VJ框架 与 人脸检测/物体检测 详解
Viola-Jones Object Detection Framework
1. VJ Framework
1.1 Overview
本文详细阐述 Viola-Joines 人脸检测/物体检测 实时处理框架,主要参考 Robust Real-Time Face Detection 这篇论文以及本人工程实践经验。论文中 VJ 总结其主要贡献有三方面:
- Feature: Haar-based feature (wavelet)
- Learning algorithm: AdaBoost
- Attentional Cascade
其中 AdaBoost 本人有专门一篇文章讲解(”AdaBoost 详解”),这里直接跳过,当然,AdaBoost 模型在这里的应用是相当成功的。本文主要展开 Feature 和 Attentional Cascade 这个视觉和工程上的内容;这俩个贡献极大地提升了算法性能,实现了实时物体检测。
本节会梳理一下 VJ 框架的 runtime 检测流程和模型训练流程;之后小节展开讨论 Feature 和 Attentional Cascade 话题。
1.2 检测流程
这里把物体检测识别流程整体梳理一遍。我们的输入是一个一张待识别原始大图,输出是使用窗口框出大图中所有被检测到的目标(例如最常用的人脸)
- 图片预处理
- 降采样,原始大图size太大处理太慢,例如把 1000*1000 的原始图片降为 500*500
- 像素 intensity 压缩,一般的图片是3通道( 2563 )的RGB,我们会把它压缩到单通道的 intensity( 2561 )
- 特征预处理(Feature)
这里会根据 Feature 相关思路,计算出待检测图片的 Integral Image,VJ 框架通过这项优化,极大地加速训练和识别过程 - 滑窗检测
先以基础检测尺寸(训练时使用的24*24)在待检测图片上逐次划过所有位置(x轴+y轴全量遍历,当然 stride 可以设置大一点),在所有窗口上判断其是否为目标;并且会逐渐扩大检测窗口尺度(如每次扩大1.5倍)完成各个尺度下图片的检测。滑窗方式把检测问题转换为了二分类识别问题,但是这里需要识别的数量级巨大,500*500 的一张处理后待检测图片,轻轻松松包含10万个需要确认的检测窗口 - 图片检测(AdaBoost + Cascade 二分类器)
滑窗过程中每一个检测窗口都需要调用图片检测来确认结果,这里实际上利用了 Attentional Cascade 结构极大加速了判断过程:对于明显不是检测目标的窗口立刻拒绝,而对于很像检测目标的窗口则逐渐地使用更多资源判断,并最终确认得到目标
另外,检测过程中使用的特征,基于之前计算好的 Integral Image,可以通过几个加减计算直接得到,非常快速;并且 Cascade 基础是 AdaBoost,而 AdaBoost 基础是 Decision Stump,所以执行效率非常高 - 检测结果合并
最后,所有的 positive 检测窗口会进行合并(同一/不同尺度 的滑窗都有可能重复圈定一个目标),并消除一些错误结果。
VJ 论文最后有提到一个简单的方法,就是把 overlapping 的检测结果分到一个组里,每个组以组内结果的均值输出一个最终展示结果;false positive 被分配到的组可能只有一个检测结果,可以直接干掉。当然,实践中肯定可以使用更复杂的策略、算法来进行合并,且消除一些 false positive。
1.3 训练流程
1.2 中的“图片检测 ”使用的就是我们训练的基于 AdaBoost 的 Cascade 结构模型,这里概述一下训练过程。这里明确一下目标:输入一张确定size的小图片,输出确认这个小图片描述的是否是检测目标(其实这就把检测问题转化为粗略识别一类物体的二分类问题)。
- 样本准备
首先要确认一个检测窗口尺寸,VJ 原文是 24*24,这个是之后运行时滑窗检测的基础目标窗口 size,当然训练集需要使用这个 size。
- 正样本;一般数千到数万张标准 size 的目标物体小图
- 负样本;Cascade 结构极其吃负样本,作者之前训练时使用了10亿量级的负样本。当然,这么大的量级是训练过程中动态生成的,原始素材是数千到数万张不包含目标物体的大图(可以是2000*2000的各种自然景色图片啊什么的);训练的时候可以从大图中动态切出来大量的标准 size 的模型使用负样本
