人脸验证(四)--CenterLoss
有点纠结,实质上本文只是在深度学习框架下人脸识别损失函数的改进。但我还是把它归类到端到端了。出于个人原因。
转自:http://blog.csdn.net/yang_502/article/details/72792786
16年ECCV的文章《A Discriminative Feature Learning Approach for Deep Face Recognition》
code:https://github.com/ydwen/caffe-face
Motivation:
和metric learning的想法一致,希望同类样本之间紧凑,不同类样本之间分散。现有的CNN最常用的softmax损失函数来训练网络,得到的深度特征通常具有比较强的区分性,也就是比较强的类间判别力。关于softmax的类内判别力,作者在文章中给了toy example,很直观的理解。
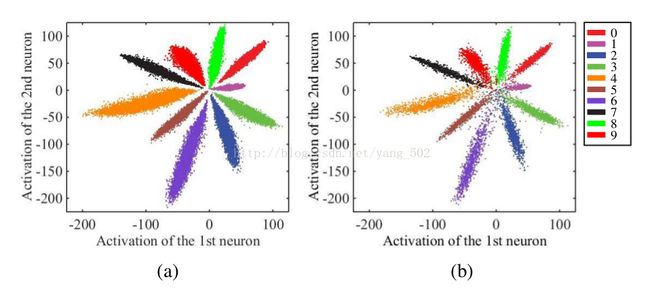
上面给的是mnist的最后一层特征在二维空间的一个分布情况,可以看到类间是可分的,但类内存在的差距还是比较大的。对于像人脸这种复杂分布的数据,我们通常不仅希望数据在特征空间不仅是类间可分,更重要的是类内紧凑。因为同一个人的类内变化很可能会大于类间的变化,只有保持类内紧凑,我们才能对那些类内大变化的样本有一个更加鲁棒的判定结果。也就是学习一种discriminative的特征。
下图就是我们希望达到的一种效果。
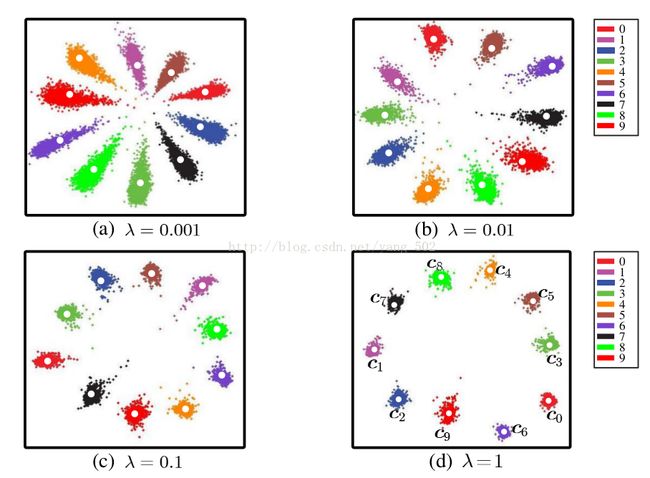
另外一种通俗解释 :
一句话:通过添加center loss 让简单的softmax 能够训练出更有内聚性的特征。
作者意图,在配合softmax适用的时候,希望使学习到的特征具有更好的泛化性和辨别能力。通过惩罚每个种类的样本和该种类样本中心的偏移,使得同一种类的样本尽量聚合在一起。
相对于triplet(Google FaceNet: A Unified Embedding for Face Recognition and Clustering:2015)和contrastive(汤晓鸥 Deep LearningFace Representation by Joint Identification-Verification:2014)来说,这个目标其实相对‘清晰’, 所以网络收敛的速度甚至比仅仅用softmax更快,而且不需要像前两者那样构造大量的训练对。
看一张图:
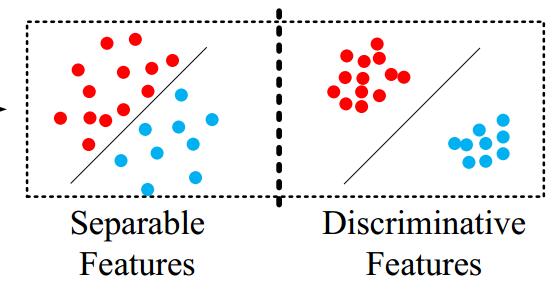
在左图中,我们发现一个类如果太胖,那么出现的结果就是类内距离>类间距离。(任意红点之间的距离应该小于红蓝之间的距离。)
左边时softmax一般结果,右边时centerloss结果。我们期望特征不仅可分,而且时必须差异大。如右边图。
Approach:
考虑保持softmax loss的类间判别力,提出center loss,center loss就是为了约束类内紧凑的条件。相比于传统的CNN,仅改变了原有的损失函数,易于训练和优化网络。
softmax loss :
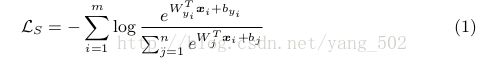
center loss:

其中,cyi就是每类人特征的中心表示。这个就是一个类中心特征,希望在一类人的所有图像特征与类中心特征的距离总和最小。
完整的loss function:
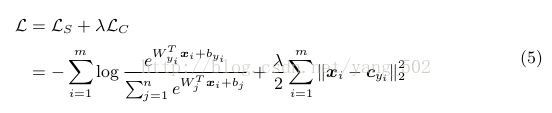
关于center loss 的求导:
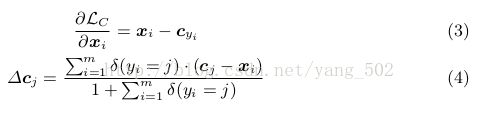
最后的loss实现可以参考code的具体实现。
Experiments:
CNN architecture
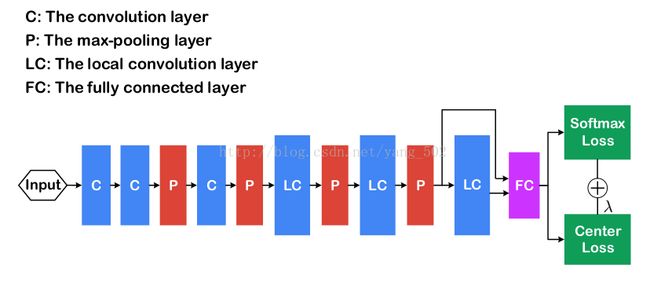
Weights in three local convolution layers are locally shared in the regions of 4 × 4, 2 × 2 and 1 × 1 respectively.
