AudioTrack播放音乐演示样例:
AudioTrack audio = new AudioTrack(
AudioManager.STREAM_MUSIC, // 指定流的类型
32000, // 设置音频数据的採样率 32k,假设是44.1k就是44100
AudioFormat.CHANNEL_OUT_STEREO, // 设置输出声道为双声道立体声,而CHANNEL_OUT_MONO类型是单声道
AudioFormat.ENCODING_PCM_16BIT, // 设置音频数据块是8位还是16位。这里设置为16位。
好像如今绝大多数的音频都是16位的了
AudioTrack.MODE_STREAM // 设置模式类型,在这里设置为流类型,第二种MODE_STATIC貌似没有什么效果
);
audio.play(); // start启动音频设备。以下就能够真正開始音频数据的播放了
// 打开mp3文件,读取数据,解码等操作省略 ...
byte[] buffer = new buffer[4096];
int count;
while(true)
{
// 最关键的是将解码后的数据,从缓冲区写入到AudioTrack对象中
audio.write(buffer, 0, 4096);
if(文件结束) break;
}
//关闭并释放资源
audio.stop();
audio.release();

AudioTrack构造过程
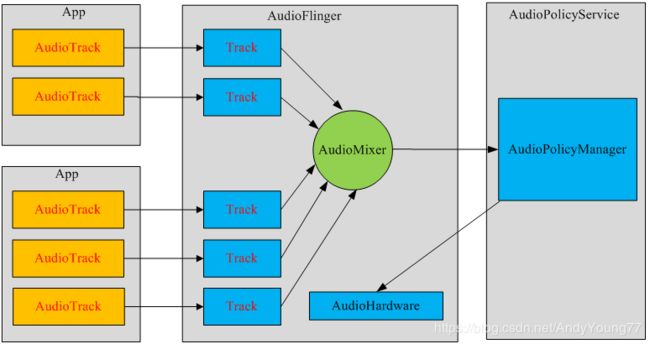
每个音频流相应着一个AudioTrack类的一个实例,每个AudioTrack会在创建时注冊到 AudioFlinger中,也就是对应AudioFlinger中的一个track,client & proxy。由AudioFlinger把全部的AudioTrack进行混合(Mixer)。然后输送到AudioHardware中进行播放。眼下Android同一时候最多能够创建32个音频流,也就是说。Mixer最多会同一时候处理32个AudioTrack的数据流。
frameworks\base\media\java\android\media\AudioTrack.java
/**
-
streamType:音频流类型
-
sampleRateInHz:採样率
-
channelConfig:音频声道
-
audioFormat:音频格式
-
bufferSizeInBytes缓冲区大小:
-
mode:音频数据载入模式
-
sessionId:会话id
*/public AudioTrack(int streamType, int sampleRateInHz, int channelConfig, int audioFormat,
int bufferSizeInBytes, int mode, int sessionId)
throws IllegalArgumentException {
// mState already == STATE_UNINITIALIZED// remember which looper is associated with the AudioTrack instantiation Looper looper; if ((looper = Looper.myLooper()) == null) { looper = Looper.getMainLooper(); } mInitializationLooper = looper; /** * 參数检查 * 1.检查streamType是否为:STREAM_ALARM、STREAM_MUSIC、STREAM_RING、STREAM_SYSTEM、STREAM_VOICE_CALL、 * STREAM_NOTIFICATION、STREAM_BLUETOOTH_SCO、STREAM_BLUETOOTH_SCO,并赋值给mStreamType * 2.检查sampleRateInHz是否在4000到48000之间。并赋值给mSampleRate * 3.设置mChannels: * CHANNEL_OUT_DEFAULT、CHANNEL_OUT_MONO、CHANNEL_CONFIGURATION_MONO ---> CHANNEL_OUT_MONO * CHANNEL_OUT_STEREO、CHANNEL_CONFIGURATION_STEREO ---> CHANNEL_OUT_STEREO * 4.设置mAudioFormat: * ENCODING_PCM_16BIT、ENCODING_DEFAULT ---> ENCODING_PCM_16BIT * ENCODING_PCM_8BIT ---> ENCODING_PCM_8BIT * 5.设置mDataLoadMode: * MODE_STREAM * MODE_STATIC */ audioParamCheck(streamType, sampleRateInHz, channelConfig, audioFormat, mode); /** * buffer大小检查,计算每帧字节大小,假设是ENCODING_PCM_16BIT,则为mChannelCount * 2 * mNativeBufferSizeInFrames为帧数 */ audioBuffSizeCheck(bufferSizeInBytes); if (sessionId < 0) { throw new IllegalArgumentException("Invalid audio session ID: "+sessionId); } //进入native层初始化 int[] session = new int[1]; session[0] = sessionId; // native initialization int initResult = native_setup(new WeakReference(this), mStreamType, mSampleRate, mChannels, mAudioFormat, mNativeBufferSizeInBytes, mDataLoadMode, session); if (initResult != SUCCESS) { loge("Error code "+initResult+" when initializing AudioTrack."); return; // with mState == STATE_UNINITIALIZED } mSessionId = session[0]; if (mDataLoadMode == MODE_STATIC) { mState = STATE_NO_STATIC_DATA; } else { mState = STATE_INITIALIZED; }
audio session. Use this constructor when the AudioTrack must be attached to a particular audio session. The primary use of the audio session ID is to associate audio effects to a particular instance of AudioTrack: if an audio session ID is provided when creating an AudioEffect, this effect will be applied only to audio tracks and media players in the same session and not to the output mix. When an AudioTrack is created without specifying a session, it will create its own session which can be retreived by calling the getAudioSessionId() method. If a non-zero session ID is provided, this AudioTrack will share effects attached to this session with all other media players or audio tracks in the same session, otherwise a new session will be created for this track if none is supplied.
streamType
the type of the audio stream. See STREAM_VOICE_CALL,STREAM_SYSTEM,STREAM_RING,STREAM_MUSIC,STREAM_ALARM, and STREAM_NOTIFICATION.
sampleRateInHz
the sample rate expressed in Hertz.
channelConfig
describes the configuration of the audio channels. SeeCHANNEL_OUT_MONO and CHANNEL_OUT_STEREO
audioFormat
the format in which the audio data is represented. See ENCODING_PCM_16BIT and ENCODING_PCM_8BIT
bufferSizeInBytes
the total size (in bytes) of the buffer where audio data is read from for playback. If using the AudioTrack in streaming mode, you can write data into this buffer in smaller chunks than this size. If using the AudioTrack in static mode, this is the maximum size of the sound that will be played for this instance. See getMinBufferSize(int, int, int) to determine the minimum required buffer size for the successful creation of an AudioTrack instance in streaming mode. Using values smaller than getMinBufferSize() will result in an initialization failure.
mode
streaming or static buffer. See MODE_STATIC and MODE_STREAM
sessionId
Id of audio session the AudioTrack must be attached to
AudioTrack有两种数据载入模式:
MODE_STREAM
在这样的模式下,应用程序持续地write音频数据流到AudioTrack中,而且write动作将阻塞直到数据流从Java层传输到native层,同一时候增加到播放队列中。这样的模式适用于播放大音频数据,但该模式也造成了一定的延时;
MODE_STATIC
在播放之前,先把全部数据一次性write到AudioTrack的内部缓冲区中。适用于播放内存占用小、延时要求较高的音频数据。
frameworks\base\core\jni\android_media_AudioTrack.cpp
static int android_media_AudioTrack_native_setup(JNIEnv *env, jobject thiz, jobject weak_this,jint streamType, jint sampleRateInHertz, jint javaChannelMask,
jint audioFormat, jint buffSizeInBytes, jint memoryMode, jintArray jSession)
{
ALOGV("sampleRate=%d, audioFormat(from Java)=%d, channel mask=%x, buffSize=%d",
sampleRateInHertz, audioFormat, javaChannelMask, buffSizeInBytes);
int afSampleRate;//採样率
int afFrameCount;//帧数
//通过AudioSystem从AudioPolicyService中读取相应音频流类型的帧数
if (AudioSystem::getOutputFrameCount(&afFrameCount, (audio_stream_type_t) streamType) != NO_ERROR) {
ALOGE("Error creating AudioTrack: Could not get AudioSystem frame count.");
return AUDIOTRACK_ERROR_SETUP_AUDIOSYSTEM;
}
//通过AudioSystem从AudioPolicyService中读取相应音频流类型的採样率
if (AudioSystem::getOutputSamplingRate(&afSampleRate, (audio_stream_type_t) streamType) != NO_ERROR) {
ALOGE("Error creating AudioTrack: Could not get AudioSystem sampling rate.");
return AUDIOTRACK_ERROR_SETUP_AUDIOSYSTEM;
}
// Java channel masks don't map directly to the native definition, but it's a simple shift
// to skip the two deprecated channel configurations "default" and "mono".
uint32_t nativeChannelMask = ((uint32_t)javaChannelMask) >> 2;
//推断是否为输出通道
if (!audio_is_output_channel(nativeChannelMask)) {
ALOGE("Error creating AudioTrack: invalid channel mask.");
return AUDIOTRACK_ERROR_SETUP_INVALIDCHANNELMASK;
}
//得到通道个数,popcount函数用于统计一个整数中有多少位为1
int nbChannels = popcount(nativeChannelMask);
// check the stream type
audio_stream_type_t atStreamType;
switch (streamType) {
case AUDIO_STREAM_VOICE_CALL:
case AUDIO_STREAM_SYSTEM:
case AUDIO_STREAM_RING:
case AUDIO_STREAM_MUSIC:
case AUDIO_STREAM_ALARM:
case AUDIO_STREAM_NOTIFICATION:
case AUDIO_STREAM_BLUETOOTH_SCO:
case AUDIO_STREAM_DTMF:
atStreamType = (audio_stream_type_t) streamType;
break;
default:
ALOGE("Error creating AudioTrack: unknown stream type.");
return AUDIOTRACK_ERROR_SETUP_INVALIDSTREAMTYPE;
}
// This function was called from Java, so we compare the format against the Java constants
if ((audioFormat != javaAudioTrackFields.PCM16) && (audioFormat != javaAudioTrackFields.PCM8)) {
ALOGE("Error creating AudioTrack: unsupported audio format.");
return AUDIOTRACK_ERROR_SETUP_INVALIDFORMAT;
}
// for the moment 8bitPCM in MODE_STATIC is not supported natively in the AudioTrack C++ class so we declare everything as 16bitPCM, the 8->16bit conversion for MODE_STATIC will be handled in android_media_AudioTrack_native_write_byte()
if ((audioFormat == javaAudioTrackFields.PCM8)
&& (memoryMode == javaAudioTrackFields.MODE_STATIC)) {
ALOGV("android_media_AudioTrack_native_setup(): requesting MODE_STATIC for 8bit \
buff size of %dbytes, switching to 16bit, buff size of %dbytes",
buffSizeInBytes, 2*buffSizeInBytes);
audioFormat = javaAudioTrackFields.PCM16;
// we will need twice the memory to store the data
buffSizeInBytes *= 2;
}
//依据不同的採样方式得到一个採样点的字节数
int bytesPerSample = audioFormat == javaAudioTrackFields.PCM16 ? 2 : 1;
audio_format_t format = audioFormat == javaAudioTrackFields.PCM16 ?