- 训练集和验证集;需要切出一个 validation set(例如和 training set 1:1 大小)来持续验证集成过程,这个验证集是静态的,但是会直接影响整个 Cascade 结构构建,对于 VJ 这一体系非常重要(所以感觉还是大一点好~)
- Cascade 训练
逐层训练出 Cascade 结构,每一层是一个 AdaBoost;每完成一层训练之后,都要为下一层重新准备已有结构无法 reject 的负样本(所以特别吃负样本),具体细节后续展开。 - 输出整个 Cascade 模型所有参数,供检测流程直接使用
2. Feature
特征是 VJ 框架的核心,这里使用 Haar 特征。对于一般的机器学习来说,都需要 feature extract 的步骤,从原始数据中,提取出合适的特征来供模型学习,这里的 Haar 特征有2个特点以及1个重要的加速计算方法,本节依次展开讨论。
2.1 过完备表达 overcomplete representation
数量级暴增
对于我们使用的基础 size 24*24,总计有 576 个像素点,如果直接使用像素做特征的话只有 576 个整数(0到255的图像 intensity)特征。
但是使用 Haar 特征的话,原论文中提取出 162,336 个整数特征,这个量级远远大于原始像素数量。实际上原始像素能够完整地表达这张图片的所有信息,但是我们使用了相比之下数量多的多 haar 特征去表达图片,称为 overcomplete representation。实际上,原文使用5种经典提取模板,我们其实还可以加入其它模板进一步扩充特征,更加地 overcomplete。
既有数量,更有价值
当然,overcomplete 光有数量是不够的,如果全部都是一些没有意义的特征,找再多也用。但是,haar 特征有潜能捕捉到重要信息。每个haar 特征可以看作是在图片的特定范围提取某一特定信号的结果,本质上其实是 小波变换 wavelet。这些特征能够很好的捕捉到边缘、线条、颜色以及一些简单的图像模式。虽然都是简单、粗糙的模式,但这正好构成了 AdaBoost 中 weak classifier 的基础,充分的 haar 特征表达为后续的模型学习提供更多可能。
Haar 简介
这里简单阐述这种特征的提取方式。下面这张图片摘自 VJ 原论文,展示了4种不同模板的 haar 特征提取。提取的时候,会使用相关模板在图片上滑窗,在任意位置上求取 rectangle 中白色区域像素和减去黑色区域像素和,所以结果是一个整数。另外,各个模板会 scale 到各个可能的尺寸依次滑窗求特征,所以最后能产出那么多的特征。(注意,这里说的特征提取滑窗,是 haar 特征在基础 size 的检测窗口上滑动;而后续说的检测流程滑窗,是检测窗口在待检测图片上滑动;是二个层次上的东西哦)

Figure 1. Feature Extraction of Haar-like (from VJ)
另外,大部分的特征其实是没有意义的,但是 AdaBoost 能够将少数牛逼的、很有效的、甚至我们直接看起来很有解释意义的特征挖掘出来。下图是 VJ 展示它们模型挖掘到的最重要特征:

Figure 2. Some Great Haar-like Features for Face-detection (from VJ)
这是很有解释性的 Haar 特征,模型学会了通过眼睛这一位置的显著对比度,来区分图片是否是人脸。
2.2 缩放不变性 scaling invariability
Haar 特征还有一个关键特性就是 scaling invariability。当检测窗口放大时,Haar 模板对应的白色、黑色区域是以一致的比例扩大的,所以原 Haar 特征的意义不变;Haar 本身求取的就是一个相对值。
在实践中,虽然我们整个模型训练只是基于 size 24*24 的检测窗口;但是,真正检测时需要对这个基础 size scale up,例如我们需要对 24*24、48*48、96*96 的检测窗口都要能判定是否为目标物体。这对于 Haar 特征太简单了,只要直接对 Haar 的提取窗口作同样的 scale up,就可以近似表达出任意 size 检测窗口在基础 size 检测窗口上的特征值;所以我们基于 Haar 特征训练的模型可以高效地无缝地直接应用在各个 scale 的检测窗口上。
