关于ADMM的研究(二)
4. Consensus and Sharing
本节讲述的两个优化问题,是非常常见的优化问题,也非常重要,我认为是ADMM算法通往并行和分布式计算的一个途径:consensus和sharing,即一致性优化问题与共享优化问题。
Consensus
4.1 全局变量一致性优化(Global variable consensus optimization)(切割数据,参数(变量)维数相同)
所谓全局变量一致性优化问题,即目标函数根据数据分解成 N 子目标函数(子系统),每个子系统和子数据都可以获得一个参数解 xi ,但是全局解只有一个 z ,于是就可以写成如下优化命题:
注意,此时 fi:Rn→R⋃+∞ 仍是凸函数,而 xi 并不是对参数空间进行划分,这里是对数据而言,所以 xi 维度一样 xi,z∈Rn ,与之前的问题并不太一样。这种问题其实就是所谓的并行化处理,或分布式处理,希望从多个分块的数据集中获取相同的全局参数解。
在ADMM算法框架下(先返回最初从扩增lagrangian导出的ADMM),这种问题解法相当明确:
对 y -update和 z -update的 yk+1i 和 zk+1i 分别求个平均,易得 y¯k+1=0 ,于是可以知道 z -update步其实可以简化为 zk+1=x¯k+1 ,于是上述ADMM其实可以进一步化简为如下形式:
这种迭代算法写出来了,并行化那么就是轻而易举了,各个子数据分别并行求最小化,然后将各个子数据的解汇集起来求均值,整体更新对偶变量 yk ,然后再继续回带求最小值至收敛。当然也可以分布式部署(hadoop化),但是说起来容易,真正工程实施起来又是另外一回事,各个子节点机器间的通信更新是一个需要细细揣摩的问题。
另外,对于全局一致性优化,也需要给出相应的终止迭代准则,与一般的ADMM类似,看primal和dual的residuals即可
4.2 带正则项的全局一致性问题
下面就是要将之前所谈到的经典的机器学习算法并行化起来。想法很简单,就是对全局变量加上正则项即可,因此ADMM算法只需要改变下 z -update步即可
同样的,我们仍对 z 做一个平均处理,于是就有
上述形式都取得是最原始的ADMM形式,简化处理,写成scaled形式即有
这样对于后续处理问题就清晰明了多了。可以看到如果 g(z)=λ|z|1 ,即lasso问题,那么 z -update步就用软阈值operator即可。因此,对于大规模数据,要想用lasso等算法,只需要对数据做切块(切块也最好切均匀点),纳入到全局变量一致性的ADMM框架中,即可并行化处理。下面给出一些实例。
切割大样本数据,并行化计算
在经典的统计估计中,我们处理的多半是大样本低维度的数据,现在则多是是大样本高维度的数据。对于经典的大样本低维度数据,如果机器不够好,那么就抽样部分数据亦可以实现较好估计,不过如果没有很好的信息,就是想要对大样本进行处理,那么切割数据,并行计算是一个好的选择。现在的社交网络、网络日志、无线感应网络等都可以这么实施。下面的具体模型都在受约束的凸优化问题中以及 ℓ1 -norm问题中提过,此处只不过切割数据,做成分布式模型,思想很简单,与带正则项的global consensus问题一样的处理。经典问题lasso、sparse logistic lasso、SVM都可以纳入如下框架处理。
有观测阵 A∈Rm×n 和响应值 b∈Rm ,可以对应切分,即对矩阵 A 和向量 b 横着切,
于是原来带正则项的优化问题就可以按照数据分解到多个子系统上去分别优化,然后汇集起来,形成一个global consensus问题。
结合受约束的凸优化问题时所给出来的具体的ADMM算法解的形式,下面直接给出这些问题的ADMM迭代算法公式
(1)Lasso
如果切割的数据量小于维数 mi<n ,那么求解时分解小的矩阵 AiATi+ρI 即可;其他求逆采用矩阵加速技巧即可。
(2)Sparse Logistic Regression
在 x -update步是需要用一些有效的算法来解决 ℓ2 正则的logistic回归,比如L-BFGS,其他的优化算法应该问题不大吧。
(3)SVM
注意分类问题和回归问题的损失函数不同,一般都是用 l(sign(t)y) 形式来寻求最优的分类权重使得分类正确。SVM使用Hinge Loss: ℓ(y)=max(0,1−t⋅y) ,即将预测类别与实际分类符号相反的损失给凸显出来。分布式的ADMM形式
4.3 一般形式的一致性优化问题(切割参数到各子系统,但各子系统目标函数参数维度不同,可能部分重合)
