评分卡模型开发--上线监测
转自:https://cloud.tencent.com/developer/article/1016299
那么我们的评分卡上线后,如何对评分卡的效果进行有效监测,监测哪些指标,监测的指标阈值达到多少我们需要对现有评分卡进行调整更新?这是我们在评分卡上线后需要持续性监测、关注的问题,今天就来跟大家分享一下互金行业评分卡监测的常用手段。
1. 模型稳定性
包括评分卡得分分布的PSI(Population Stability Index), 评分卡所有涉及变量的PSI. 模型分数分布稳定性:监测模型的打分结果的分布是否有变化,主要将评分卡上线后的样本RealData与建模时的样本Train_Data比较。使用的统计指标为PSI(Population Stability Index).使用的指标是PSI.
变量稳定性:监测模型的输入变量的分布是否有变化,主要将评分卡上线后的样本RealData与建模时的样本Train_Data比较。使用的指标也是PSI.
PSI 计算步骤: 假设我们要比较样本A与样本B中某一变量Y的分布,首先按照同一标准将Y分为几个区间(通常分为10段),计算样本A和样本B中每个区间的占比。在每个区间段上,将两个样本的各自占比相除再取对数,然后乘以各自占比之差,最后将各个区间段的计算值相加,得到最终PSI.
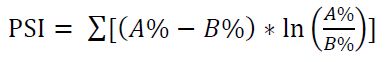
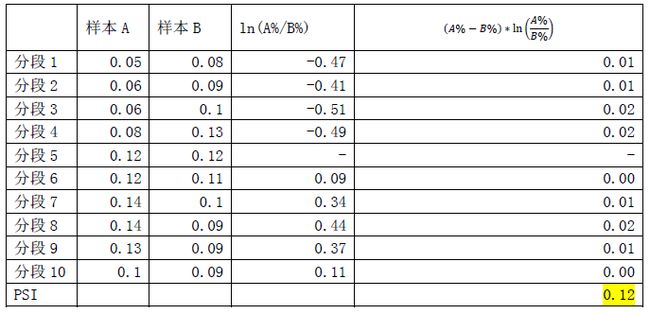
以“联名贷”产品申请评分卡监测过程为例,代码实现:
realdata<-read.csv("C:/Users/5609/Desktop/每日定时报表/20171023/CacheData_LMD.csv",header = TRUE)
modeldata<-read.csv("D:/sissi/联名贷/联名贷分数_建模样本.csv",header=TRUE)
realdata$申请日期<-as.Date(realdata$time)
modeldata$申请日期<-as.Date(modeldata$申请日期)
vars <- read.table("variable list.txt", sep = "\t")
vars <- as.character(vars[,1])
for (i in vars){
if(is.character(modeldata[,i]) | is.logical(modeldata[,i])){
modeldata[,i] <- as.factor(modeldata[,i])
}
}
modeldata1<-modeldata[,c("申请编号","申请日期",vars,"pred","groups","groups_n")]
realdata1<-realdata[,c("申请编号","申请日期",vars,"final_score","group")]
# 联名贷评分卡分组
breaks_g <- c( 0, 3.67,
4.49,
5.21,
5.99,
6.83,
8.02,
9.59,
12.44,
19.90,
100.00
)
realdata1$groups <- cut(realdata1$final_score, breaks = breaks_g, include.lowest = FALSE, right = TRUE)
realdata1$groups_n<-as.numeric(realdata1$groups)
####建模数据
tab <- summary(modeldata$groups)
write.table(tab, "clipboard", sep = "\t")
t1 <- summary(modeldata$groups)/dim(modeldata)[1]
write.table(t1, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 每组样本量 更新至excel
tab <- summary(realdata1$groups)
write.table(tab, "clipboard", sep = "\t")
# 每组占比 更新至excel
t2 <- summary(realdata1$groups)/dim(realdata1)[1]
write.table(t2, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
PSI <- sum((t2-t1)*log(t2/t1))
PSI
# 变量 PSI ----------------------------------------------------------------
vars <- read.table("variable list.txt", sep = "\t")
vars <- as.character(vars[,1])
# 调整变量值 (评分卡对输入变量的值有调整,将调整后的值与建模时的数据做比较)
#loan_query_12MA_level
realdata1$loan_query_12MA_level <- cut(realdata1$loan_query_12MA, breaks = c(0, 1.5,Inf),
include.lowest = TRUE)
realdata1$loan_query_12MA_level <- as.character(realdata1$loan_query_12MA_level)
index <- is.na(realdata1$loan_query_12MA_level)
realdata1[index, "loan_query_12MA_level"] <- "NA"
realdata1$loan_query_12MA_level <- as.factor(realdata1$loan_query_12MA_level)
levels(realdata1$loan_query_12MA_level) <- c( "2_(1.5,Inf]", "1_[0,1.5] & NA","1_[0,1.5] & NA" )
realdata1$loan_query_12MA_level <- as.character(realdata1$loan_query_12MA_level)
# 未结清贷款笔数
realdata1$未结清贷款笔数_level <- cut(realdata1$未结清贷款笔数_level,
breaks = c(0, 5, Inf),