AUDIO_FORMAT_PCM_16_BIT : AUDIO_FORMAT_PCM_8_BIT;
//依据buffer大小反向计算帧数 。 一帧大小=一个採样点字节数 * 声道数
int frameCount = buffSizeInBytes / (nbChannels * bytesPerSample);
//推断參数的合法性
jclass clazz = env->GetObjectClass(thiz);
if (clazz == NULL) {
ALOGE("Can't find %s when setting up callback.", kClassPathName);
return AUDIOTRACK_ERROR_SETUP_NATIVEINITFAILED;
}
if (jSession == NULL) {
ALOGE("Error creating AudioTrack: invalid session ID pointer");
return AUDIOTRACK_ERROR;
}
jint* nSession = (jint *) env->GetPrimitiveArrayCritical(jSession, NULL);
if (nSession == NULL) {
ALOGE("Error creating AudioTrack: Error retrieving session id pointer");
return AUDIOTRACK_ERROR;
}
int sessionId = nSession[0];
env->ReleasePrimitiveArrayCritical(jSession, nSession, 0);
nSession = NULL;
// create the native AudioTrack object
sp lpTrack = new AudioTrack();
if (lpTrack == NULL) {
ALOGE("Error creating uninitialized AudioTrack");
return AUDIOTRACK_ERROR_SETUP_NATIVEINITFAILED;
}
// 创建存储音频数据的容器
AudioTrackJniStorage* lpJniStorage = new AudioTrackJniStorage();
lpJniStorage->mStreamType = atStreamType;
//将Java层的AudioTrack引用保存到AudioTrackJniStorage中
lpJniStorage->mCallbackData.audioTrack_class = (jclass)env->NewGlobalRef(clazz);
// we use a weak reference so the AudioTrack object can be garbage collected.
lpJniStorage->mCallbackData.audioTrack_ref = env->NewGlobalRef(weak_this);
lpJniStorage->mCallbackData.busy = false;
//初始化不同模式下的native AudioTrack对象
if (memoryMode == javaAudioTrackFields.MODE_STREAM) { //stream模式
lpTrack->set(
atStreamType,// stream type
sampleRateInHertz,
format,// word length, PCM
nativeChannelMask,
frameCount,
AUDIO_OUTPUT_FLAG_NONE,
audioCallback,
&(lpJniStorage->mCallbackData),//callback, callback data (user)
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
0,//stream模式下的共享内存在AudioFlinger中创建
true,// thread can call Java
sessionId);// audio session ID
} else if (memoryMode == javaAudioTrackFields.MODE_STATIC) {//static模式
// 为AudioTrack分配共享内存区域
if (!lpJniStorage->allocSharedMem(buffSizeInBytes)) {
ALOGE("Error creating AudioTrack in static mode: error creating mem heap base");
goto native_init_failure;
}
lpTrack->set(
atStreamType,// stream type
sampleRateInHertz,
format,// word length, PCM
nativeChannelMask,
frameCount,
AUDIO_OUTPUT_FLAG_NONE,
audioCallback, &(lpJniStorage->mCallbackData),//callback, callback data (user));
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
lpJniStorage->mMemBase,// shared mem
true,// thread can call Java
sessionId);// audio session ID
}
if (lpTrack->initCheck() != NO_ERROR) {
ALOGE("Error initializing AudioTrack");
goto native_init_failure;
}
nSession = (jint *) env->GetPrimitiveArrayCritical(jSession, NULL);
if (nSession == NULL) {
ALOGE("Error creating AudioTrack: Error retrieving session id pointer");
goto native_init_failure;
}
// read the audio session ID back from AudioTrack in case we create a new session
nSession[0] = lpTrack->getSessionId();
env->ReleasePrimitiveArrayCritical(jSession, nSession, 0);
nSession = NULL;
{ // scope for the lock
Mutex::Autolock l(sLock);
sAudioTrackCallBackCookies.add(&lpJniStorage->mCallbackData);
}
// save our newly created C++ AudioTrack in the "nativeTrackInJavaObj" field
// of the Java object (in mNativeTrackInJavaObj)
setAudioTrack(env, thiz, lpTrack);
// save the JNI resources so we can free them later
//ALOGV("storing lpJniStorage: %x\n", (int)lpJniStorage);
env->SetIntField(thiz, javaAudioTrackFields.jniData, (int)lpJniStorage);
return AUDIOTRACK_SUCCESS;
// failures:
native_init_failure:
if (nSession != NULL) {
env->ReleasePrimitiveArrayCritical(jSession, nSession, 0);
}
env->DeleteGlobalRef(lpJniStorage->mCallbackData.audioTrack_class);
env->DeleteGlobalRef(lpJniStorage->mCallbackData.audioTrack_ref);
delete lpJniStorage;
env->SetIntField(thiz, javaAudioTrackFields.jniData, 0);
return AUDIOTRACK_ERROR_SETUP_NATIVEINITFAILED;
}
-
检查音频參数; -
创建一个AudioTrack(native)对象; -
创建一个AudioTrackJniStorage对象。 -
调用set函数初始化AudioTrack。
buffersize = frameCount * 每帧数据量 = frameCount * (Channel数 * 每一个Channel数据量)
构造native AudioTrack
frameworks\av\media\libmedia\AudioTrack.cpp
AudioTrack::AudioTrack(): mStatus(NO_INIT),
mIsTimed(false),
mPreviousPriority(ANDROID_PRIORITY_NORMAL),
mPreviousSchedulingGroup(SP_DEFAULT),
mCblk(NULL)
{
}
构造AudioTrackJniStorage
AudioTrackJniStorage是音频数据存储的容器,是对匿名共享内存的封装。
初始化AudioTrack
为AudioTrack设置音频參数信息,在Android4.4中,添加了一个參数transfer_type用于指定音频数据的传输方式,Android4.4定义了4种音频传输数据方式:
enum transfer_type {
TRANSFER_DEFAULT, // not specified explicitly; determine from the other parameters
TRANSFER_CALLBACK, // callback EVENT_MORE_DATA
TRANSFER_OBTAIN, // FIXME deprecated: call obtainBuffer() and releaseBuffer()
TRANSFER_SYNC, // synchronous write()
TRANSFER_SHARED, // shared memory
};
/**
* 初始化AudioTrack
* @param streamType 音频流类型
* @param sampleRate 採样率
* @param format 音频格式
* @param channelMask 输出声道
* @param frameCount 帧数
* @param flags 输出标志位
* @param cbf Callback function. If not null, this function is called periodically
* to provide new data and inform of marker, position updates, etc.
* @param user Context for use by the callback receiver.
* @param notificationFrames The callback function is called each time notificationFrames * PCM frames have been consumed from track input buffer.
* @param sharedBuffer 共享内存
* @param threadCanCallJava
* @param sessionId
* @return
*/
status_t AudioTrack::set(
audio_stream_type_t streamType,
uint32_t sampleRate,
audio_format_t format,
audio_channel_mask_t channelMask,
int frameCountInt,
audio_output_flags_t flags,
callback_t cbf,
void* user,
int notificationFrames,
const sp& sharedBuffer,
bool threadCanCallJava,
int sessionId,
transfer_type transferType,
const audio_offload_info_t *offloadInfo,
int uid)
{
//设置音频传输数据类型
switch (transferType) {
case TRANSFER_DEFAULT:
if (sharedBuffer != 0) {
transferType = TRANSFER_SHARED;
} else if (cbf == NULL || threadCanCallJava) {
transferType = TRANSFER_SYNC;
} else {
transferType = TRANSFER_CALLBACK;
}
break;
case TRANSFER_CALLBACK:
if (cbf == NULL || sharedBuffer != 0) {
ALOGE("Transfer type TRANSFER_CALLBACK but cbf == NULL || sharedBuffer != 0");
return BAD_VALUE;
}
break;
case TRANSFER_OBTAIN:
case TRANSFER_SYNC:
if (sharedBuffer != 0) {
ALOGE("Transfer type TRANSFER_OBTAIN but sharedBuffer != 0");
return BAD_VALUE;
}
break;
case TRANSFER_SHARED:
if (sharedBuffer == 0) {
ALOGE("Transfer type TRANSFER_SHARED but sharedBuffer == 0");
return BAD_VALUE;
}
break;
default:
ALOGE("Invalid transfer type %d", transferType);
return BAD_VALUE;
}
mTransfer = transferType;
// FIXME "int" here is legacy and will be replaced by size_t later
if (frameCountInt < 0) {
ALOGE("Invalid frame count %d", frameCountInt);
return BAD_VALUE;
}
size_t frameCount = frameCountInt;
ALOGV_IF(sharedBuffer != 0, "sharedBuffer: %p, size: %d", sharedBuffer->pointer(),
sharedBuffer->size());
ALOGV("set() streamType %d frameCount %u flags %04x", streamType, frameCount, flags);
AutoMutex lock(mLock);
// invariant that mAudioTrack != 0 is true only after set() returns successfully
if (mAudioTrack != 0) {
ALOGE("Track already in use");
return INVALID_OPERATION;
}
mOutput = 0;
// 音频流类型设置
if (streamType == AUDIO_STREAM_DEFAULT) {
streamType = AUDIO_STREAM_MUSIC;
}
//依据音频流类型从AudioPolicyService中得到相应的音频採样率
if (sampleRate == 0) {
uint32_t afSampleRate;
if (AudioSystem::getOutputSamplingRate(&afSampleRate, streamType) != NO_ERROR) {
return NO_INIT;
}
sampleRate = afSampleRate;
}
mSampleRate = sampleRate;
//音频格式设置
if (format == AUDIO_FORMAT_DEFAULT) {
format = AUDIO_FORMAT_PCM_16_BIT;
}
//假设没有设置声道,则默认设置为立体声通道
if (channelMask == 0) {
channelMask = AUDIO_CHANNEL_OUT_STEREO;
}
// validate parameters
if (!audio_is_valid_format(format)) {
ALOGE("Invalid format %d", format);
return BAD_VALUE;
}
// AudioFlinger does not currently support 8-bit data in shared memory
if (format == AUDIO_FORMAT_PCM_8_BIT && sharedBuffer != 0) {
ALOGE("8-bit data in shared memory is not supported");
return BAD_VALUE;
}
// force direct flag if format is not linear PCM
// or offload was requested
if ((flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD)
|| !audio_is_linear_pcm(format)) {
ALOGV( (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD)
?