额外提一点,如果没有 scaling invariability 的话,我们只能处理固定 size 的检测窗口。按照 VJ 原文说法的话需要对待检测图片作 pyramid(待检测大图 scale down 到各个尺度,类似金字塔),各尺度上都使用基础 size 的检测窗口滑窗检测。这种方法光是 pyramid 构建就已经造成巨大性能消耗。
2.3 计算加速 Integral Image
实际上 VJ 的主要贡献在于 Integral Image,这一方法使 Haar 特征计算变得非常迅速,使整个系统性能大幅提升。积分图 Integral Image 由原待检测图片生成,它们 size 一致,积分图每一的值为该点在原图上整个左上区域(包括该点)的像素和( ii 表示 integral image, i 表示原图):
积分图本身的计算复杂度是 O(MN) (待检测图片 size M*N),计算过程中使用了 dynamic planning 的思想,引入另一个中间变量 s(x,y) 作为 cumulative row sum 即按行积分;初始化 s(x,−1)=0, ii(−1,y)=0 ,按以下公式在原图上迭代一遍,即得到积分图 ii :
使用积分图计算任意 rectangle 范围的像素和非常简单,所以 Haar 特征的计算就很简单,如下图实例:The sum within D can be computed as 4 - 2 - 3 + 1

Figure 3. Calculating the sum of pixels from integral image is so easy (from VJ)
3. Attentional Cascade
这是 VJ 的另一重大贡献,Attentional Cascade 的核心思想在于:对于明显不是检测目标的窗口立刻拒绝,而对于很像检测目标的窗口则逐渐地使用更多资源判断,并最终确认得到目标。其结构如下图:
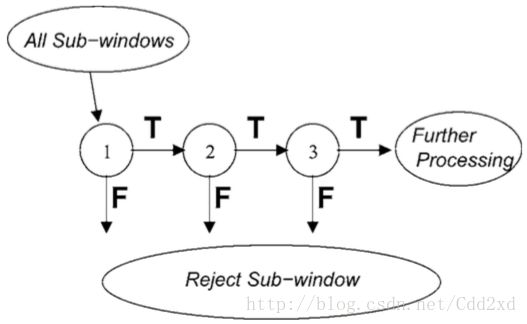
Figure 4. Structure of Cascade (from VJ)
3.1 性能提升
按照 VJ 原文估计,使用上图的 Cascade 结构获得了10倍以上的性能,这里的提升可以分为俩个方面:
- 层次结构
这里使用了多个层次的模型,图中的 1、2、3 都是 AdaBoost(Cascade 在 ensemble 的基础上再 ensemble 了一次~),只有逐层模型判断都是 True 才最终接受,任何一层模型 False 就直接拒绝,不会进行进一步处理。 - 越靠前的层次越简单
更重要的是,层次越靠前的 AdaBoost 可以越简单(集成的 weak classifer 数量更少)。原论文上述“1”这一 AdaBoost 只集成了 2 个 decision stump,但是实践中却能 Reject 约 50% 的检测窗口,这对于性能上的贡献,是决定性的!
3.2 重要假设
Cascade 能够大幅提升检测性能是因为: 真实检测任务中绝大多数的检测窗口都不是目标。
就人脸检测应用到门禁系统来说,在现实中运行的大多数时间,采集到的图片根本就不包含人脸,一张待检测图片对应的成千上万检测窗口都是无效检测。并且,就算真的有人脸出现,往往也就一个人脸,可能也就对应了几十个检测窗口,绝大多数的窗口还是无效的。
所以系统对 negative 结果的高效率识别极其重要,Cascade 正是基于此目标设计的。其试图尽量用最简单(性能消耗最小)的方法在最初的层次上把 negative 样本 reject。例如,假如我们的系统对着天空,或者某一统一颜色的背景,可能只需要一个 Decision Stump 就可以把 99% 以上的检测窗口干掉,有些窗口确实太明显不可能是人脸,这可能直接就带来性能成百上千倍的提升了。
另外,其实 Cascade 对 positive 识别的性能消耗反而是增加的,因为这至少增加了层次间跳转消耗,而非一次计算得到结果;但是,negative 的性能提升完全抵消了这一消耗。所以算法模型根据业务特点作调整很重要。
3.3 额外特性,需要海量 negative 样本
Cascade 除了贡献的大幅性能增长外,还有一个额外的特点,就是需要使用大量 negative 样本训练。Cascade 的训练细节(下一小节详述)上,每个层次的训练集正例是一致的,但是负例需要选取上一层次的 false positive 数据,这样 Cascade 的 false positive 会随层次逐渐降低(检测越来越精确)。这个特性可以算一把双刃剑:
- 正面