上述全局一致性优化问题,我们可以看到,所做的处理不过是对数据分块,然后并行化处理。但是更一般的优化问题是,参数空间也是分块的,即每个子目标函数 fi(xi) 的参数维度不同 xi,∈Rni ,我们称之为局部变量。而局部变量所对应的的也将不再是全局变量 z ,而是全局变量中的一部分 zg ,并且不是像之前的顺序对应,而可能是随便对应到 z 的某个位置。可令 g=G(i,⋅) ,即将 xi 映射到 z 的某部位
如果对所有 i 有 G(i,j)=j ,那么 xi 与 z 就是顺序映射,也就是全局一致性优化问题,否则就不是。结合下图就比较好理解
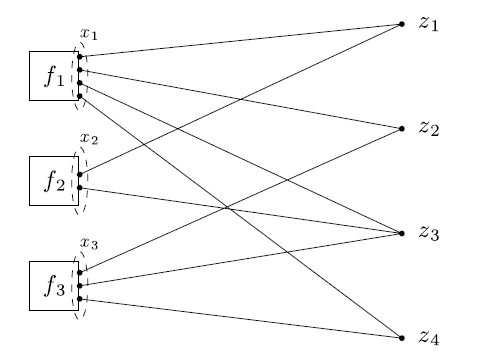
虽然如果用其他方法来做感觉会复杂,但是纳入到上述ADMM框架,其实只不过是全局一致性优化问题的一个局部化变形,不过此时不是对数据进行分块,是对参数空间进行分块
后续想做平均化处理,即中间会发生重合的参数 zi 取值一样的,那么 z -update将只能找他对应的那些 x 进行平均化,也就是变成局部了,因为不是所有值都是要全局保持一致的。比如上面那个图中的 z1,z2,z3,z4 都分别只要求在部分 xi 发生了共享需要保持一样,而不是像之前全局要求每个 xi 对应的都是 z 。即
该式子表示就是 z 的第 g 个变量的平均值来源于所有映射到该变量的 x 与 y 的平均值。与之前的global类似,此时对于 y 的取均值会为0,因此 z -update就变成了更简单的形式
同全局一致性优化问题一样,我们可以加上正则项,然后也可以变成带正则项的一般形式的一致性优化问题。此处不赘述,与全局基本类似。
Sharing
4.4 共享问题(sharing)(横向切割数据,也可纵向切变量)
与之前的全局变量一致性优化问题类似,共享问题也是一个非常一般而且常见的问题。他的形式如下:
这里的第一部分局部损失 fi(xi) 与全局一致性优化是一样的,即所有的 xi∈Rn,i=1,…,N 同维度,而对于一个共享的目标函数 g 则是新加入的。在实际中,我们常常需要优化每个子数据集上的损失函数,同时还要加上全局数据所带来的损失;或者需要优化每个子系统的部分变量,同时还要优化整个变量。共享问题是一个非常重要而灵活的问题,它也可以纳入到ADMM框架中,形式如下:
上述形式当然还不够简洁,需要进一步化简。因为 x -update可以不用担心,分机并行处理优化求解即可,而对于 z -update这里面需要对 Nn 个变量求解,想加快速度,就减少变量个数。于是想办法通过和之前那种平均方式一样来简化形式解。
对于 z -update步,令 ai=uki+xk+1i ,于是 z -update步优化问题转化为
当 z¯ 固定时,那么后面的最优解(类似回归)为 zi=ai+z¯−a¯ ,带入上式后于是后续优化就开始整体更新(均值化)
另外,有证明如果强对偶性存在,那么global consensus问题与sharing问题是可以相互转化的,可以同时达到最优,两者存在着很紧密的对偶关系。
本节开头提过,sharing问题用来切分数据做并行化,也可以切分参数空间做并行化。这对于高维、超高维问题是非常有好处的。因为高维统计中,大样本是一方面问题,而高维度才是重中之重,如果能切分特征到低纬度中去求解,然后在合并起来,那么这将是一个很美妙的事情。上面利用regularized global consensus问题解决了切分大样本数据的并行化问题,下面利用sharing思想解决常见的高维数据并行化问题
切割变量(特征)空间,并行化处理
同样假设面对还是一个观测阵 A∈Rm×n 和响应观测 b∈Rn ,此时有 n»m ,那么要么就降维处理,要么就切分维度去处理,或者对于超高维矩阵,切分维度后再降维。此时 A 矩阵就不是像之前横着切分,而是竖着切分,这样对应着参数空间的切分:
于是正则项也可以切分为 r(x)=∑Ni=1ri(xi) 。那么最初的 minl(Ax−b)+r(x) 形式就变成了
这个与sharing问题非常接近了,做点变化那就是sharing问题了
与之前的global consensus问题相比,ADMM框架 x -update与 z -update似乎是反过来了。于是将此形式直接套到Lasso等高维问题即有很具体的形式解了。
(1)Lasso
当 |ATi(Aixki+z¯k−Ax¯¯¯¯¯k−uk)|2≤λ/ρ 时 xk+1i=0 (第 i 块特征不需要用),这样加快了 x -update速度,不过这个对串行更有效,对并行起来也没有多大用..