"Offload request, forcing to Direct Output"
: "Not linear PCM, forcing to Direct Output");
flags = (audio_output_flags_t)
// FIXME why can't we allow direct AND fast?
((flags | AUDIO_OUTPUT_FLAG_DIRECT) & ~AUDIO_OUTPUT_FLAG_FAST);
}
// only allow deep buffering for music stream type
if (streamType != AUDIO_STREAM_MUSIC) {
flags = (audio_output_flags_t)(flags &~AUDIO_OUTPUT_FLAG_DEEP_BUFFER);
}
//输出声道合法性检查
if (!audio_is_output_channel(channelMask)) {
ALOGE("Invalid channel mask %#x", channelMask);
return BAD_VALUE;
}
mChannelMask = channelMask;
//计算声道个数
uint32_t channelCount = popcount(channelMask);
mChannelCount = channelCount;
if (audio_is_linear_pcm(format)) {
mFrameSize = channelCount * audio_bytes_per_sample(format);
mFrameSizeAF = channelCount * sizeof(int16_t);
} else {
mFrameSize = sizeof(uint8_t);
mFrameSizeAF = sizeof(uint8_t);
}
/**
* audio_io_handle_t是一个整形值,用于标示音频播放线程,这里更加音频參数
* 从AudioFlinger中查找用于播放此音频的播放线程。并返回该播放线程的ID值
*/
audio_io_handle_t output = AudioSystem::getOutput(
streamType,
sampleRate, format, channelMask,
flags,
offloadInfo);
if (output == 0) {
ALOGE("Could not get audio output for stream type %d", streamType);
return BAD_VALUE;
}
//AudioTrack初始化
mVolume[LEFT] = 1.0f;
mVolume[RIGHT] = 1.0f;
mSendLevel = 0.0f;
mFrameCount = frameCount;
mReqFrameCount = frameCount;
mNotificationFramesReq = notificationFrames;
mNotificationFramesAct = 0;
mSessionId = sessionId;
if (uid == -1 || (IPCThreadState::self()->getCallingPid() != getpid())) {
mClientUid = IPCThreadState::self()->getCallingUid();
} else {
mClientUid = uid;
}
mAuxEffectId = 0;
mFlags = flags;
mCbf = cbf;
//假设设置了提供音频数据的回调函数,则启动AudioTrackThread线程来提供音频数据
if (cbf != NULL) {
mAudioTrackThread = new AudioTrackThread(*this, threadCanCallJava);
mAudioTrackThread->run("AudioTrack", ANDROID_PRIORITY_AUDIO, 0 /*stack*/);
}
// create the IAudioTrack
status_t status = createTrack_l(streamType,
sampleRate,
format,
frameCount,
flags,
sharedBuffer,
output,
0 /*epoch*/);
if (status != NO_ERROR) {
if (mAudioTrackThread != 0) {
mAudioTrackThread->requestExit(); // see comment in AudioTrack.h
mAudioTrackThread->requestExitAndWait();
mAudioTrackThread.clear();
}
//Use of direct and offloaded output streams is ref counted by audio policy manager.
// As getOutput was called above and resulted in an output stream to be opened,
// we need to release it.
AudioSystem::releaseOutput(output);
return status;
}
mStatus = NO_ERROR;
mStreamType = streamType;
mFormat = format;
mSharedBuffer = sharedBuffer;
mState = STATE_STOPPED;
mUserData = user;
mLoopPeriod = 0;
mMarkerPosition = 0;
mMarkerReached = false;
mNewPosition = 0;
mUpdatePeriod = 0;
AudioSystem::acquireAudioSessionId(mSessionId);
mSequence = 1;
mObservedSequence = mSequence;
mInUnderrun = false;
mOutput = output;
return NO_ERROR;
}
a) AudioPolicyService启动时载入了系统支持的全部音频接口。而且打开了默认的音频输出。打开音频输出时,调用AudioFlinger::openOutput()函数为当前打开的音频输出接口output创建一个PlaybackThread线程,同时为该线程分配一个全局唯一的audio_io_handle_t值,并以键值对的形式保存在AudioFlinger的成员变量mPlaybackThreads中。在这里首先依据音频參数通过调用AudioSystem::getOutput()函数得到当前音频输出接口的PlaybackThread线程id号。同时传递给createTrack函数用于创建Track。
b) AudioTrack在AudioFlinger中是以Track来管理的。不过由于它们之间是跨进程的关系,因此须要一个“桥梁”来维护,这个沟通的媒介是IAudioTrack。函数createTrack_l除了为AudioTrack在AudioFlinger中申请一个Track外。还会建立两者间IAudioTrack桥梁。
c) 获取音频输出就是依据音频參数如采样率、声道、格式等从已经打开的音频输出描述符列表中查找合适的音频输出AudioOutputDescriptor,并返回该音频输出在AudioFlinger中创建的播放线程id号,假设没有合适当前音频输出參数的AudioOutputDescriptor。则请求AudioFlinger打开一个新的音频输出通道,并为当前音频输出创建相应的播放线程,返回该播放线程的id号。详细过程请參考Android AudioPolicyService服务启动过程中的打开输出小节。
创建AudioTrackThread线程
初始化AudioTrack时,假设audioCallback为Null,就会创建AudioTrackThread线程。
AudioTrack支持两种数据输入方式:
1) Push方式:用户主动write,MediaPlayerService通常採用此方式;
2) Pull方式: AudioTrackThread线程通过audioCallback回调函数主动从用户那里获取数据。ToneGenerator就是採用这样的方式。
bool AudioTrack::AudioTrackThread::threadLoop()
{
{
AutoMutex _l(mMyLock);
if (mPaused) {
mMyCond.wait(mMyLock);
// caller will check for exitPending()
return true;
}
}
//调用创建当前AudioTrackThread线程的AudioTrack的processAudioBuffer函数
if (!mReceiver.processAudioBuffer(this)) {
pause();
}
return true;
}
申请Track
音频播放须要AudioTrack写入音频数据,同一时候须要AudioFlinger混音,因此需要在AudioTrack与AudioFlinger之间建立数据通道,而AudioTrack与AudioFlinger又分属不同的进程空间,Android系统採用Binder通信方式来搭建它们之间的桥梁。
status_t AudioTrack::createTrack_l(
audio_stream_type_t streamType,
uint32_t sampleRate,
audio_format_t format,
size_t frameCount,
audio_output_flags_t flags,
const sp& sharedBuffer,
audio_io_handle_t output,
size_t epoch)
{
status_t status;
//得到AudioFlinger的代理对象
const sp& audioFlinger = AudioSystem::get_audio_flinger();
if (audioFlinger == 0) {
ALOGE("Could not get audioflinger");
return NO_INIT;
}
//得到输出时延
uint32_t afLatency;
status = AudioSystem::getLatency(output, streamType, &afLatency);
if (status != NO_ERROR) {
ALOGE("getLatency(%d) failed status %d", output, status);
return NO_INIT;
}
//得到音频帧数
size_t afFrameCount;
status = AudioSystem::getFrameCount(output, streamType, &afFrameCount);
if (status != NO_ERROR) {
ALOGE("getFrameCount(output=%d, streamType=%d) status %d", output, streamType, status);
return NO_INIT;
}
//得到採样率
uint32_t afSampleRate;
status = AudioSystem::getSamplingRate(output, streamType, &afSampleRate);
if (status != NO_ERROR) {
ALOGE("getSamplingRate(output=%d, streamType=%d) status %d", output, streamType, status);
return NO_INIT;
}
// Client decides whether the track is TIMED (see below), but can only express a preference
// for FAST. Server will perform additional tests.
if ((flags & AUDIO_OUTPUT_FLAG_FAST) && !(
// either of these use cases:
// use case 1: shared buffer
(sharedBuffer != 0) ||
// use case 2: callback handler
(mCbf != NULL))) {
ALOGW("AUDIO_OUTPUT_FLAG_FAST denied by client");
// once denied, do not request again if IAudioTrack is re-created
flags = (audio_output_flags_t) (flags & ~AUDIO_OUTPUT_FLAG_FAST);
mFlags = flags;
}
ALOGV("createTrack_l() output %d afLatency %d", output, afLatency);
// The client's AudioTrack buffer is divided into n parts for purpose of wakeup by server, where
// n = 1 fast track; nBuffering is ignored
// n = 2 normal track, no sample rate conversion
// n = 3 normal track, with sample rate conversion
// (pessimistic; some non-1:1 conversion ratios don't actually need triple-buffering)
// n > 3 very high latency or very small notification interval; nBuffering is ignored
const uint32_t nBuffering = (sampleRate == afSampleRate) ? 2 : 3;
mNotificationFramesAct = mNotificationFramesReq;
if (!audio_is_linear_pcm(format)) {
if (sharedBuffer != 0) {//static模式
// Same comment as below about ignoring frameCount parameter for set()
frameCount = sharedBuffer->size();
} else if (frameCount == 0) {
frameCount = afFrameCount;
}
if (mNotificationFramesAct != frameCount) {
mNotificationFramesAct = frameCount;
}
} else if (sharedBuffer != 0) {// static模式
// Ensure that buffer alignment matches channel count
// 8-bit data in shared memory is not currently supported by AudioFlinger
size_t alignment = /* format == AUDIO_FORMAT_PCM_8_BIT ? 1 : */ 2;
if (mChannelCount > 1) {
// More than 2 channels does not require stronger alignment than stereo
alignment <<= 1;
}
if (((size_t)sharedBuffer->pointer() & (alignment - 1)) != 0) {
ALOGE("Invalid buffer alignment: address %p, channel count %u",
sharedBuffer->pointer(), mChannelCount);
return BAD_VALUE;
}
// When initializing a shared buffer AudioTrack via constructors,
// there's no frameCount parameter.
