python词频统计GUI(thinter)
本文介绍利用python实现了简单的词频统计程序,其中涉及了简单的正则表达式的使用和python可视化模块tkinter的使用。完成了选择任意的文件,然后统计其中的单词的出现频度并以列表的形式展现出来。最后连接数据库并将所得的结果写入数据库。
一,首先是简单的词频统计
利用文件名读取文件,然后调用remove_punctuation()函数去除其中的杂乱的字符,实现只有英文的字符。然后将得到的字符串转化为字典,单词作为索引,次数作为值,一遍循环以后实现了建立词频统计,然后将结果写入了文件中,用于验证。
wordDict = {}
with open(filenamevar) as file:
content = file.read()
# remove the character which is not in a-zA-Z
content = remove_punctuation(content)
# covert the str to the lower statement
content = content.lower()
wordList = sorted(list(content.split()))
for word in wordList:
if word not in wordDict:
wordDict[word] = 1
else:
wordDict[word] = wordDict[word] + 1
file.close()
with open('out.txt', 'w') as file2:
for x, y in wordDict.items():
file2.write(x + ' ' + str(y) + '\n')以下是remove_punctuation()函数部分,利用简单的正则表达式,用空格替换原来的除英文意外的字符,返回目标字符串:
def remove_punctuation(line):
rule = re.compile(r"[^a-zA-Z]")
line = rule.sub(' ', line)
return line二,tkinter的使用
利用tkinter构建简单的客户端:
root = tk.Tk()
entryvar = tk.StringVar() # 路径
root.geometry('600x400+400+200')
# var.set("请选择你要打开的文件")
root.title("统计词频")
# define the frame
frame = tk.Frame(root)
frame2 = tk.Frame(root)
frame2.place(x=100, y=30, width=300, height=175)
# label = tk.Label(frame2, textvariable = var).pack(side = tk.LEFT)
Entryvar = tk.Entry(frame2, textvariable=entryvar, width=20)
Entryvar.pack(side=tk.LEFT)
# print((type(Entryvar)))
button = tk.Button(frame2, text="读入文件", command=getFile).pack(side=tk.LEFT)
button2 = tk.Button(frame2, text="统计", command=wordResult).pack(side=tk.LEFT)
button3 = tk.Button(frame2, text="插入数据库", command=pyDatebase).pack(side=tk.LEFT)
# 表格
frame.place(x=400, y=30, width=170, height=330)
scrollBar = tk.Scrollbar(frame)
scrollBar.pack(side=tk.RIGHT, fill=tk.Y)
tree = Treeview(frame, columns=('c1', 'c2'), show="headings", yscrollcommand=scrollBar.set)
tree.column('c1', width=90, anchor='center')
tree.column('c2', width=70, anchor='center')
tree.heading('c1', text='单词')
tree.heading('c2', text='出现次数')
tree.pack(side=tk.LEFT, fill=tk.Y)
scrollBar.config(command=tree.yview)
root.mainloop()
三,数据库连接
利用pymysql连接工具连接数据库,向数据库中插入数据。
def pyDatebase():
connect = pymysql.Connect(host='localhost', port=3306, user='root', passwd='123456', db='python', charset='utf8')
# 获取游标
cursor = connect.cursor()
#删除原数据
sql_delete = "delete from test;"
cursor.execute(sql_delete)
# 插入数据
sql_insert = "INSERT INTO test (word, number) VALUES ( '%s', '%s')"
for x, y in wordDict.items():
date = x, y
cursor.execute(sql_insert % date)
connect.commit()
print('成功插入条数据')
最终测试结果如下: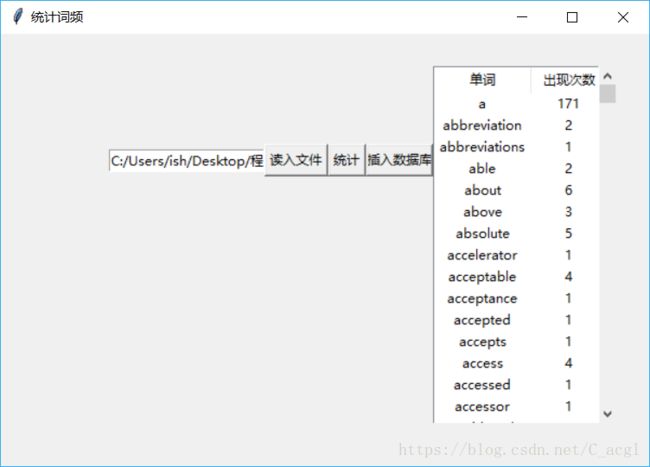

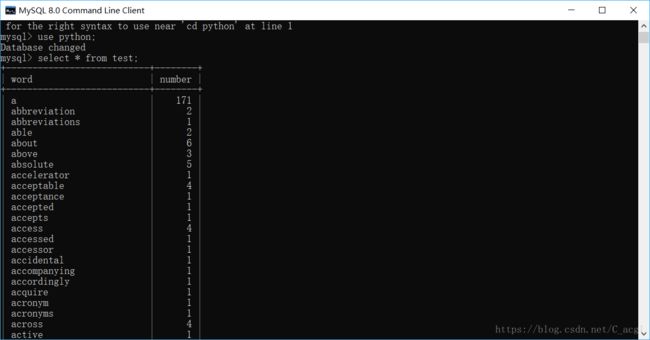
结果反思:
首先在tkinter的使用过程中,最开始是直接通过askopenfilename()这个函数去获取对话框中打开的文件的文件名,然后想要利用这个文件名进行一系列的操作,但是,经过不断的测试发现,利用button()的command属性调用的函数,不会再mainloop()循环以内就返回值,也就是说,再可视化的循环内是获取不到filename的,这也就导致了无法去获取文件名,无法进一步进行操作,然后在搜寻资料发现了要向在mainloop()循环内获得这个值,那么就必须得使用tkinter的内部String变量的方法StringVar并进行动态赋值,才能实现文件名的获取,也才能实现后续的一系列操作。
由此可见,对一个已调用模块的熟悉程度也就注定了自己在这个模块的使用的过程中会有多大的返工。
附源码如下:
import re
import tkinter as tk
import pymysql.cursors
import tkinter.filedialog
from tkinter.ttk import Treeview
wordDict = {}
def pyDatebase():
connect = pymysql.Connect(host='localhost', port=3306, user='root', passwd='123456', db='python', charset='utf8')
# 获取游标
cursor = connect.cursor()
#删除原数据
sql_delete = "delete from test;"
cursor.execute(sql_delete)
# 插入数据
sql_insert = "INSERT INTO test (word, number) VALUES ( '%s', '%s')"
for x, y in wordDict.items():
date = x, y
cursor.execute(sql_insert % date)
connect.commit()
print('成功插入条数据')
def remove_punctuation(line):
rule = re.compile(r"[^a-zA-Z]")
line = rule.sub(' ', line)
return line
def wordResult():
filenamevar = Entryvar.get()
with open(filenamevar) as file:
content = file.read()
# remove the character which is not in a-zA-Z
content = remove_punctuation(content)
# covert the str to the lower statement
content = content.lower()
wordList = sorted(list(content.split()))
for word in wordList:
if word not in wordDict:
wordDict[word] = 1
else:
wordDict[word] = wordDict[word] + 1
file.close()
with open('out.txt', 'w') as file2:
for x, y in wordDict.items():
file2.write(x + ' ' + str(y) + '\n')
for x, y in wordDict.items():
tree.insert('', 'end', value=(x, y))
# 获取文件的路径
def getFile():
global filename
filename = tk.filedialog.askopenfilename()
entryvar.set(filename)
root = tk.Tk()
entryvar = tk.StringVar() # 路径
root.geometry('600x400+400+200')
# var.set("请选择你要打开的文件")
root.title("统计词频")
# define the frame
frame = tk.Frame(root)
frame2 = tk.Frame(root)
frame2.place(x=100, y=30, width=300, height=175)
# label = tk.Label(frame2, textvariable = var).pack(side = tk.LEFT)
Entryvar = tk.Entry(frame2, textvariable=entryvar, width=20)
Entryvar.pack(side=tk.LEFT)
# print((type(Entryvar)))
button = tk.Button(frame2, text="读入文件", command=getFile).pack(side=tk.LEFT)
button2 = tk.Button(frame2, text="统计", command=wordResult).pack(side=tk.LEFT)
button3 = tk.Button(frame2, text="插入数据库", command=pyDatebase).pack(side=tk.LEFT)
# 表格
frame.place(x=400, y=30, width=170, height=330)
scrollBar = tk.Scrollbar(frame)
scrollBar.pack(side=tk.RIGHT, fill=tk.Y)
tree = Treeview(frame, columns=('c1', 'c2'), show="headings", yscrollcommand=scrollBar.set)
tree.column('c1', width=90, anchor='center')
tree.column('c2', width=70, anchor='center')
tree.heading('c1', text='单词')
tree.heading('c2', text='出现次数')
tree.pack(side=tk.LEFT, fill=tk.Y)
scrollBar.config(command=tree.yview)
root.mainloop()