include.lowest = TRUE, right = FALSE)
realdata1$未结清贷款笔数_level <- as.factor(as.character(realdata1$未结清贷款笔数_level))
index <- is.na(realdata1$未结清贷款笔数_level)
realdata1[index, "未结清贷款笔数_level"] <- "[0,5)"
#贷款类别
realdata1$贷款类别 <- as.factor(as.character(realdata1$贷款类别))
levels(realdata1$贷款类别) <- c( "新贷款", "再贷","续贷" )
modeldata1[, "贷款类别"] <- ordered(
modeldata1[, "贷款类别"],
levels=c("新贷款", "再贷", "续贷"),
labels=c('新贷款', '再贷', '续贷')
);
table(modeldata1[, "贷款类别"])
#modeldata1[order(modeldata1[, "贷款类别"]),]
#名下物业数量_所有联名人
index <- is.na(realdata1$名下物业数量_所有联名人)
realdata1[index, "名下物业数量_所有联名人"] <- 0
index <- realdata1$名下物业数量_所有联名人 > 3
realdata1[index, "名下物业数量_所有联名人"] <- 3
#要求贷款期限_level
realdata1$要求贷款期限_level <- cut(realdata1$要求贷款期限, breaks = c(0,18,36),
include.lowest = FALSE, right = TRUE)
realdata1$HZ_score<-realdata1$HZ_score/100
realdata1$主贷人分数<-realdata1$主贷人分数/100
PSI <- NULL
########"HZ_score"
var_name <- "HZ_score"
breaks_v <- unique(quantile(modeldata1[,var_name], seq(0,1,.2), na.rm = TRUE))
N <- length(breaks_v)
breaks_v <- c(-99,breaks_v[2:(N-1)], Inf)
breaks_v
modeldata1$groups_v <- cut(modeldata1[, var_name], breaks = breaks_v, include.lowest = TRUE, right = FALSE)
index <- !is.na(modeldata1[,var_name])
t1 <- summary(modeldata1[index,"groups_v"])/sum(index)
realdata1$groups_v <- cut(realdata1[, var_name], breaks = breaks_v, include.lowest = TRUE, right = FALSE)
index <- !is.na(realdata1[,var_name])
t2 <- summary(realdata1[index,"groups_v"])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[1] <- sum((t2-t1)*log(t2/t1))
########"主贷人分数"
var_name <- "主贷人分数"
breaks_v <- unique(quantile(modeldata1[,var_name], seq(0,1,.2), na.rm = TRUE))
N <- length(breaks_v)
breaks_v <- c(-99,breaks_v[2:(N-1)], Inf)
breaks_v
modeldata1$groups_v <- cut(modeldata1[, var_name], breaks = breaks_v, include.lowest = TRUE, right = FALSE)
index <- !is.na(modeldata1[,var_name])
t1 <- summary(modeldata1[index,"groups_v"])/sum(index)
realdata1$groups_v <- cut(realdata1[, var_name], breaks = breaks_v, include.lowest = TRUE, right = FALSE)
index <- !is.na(realdata1[,var_name])
t2 <- summary(realdata1[index,"groups_v"])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[2] <- sum((t2-t1)*log(t2/t1))
########loan_query_12MA_level
modeldata1$loan_query_12MA_level<-as.character(modeldata1$loan_query_12MA_level)
var_name <- "loan_query_12MA_level"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[3] <- sum((t2-t1)*log(t2/t1))
#######未结清贷款笔数_level
#modeldata1$未结清贷款笔数_level<-as.character(modeldata1$未结清贷款笔数_level)
var_name <- "未结清贷款笔数_level"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[4] <- sum((t2-t1)*log(t2/t1))
########名下物业数量_所有联名人
#modeldata1$名下物业数量_所有联名人<-as.character(modeldata1$名下物业数量_所有联名人)
#realdata1$名下物业数量_所有联名人<-as.character(realdata1$名下物业数量_所有联名人)