// But when initializing a shared buffer AudioTrack via set(),
// there _is_ a frameCount parameter. We silently ignore it.
frameCount = sharedBuffer->size()/mChannelCount/sizeof(int16_t);
} else if (!(flags & AUDIO_OUTPUT_FLAG_FAST)) {
// FIXME move these calculations and associated checks to server
// Ensure that buffer depth covers at least audio hardware latency
uint32_t minBufCount = afLatency / ((1000 * afFrameCount)/afSampleRate);
ALOGV("afFrameCount=%d, minBufCount=%d, afSampleRate=%u, afLatency=%d",
afFrameCount, minBufCount, afSampleRate, afLatency);
if (minBufCount <= nBuffering) {
minBufCount = nBuffering;
}
size_t minFrameCount = (afFrameCount*sampleRate*minBufCount)/afSampleRate;
ALOGV("minFrameCount: %u, afFrameCount=%d, minBufCount=%d, sampleRate=%u, afSampleRate=%u"", afLatency=%d",minFrameCount, afFrameCount, minBufCount, sampleRate, afSampleRate, afLatency);
if (frameCount == 0) {
frameCount = minFrameCount;
} else if (frameCount < minFrameCount) {
// not ALOGW because it happens all the time when playing key clicks over A2DP
ALOGV("Minimum buffer size corrected from %d to %d",
frameCount, minFrameCount);
frameCount = minFrameCount;
}
// Make sure that application is notified with sufficient margin before underrun
if (mNotificationFramesAct == 0 || mNotificationFramesAct > frameCount/nBuffering) {
mNotificationFramesAct = frameCount/nBuffering;
}
} else {
// For fast tracks, the frame count calculations and checks are done by server
}
IAudioFlinger::track_flags_t trackFlags = IAudioFlinger::TRACK_DEFAULT;
if (mIsTimed) {
trackFlags |= IAudioFlinger::TRACK_TIMED;
}
pid_t tid = -1;
if (flags & AUDIO_OUTPUT_FLAG_FAST) {
trackFlags |= IAudioFlinger::TRACK_FAST;
if (mAudioTrackThread != 0) {
tid = mAudioTrackThread->getTid();
}
}
if (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) {
trackFlags |= IAudioFlinger::TRACK_OFFLOAD;
}
//向AudioFlinger发送createTrack请求,在stream模式下sharedBuffer为空,output为AudioFlinger中播放线程的id号
sp track = audioFlinger->createTrack(streamType,
sampleRate,
// AudioFlinger only sees 16-bit PCM
format == AUDIO_FORMAT_PCM_8_BIT ?
AUDIO_FORMAT_PCM_16_BIT : format,
mChannelMask,
frameCount,
&trackFlags,
sharedBuffer,
output,
tid,
&mSessionId,
mName,
mClientUid,
&status);
if (track == 0) {
ALOGE("AudioFlinger could not create track, status: %d", status);
return status;
}
//AudioFlinger创建Tack对象时会分配一块共享内存,这里得到这块共享内存的代理对象BpMemory
sp iMem = track->getCblk();
if (iMem == 0) {
ALOGE("Could not get control block");
return NO_INIT;
}
// invariant that mAudioTrack != 0 is true only after set() returns successfully
if (mAudioTrack != 0) {
mAudioTrack->asBinder()->unlinkToDeath(mDeathNotifier, this);
mDeathNotifier.clear();
}
//将创建的Track代理对象、匿名共享内存代理对象保存到AudioTrack的成员变量中
mAudioTrack = track;
mCblkMemory = iMem;
//保存匿名共享内存的首地址。在匿名共享内存的头部存放了一个audio_track_cblk_t对象
audio_track_cblk_t* cblk = static_cast(iMem->pointer());
mCblk = cblk;
size_t temp = cblk->frameCount_;
if (temp < frameCount || (frameCount == 0 && temp == 0)) {
// In current design, AudioTrack client checks and ensures frame count validity before
// passing it to AudioFlinger so AudioFlinger should not return a different value except
// for fast track as it uses a special method of assigning frame count.
ALOGW("Requested frameCount %u but received frameCount %u", frameCount, temp);
}
frameCount = temp;
mAwaitBoost = false;
if (flags & AUDIO_OUTPUT_FLAG_FAST) {
if (trackFlags & IAudioFlinger::TRACK_FAST) {
ALOGV("AUDIO_OUTPUT_FLAG_FAST successful; frameCount %u", frameCount);
mAwaitBoost = true;
if (sharedBuffer == 0) {
// double-buffering is not required for fast tracks, due to tighter scheduling
if (mNotificationFramesAct == 0 || mNotificationFramesAct > frameCount) {
mNotificationFramesAct = frameCount;
}
}
} else {
ALOGV("AUDIO_OUTPUT_FLAG_FAST denied by server; frameCount %u", frameCount);
// once denied, do not request again if IAudioTrack is re-created
flags = (audio_output_flags_t) (flags & ~AUDIO_OUTPUT_FLAG_FAST);
mFlags = flags;
if (sharedBuffer == 0) {//stream模式
if (mNotificationFramesAct == 0 || mNotificationFramesAct > frameCount/nBuffering) {
mNotificationFramesAct = frameCount/nBuffering;
}
}
}
}
if (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) {
if (trackFlags & IAudioFlinger::TRACK_OFFLOAD) {
ALOGV("AUDIO_OUTPUT_FLAG_OFFLOAD successful");
} else {
ALOGW("AUDIO_OUTPUT_FLAG_OFFLOAD denied by server");
flags = (audio_output_flags_t) (flags & ~AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD);
mFlags = flags;
return NO_INIT;
}
}
mRefreshRemaining = true;
// Starting address of buffers in shared memory. If there is a shared buffer, buffers
// is the value of pointer() for the shared buffer, otherwise buffers points
// immediately after the control block. This address is for the mapping within client
// address space. AudioFlinger::TrackBase::mBuffer is for the server address space.
void* buffers;
if (sharedBuffer == 0) {//stream模式
buffers = (char*)cblk + sizeof(audio_track_cblk_t);
} else {
buffers = sharedBuffer->pointer();
}
mAudioTrack->attachAuxEffect(mAuxEffectId);
// FIXME don't believe this lie
mLatency = afLatency + (1000*frameCount) / sampleRate;
mFrameCount = frameCount;
// If IAudioTrack is re-created, don't let the requested frameCount
// decrease. This can confuse clients that cache frameCount().
if (frameCount > mReqFrameCount) {
mReqFrameCount = frameCount;
}
// update proxy
if (sharedBuffer == 0) {
mStaticProxy.clear();
mProxy = new AudioTrackClientProxy(cblk, buffers, frameCount, mFrameSizeAF);
} else {
mStaticProxy = new StaticAudioTrackClientProxy(cblk, buffers, frameCount, mFrameSizeAF);
mProxy = mStaticProxy;
}
mProxy->setVolumeLR((uint32_t(uint16_t(mVolume[RIGHT] * 0x1000)) << 16) |
uint16_t(mVolume[LEFT] * 0x1000));
mProxy->setSendLevel(mSendLevel);
mProxy->setSampleRate(mSampleRate);
mProxy->setEpoch(epoch);
mProxy->setMinimum(mNotificationFramesAct);
mDeathNotifier = new DeathNotifier(this);
mAudioTrack->asBinder()->linkToDeath(mDeathNotifier, this);
return NO_ERROR;
}
IAudioTrack建立了AudioTrack与AudioFlinger之间的关系,在static模式下,用于存放音频数据的匿名共享内存在AudioTrack这边创建。在stream播放模式下,匿名共享内存却是在AudioFlinger这边创建。这两种播放模式下创建的匿名共享内存是有差别的,stream模式下的匿名共享内存头部会创建一个audio_track_cblk_t对象,用于协调生产者AudioTrack和消费者AudioFlinger之间的步调。createTrack就是在AudioFlinger中创建一个Track对象。
frameworks\av\services\audioflinger\ AudioFlinger.cpp
sp AudioFlinger::createTrack(
audio_stream_type_t streamType,
uint32_t sampleRate,
audio_format_t format,
audio_channel_mask_t channelMask,
size_t frameCount,
IAudioFlinger::track_flags_t *flags,
const sp& sharedBuffer,
audio_io_handle_t output,
pid_t tid,
int *sessionId,
String8& name,
int clientUid,
status_t *status)
{
sp track;
sp trackHandle;
sp client;
status_t lStatus;
int lSessionId;
// client AudioTrack::set already implements AUDIO_STREAM_DEFAULT => AUDIO_STREAM_MUSIC,
// but if someone uses binder directly they could bypass that and cause us to crash
if (uint32_t(streamType) >= AUDIO_STREAM_CNT) {
ALOGE("createTrack() invalid stream type %d", streamType);
lStatus = BAD_VALUE;
goto Exit;
}
// client is responsible for conversion of 8-bit PCM to 16-bit PCM,
// and we don't yet support 8.24 or 32-bit PCM
if (audio_is_linear_pcm(format) && format != AUDIO_FORMAT_PCM_16_BIT) {
ALOGE("createTrack() invalid format %d", format);
lStatus = BAD_VALUE;
goto Exit;
}
{
Mutex::Autolock _l(mLock);
//依据播放线程ID号查找出相应的PlaybackThread,在openOutput时,
//播放线程以key/value形式保存在AudioFlinger的mPlaybackThreads中
PlaybackThread *thread = checkPlaybackThread_l(output);
PlaybackThread *effectThread = NULL;
if (thread == NULL) {
ALOGE("no playback thread found for output handle %d", output);
lStatus = BAD_VALUE;
goto Exit;
}
pid_t pid = IPCThreadState::self()->getCallingPid();
//依据客户端进程pid查找是否已经为该客户进程创建了Client对象。假设没有,则创建一个Client对象
client = registerPid_l(pid);
ALOGV("createTrack() sessionId: %d", (sessionId == NULL) ?
-2 : *sessionId);
if (sessionId != NULL && *sessionId != AUDIO_SESSION_OUTPUT_MIX) {
// check if an effect chain with the same session ID is present on another
// output thread and move it here.