(2)Group Lasso 与lasso基本一样,只是在 x -update上有一个正则项的不同,有 ℓ1 -norm变成了 ℓ2 -norm
该问题其实就是按组最小化 (ρ/2)|Aixi−v|22+λ|xi|2 ,解为
涉及矩阵长短计算时,再看矩阵小技巧。
(3)Sparse Logstic Regression 也与lasso区别不大,只是 z -update的损失函数不同,其余相同于是
(4)SVM
SVM与之前的global consensus时候优化顺序反了过来,与logistic rgression只是在 z -update步不同(损失函数不同):
z -update解析解可以写成软阈值算子
(5)Generalized Additive Models
广义可加模型是一个很适合sharing框架的问题。它本身就是对各个各个特征做了变化后(非参方法),重新表示观测的方式
当 fi 是线性变化时,则退化成普通线性回归。此时我们目标优化的问题是
其中有 m 个观测, n 维特征(变量)。 rj 此时是对一个functional的正则,此时这个问题看起来似乎既可以对数据切分,也可以对特征切分,不过此时仍用sharing问题来做,相当于对特征切分为一个特征为一个子系统,于是有
fj 是一个 ℓ2 正则的损失,有直接求解的算法求解, z 可以一块一块的求解?
最后再说一个经济学中很重要的sharing问题的特例,即交换问题(exchange problem):
此时共享目标函数 g=0 。 xi 可以表示不同物品在 N 个系统上的交换数量, (xi)j 可以表示物品 j 从子系统 i 上收到的交换数目,约束条件就可以看做在这些系统中物品交换是保持均衡稳定的。于是转化为sharing问题,就有很简单的ADMM解法(或者当做之前讲过的受约束的凸优化问题来解,做投影):
4.4 应用小总结
感觉上通过consensus problem和general consensus problem,我们可以看到并行和分布式部署优化方案的可行性。我们可以切分数据以及相应的目标函数,也可以切分变量到各个子系统上去,分别作优化,甚至我们可以大胆想象对不同类型数据块用不同的优化算法,结合consensus问题和ADMM算法,达到同一个global variable的优化目的;或者对不同变量在不同类型数据块上优化,即使有重叠,也可以结合general consensus思想和ADMM算法来解决这个问题。当然前提是能够定义好需要估计的参数和优化的目标函数!大规模部署的前景还是很不错的。下面具体分布式统计模型的构建便是ADMM算法非常好的应用。切分数据、切分变量(不过每个子系统的目标函数基本都是一样的,其实应该可以不同)
5. Nonconvex问题
5.1 变量选择(Regressor Selection)
5.2 因子模型(Factor Model Fitting)
5.3 双凸优化(Bi-convex Problem)
非负矩阵分解(Nonnegative Matrix Factorization)
6. 具体实施与实际计算结果
这块真的很实际,需要明白MPI的机理和Mapreduce、Graphlab等通信运作的机理,这样才好部署ADMM算法,因为中间有很多迭代,需要做好子节点间参数与整体参数的通信,保持迭代时能同步更新参数。看实际运作,MPI和GraphLab可能更适合这种框架,Hadoop也是可以的,不过毕竟不是为迭代算法所生,要做好需要进行一些优化。Boyd提到Hadoop其中的Hbase更适合这种框架,因为Hbase是一种大表格,带有时间戳,适合记录迭代的记录,这样就不容易导致分布计算时候搞不清是哪一步的迭代结果了,导致通信调整比较复杂。不过在MapReduce框架下实施ADMM算法是没有什么问题的,只要熟稔Hadoop的一些细节部分,基本没有太大问题。
8. 总结
一个好的一般性算法,我个人觉得是易实施,并可大规模应用许多问题。可以让统计学家卡在搞算法的瓶颈中解放出来,使得他们能快速用模拟,验证自己构建可能较为复杂的模型。只有当看到一个令人感到欣慰的结果时,那些模型的统计性质的证明才可能是有意义的,如果事先连希望都看不到,那证明起来都可能底气不足,让人难以信服,更难以大规模应用统计学家所构建的模型。现在是一个高维数据、海量数据的年代,算法的重要性更会凸显出来,一个好的模型如果没有一个有效的算法支撑,那么他将可能什么都不是,Lasso头几年所遭遇的冷遇也充分证明了这一点,再比如在没有计算机年代,Pearson的矩估计应用反而远多于Fisher的MLE估计方法也是一个道理。好的一般性的解决方案,我想这不管是优化理论,还是统计等其他应用学科,虽然知道没有最牛最终极的方法,但是能涌现一些大范围适用的方法,那就是再好不过了。一招鲜吃遍天,人还都是喜欢简单、安逸爱偷懒的嘛..