var_name <- "名下物业数量_所有联名人"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[5] <- sum((t2-t1)*log(t2/t1))
########要求贷款期限_level
modeldata1$要求贷款期限_level<-as.character(modeldata1$要求贷款期限_level)
var_name <- "要求贷款期限_level"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[6] <- sum((t2-t1)*log(t2/t1))
###########最近1_3月信用卡是否逾期
var_name <- "最近1_3月信用卡是否逾期"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[7] <- sum((t2-t1)*log(t2/t1))
###########贷款类别
var_name <- "贷款类别"
index <- !is.na(modeldata1[,var_name])
t1 <- table(modeldata1[index,var_name])/sum(index)
index <- !is.na(realdata1[,var_name])
t2 <- table(realdata1[index,var_name])/sum(index)
sum((t2-t1)*log(t2/t1))
PSI[8] <- sum((t2-t1)*log(t2/t1))PSI<0.1 样本分布有微小变化 PSI 0.1~0.2 样本分布有变化 PSI>0.2 样本分布有显著变化
计算完建模变量的PSI值,需要重点关注PSI>0.2的变量,说明这几项的分布较建模时已经发生比较显著的变化,需要考虑是否是客户质量变化引起的PSI变动。
##### 观测PSI大于0.2的变量#####
xx<-tapply(Data$未结清贷款笔数, substr(aa$申请日期,1,7),mean, na.rm = TRUE)
write.table(xx, "clipboard", sep = "\t", col.names = FALSE, row.names = TRUE)
yy<-tapply(Data$名下物业数量_所有联名人, substr(aa$申请日期,1,7),mean, na.rm = TRUE)
write.table(yy, "clipboard", sep = "\t", col.names = FALSE, row.names = TRUE)
zz<-tapply(Data$要求贷款期限, substr(aa$申请日期,1,7),mean, na.rm = TRUE)
write.table(zz, "clipboard", sep = "\t", col.names = FALSE, row.names = TRUE)此为实例数据,可以看到PSI>0.2的变量较建模初期存在较大波动,风控部门提供监测数据,业务部门需总结变量出现异常性或趋势性波动的原因。
2. 坏账变现
以9个月内逾期60天为坏账标准,或12个月内逾期90天为坏账标准,观测模型的表现。(坏账标准具体需根据不同产品来定义) 我常用的坏账监测标准:60days/9m;90days/12m;30+监测(适用于续贷产品或催收评分卡) 监测所使用的统计量:可使用AUC,KS来监测评分卡模型在样本上的预测效果。
以后置评分卡监测过程为例,代码实现:
# 模型表现 60d/9M --------------------------------------------------------------
# 读取数据 合并
Data2016 <- read.csv("d:/sissi/Data/2016Data/HZ_score_201601_201606.csv", header = TRUE)
Data201607 <- read.csv("d:/sissi/Data/2016Data/HZ_score_201607_201612.csv", header = TRUE)
index <- Data2016$app_no %in% Data201607$app_no
Data2016 <- Data2016[!index,]
Data2016 <- rbind(Data2016, Data201607)
# 对数据进行新版分组
breaks_g <- c(0,
3.73,
4.45 ,
5.05 ,
5.61 ,
6.21 ,
6.87 ,
7.54 ,
8.25 ,
9.14 ,
10.02 ,
11.09 ,
12.13 ,
13.24 ,
14.66 ,
16.67 ,
19.20 ,
22.96 ,
28.73 ,
39.24 ,
100.00
)
Data2016$groups <- cut(Data2016$score, breaks = breaks_g, include.lowest = FALSE, right = TRUE)
# 读取Data Source需更新至最新
DS <- read.csv("D:/sissi/ds201710/DataSource-2017年10月10日.csv", header = TRUE)
Data2016 <- merge(Data2016, DS[,c("申请编号", "合同起始日", "状态.贷前.","录单营业部","贷款产品")], by.x = "app_no", by.y = "申请编号", all.x = TRUE)
Data2016 <- Data2016[Data2016$合同起始日!="",]
Data2016$合同起始日 <- as.Date(Data2016$合同起始日)
# 读取2015年数据
Data2015 <- read.csv("D:/sissi/后置/Score_HZ_201206_201512.csv", header = TRUE)
Data2015 <- Data2015[!duplicated(Data2015$app_no),]
Data2015 <- merge(Data2015, DS[,c("申请编号", "状态.贷前.", "合同起始日","是否联名贷款","实际贷款额度","要求贷款额度","录单营业部","贷款产品")], by.x = "app_no", by.y = "申请编号", all.x = TRUE)
Data2015 <- Data2015[Data2015$合同起始日!="",]
Data2015$合同起始日 <- as.Date(Data2015$合同起始日)
