撰写简单的分类器逻辑,了解分类器接口标准,深入理解机器学习过程
准备工作
可以继续使用前一篇pipline文章的项目,如果没有请参照它的准备工作部分
Scikit-learn-pipeline-macOS-案例-机器学习
需要下载安装Python 3.x
从终端安装Pip、Virtualenv并创建项目和初始化、激活虚拟环境
从终端安装Numpy和Scipy,Scikit-learn等第三方模块
sudo easy_install pip
sudo pip install --upgrade virtualenv
mkdir ~/desktop/myapp
sudo virtualenv --system-site-packages -p python3 ~/venv
cd ~/desktop/myapp
source ./venv/bin/activate
sudo pip install numpy scipy
pip install -U scikit-learn
创建iris3.py文件,包含以下内容
#导入数据集(在这里共计150条)
from sklearn import datasets
iris=datasets.load_iris()
#特征和标签
X=iris.data
y=iris.target
#将数据划分为训练数据和测试数据,测试数据占一半即0.5(75条)
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.5)
#创建分类器classifier
from sklearn.neighbors import KNeighborsClassifier
my_classifier=KNeighborsClassifier()
#训练数据
my_classifier.fit(X_train,y_train)
#使用训练好的分类器模型进行预测实验
predictions=my_classifier.predict(X_test)
#计算精确度
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,predictions))
从终端环境(venv)运行
python iris3.py
正常输出0.9x数字
分类器接口
classfier类应该至少有两个方法.fit用来训练和.predict用来预测
修改创建分类器部分的代码,去掉from sklearn.neighbors...一行,增加自定义分类器MyClassifier并使用它my_classifier=MyClassifier()
#创建分类器classifier
class MyClassifier():
def fit(self,xtrain,ytrain):
pass #暂时什么也不做
def predict(self,xtest):
pass #暂时什么也不做
my_classifier=MyClassifier()
如果现在运行它将报错,因为fit和predict并没有正确返回接口需要格式的数据(实际上pass什么都不执行)
随机分类器
如果给你很多鸢尾花的训练数据(比如第一朵花萼长宽3,2.1花瓣长宽4,3.2,属于setosa,第二朵...),然你自己分析这些数据从中找出每种鸢尾花的特征。
稍后,再给你一些鸢尾花的新数据(这次数据中不再告诉你每一朵是哪种鸢尾花,只有4个长宽数据),你需要评估出每朵花属于[setosa,versicolor,virginica]三种中的哪一种?
这时候,最简单的方法恐怕就是乱猜,就如同有人问你花萼长宽2.2,3花瓣长宽2.7,4这样的鸢尾花属于哪一种?你大脑都不过的就说出了versicolor。即使这样,你仍然有33%的可能猜对,不是吗?
修改我们的代码,实现随机分类器
import random #导入随机模块
#创建分类器classifier
class MyClassifier():
def fit(self,xtrain,ytrain):
self.X_train=xtrain #把训练数据xtrain变成自身的属性,以便于在后续predict方法中使用
self.y_train=ytrain #把训练可能ytrain变成自身的属性,以便于后续使用
#这里的ytrain就是[setosa,versicolor,virginica]数组
def predict(self,xtest):
my_predictions=[] #对多条数据预测出的结果数组,如第一朵versicolor,第二朵setosa,第三...
for row in xtest: #对每一条数据进行预测
label=random.choice(self.y_train) #随机选择一种鸢尾花类型
my_predictions.append(label) #把预测出的类型放入数组
return my_predictions #返回预测出的结果数组
my_classifier=MyClassifier()
然后在终端运行
python iris3.py
应该输出精确度是0.3x左右(多试几次)
最近邻分类器原理
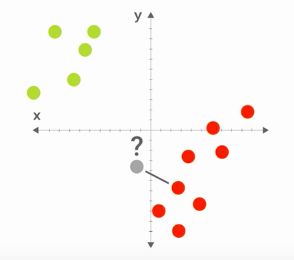
最近邻算法(Nearest Neighbor algorithm)是根据距离来评估数据所属类型的算法。

