Kylin集群模式部署(使用同一HBase存储)
HDP版本:3.0
Kylin版本:2.6.0
前言
本文主要讲解如何部署Kylin集群,采取多个Kylin实例共享HBase存储的模式,如果需要事先了解Kylin基本概念的朋友可以点击这里前往。
一、安装启动Kylin
首先安装一个Kylin实例,然后再分析Kylin集群模式部署的注意点。
1. 下载源码
这里使用的是Kylin-2.6.0的版本,如果需要其它版本的话,请点击这里
cd /usr/hdp/3.0.1.0-187/
wget https://dist.apache.org/repos/dist/dev/kylin/apache-kylin-2.6.0-rc1/apache-kylin-2.6.0-bin-hadoop3.tar.gz
mv apache-kylin-2.6.0-bin-hadoop3.tar.gz kylin
2. 修改配置文件
启动kylin服务时,会在Retrieving hive dependency…卡住,需要手动敲两下回车或者任意命令才可以继续往下执行,否则会一直被卡住。
觉得是由于Hive版本升级,hive命令行仅支持JDBC操作,所以需要输入用户名和密码所导致的Retrieving hive dependency…卡住。
解决办法是:修改kylin配置,将hive执行模式改为beeline。
cd /usr/hdp/3.0.1.0-187/kylin
vim conf/kylin.properties
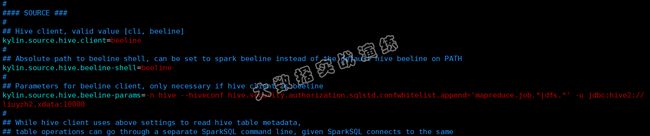
修改kylin.properties文件:
Kylin的配置项有很多,大部分的配置项都是采用的默认的配置。在这里我们需要设置一下hive的执行模式为beeline。
## Hive client, valid value [cli, beeline]
kylin.source.hive.client=beeline
## Absolute path to beeline shell, can be set to spark beeline instead of the default hive beeline on PATH
kylin.source.hive.beeline-shell=beeline
## Parameters for beeline client, only necessary if hive client is beeline
kylin.source.hive.beeline-params=-n hive --hiveconf hive.security.authorization.sqlstd.confwhitelist.append='mapreduce.job.*|dfs.*' -u jdbc:hive2://liuyzh2.xdata:10000
配置如下图所示:
3. 启动
Kylin在基于默认配置的情况下启动需要依赖HDFS、YARN、MapReduce、Hive、HBase。
在启动kylin服务之前,还需要搞定以下两点:
- 选择运行kylin服务的用户
由于kylin的底层存储还是在HDFS上,所以建议大家还是使用hdfs用户来启动kylin服务,以避免在构建cubu过程中报hdfs文件权限的问题。
之前,我曾尝试过使用kylin用户来启动kylin服务,但是最后我放弃了。举个例子:Hive的存储目录是 /warehouse/tablespace/managed/hive,由于该目录的文件权限是700,普通用户kylin是没有办法访问这个目录的,需要将该目录设置为777,或者通过hdfs的setfacl命令,将kylin用户设置为对该目录具有读写可执行的权限。对于后期使用ambari集成kylin服务老说太过于麻烦,也害怕后续还会有类似的文件权限的报错。
所以最后选用了使用hdfs用户来启动kylin服务,省心!