Data2015$groups <- cut(Data2015$pred_refitted*100, breaks = breaks_g, include.lowest = FALSE, right = TRUE)
Data2016$pred_refitted <- Data2016$score/100
# 合并数据
vars <- c( "app_no" , "合同起始日" ,"pred_refitted","状态.贷前.","groups","录单营业部","贷款产品")
Data_all <- rbind(Data2015[,vars], Data2016[,vars])
# 读取旧评分卡分数
old_score_card1 <- read.csv("D:/sissi/评分卡监测/20170206/旧版评分卡分数_201510_201608.csv")
old_score_card2<-SCORE_CARD_RESULT[,c("申请编号","后置评分卡计算结果")]
old_score_card<-rbind(old_score_card1,old_score_card2)
old_score_card<-old_score_card[!(duplicated(old_score_card$申请编号)),]
breaks_g_old <- c(0,6.84, 8.97, 10.58, 12.12, 13.4, 14.75,
16.19, 17.56, 19.02, 20.46, 22, 23.93, 26.14,
28.58, 31.46, 35.16, 39.76, 45.86, 54.97, 100)
old_score_card$后置评分卡计算结果<-as.numeric(old_score_card$后置评分卡计算结果)
old_score_card$分组 <- cut(old_score_card$后置评分卡计算结果, breaks = breaks_g_old, include.lowest = FALSE, right = TRUE)
old_score_card <- old_score_card[!duplicated(old_score_card$申请编号),]
# 从OverDueDate报表中读取9个月时的逾期状态 Dates中日期需更新至最新一月一号 OverDueDate报表需保存成csv格式
data_out <- NULL
Dates <- c("2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01",
"2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01",
"2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01",
"2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01",
"2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01",
"2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01",
"2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01",
"2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01",
"2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01",
"2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01",
"2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01",
"2017-07-01","2017-08-01","2017-09-01","2017-10-01")
Table <- matrix(nrow = 100, ncol = 7)
for (i in 1:(length(Dates)-10)) {
StartDate <- Dates[i]
EndDate <- Dates[i+1]
Date1 <- Dates[i+10]
file1 <- paste("D:/sissi/OverdueDaily/OverDueDate",Date1,".csv",sep = "")
overdue <- read.csv(file1, header = TRUE, sep = ",")
data <- subset(Data_all, Data_all$合同起始日 < EndDate & Data_all$合同起始日 >= StartDate)
if (dim(data)[1]==0) {next }
data <- merge(data, overdue[, c("申请编号","逾期天数","逾期日期","贷款剩余本金","账户状态")],
by.x = "app_no", by.y = "申请编号", all.x = TRUE)
data[is.na(data$逾期天数), "逾期天数"] <- 0
data$overdue60 <- ifelse(data$逾期天数>=60, TRUE, FALSE)
index <- !is.na(data$账户状态) & data$账户状态 %in% c("ACCOOA","RWOCOOA", "RWOCORA", "RWOCOXX","WOCOOA", "WOCORA", "WOCOXX")
data[index, "overdue60"] <- TRUE
index <- data$overdue60 == FALSE
data[index, "贷款剩余本金"] <- 0
data <- data[,c("app_no","逾期日期","逾期天数","overdue60","贷款剩余本金")]
if (is.null(data_out)) {
data_out <- data
} else {
data_out <- rbind(data_out,data)
}
}
Data_all <- merge(Data_all, data_out[,c("app_no", "overdue60","贷款剩余本金")], by = "app_no", all.x = TRUE)