//遍历全部的播放线程。不包含输出线程,假设该线程中Track的sessionId与当前同样,则取出该线程作为当前Track的effectThread。
for (size_t i = 0; i < mPlaybackThreads.size(); i++) {
sp t = mPlaybackThreads.valueAt(i);
if (mPlaybackThreads.keyAt(i) != output) {
uint32_t sessions = t->hasAudioSession(*sessionId);
if (sessions & PlaybackThread::EFFECT_SESSION) {
effectThread = t.get();
break;
}
}
}
lSessionId = *sessionId;
} else {
// if no audio session id is provided, create one here
lSessionId = nextUniqueId();
if (sessionId != NULL) {
*sessionId = lSessionId;
}
}
ALOGV("createTrack() lSessionId: %d", lSessionId);
//在找到的PlaybackThread线程中创建Track
track = thread->createTrack_l(client, streamType, sampleRate, format,
channelMask, frameCount, sharedBuffer, lSessionId, flags, tid, clientUid, &lStatus);
// move effect chain to this output thread if an effect on same session was waiting
// for a track to be created
if (lStatus == NO_ERROR && effectThread != NULL) {
Mutex::Autolock _dl(thread->mLock);
Mutex::Autolock _sl(effectThread->mLock);
moveEffectChain_l(lSessionId, effectThread, thread, true);
}
// Look for sync events awaiting for a session to be used.
for (int i = 0; i < (int)mPendingSyncEvents.size(); i++) {
if (mPendingSyncEvents[i]->triggerSession() == lSessionId) {
if (thread->isValidSyncEvent(mPendingSyncEvents[i])) {
if (lStatus == NO_ERROR) {
(void) track->setSyncEvent(mPendingSyncEvents[i]);
} else {
mPendingSyncEvents[i]->cancel();
}
mPendingSyncEvents.removeAt(i);
i--;
}
}
}
}
//此时Track已成功创建,还须要为该Track创建代理对象TrackHandle
if (lStatus == NO_ERROR) {
// s for server's pid, n for normal mixer name, f for fast index
name = String8::format("s:%d;n:%d;f:%d", getpid_cached, track->name() - AudioMixer::TRACK0,track->fastIndex());
trackHandle = new TrackHandle(track);
} else {
// remove local strong reference to Client before deleting the Track so that the Client destructor is called by the TrackBase destructor with mLock held
client.clear();
track.clear();
}
Exit:
if (status != NULL) {
*status = lStatus;
}
/**
* 向客户进程返回IAudioTrack的代理对象,这样客户进程就能够跨进程訪问创建的Track了,
* 訪问方式例如以下:BpAudioTrack --> BnAudioTrack --> TrackHandle --> Track
*/
return trackHandle;
}
该函数首先以单例模式为应用程序进程创建一个Client对象,直接对话某个客户进程。然后依据播放线程ID找出相应的PlaybackThread。并将创建Track的任务转交给它,PlaybackThread完成Track创建后,因为Track没有通信功能,因此还需要为其创建一个代理通信业务的TrackHandle对象。

构造Client对象
依据进程pid。为请求播放音频的client创建一个Client对象。
sp AudioFlinger::registerPid_l(pid_t pid)
{
// If pid is already in the mClients wp<> map, then use that entry
// (for which promote() is always != 0), otherwise create a new entry and Client.
sp client = mClients.valueFor(pid).promote();
if (client == 0) {
client = new Client(this, pid);
mClients.add(pid, client);
}
return client;
}
AudioFlinger的成员变量mClients以键值对的形式保存pid和Client对象。这里首先取出pid相应的Client对象,假设该对象为空。则为client进程创建一个新的Client对象。
AudioFlinger::Client::Client(const sp& audioFlinger, pid_t pid)
: RefBase(),mAudioFlinger(audioFlinger),
// FIXME should be a "k" constant not hard-coded, in .h or ro. property, see 4 lines below
mMemoryDealer(new MemoryDealer(2*1024*1024, "AudioFlinger::Client")),
mPid(pid),
mTimedTrackCount(0)
{
// 1 MB of address space is good for 32 tracks, 8 buffers each, 4 KB/buffer
}
构造Client对象时。创建了一个MemoryDealer对象,该对象用于分配共享内存。
MemoryDealer是个工具类。用于分配共享内存。每个Client都拥有一个MemoryDealer对象,这就意味着每个client进程都是在自己独有的内存空间中分配共享内存。MemoryDealer构造时创建了一个大小为2 * 1024 * 1024的匿名共享内存,该客户进程所有的AudioTrack在AudioFlinger中创建的Track都是在这块共享内存中分配buffer。
由此可知。当应用程序进程中的AudioTrack请求AudioFlinger在某个PlaybackThread中创建Track对象时,AudioFlinger首先会为应用程序进程创建一个Client对象,同一时候创建一块大小为2M的共享内存。在创建Track时,Track将在2M共享内存中分配buffer用于音频播放。

创建Track对象
sp AudioFlinger::PlaybackThread::createTrack_l(
const sp& client,
audio_stream_type_t streamType,
uint32_t sampleRate,
audio_format_t format,
audio_channel_mask_t channelMask,
size_t frameCount,
const sp& sharedBuffer,
int sessionId,
IAudioFlinger::track_flags_t *flags,
pid_t tid,
int uid,
status_t *status)
{
sp 这里就为AudioTrack创建了一个Track对象。Track继承于TrackBase,因此构造Track时,首先运行TrackBase的构造函数。
AudioFlinger::ThreadBase::TrackBase::TrackBase(
ThreadBase *thread,//所属的播放线程
const sp& client,//所属的Client
uint32_t sampleRate,//採样率
audio_format_t format,//音频格式
audio_channel_mask_t channelMask,//声道
size_t frameCount,//音频帧个数
const sp& sharedBuffer,//共享内存
int sessionId,
int clientUid,
bool isOut)
: RefBase(),
mThread(thread),
mClient(client),
mCblk(NULL),
// mBuffer
mState(IDLE),
mSampleRate(sampleRate),
mFormat(format),
mChannelMask(channelMask),
mChannelCount(popcount(channelMask)),
mFrameSize(audio_is_linear_pcm(format) ?
mChannelCount * audio_bytes_per_sample(format) : sizeof(int8_t)),
mFrameCount(frameCount),
mSessionId(sessionId),
mIsOut(isOut),
mServerProxy(NULL),
mId(android_atomic_inc(&nextTrackId)),
mTerminated(false)
{
// if the caller is us, trust the specified uid
if (IPCThreadState::self()->getCallingPid() != getpid_cached || clientUid == -1) {
int newclientUid = IPCThreadState::self()->getCallingUid();
if (clientUid != -1 && clientUid != newclientUid) {
ALOGW("uid %d tried to pass itself off as %d", newclientUid, clientUid);
}
clientUid = newclientUid;
}
// clientUid contains the uid of the app that is responsible for this track, so we can blame
//得到应用进程uid
mUid = clientUid;
// client == 0 implies sharedBuffer == 0
ALOG_ASSERT(!(client == 0 && sharedBuffer != 0));
ALOGV_IF(sharedBuffer != 0, "sharedBuffer: %p, size: %d", sharedBuffer->pointer(),
sharedBuffer->size());
//计算audio_track_cblk_t大小
size_t size = sizeof(audio_track_cblk_t);
//计算存放音频数据的buffer大小。= frameCount*mFrameSize
size_t bufferSize = (sharedBuffer == 0 ? roundup(frameCount) : frameCount) * mFrameSize;
/**
* stream模式下,须要audio_track_cblk_t来协调生成者和消费者。计算共享内存大小
* --------------------------------------------------------
* | audio_track_cblk_t | buffer |
* --------------------------------------------------------
*/
if (sharedBuffer == 0) {//stream模式下
size += bufferSize;
}
//假设Client不为空。就通过Client来分配buffer
if (client != 0) {
//请求Client中的MemoryDealer工具类来分配buffer
mCblkMemory = client->heap()->allocate(size);
//分配成功
if (mCblkMemory != 0) {
//将共享内存的指针强制转换为audio_track_cblk_t
mCblk = static_cast(mCblkMemory->pointer());
// can't assume mCblk != NULL
} else {
ALOGE("not enough memory for AudioTrack size=%u", size);
client->heap()->dump("AudioTrack");
return;
}
} else {//Client为空,使用数组方式分配内存空间
// this syntax avoids calling the audio_track_cblk_t constructor twice
mCblk = (audio_track_cblk_t *) new uint8_t[size];
// assume mCblk != NULL
}
/**
* 当为应用进程创建了Client对象。则通过Client来分配音频数据buffer,否则通过数组方式分配buffer。
* stream模式下,在分配好的buffer头部创建audio_track_cblk_t对象。而static模式下。创建单独的
* audio_track_cblk_t对象。
*/
if (mCblk != NULL) {
// construct the shared structure in-place.
new(mCblk) audio_track_cblk_t();
// clear all buffers
mCblk->frameCount_ = frameCount;
if (sharedBuffer == 0) {//stream模式
//将mBuffer指向数据buffer的首地址
mBuffer = (char*)mCblk + sizeof(audio_track_cblk_t);
//清空数据buffer
memset(mBuffer, 0, bufferSize);
} else {//static模式
mBuffer = sharedBuffer->pointer();
#if 0
mCblk->mFlags = CBLK_FORCEREADY; // FIXME hack, need to fix the track ready logic
#endif
}
#ifdef TEE_SINK
…
#endif
ALOGD("TrackBase constructed"); // SPRD: add some log
}
}
TrackBase构造过程主要是为音频播放分配共享内存,在static模式下,共享内存由应用进程自身分配,但在stream模式,共享内存由AudioFlinger分配,static和stream模式下,都会创建audio_track_cblk_t对象,唯一的差别在于,在stream模式下。audio_track_cblk_t对象创建在共享内存的头部。
static模式:

stream模式:

接下来继续分析Track的构造过程:
AudioFlinger::PlaybackThread::Track::Track(
PlaybackThread *thread, //所属的播放线程
const sp& client, //所属的Client
audio_stream_type_t streamType,//音频流类型
uint32_t sampleRate, //採样率
audio_format_t format, //音频格式
audio_channel_mask_t channelMask, //声道
size_t frameCount, //音频帧个数
const sp& sharedBuffer, //共享内存
int sessionId,
int uid,
IAudioFlinger::track_flags_t flags)
: TrackBase(thread, client, sampleRate, format, channelMask, frameCount, sharedBuffer,sessionId, uid, true /isOut/),
mFillingUpStatus(FS_INVALID),
// mRetryCount initialized later when needed
mSharedBuffer(sharedBuffer),
mStreamType(streamType),
mName(-1), // see note below
mMainBuffer(thread->mixBuffer()),
mAuxBuffer(NULL),
mAuxEffectId(0), mHasVolumeController(false),
mPresentationCompleteFrames(0),
mFlags(flags),
mFastIndex(-1),
mCachedVolume(1.0),
mIsInvalid(false),
mAudioTrackServerProxy(NULL),
mResumeToStopping(false)
{
if (mCblk != NULL) {//audio_track_cblk_t对象不为空
if (sharedBuffer == 0) {//stream模式
mAudioTrackServerProxy = new AudioTrackServerProxy(mCblk, mBuffer, frameCount,
mFrameSize);
} else {//static模式
mAudioTrackServerProxy = new StaticAudioTrackServerProxy(mCblk, mBuffer, frameCount,mFrameSize);
}
mServerProxy = mAudioTrackServerProxy;
// to avoid leaking a track name, do not allocate one unless there is an mCblk
mName = thread->getTrackName_l(channelMask, sessionId);
if (mName < 0) {
ALOGE(“no more track names available”);
return;
}
// only allocate a fast track index if we were able to allocate a normal track name
if (flags & IAudioFlinger::TRACK_FAST) {
mAudioTrackServerProxy->framesReadyIsCalledByMultipleThreads();
ALOG_ASSERT(thread->mFastTrackAvailMask != 0);
int i = __builtin_ctz(thread->mFastTrackAvailMask);
ALOG_ASSERT(0 < i && i < (int)FastMixerState::kMaxFastTracks);
// FIXME This is too eager. We allocate a fast track index before the
// fast track becomes active. Since fast tracks are a scarce resource,
// this means we are potentially denying other more important fast tracks
// from being created. It would be better to allocate the index dynamically.
