缺失值处理
缺失值处理
之前写过一篇文章缺失值可视化处理–missingno
主要介绍了缺失值的查看,今天聊一下,出现了缺失值后我们要做的后续工作,就是缺失值的处理。
1、缺失值删除
首先附上几个代码
data数据集
data.isnull()#缺失值判断:是缺失值返回True,否则范围False
data.isnull().sum()#缺失值计算:返回每列包含的缺失值的个数
data.dropna()#缺失值删除:直接删除含有缺失值的行
data.dropna(axis = 1)#缺失值删除列:直接删除含有缺失值的列
data.dropna(how = 'all')#缺失值删除行:只删除全是缺失值的行
data.dropna(thresh = n)#缺失值删除判断:保留至少有n个缺失值的行
data.dropna(subset = ['C'])#缺失值删除列:删除含有缺失值的特定的列
2、缺失值填充
主要针对数值型数值(Numerical Data)
fillna()函数
data.fillna(0):用0填充
data.fillna(method=‘pad’):用前一个数值填充
data.fillna(data.mean()):用该列均值填充
Imputer
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)#均值填充缺失值
imr = imr.fit(data)
imputed_data = imr.transform(data.values)
参数解释:
填补缺失值:sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
主要参数说明:
missing_values:缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
strategy:替换策略,字符串,默认用均值‘mean’替换
①若为mean时,用特征列的均值替换
②若为median时,用特征列的中位数替换
③若为most_frequent时,用特征列的众数替换
axis:指定轴数,默认axis=0代表列,axis=1代表行
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,存在如下情况时,即使设置为False时,也不会就地修改
①X不是浮点值数组
②X是稀疏且missing_values=0
③axis=0且X为CRS矩阵
④axis=1且X为CSC矩阵
statistics_属性:axis设置为0时,每个特征的填充值数组,axis=1时,报没有该属性错误
举例:
import numpy as np
from sklearn.preprocessing import Imputer
train_X = np.array([[1, 2], [np.nan, 3], [7, 6]])
imp = Imputer(missing_values=np.nan , strategy='mean', axis=0)
imp.fit(train_X)
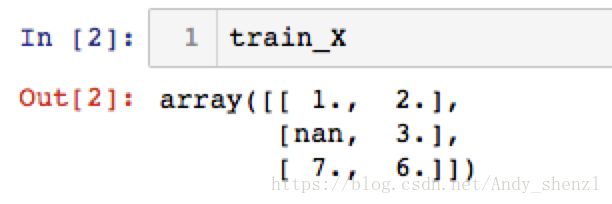
训练集数据中,
第一列有一个缺失值,平均值为(1+7)/2=4
第二列无缺失值,平均值为(2+3+6)/3=3.6667

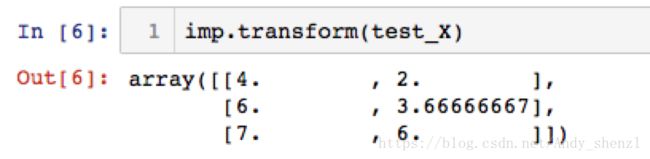
加入一个测试集:

将训练集的数据加入到测试集的缺失值中