Data_all <- merge(Data_all, DS[,c("申请编号", "实际贷款额度", "贷款类别","申请日期","合作方")], by.x = "app_no", by.y = "申请编号", all.x = TRUE)
Data_all$申请日期 <- as.Date(Data_all$申请日期)
Data_all <- subset(Data_all, Data_all$状态.贷前.=="AC" & Data_all$贷款类别 != "续贷")
Data_all <- merge(Data_all, old_score_card[, c("申请编号", "后置评分卡计算结果","分组")],
by.x = "app_no", by.y = "申请编号", all.x = TRUE)
# 有2笔债务重组无评分卡分数
index <- !is.na(Data_all$后置评分卡计算结果) & !is.na(Data_all$overdue60) &
Data_all$合同起始日 >= "2015-11-01" & Data_all$申请日期 >= "2015-11-01" & !is.na(Data_all$overdue60)
# 旧版评分卡AUC
gbm.roc.area(Data_all[index,"overdue60"],Data_all[index,"后置评分卡计算结果"]/100)
# 新版评分卡AUC
gbm.roc.area(Data_all[index,"overdue60"],Data_all[index,"pred_refitted"])
subData1 <- Data_all[index,]
# 新版评分卡KS
b_points <- quantile(subData1$pred_refitted, seq(0,1,.01))
C_R <- NULL
C_N <- NULL
for (i in 1:100){
index <- subData1$pred_refitted<=b_points[i+1]
C_R[i] <- sum(subData1[index, "overdue60"]==1)/sum(subData1[,"overdue60"]==1)
C_N[i] <- sum(subData1[index, "overdue60"]==0)/sum(subData1[,"overdue60"]==0)
}
KS <- max(C_N - C_R)
KS
# 旧版评分卡 KS
b_points <- quantile(subData1$后置评分卡计算结果/100, seq(0,1,.01))
C_R <- NULL
C_N <- NULL
for (i in 1:100){
index <- subData1$后置评分卡计算结果/100<=b_points[i+1]
C_R[i] <- sum(subData1[index, "overdue60"]==1)/sum(subData1[,"overdue60"]==1)
C_N[i] <- sum(subData1[index, "overdue60"]==0)/sum(subData1[,"overdue60"]==0)
}
KS <- max(C_N - C_R)
KS
# 新版每组坏账 (A/C)
tab <- tapply(subData1$overdue60, subData1$groups, mean)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 新版每组样本量
tab <- tapply(subData1$overdue60, subData1$groups, length)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
#新版每组占比
tab <- tapply(subData1$overdue60, subData1$groups, length)/dim(subData1)[1]
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 新版每组逾期金额
tab <- tapply(subData1$贷款剩余本金, subData1$groups, sum)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 新版每组合同金额
tab <- tapply(subData1$实际贷款额度, subData1$groups, sum)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 旧版每组坏账 (A/C)
tab <- tapply(subData1$overdue60, subData1$分组, mean)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 旧版每组样本量
tab <- tapply(subData1$overdue60, subData1$分组, length)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
#旧版每组占比
tab <- tapply(subData1$overdue60, subData1$分组, length)/dim(subData1)[1]
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 旧版每组逾期金额
tab <- tapply(subData1$贷款剩余本金, subData1$分组, sum)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 旧版每组合同金额
tab <- tapply(subData1$实际贷款额度, subData1$分组, sum)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)
# 按新版每组比例对旧版进行重新分组 将新版cumulative占比结果更新至下面quantile函数
breaks_g <- quantile(subData1$后置评分卡计算结果, c(0, 0.0626,
0.1170 ,
0.1749 ,
0.2244 ,
0.2863 ,
0.3463 ,
0.3997 ,
0.4527 ,
0.5158 ,
0.5744 ,
0.6339 ,
0.6783 ,
0.7214 ,