mFastIndex = i;
// Read the initial underruns because this field is never cleared by the fast mixer
mObservedUnderruns = thread->getFastTrackUnderruns(i);
thread->mFastTrackAvailMask &= ~(1 << i);
}
}
ALOGV(“Track constructor name %d, calling pid %d”, mName,
IPCThreadState::self()->getCallingPid());
}
在TrackBase的构造过程中依据是否创建Client对象来採取不同方式分配audio_track_cblk_t对象内存空间,而且创建audio_track_cblk_t对象。在Track构造中。依据不同的播放模式,创建不同的代理对象:
Stream模式下。创建AudioTrackServerProxy代理对象;
Static模式下,创建StaticAudioTrackServerProxy代理对象;

在stream模式下,同一时候分配指定大小的音频数据buffer ,该buffer的结构例如以下所看到的:

我们知道在构造Client对象时,创建了一个内存分配工具对象MemoryDealer,同一时候创建了一块大小为2M的匿名共享内存。这里就是使用MemoryDealer对象在这块匿名共享内存上分配指定大小的buffer。
frameworks\native\libs\binder\MemoryDealer.cpp
sp MemoryDealer::allocate(size_t size)
{
sp memory;
//分配size大小的共享内存,并返回该buffer的偏移量
const ssize_t offset = allocator()->allocate(size);
if (offset >= 0) {
//将分配的buffer封装为Allocation对象
memory = new Allocation(this, heap(), offset, size);
}
return memory;
}
size_t SimpleBestFitAllocator::allocate(size_t size, uint32_t flags)
{
Mutex::Autolock _l(mLock);
ssize_t offset = alloc(size, flags);
return offset;
}
ssize_t SimpleBestFitAllocator::alloc(size_t size, uint32_t flags)
{
if (size == 0) {
return 0;
}
size = (size + kMemoryAlign-1) / kMemoryAlign;
chunk_t* free_chunk = 0;
chunk_t* cur = mList.head();
size_t pagesize = getpagesize();
while (cur) {
int extra = 0;
if (flags & PAGE_ALIGNED)
extra = ( -cur->start & ((pagesize/kMemoryAlign)-1) ) ;
// best fit
if (cur->free && (cur->size >= (size+extra))) {
if ((!free_chunk) || (cur->size < free_chunk->size)) {
free_chunk = cur;
}
if (cur->size == size) {
break;
}
}
cur = cur->next;
}
if (free_chunk) {
const size_t free_size = free_chunk->size;
free_chunk->free = 0;
free_chunk->size = size;
if (free_size > size) {
int extra = 0;
if (flags & PAGE_ALIGNED)
extra = ( -free_chunk->start & ((pagesize/kMemoryAlign)-1) ) ;
if (extra) {
chunk_t* split = new chunk_t(free_chunk->start, extra);
free_chunk->start += extra;
mList.insertBefore(free_chunk, split);
}
ALOGE_IF((flags&PAGE_ALIGNED) &&
((free_chunk->startkMemoryAlign)&(pagesize-1)),
“PAGE_ALIGNED requested, but page is not aligned!!!”);
const ssize_t tail_free = free_size - (size+extra);
if (tail_free > 0) {
chunk_t split = new chunk_t(
free_chunk->start + free_chunk->size, tail_free);
mList.insertAfter(free_chunk, split);
}
}
return (free_chunk->start)*kMemoryAlign;
}
return NO_MEMORY;
}
audio_track_cblk_t对象用于协调生产者AudioTrack和消费者AudioFlinger之间的步调。

在createTrack时由AudioFlinger申请对应的内存,然后通过IMemory接口返回AudioTrack,这样AudioTrack和AudioFlinger管理着同一个audio_track_cblk_t,通过它实现了环形FIFO。AudioTrack向FIFO中写入音频数据,AudioFlinger从FIFO中读取音频数据,经Mixer后送给AudioHardware进行播放。
-
AudioTrack是FIFO的数据生产者; -
AudioFlinger是FIFO的数据消费者;
构造TrackHandle
Track对象仅仅负责音频相关业务,对外并没有提供夸进程的Binder调用接口,因此须要将通信业务托付给另外一个对象来完毕。这就是TrackHandle存在的意义,TrackHandle负责代理Track的通信业务。它是Track与AudioTrack之间的跨进程通道。
AudioFlinger拥有多个工作线程(playbackThread),每一个线程拥有多个Track。播放线程实际上是MixerThread的实例。MixerThread的threadLoop()中。会把该线程中的各个Track进行混合,必要时还要进行ReSample(重採样)的动作,转换为统一的採样率(44.1K)。然后通过音频系统的AudioHardware层输出音频数据。
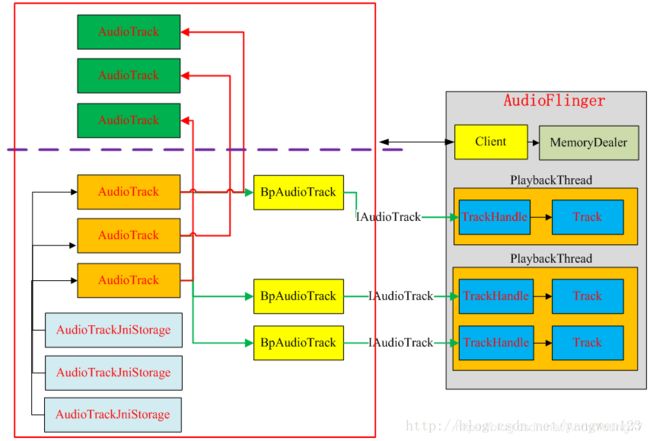
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
Ø Framework或者Java层通过JNI创建AudioTrack对象;
Ø 依据StreamType等參数,查找已打开的音频输出设备。假设查找不到匹配的音频输出设备。则请求AudioFlinger打开新的音频输出设备;
Ø AudioFlinger为该输出设备创建混音线程MixerThread,并把该线程的id作为getOutput()的返回值返回给AudioTrack;
Ø AudioTrack通过binder机制调用AudioFlinger的createTrack()创建Track。而且创建TrackHandle Binder本地对象,同一时候返回IAudioTrack的代理对象。
Ø AudioFlinger注冊该Track到MixerThread中;
Ø AudioTrack通过IAudioTrack接口,得到在AudioFlinger中创建的FIFO(audio_track_cblk_t);

AudioTrack启动过程
status_t AudioTrack::start()
status = mAudioTrack->start();
由于mAudioTrack是binder的proxy对象,因此start会调用到BnBinder对象的start方法,即
status_t AudioFlinger::TrackHandle::start() {
return mTrack->start();
}
由于我们是在PlaybackThread下进行音频输出的,因此会进一步调用到PlaybackThread::Track:: start方法,其中最主要的是下面两个步骤:
status_t AudioFlinger::PlaybackThread::Track::start(
PlaybackThread *playbackThread = (PlaybackThread *)thread.get();
status = playbackThread->addTrack_l(this);
}
还记得我们在getOutput的时候创建了一个MixerThread吗,而且在createTrack_l的时候把这个Thread加入了mPlaybackThreads进行管理,现在我们要把它取出来,调用它的addTrack_l方法了
// addTrack_l() must be called with ThreadBase::mLock held
status_t AudioFlinger::PlaybackThread::addTrack_l(const sp在addTrack_l方法内,主要步骤有三个:
如果该track(share buffer)是新增track,则需要调用startOutput进行初始化
把该track加入mActiveTracks
发送广播,通知MixerThread开始工作
// addTrack_l() must be called with ThreadBase::mLock held
status_t AudioFlinger::PlaybackThread::addTrack_l(const sp- track初始化
在分析getOutput的时候,我们已经知道Audio接口的调用流程,即AudioSystem->AudioPolicyService->Audio_policy_hal->AudioPolicyManagerBase,现在我们来看一下AudioPolicyManagerBase:: startOutput做了什么
status_t AudioPolicyManager::startOutput(audio_io_handle_t output,
AudioSystem::stream_type stream,
int session)
{
status_t status = startSource(outputDesc, stream, newDevice, address, &delayMs);//主要设置输出设备,设置音量,check mute
}
-
track加入mAudioTrack
mAudioTrack即当前MixerThread所包含的Track集合,在后面就是对这些Track集合进行混音 -
broadcast_l
void AudioFlinger::PlaybackThread::broadcast_l()
{
// Thread could be blocked waiting for async
// so signal it to handle state changes immediately
// If threadLoop is currently unlocked a signal of mWaitWorkCV will
// be lost so we also flag to prevent it blocking on mWaitWorkCV
mSignalPending = true;
mWaitWorkCV.broadcast();
}
我们已经有了MixerThread,由于MixerThread继承与PlaybackThread,因此跑的是PlaybackThread::threadLoop,在threadLoop内,如果mActiveTrack为空的话,表明没有音频数据等待输出,那么threadLoop会进入睡眠,等待唤醒,这里的broadcast就是做了这个唤醒的工作
bool AudioFlinger::PlaybackThread::threadLoop() {
if ((!mActiveTracks.size() && systemTime() > standbyTime) ||
isSuspended())
mWaitWorkCV.wait(mLock);
}
... }
下面是start的总体流程

AudioTrack数据写入过程
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking)
{
够简单,就是obtainBuffer,memcpy数据,然后releasBuffer
眯着眼睛都能想到,obtainBuffer一定是Lock住内存了,releaseBuffer一定是unlock内存了
do {
audioBuffer.frameCount = userSize/frameSize();
status_t err = obtainBuffer(&audioBuffer, -1);
size_t toWrite;
toWrite = audioBuffer.size;
memcpy(audioBuffer.i8, src, toWrite);
src += toWrite;
}
userSize -= toWrite;
written += toWrite;
releaseBuffer(&audioBuffer);
} while (userSize);
return written;
}
//obtainBuffer太复杂了,不过大家知道其大概工作方式就可以了
status_t AudioTrack::obtainBuffer(Buffer* audioBuffer, int32_t waitCount)
{
//恕我中间省略太多,大部分都是和当前数据位置相关,
uint32_t framesAvail = cblk->framesAvailable();
cblk->lock.lock();//看见没,lock了
result = cblk->cv.waitRelative(cblk->lock, milliseconds(waitTimeMs));
//我发现多地方都要判断远端的AudioFlinger的状态,比如是否退出了之类的,难道
//没有一个好的方法来集中处理这种事情吗?
