浅谈Web请求过程
1B/S网络架构
1.1 为什么使用该架构(好处)
随着Web2.0时代的到来,互联网架构,由传统的C/S架构(Client/Server)逐渐过渡到B/S架构(Browser/Server),B/S架构带来的好处:
(1) 客服端使用统一浏览器。一方面,浏览器具有统一性,从而有效屏蔽了不同服务提供商提供给用户使用服务的差异性;另一方面,浏览器的交互特性具有用户使用继承性,即用户使用了这个浏览器之后就有了使用其他浏览器的经验,彼此差不多,经验可复用。
(2) 服务端基于统一的HTTP协议。使用统一的HTTP标准(所有开发者都要遵从),为服务提供商简化了开发模式,节省开发成本,服务开发者只需要关注提供服务的应用逻辑(不需关注协议通信等,只需要关注业务逻辑,所以此架构简化了服务器提供者的开发)。
既然如此,用户在浏览器中一次简单的点击到看到返回信息的操作,这期间到底发生了什么?涉及到哪些技术?
1.2架构特点
传统C/S架构采用的长连接的交互模式,B/S网络架构从前端到后端都是基于统一的应用层协议HTTP来交互数据,采用无状态、短链接的通信模式(一次请求获取一次数据,然后断开通信连接,可以让其他更多用户连接通信),所以就有了如下好处:
(1)满足海量用户访问请求;(2)保持用户请求的快速响应。
无论网络架构如何,都有一些共性原则需要遵守:
- 必须要有一个统一资源定位符URL(独一无二的URL,用来寻找资源)
- 必须要遵守HTTP协议与服务端交互(统一的访问资源的规则、协议或招呼方式)
- 必须在浏览器中展示(渲染)返回的数据。
那么,如上文所问,用户的一次简单的店家操作是如何发起一个请求呢?
1.3 如何发出一个请求的过程
发起一个HTTP请求的过程就是建立一个Socket通信的过程:
- 用户在浏览器输入网址,在浏览器建立Socket连接之前,必须根据地址栏里写入的URL的域名DNS解析出IP地址
- 再根据这个IP地址和默认的80端口与远程服务器建立Socket连接
- 然后浏览器根据这个url组装成一个get类型的HTTP请求头,发送给目标服务器
- 服务器执行逻辑,返回结果数据,断开连接。
[linux环境]: Linux下可以使用curl+url就可以简单发起HTTP请求。查看http头信息,加上-I选项,例子如下:
curl “http://www.baidu.com”
curl “http://www.baidu.com” –I
2 理论分析
了解了浏览器是如何发出一个请求的,那么就说一下发起web请求过程所涉及的技术:
2.1 HTTP解析
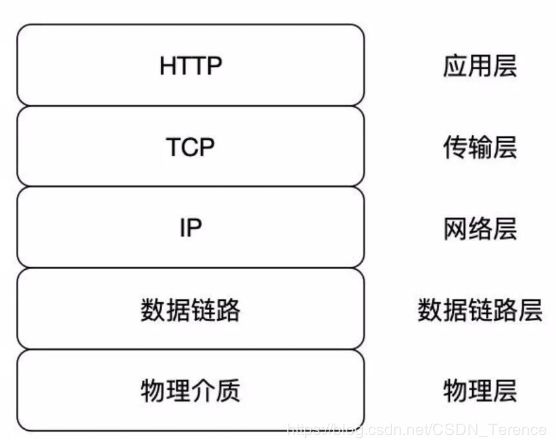
HTTP(超文本传输协议)是应用层上的一种客户端/服务端模型的通信协议,它由请求和响应构成,且是无状态的。
协议内容:
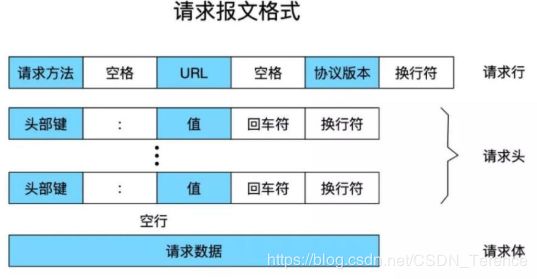
请求(Request)客户端发送一个HTTP请求到服务端的格式:
-
请求行
-
请求头
-
请求体

(认识http类型的请求url参考:认识url结构)
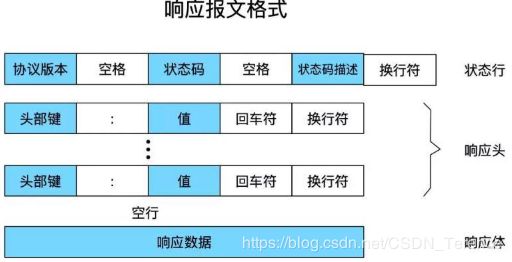
响应(Response)服务端响应客户端格式:
-
状态行
-
响应头
-
响应体

常见的http请求方法:GET POST PUT PATCH DELETE OPTIONS CONNECT HEAD TRACE
常见的http请求头:
| 请求头 |
说明 |
| Accept-Charset |
用于指定客户端接受的字符集 |
| Accept-Encoding |
用于指定可接受的内容编码 |