0.7686 ,
0.8232 ,
0.8691 ,
0.9108 ,
0.9522 ,
0.9835 ,
1.0000
))
subData1$分组_new <- cut(subData1$后置评分卡计算结果, breaks = breaks_g, include.lowest = TRUE, right = FALSE )
# 旧版新分组 坏账率(A/C)
tab <- tapply(subData1$overdue60, subData1$分组_new, mean)
write.table(tab, "clipboard", sep = "\t")
# 旧版新分组 样本量
tab <- tapply(subData1$overdue60, subData1$分组_new, length)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE)
# 旧版新分组 逾期金额
tab <- tapply(subData1$贷款剩余本金, subData1$分组_new, sum)
write.table(tab, "clipboard", sep = "\t")
# 旧版新分组 合同金额
tab <- tapply(subData1$实际贷款额度, subData1$分组_new, sum)
write.table(tab, "clipboard", sep = "\t", row.names = FALSE, col.names = FALSE)3. 拒绝原因
针对每个变量,根据其取值,按照样本量平均分为3~5组,计算每一组中的平均得分。对每一个客户的各个变量,根据实际值落入的组判断对应的平均分X, 再减去该变量各组平均分的最小值X_min, X-X_min为该变量对应的差值。将每个变量对应的差值从高到低排序,输出头三个不同的拒绝原因。例如,最近120天内查询这个变量,根据其样本中的取值,可以分为5组,每组中的平均分数如下:
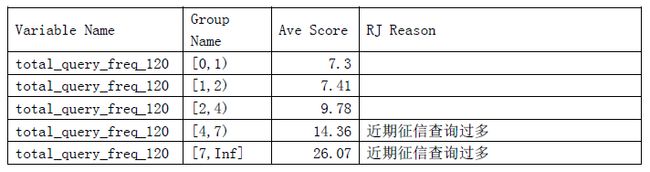
某客户,其最近120天内查询次数为4次,落入第四组,该组平均得分为14.36,全部5组中,最低分为7.3,所以该客户这个变量对应的差值为7.06. 对应的拒绝原因为“近期征信查询过多”。将该客户的所有变量按照同样的方法计算差值,再排序,可得到输出的拒绝原因。
该部分代码主要监测被拒绝客户的拒绝原因,以及被评分卡拒绝的客户的拒绝原因明细。
# 读取拒绝原因 需更新至最新
RJ_REASON <- read.table("D:/sissi/评分卡监测/20171017/V_RJ_REASON_DETAIL.txt", header = TRUE,stringsAsFactors=FALSE)
RJ_REASON1 <- read.table("D:/sissi/评分卡监测/20171017/V_RJ_REASON_DETAIL1.txt", header = TRUE,stringsAsFactors=FALSE)
RJ_REASON<-rbind(RJ_REASON,RJ_REASON1)
RJ_REASON<-RJ_REASON[!(duplicated(RJ_REASON$申请编号)),]
RJ_REASON <- RJ_REASON[RJ_REASON$申请编号!="null" & !is.na(RJ_REASON$申请编号),]
RealData <- merge(RealData, SCORE_CARD_RESULT[, c("申请编号", "后置评分卡计算结果", "后置评分卡分组")],
by.x = "app_no", by.y = "申请编号", all.x = TRUE)
RealData <- merge(RealData, RJ_REASON[, c("申请编号", "状态","拒绝原因","贷款类型","贷款产品")],
by.x = "app_no", by.y = "申请编号", all.x = TRUE)
RealData <- merge(RealData, DS[, c("申请编号", "状态.贷前.", "主拒绝原因" )], by.x = "app_no", by.y = "申请编号", all.x = TRUE)
index <- is.na(RealData$状态)
RealData[index, "状态"] <- RealData[index, "状态.贷前."]
# 拒绝原因 --------------------------------------------------------------------
index <- is.na(RealData$拒绝原因) | RealData$拒绝原因 == "null"
RealData$拒绝原因 <- as.character(RealData$拒绝原因)
RealData[index, "拒绝原因"] <- as.character(RealData[index, "主拒绝原因"])
index <- RealData$状态.贷前.=="RJ"
subData <- RealData[index,]
summary(subData)
# 整体被拒绝原因
library(stringr)
temp <- unlist(str_split(subData[,"拒绝原因"], ","))
tab <- summary(as.factor(temp))
write.table(tab, "clipboard", sep = "\t")
# 被评分卡拒绝的
index <- RealData$状态.贷前.=="RJ" & grepl("综合评分差", RealData$拒绝原因)
subData <- RealData[index,]
# 拒绝原因1
tab <- summary(subData$RJ_reason1)
write.table(tab, "clipboard", sep = "\t")
# 拒绝原因2
tab <- summary(subData$RJ_reason2)
write.table(tab, "clipboard", sep = "\t")
# 拒绝原因3
tab <- summary(subData$RJ_reason3)
write.table(tab, "clipboard", sep = "\t")关于监测频率,对于一般金融产品,以每月一次的监测频率进行监测;对于催收评分卡或某些特殊需求的金融产品,需每周做一次监测。监测结果需定时上传,在监测指标明显波动的情况下需考虑更新或重建评分卡。