如图所示,绿色和红色代表我们的训练数据(因此我们知道它们属于哪种颜色类型),二灰色是我们要评估的测试新数据,我们不知道它该属于绿色还是属于红色。
简单的想法是,我们计算灰色点到其他所有点的距离,找到距离它最近的点,如果这个最近点是绿色,那么我们就认为灰色点是绿色,如下图

相反,如果距离最近点是红色,我们就认为灰色点应该是红色,如下图
特征即坐标
在平面纸上,每一个点有两个位置特征(横向x,竖向y);在三维空间,每一个点有三个位置特征(x,y,z)。
请把思想打开!
在鸢尾花分类空间中,每一朵鸢尾花有四个位置特征(花萼的长度、宽度和花瓣的长度、宽度),尽管我们没法画出这个空间,但不妨碍我们想象它存在。
在这个空间中,每一朵鸢尾花处在不同的位置,假想属于setosa类型的鸢尾花都分布在空间右上区域,属于versicolor类型的都在左上区域,属于virginica都在中间偏下的区域,如下图所示(当然这不是真的)

如果我们有一个新的需要预测类型的花,那么我们把它放到这个空间里,找到最近邻的点花的类型,就能评估出新花的类型
计算空间距离
对于一维空间(也就是一条横线)上AB两点间的距离,就是A的位置减去B的位置。因为在一维空间,AB的位置只有一个特征(就是横向x位置)。即
当然有
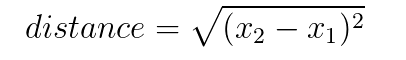
对于二维平面上两点的距离,如下图
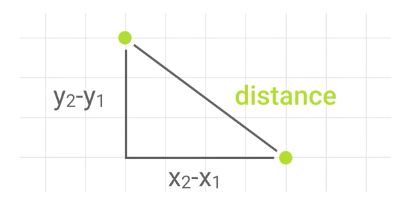
根据勾股定理,斜边就是两点间的距离,我们有
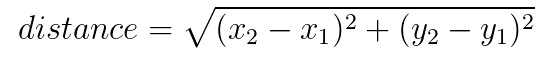
对于三维空间中两点的距离,同样我们有以下公式(可自行画图体会)
鸢尾花数据空间有四个维度(花萼长a宽b和花瓣长c宽d),同样我们有以下公式计算两朵花数据之间的距离
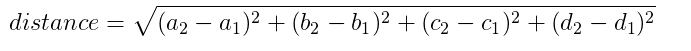
编写最近邻分类器
修改代码,去掉import random行;为分类器定义新的closest方法,用来计算新花朵到所有训练数据花朵的最近距离,修改label=self.closest(row)替换随机方法。
X_train训练数据,与之对应的y_train包含了每个训练花朵的类型,这是已知的,所以找到最近的花,就知道它的类型,进而评估新花的类型
代码如下
#import random #导入随机模块
from scipy.spatial import distance #导入距离计算模块
#创建分类器classifier
class MyClassifier():
def fit(self,xtrain,ytrain):
self.X_train=xtrain #把训练数据xtrain变成自身的属性,以便于在后续predict方法中使用
self.y_train=ytrain #把训练可能ytrain变成自身的属性,以便于后续使用
#这里的ytrain就是[setosa,versicolor,virginica]数组
def predict(self,xtest):
my_predictions=[] #对多条数据预测出的结果数组,如第一朵versicolor,第二朵setosa,第三...
for row in xtest: #对每一条数据进行预测
label=self.closest(row) #获取最近点类型,closest方法在下面定义
my_predictions.append(label) #把预测出的类型放入数组
return my_predictions #返回预测出的结果数组
def closest(self,row):
best_dist=distance.euclidean(row,self.X_train[0]) #计算到第一个点的距离
best_index=0 #假设第一个点就是最近的,下面会修正
for i in range(1,len(self.X_train)):
dist=distance.euclidean(row,self.X_train[i]) #计算训练数据中每个点到新点的距离
if(dist再次运行
python iris3.py
可以看到输出的精确度明显从原来的0.3x提高到0.9x
探索人工智能的新边界
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,感谢转发~
END