| Accept-Language |
用于指定一种自然语言 |
| Host |
用与指定被请求资源的Intent主机和端口号 |
| User-Agent |
客服端将他的操作系统、览器和其他属性告诉服务器 |
| Connection |
当前连接是否保持 |
常见的http响应头:
| 响应头 |
说明 |
| Server |
使用服务器名称 |
| Content-Type |
用来指明发送给接收者的实体正文的媒体类型 |
| Content-Encoding |
与请求报头Accept-Encoding对应,告诉浏览器服务端采用的是什么压缩编码 |
| Content-Language |
描述了资源所用的自然语言 |
| Content-Length |
指明实体正文的长度,用以字节方式存储的十进制数字来表示 |
| Keep-Alive |
保存连接的时间,如Keep-Alive:timeout=5 max=120 |
常见http状态码【重要】
| 状态码 |
说明 |
| 200 |
客户端请求成功,OK |
| 302 |
临时跳转,跳转的地址通过Location指定 |
| 400 |
客户端请求有语法错误,不能被服务器识别 |
| 403 |
服务器收到请求,但拒绝提供服务 |
| 404 |
请求的资源不存在 |
| 500 |
服务器发生不可预期的错误 |
2.2 浏览器缓存机制
浏览器缓存是一个比较复杂但是又比较重要的机制。按ctrl+f5组合键刷新页面,会重新请求服务器,即使是请求服务器,也有可能服务器的前端部署一个缓存服务器,为了让用户能够看到最新数据,必须通过HTTP来控制。在请求头加上Pragma:no-cache和Cache-Control:no-cache。
HTTP Head字段用于指定所有缓存机制在整个请求响应链中必须服从的指令。
HTTP Head字段的可选值:
Public:所有内容都被缓存,在响应头设置。
Private:内容只缓存到私有缓存中,在响应头设置。
No-cache: 所有内容不会被缓存
No-store:所有内容不会被缓存到缓存或Intent临时文件中
Must-revalidation/proxy-revalidation:如果缓存内容失败,请求必须发送到服务器进行重新验证
Max-age=xx:缓存内容在xxx秒后失效,这个只在HTTP1.1可用。
Expires:通常使用格式是:Expries:Sat,25 Feb 2012 12:22:17 GMT 后面跟着一个日期和时间,超过这个时间值,缓存的内容将失效。也就是浏览器在发出请求之前检查这个页面这个字段。
Last-Modified/Etag:
Last-Modified字段一般用于一个服务器上的资源最后修改时间,资源可以是静态(静态内容自动加上Last-Modified)或者动态的内容(Servlet提供一个getLastModified方法用于检查某个动态内容是否已经更新),通过这个最后修改时间可以判断当前请求的资源是否最新的。
浏览器再次请求子啊请求头增加一个If-Modified-Since: 字段,询问当前缓存的页面是否最新。如果最新,服务器返回304.
Etag这个字段让服务器给每个一个页面分配一个唯一编号,区分当前这个页面是否最新的。如果多台服务器,就比较难处理。
2.3 DNS域名解析
DNS域名解析是为了将URL域名解析成IP地址
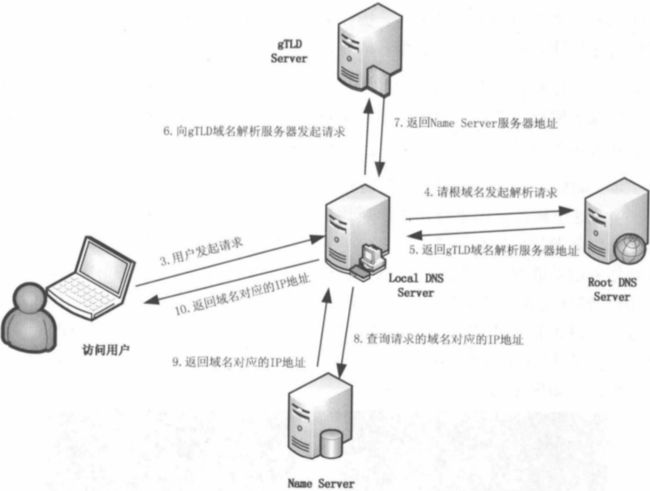
1.浏览器缓存检查(本机),其中域名被缓存的时间限制可以通过TTL属性来限制。
2.操作系统缓存检查(本机)+hosts解析(本机)