if (result == DEAD_OBJECT) {
result = createTrack(mStreamType, cblk->sampleRate, mFormat, mChannelCount,
mFrameCount, mFlags, mSharedBuffer,getOutput());
}
//得到buffer
audioBuffer->raw = (int8_t *)cblk->buffer(u);
return active ? status_t(NO_ERROR) : status_t(STOPPED);
}
在看看releaseBuffer
void AudioTrack::releaseBuffer(Buffer* audioBuffer)
{
audio_track_cblk_t* cblk = mCblk;
cblk->stepUser(audioBuffer->frameCount);
}
奇怪了,releaseBuffer没有unlock操作啊?难道我失误了?
再去看看obtainBuffer?为何写得这么晦涩难懂?
原来在obtainBuffer中会某一次进去lock,再某一次进去可能就是unlock了。没看到obtainBuffer中到处有lock,unlock,wait等同步操作吗。一定是这个道理。难怪写这么复杂。还使用了少用的goto语句。
唉,有必要这样吗!你牛逼,你说的都对
AudioTrack停止过程
track stop之后,获取不到数据,该track首先会presentationComplete将所有buffer缓存残留数据写完之后,再会从active track中remove掉,然后里面调用stopOutput
void AudioTrack::stop()
mAudioTrack->stop();
void AudioFlinger::PlaybackThread::Track::stop()
{
if (state == RESUMING || state == ACTIVE || state == PAUSING || state == PAUSED) {
// If the track is not active (PAUSED and buffers full), flush buffers
PlaybackThread *playbackThread = (PlaybackThread *)thread.get();
if (playbackThread->mActiveTracks.indexOf(this) < 0) {
reset();
mState = STOPPED;
} else if (!isFastTrack() && !isOffloaded() && !isDirect()) {
mState = STOPPED;
} else {
// For fast tracks prepareTracks_l() will set state to STOPPING_2
// presentation is complete
// For an offloaded track this starts a drain and state will
// move to STOPPING_2 when drain completes and then STOPPED
mState = STOPPING_1;
if (isOffloaded()) {
mRetryCount = PlaybackThread::kMaxTrackStopRetriesOffload;
}
}
playbackThread->broadcast_l();//多多关注这个,搞明白
ALOGV("not stopping/stopped => stopping/stopped (%d) on thread %p", mName,
playbackThread);
}
}
#threadLoop处理数据准备,混音,重采样,音效处理,写HAL的过程
threadLoop中AudioFlinger如何获取共享buffer的数据,以及如何做resample,mix,最后写往HAL的
bool AudioFlinger::PlaybackThread::threadLoop()
{
Vector< sp上面是threadLoop的源码,也是数据处理的主体部分,其中主要分为以下几个小部分
1.prepareTracks_l
2.threadLoop_mix
3.effectChains[i]->process_l
4.threadLoop_write
prepareTracks_l
AudioFlinger::PlaybackThread::mixer_stateAudioFlinger::MixerThread::prepareTracks_l(…)
{
/*Step 1. 当前活跃的Track数量*/
size_t count = mActiveTracks.size();
/*Step 2. 循环处理每个Track,这是函数的核心*/
for (size_t i=0; icblk(); //Step 4.1 数据块准备
/*Step 4.2 要回放音频前,至少需要准备多少帧数据?*/
uint32_t minFrames = 1;//初始化
//具体计算minFrames…
/*Step 4.3 如果数据已经准备完毕*/
//调整音量
//其它参数设置
}//for循环结束
/*Step 5. 后续判断*/
//返回结果,指明当前状态是否已经ready
}
Step1@ MixerThread::prepareTracks_l, mActiveTracks的数据类型是SortedVector,用于记录当前活跃的Track。它会随着新的AudioTrack的加入而扩大,也会在必要的情况下(AudioTrack工作结束、或者出错等等)remove相应的Track。
Step2&3@MixerThread::prepareTracks_l, 循环的条件就是要逐个处理该PlaybackThread中包含的Track。假如当前是一个FastTrack,我们还要做一些其它准备,这里就暂时不去涉及具体细节了。
Step4@ MixerThread::prepareTracks_l, 这一步是准备工作中最重要的,那就是缓冲数据。在学习代码细节前,我们先来了解数据传输时容易出现的underrun情况。
什么是Buffer underrun呢?
当两个设备或进程间形成“生产者-消费者”关系时,如果生产的速度不及消费者消耗的速度,就会出现Underrun。以音频回放为例,此时用户听到的声音就可能是断断续续的,或者是重复播放当前buffer中的数据(取决于具体的实现)。
如何避免这种异常的发生?这也是Step4所要解决的问题,以下分为几个小步骤来看AudioFlinger是如何做到的。
Ø Step4.1,取得数据块
audio_track_cblk_t*cblk = track->cblk();
关于audio_track_cblk_t的更多描述,可以参见后面数据流小节。
Ø Step4.2 计算正确回放音频所需的最少帧数,初始值为1。
uint32_tminFrames = 1;
if((track->sharedBuffer() == 0) && !track->isStopped() &&!track->isPausing() &&
(mMixerStatusIgnoringFastTracks == MIXER_TRACKS_READY)) {
if(t->sampleRate() == (int)mSampleRate) {
minFrames = mNormalFrameCount;
} else {
minFrames =(mNormalFrameCount * t->sampleRate()) / mSampleRate + 1 + 1;
minFrames +=mAudioMixer->getUnreleasedFrames(track->name());
ALOG_ASSERT(minFrames <= cblk->frameCount);
}
}
当track->sharedBuffer()为0时,说明AudioTrack不是STATIC模式的,否则数据就是一次性传送的,可以参见AudioTrack小节的描述。全局变量mSampleRate 是通过mOutput->stream->common.get_sample_rate获得的,它是由HAL提供的,代表的是设备的Sampling rate。
如果两者一致的话,就采用mNormalFrameCount,这个值在readOutputParameters函数中进行初始化。如果两者不一致的话,就要预留多余的量做rounding(+1)和interpolation(+1)。另外,还需要考虑未释放的空间大小,也就是getUnreleasedFrames得到的。得出的minFrames必需小于数据块的总大小,因而最后有个ASSERT。通常情况下frameCount分配的是一个buffer的两倍,可以参见AudioTrack小节的例子。
Ø Step4.3 数据是否准备就绪了?