- 解决hive用户不能访问
/kylin/kylin_metadata
/kylin/kylin_metadata文件主要存储同步Hive表基数的相关文件,以及存储构建cube的相关信息。需要hive用户访问这个目录。
su hdfs
hdfs dfs -mkdir -p /kylin/kylin_metadata
hdfs dfs -chmod -R 777 /kylin/kylin_metadata
前期工作准备好之后,使用hdfs用户来启动kylin服务:
su hdfs
chown -R hdfs:hdfs /usr/hdp/3.0.1.0-187/kylin
/usr/hdp/3.0.1.0-187/kylin/bin/kylin.sh start
二、搭建kylin集群
1. 以下来自kylin官网资料:
Kylin 实例是无状态的服务,运行时的状态信息存储在 HBase metastore 中。 出于负载均衡的考虑,您可以启用多个共享一个 metastore 的 Kylin 实例,使得各个节点分担查询压力且互为备份,从而提高服务的可用性。下图描绘了 Kylin 集群模式部署的一个典型场景:
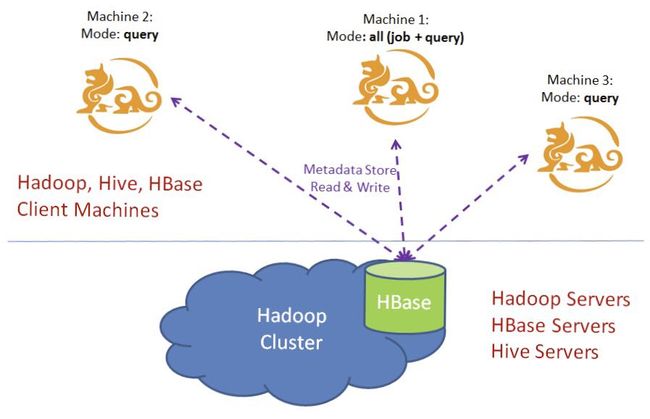
如果您需要将多个 Kylin 节点组成集群,请确保他们使用同一个 Hadoop 集群、HBase 集群。然后在每个节点的配置文件 $KYLIN_HOME/conf/kylin.properties 中执行下述操作:
- 配置相同的
kylin.metadata.url值,即配置所有的 Kylin 节点使用同一个 HBase metastore。 - 配置 Kylin 节点列表
kylin.server.cluster-servers,包括所有节点(包括当前节点),当事件变化时,接收变化的节点需要通知其他所有节点(包括当前节点)。 - 配置 Kylin 节点的运行模式
kylin.server.mode,参数值可选all,job,query中的一个,默认值为all。job模式代表该服务仅用于任务调度,不用于查询;query模式代表该服务仅用于查询,不用于构建任务的调度;all模式代表该服务同时用于任务调度和 SQL 查询。
注意:默认情况下只有一个实例用于构建任务的调度 (即 kylin.server.mode 设置为 all 或者 job 模式)。
2. kylin配置
假如现在我们有三台机器,在每一台机器里都安装一个kylin服务。使用同一HBase存储,用Nginx做负载均衡。
将之前配置好的kylin源码拷贝至其余两台机器上的相同目录下。需要配置或检查以下三个配置项,其余保持默认即可。
# 配置所有的 Kylin 节点使用同一个 HBase metastore。
kylin.metadata.url=kylin_metadata@hbase
# 配置 Kylin 节点的运行模式
kylin.server.mode=all or job or query
# 将所有的 kylin 服务都写在一起。当事件变化时,接收变化的节点需要通知其他所有节点(包括当前节点)。
kylin.server.cluster-servers=node71.xdata:7070,node73.xdata:7070,node72.xdata:7070
默认情况下只有一个实例用于构建任务的调度,即仅有一台kylin可以配置为kylin.server.mode=all或kylin.server.mode=job,其余机器的kylin配置为kylin.server.mode=query。
3. Nginx配置
使用Nginx来对Ktlin集群做负载均衡,以下为nginx.conf文件内容:
user root;
worker_processes auto;
error_log /var/log/nginx/error.log;
error_log /var/log/nginx/error.log notice;
error_log /var/log/nginx/error.log info;
pid /var/run/nginx/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log;
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
#gzip on;
server {
listen 81;
server_name localhost;
#charset koi8-r;
location / {
proxy_pass http://kylin.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
upstream kylin.com {
ip_hash;
server node71.xdata:7070;server node73.xdata:7070;server node72.xdata:7070;
}
}
为了维持session会话持久性,避免频繁刷新页面出现kylin登陆页面进行登陆,需要在nginx.conf文件内配置ip_hash。
关于Nginx的安装,需要提前编译,编译通过后才可以使用,并且依赖于当前目录。如果之后需要移动nginx目录的话,则需要再次编译nginx,才可以重新使用。
关于Nginx的安装,可参考Nginx安装配置。
将Nginx服务以及所有节点的kylin服务启动,我们可以在浏览器中输入:http://10.6.6.73:81/kylin/,来访问我们的Kylin集群。
三、集成Kylin服务到Ambari
之前,我写了一片文章,是集成Apache Kylin 2.5.1服务到Ambari2.6.1,可参考Ambari2.6.1集成Apache Kylin服务。
之后,我又集成了Apache Kylin 2.6.0服务到Ambari2.7.1。
现在已将Kylin的自定义服务上传至github,具体地址:Ambari集成Apache Kylin服务(离线部署、可支持HDP 2.6+及HDP 3.0+。
码字不易,如果您觉得文章写得不错,请扫码关注公众号支持作者~ 您的关注是我写作的最大动力