操作系统域名解析过程,可自行设置ip:
Windows: C:/Windows/System32/drivers/etc/hosts
Linux: /etc/hosts
3.本地域名服务器解析(LDNS,当前地区的域名解析服务器)。
这个专门的域名解析服务器性能都会很好,它们一般都会缓存域名解析结果,大约80%的域名解析都到这里就已经完成了,所以LDNS主要承担了域名的解析工作。
4.根域名服务器解析(Root Server)
5.根域名服务器返回给本地域名服务器一个所查询域的主域名服务器(gTLD Server)地址,gTLD是国际顶级域名服务器, 如.com、.cn、.org等,全球只有13台左右。
6.本地域名服务器(Local DNS Server)根据gTLD服务器地址,请求gTLD解析。
7.接受请求的gTLD服务器查找并返回此域名对应的Name Server域名服务器的地址。(这个Name Server通常就是你注册的域名服务器,例如你在某个域名服务提供商申请的域名,那么这个域名解析任务就由这个域名提供商的服务器来完成。)
8.Name Server域名服务器会查询存储的域名和IP的映射关系表,正常情况下都根据域名得到目标IP记录,连同一个TTL值返回给DNS Server域名服务器。
9.返回该域名对应的IP和TTL值,Local DNS Server会缓存这个域名和IP的对应关系,缓存的时间由TTL值控制。
10.把解析的结果返回给用户,用户根据TTL值缓存在本地系统缓存中,域名解析过程结束。
通过上面的步骤,我们最后获取的是IP地址,也就是浏览器最后发起请求的时候是基于IP来和服务器做信息交互的。在实际的DNS解析过程中,可能还不止这10个步骤,如Name Server也可能有多级,或者有一个GTM来负载均衡控制,这都有可能会影响域名解析的过程。
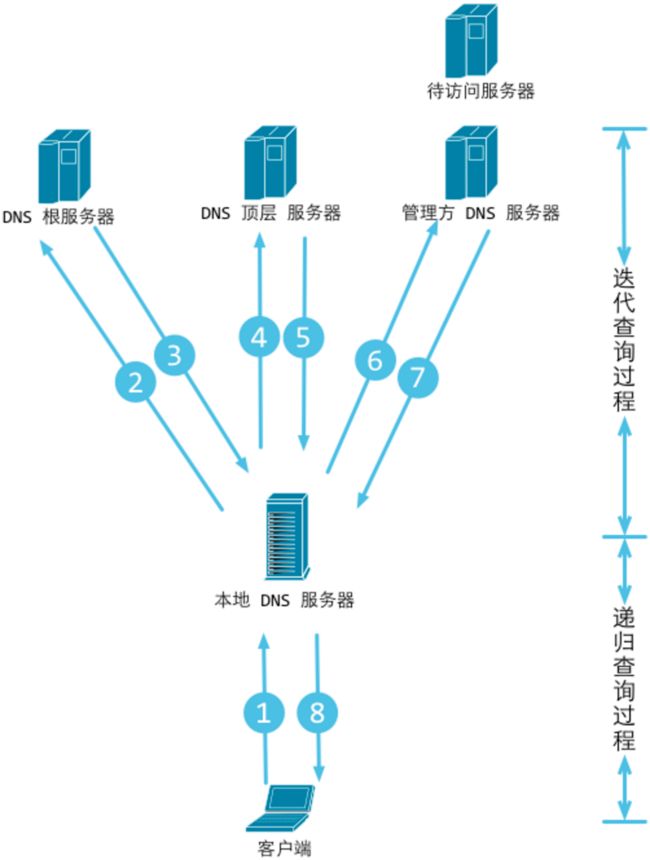
根据以上解析流程,DNS解析整个过程,分为:递归查询过程和迭代查询过程。
2.4 TCP三次握手建立通信
链接:https://blog.csdn.net/CSDN_Terence/article/details/77935297
2.5 CDN工作机制
CDN就是内容分部网络,是一种先进的流量分配网络;其目的提高用户访问网站的相应速度,有别于镜像,比镜像更智能。目前以静态数据为主(css,js,图片,视频,音频,静态页面等),用户从主服务器请求到动态内容,再从CDN上下载静态数据,从而加速网页数据内容的下载速度。
CDN请求与处理流程:向Local DNS 服务器发送请求,一般经过迭代解析后回到这个域名的注册服务器解析(每个公司都会有一台DNS解析服务器),这个服务器会把请求重新CNAME解析到另一个域名,这个域名最终会指向CDN全局中的DNS负载均衡服务器,再由这个GTM来最终分配是哪个地方的访问用户吗,返回给离这个用户最近的CDN节点。
负载均衡:就是对工作任务进行平衡。分摊到个多个操作单元上执行共同完成任务。可以提高服务器响应速度以及利用效率,避免软件或者硬件出现单点失效,解决网络拥塞问题,实现地理位置无关行,为用户提供一致的访问质量。
三种负载均衡架构分别是链路负载均衡、集群负载均衡、操作系统负载均衡
链路负载均衡:通过DNS解析到不同的IP,然后用户根据这个IP来访问不同的目标服务器
集群负载均衡:
硬件负载均衡:性能好,但是价格高,不可动态扩容,通常采用一主一备。
软件负载均衡:成本低,但是多次代理服务器,增加了网络延时。
操作系统负载均衡:就是利用操作系统级别的软中断和硬件中断来达到负载均衡,比如,可以通过设置多队列网卡实现。
其中,后两者使用的方式较多。