上一步我们计算出了数据的最小帧值,即minFrames,接下来就该判断目前的情况是否符合这一指标了,代码如下所示:
if ((track->framesReady() >=minFrames) && track->isReady() &&!track->isPaused()&& !track->isTerminated())
{//数据准备就绪,并处于ready状态
mixedTracks++; //需要mix的Track数量增加1
…
/*计算音量值*/
uint32_t vl, vr,va; //三个变量分别表示左、右声道、Aux level音量
if(track->isMuted() || track->isPausing()||mStreamTypes[track->streamType()].mute) {
vl = vr = va =0; //当静音时,变量直接赋0
if (track->isPausing()) {
track->setPaused();
}
} else {
/*这里获得的是针对每个stream类型设置的音量值,也就是后面“音量调节”小节里最
后执行到的地方,在这里就起到作用了*/
float typeVolume =mStreamTypes[track->streamType()].volume;
float v =masterVolume * typeVolume; //主音量和类型音量的乘积
uint32_t vlr = cblk->getVolumeLR(); //这里得到的vlr必须经过验证是否在合理范围内
vl = vlr &0xFFFF; //vlr的高低位分别表示vr和vl
vr = vlr>> 16;
if (vl >MAX_GAIN_INT) { //对vl进行合理值判断
ALOGV("Track left volume out of range: %04X", vl);
vl =MAX_GAIN_INT;
}
if (vr >MAX_GAIN_INT) {//对vr进行合理值判断
ALOGV("Track right volume out of range: %04X", vr);
vr =MAX_GAIN_INT;
}
// now applythe master volume and stream type volume
vl =(uint32_t)(v * vl) << 12;
vr =(uint32_t)(v * vr) << 12;
uint16_tsendLevel = cblk->getSendLevel_U4_12();
// send levelcomes from shared memory and so may be corrupt
if (sendLevel> MAX_GAIN_INT) {
ALOGV("Track send level out of range:%04X", sendLevel);
sendLevel= MAX_GAIN_INT;
}
va =(uint32_t)(v * sendLevel);
} …
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, (void*)vl);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, (void*)vr);
mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, (void*)va);
…
} else {//数据未准备就绪,略过。。。
对于音量的设置还有很多细节,大家有兴趣的可以深入研究下。在得到vl、vr和va的值后,还需要把它们应用到AudioMixer中去,不过在prepareTracks_l中还只是调用mAudioMixer->setParameter设置了这些参数,真正的实现是在threadLoop_mix中,我们后面会讲到这个函数。
Step5@ MixerThread::prepareTracks_l, 通过对每个Track执行上述的处理后,最后要返回一个结果,这通常取决于:
①是否有activetrack
②active track的数据是否已经准备就绪
返回的最终值将影响到threadLoop的下一步操作。
threadLoop_mix
PlaybackThread::threadLoop, 如果上一步的数据准备工作已经完成(即返回值是MIXER_TRACKS_READY),就开始进行真正的混音操作,即threadLoop_mix,否则会休眠一定的时间——如此循环往复直到退出循环体。
void AudioFlinger::MixerThread::threadLoop_mix()
{
int64_t pts;
…
mAudioMixer->process(pts);
…
}
threadLoop_mix在内部就是通过AudioMixer来实现混音的,我们这里具体来看下:
void AudioMixer::process(int64_t pts)
{
mState.hook(&mState,pts);
}
“hook”是钩子函数,是一个函数指针,它根据当前具体情况会分别指向以下几个函数实现:
process__validate:根据当前具体情况,将hook导向下面的几个实现
process__nop:初始化值
process__OneTrack16BitsStereoNoResampling:只有一路Track,16比特立体声,不重采样
process__genericNoResampling:两路(包含)以上Track,不重采样
process__genericResampling:两路(包含)以上Track,重采样
hook在以下几种情况下会重新赋值
Ø AudioMixer初始化时,hook指向process_nop
Ø 当状态改变或者参数变化时(比如setParameter),调用invalidateState。此时hook指向process__validate
Ø AudioMixer::process是外部调用hook的入口
其中process_validate的代码实现如下:
void AudioMixer::process__validate(state_t* state, int64_t pts)
{ …
int countActiveTracks = 0;
boolall16BitsStereoNoResample = true;
bool resampling = false;…
uint32_t en =state->enabledTracks;
while (en) {
const int i = 31 -__builtin_clz(en);
en &= ~(1<hook = process__nop;
if (countActiveTracks) {
if (resampling) {
…
state->hook = process__genericResampling;
} else {
…
state->hook = process__genericNoResampling;
if(all16BitsStereoNoResample && !volumeRamp) {
if(countActiveTracks == 1) {
state->hook = process__OneTrack16BitsStereoNoResampling;
}
}
}
}
state->hook(state, pts);
…
}
这个函数先通过while循环逐个分析处于enabled状态的Track,统计其内部各状态位(比如NEEDS_AUX__MASK、NEEDS_RESAMPLE__MASK等等)情况,得出countActiveTracks、resampling、volumeRamp及all16BitsStereoNoResample的合理值,最后根据这几个变量判断选择正确的hook实现,并调用这个hook函数执行具体工作。
threadLoop_write
PlaybackThread::threadLoop, 将数据写到HAL中,从而逐步写入到硬件设备中。
void AudioFlinger::PlaybackThread::threadLoop_write()
{
mLastWriteTime =systemTime();
mInWrite = true;
int bytesWritten;
if (mNormalSink != 0) {
…
ssize_t framesWritten= mNormalSink->write(mMixBuffer, count);
…
} else { // Direct output and offload threads
bytesWritten =(int)mOutput->stream->write(mOutput->stream, mMixBuffer,mixBufferSize);
}
if (bytesWritten > 0)mBytesWritten += mixBufferSize;
mNumWrites++;
mInWrite = false;
}
分为两种情况:
Ø 如果是采用了NBAIO(Non-blocking AudioI/O),即mNormalSink不为空,则通过它写入HAL
Ø 否则使用普通的AudioStreamOut(即mOutput变量)将数据输出
里面有一个地方要注意的是数据的来源 mSinkBuffer
AudioFlinger 是android 多媒体模块Audio模块的两大服务之一。音频相关的数据必须通过它来传递到底层,所以它就会有一个音频数据的处理过程。这里主要就是分析音频数据从编码器出来之后,怎么流向驱动的。
从audoFlinger的代码中很容易发现,数据写到驱动的处理是在函数
AudioFlinger::PlaybackThread::threadLoop_write()中。这个threadLoop_write 函数在AudioFlinger::PlaybackThread::threadLoop()函数中调用,很显然audioFlinger的数据处理都会在这个线程函数中处理。那么数据的出口是这样实现
那么数据的入口在哪里呢?
通过分析,发现PlaybackThread::threadLoop() 函数主要做三件事,prepareTracks_l(), threadLoop_mix(),threadLoop_write().
prepareTracks_l() 函数主要的工作就是检查是否有track 的状态,并做相应的处理,比如track准备好了,就把它添加到队列中区,还做一些处理比如
// XXX: these things DON'T need to be done each time
mAudioMixer->setBufferProvider(name, track);
mAudioMixer->enable(name);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, (void*)vl);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, (void*)vr);
mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, (void*)va);
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::FORMAT, (void*)track->format());
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::CHANNEL_MASK, (void*)track->channelMask());
设置参数到AudioMixer。这个很关键,会影响后面混音的结果和处理。
prepareTracks_l() 之后就是混音处理了,处理函数就是threadLoop_mix()。混音,顾名思义,就是将几种声音混到一起,实际上就是将同时处于active状态的track进行混音,每一路音频对应一个track实例。目前android 最多支持32路混音,在类AudioMixer中有相应的定义: static const uint32_tMAX_NUM_TRACKS = 32;
threadLoop_write 是数据的出口,prepareTracks_l只是准备tracks,那么很显然,数据的入口也只有threadLoop_mix 了,混音必须要对数据处理,如果没有数据怎么混音,此时将数据拉进来时最好的时机,事实上也是在threadLoop_mix 的处理过程中数据进入到AudioFlinger服务中。下面来分析threadLoop_mix。
voidAudioFlinger::MixerThread::threadLoop_mix()
{
// obtain the presentation timestamp of the next output buffer
int64_t pts;
status_t status = INVALID_OPERATION;
if (mNormalSink != 0) {
status = mNormalSink->getNextWriteTimestamp(&pts);
}else {
status = mOutputSink->getNextWriteTimestamp(&pts);
}
if (status != NO_ERROR) {
pts = AudioBufferProvider::kInvalidPTS;
}
// mix buffers...
mAudioMixer->process(pts);
mCurrentWriteLength = mixBufferSize;
if ((sleepTime == 0) && (sleepTimeShift > 0)) {
sleepTimeShift--;
}
sleepTime = 0;
standbyTime = systemTime() + standbyDelay;
//TODO: delay standby when effects have a tail
}
从函数中发现,mAudioMixer->process(pts);就是这个函数的核心,从名字就可以看出来,process就是处理的意思。接着,看看mAudioMixer->process(pts); 究竟做了什么事情。
void AudioMixer::process(int64_t pts)
{
mState.hook(&mState, pts);
}
只有一句代码,hook 是一个函数指针,指向一个函数实体,那么这个实体函数是哪个呢?这个问题先放一边,感觉比较迷茫,先看看其他的。AudioFlinger的数据处理,主要就是集中在函数bool AudioFlinger::PlaybackThread::threadLoop(),
先看看threadloop_write()函数的具体实现
ssize_t AudioFlinger::PlaybackThread::threadLoop_write()
{
….
if (mNormalSink != 0) {
…
ssize_t framesWritten = mNormalSink->write(mMixBuffer + offset,count);
// otherwise use the HAL / AudioStreamOut directly
}else {
// Direct output and offload threads
…
bytesWritten = mOutput->stream->write(mOutput->stream,
mMixBuffer + offset,mBytesRemaining);
…
}
}
以上代码可以看出,数据写到驱动就是通过上面代码来实现,看见这个就是数据在audioFlinger的出口,很明白,在我看来,数据的入口比较隐晦,写数据的buffer 是mMixBuffer,这个buffer的数据是从哪里来的呢?知道这个buffer的数据来源,应该就可以搞清楚AudioFlinger 的数据入口在哪里了。
mMixBuffer 的空间分配在函数PlaybackThread::readOutputParameters()
voidAudioFlinger::PlaybackThread::readOutputParameters()
{
mAllocMixBuffer = new int8_t[mNormalFrameCount * mFrameSize + align -1];
mMixBuffer= (int16_t *) ((((size_t)mAllocMixBuffer + align - 1) / align) * align);
memset(mMixBuffer,0, mNormalFrameCount * mFrameSize);
}
voidAudioMixer::process__genericResampling(state_t* state, int64_t pts)
{
int32_t* const outTemp = state->outputTemp;
while (e0) {
}
int32_t *out = t1.mainBuffer;
memset(outTemp,0, size);
while (e1) {
} else {
while (outFrames getNextBuffer(&t.buffer,outputPTS);
t.in = t.buffer.raw;
outFrames += t.buffer.frameCount;
t.bufferProvider->releaseBuffer(&t.buffer);
}
}
}
}
}
以上代码精简了,注意红色标记,t.bufferProvider->getNextBuffer(&t.buffer,outputPTS);这里就是获得数据的地方了,取得的数据再处理,应该就是混音处理的,t.hook,后期再分析hook指针指向哪里,处理之后的数据在outTemp所指向的内存当中,ditherAndClamp(out, outTemp, numFrames); 函数就是将数据再处理,至于这个函数是做什么处理,目前我还没有搞清楚,反正最后等到处理后的数据时out指针指向的内存….int32_t *out = t1.mainBuffer;这个out指针就是track_t结构的成员mainBuffer,这个mainBuffer跟track类的mMainBuffer有什么关系呢?
看看前面的prepareTracks_l() 函数,有一段处理代码
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MAIN_BUFFER, (void*)track->mainBuffer());
简单再说一下这个过程,在prepareTracks_l() 的时候将active的track的mMainBuffer 赋值到AudioMixer中去,这样混音后的数据就会保存到这个buffer,而mMainBuffer 又是从playbackThread中的mMixBuffer 赋值得来。
回到前面看看,数据是怎么从入口得来的,通过查找代码发现,
t.bufferProvider->getNextBuffer(&t.buffer,outputPTS);
在创建audioTrack的时候会创建一个共享内存,getNextBuffer就是从共享内存中获取数据,这个共享内存的写入端在audioTrack,读端在AudioFlinger。下一章再详细写一下,关于AudioTrack的数据到AudioFlinger的处理和audioTrack 共享内存的工作方式
FastTrack
fast track的前世今生
fast track由应用创建的时候带 fast flag,但是实际是否创建还是需要native里面确认,有些bug就是应用创建fast,但是实际被拒绝了,然后应用仍然按照fast track的速率去写数据,导致声音异常。
fast track是不会经过系统音效的,本身也是为了快速输出声音才有的。
`