整个系统学习过的 negative 样本数量级大幅度增长。如果使用单个模型,我们 10 thousand 正例 对应 100 thousand 负例 可能已经是极限(太不均衡就没法学了);但是 Cascade 可以怼出 1 billion 量级的负例。Cascade 每个层次只学习之前层次无法正确处理的 negative 样本,所以较深层次能更加专注地去解决一些 hard 样本,系统对 negative 的准确处理能力应该是提升的。再加上现实中绝大多数检测窗口是 negative 的,所以这很有意义。 - 反面
这一特性也大幅提升了训练成本。这么量级的负例必然依赖动态生成,所以每当模型训练完成一个层次,就需要重新准备下一个层次的训练集,准备过程中可能会随机枚举 billion 量级的负例,并且每个负例都要在已有模型上测试一下,这一准备过程很耗时。并且,每一次负例准备完成,由于 AdaBoost 的训练特点,需要提取新负例的特征并对整个训练集重新排序(这属于 AdaBoost 的实现细节了),也很耗时。总之,训练层次很深的 Cascade 结构是非常耗时的(完爆单个 AdaBoost),并且数据集不好的话很难训练很深,作者也正在寻找更好的数据集~
3.4 算法细节
分层原理
VJ 原文的一个小例子非常简洁地说明了 Cascade 的实现细节:
即是假设 Cascade 有 10 层,如果每一层保证至少 0.99 recall 且至多 0.3 的 false positive;那么整个 Cascade 的检测能力将非常可观地达到 0.9 recall 和 0.00001 false positive(即 0.99999 precision)!检测问题很 care precision,这是很不错的结果。
实现细节
Cascade 实现时,每个层次都有一个训练目标(recall+false positive),这个层次的 AdaBoost 每迭代累加一个 decision stump 后,会查看一下是否能达到这个目标;一旦达标就这一层次就完成训练了。
这确保各个层次尽量简单,其他进一步检测交给下一层次。只要每个层次都完成了自己的小目标,整个模型就能完成 Cascade 示例中叠加的魔法。当然,这里有额外的成本(2.5.3 中提到了),即某一层次使用的负样本是之前所有层次都识别失败(false positive)的负样本。
实践中,每一个层次的训练目标属于超参数,VJ 原文中也提到靠前的几个层次(当然越靠前越重要了)训练目标是手动调试的;后续层次可以设定一些固定目标(例如 recall 0.9,false positive 0.1)。这是一个检测精度与检测性能 tradeoff 的过程,检测精度要求越低则相应层次模型复杂度度越低性能越快,但必须保证每一层次的小目标都到位,才能得到最终符合期望的整体模型。另外,各个层次的小目标达成,一般是一个从简到难的过程(因为 negative 样本越来越 hard);第一个层次的 AdaBoost 可能只需要 2 个feature,第二个层次可能接近 10 个,到深度的层次可能需要成百上千个 feature。VJ 原作者的最终的 Cascade 包含 38 个层次,总计 6060 个 feature(decision stump)。
Cascade 中 AdaBoost 的训练 trick
Cascade 的各层次训练小目标是非常好的 recall + 有点糟糕的 false positive,这本身是不均衡的。但是,AdaBoost 算法本身优化的目标是均衡的 Accuracy,是完全不一样,我们需要对 AdaBoost 作一点修改。
每次 AdaBoost 完成一次迭代,新加入一个 decision stump 后,我们会测试其是否满足 recall + false positive 的要求,false positive 的要求是很松的,如果这个要求都达不到我们就认为测试失败,应该继续迭代 AdaBoost;但如果只是 recall 不够高,我会回引入一个松弛参数 β ,衰减 AdaBoost 的最终判别式:
上式原始 AdaBoost 判别式中 β=1.0 ,这里逐渐衰减这个参数,会使 AdaBoost 判定 positive 更容易,所以 recall 上升,false positive 上升。
我们持续调整 β (从 1.0 到 0.0),如果当前 AdaBoost 到底是否能达成小目标,如果发现彻底不能达成(松弛过程中 false positive 超过小目标),就认为测试失败,应该继续迭代 AdaBoost。