Implementation Details
Preprocessing.
使用【40】的关键点检测,进行人脸对齐与检测。人脸图像裁剪成112*96大小,像素归一化操作是通过减127.5再除128(??没搞懂)
Training data.
文章中使用的训练数据比较多,包括有CASIA-WebFace [39], CACD2000 [4], Celebrity+ [22]。但是作者他们做了图像清理,保证和测试集的人身份不重复,最后保留17,189个人的0.7M的图像。后面的训练阶段,只用了0.49M的数据,并且对图像做了水平翻转的数据增强。
Detailed settings in CNNs.
文章比较了3中模型:we respectively train three kind of models under the supervision of softmax loss (model A), softmax loss and contrastive loss (model B), softmax loss and center loss (model C)。就是网络使用的损失函数不同。
batchsize=256,在Titan X的两块GPU上做训练。A和C的初始lr=0.1,分别在16K和24K之后缩小至0.01.文章提到A在28K次收敛大致花14h,model B的收敛比较慢,初始lr=.01,咋24K和36K迭代的时候缩小学习率。B总共迭代了42K次,花22h.没说到C的训练时间。
Detailed settings in testing.
测试阶段,将测试图像通过CNN提取深度特征,即最后一个FC层的输出,将原图以及原图的水平翻转图的特征图拼接表示成共同的表示,经过PCA降维后计算COS距离。对于识别或者验证任务,可以是简单通过阈值划分或者是近邻判定。
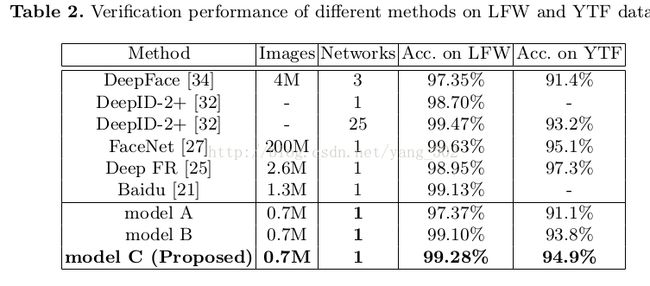
Experiments on the LFW and YTF datasets
使用0.7M的训练数据,在LFW和YTF的pair对上做了人脸验证。
Experiments on the dataset of MegaFace Challenge
使用MegaFace这个百万级别的数据库(干扰图像很多)。这个对于识别任务增大了难度。
数据库具体包括:
MegaFace datasets include gallery set and probe set. The gallery set consists of more than 1 million images from 690K different individuals, as a subset of Flickr photos [35] from Yahoo. The probe set using in this challenge are two existing databases: Facescrub [24] and FGNet [1]. Facescrub dataset is publicly available dataset, containing 100K photos of 530 unique individuals (55,742 images of males and 52,076 images of females). The possible bias can be reduced by sufficient samples in each identity. FGNet dataset is a face aging dataset, with 1002 images from 82 identities. Each identity has multiple face images at different ages (ranging from 0 to 69).

Reference
【40】 MTCNN
Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multi-task cascaded convolutional networks. arXiv preprint arXiv:1604.02878(2016)