【转载】Entity Framework概要
Entity Framework概要
Entity Framework是微软的Object Relational Mapper(对象关系映射器),也就是我们平常说的ORM,它可以让应用程序开发者将关系型数据作为业务模型来使用,也消除了开发者为数据访问编写的绝大多数管道代码的需要(比如使用ADO.NET)。Entity Framework提供了一个综合的、基于模型的系统,通过摆脱为所有的领域模型编写相似的数据访问代码,使得开发者创建数据访问层是如此之简单。Entity Framework的首发版本是EF3.5,是伴随着.Net Framework 3.5 SP1和VS 2008 SP1一同发布的。从那之后,EF已经进化了很多很多,当前版本是6.1.3
Entity Framework通过开启数据访问和将数据表示为概念化模型(即一系列的实体类和关系)减轻了创建数据访问层的任务。应用程序可以执行基本的CRUD操作,以及轻松地管理实体间的一对一,一对多和多对多关系。
下面是使用Entity Framework的一些好处:
- 因为开发者不需要为数据访问编写所有需要的ADO.NET管道代码,因此这可以节省很多开发时间。
- 我们可以使用更高级的语言(例如C#)来编写所有的数据访问逻辑而不是编写SQL查询和存储过程。
- 因为数据库表没有高级的关系(如继承),然而领域实体是可以有的,所以业务模型(也就是概念模型)可以使用实体间的关系来适配应用领域。
- 底层的数据存储可以相对轻松地被取代,因为所有的数据访问逻辑都呈现在应用层而不是数据层。
现在通过一张图看一下EF的架构:
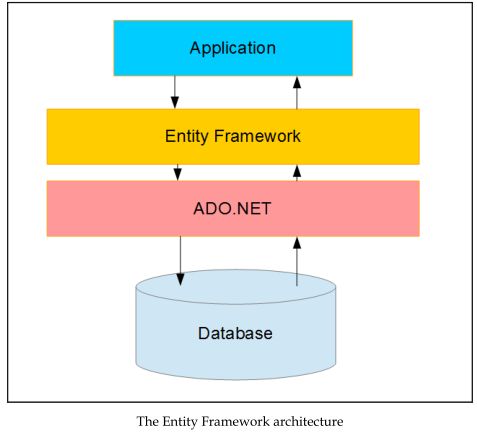
从这张图上可以看到,EF是建立在ADO.NET框架之上的,它下面仍旧使用了ADO.NET方法和类来执行数据操作。
什么是ORM
几乎所有的商业软件都要存储数据,多年来,Relational Database Management System(RDBMS)一直是开发者寻求的数据存储。ORM是允许开发者使用面向对象的编程语言访问RDBMS数据的一系列技术。可用的RDBMS包括SQL Server, Oracle, DB2, MySQL等等。这些数据库系统有一些共性。每个数据库系统都支持一个或多个数据库。数据库都包含数据表,每个表都以表格的形式存储数据,并且被分成了列和行。多个表中的数据行可能相互关联。比如,一个订单Order表中的Id可能存储在一个流水表Transaction中。
过去,在像EF这样的工具出现之前,开发者都是在软件代码内部嵌套的sql语句,这是因为编程语言不能原生理解Sql。比如,要从数据库中检索数据,然后将结果作为对象操作,必须使用ADO.NET要写相当数量的代码才行。具体来说,先定义一个存储person的类,然后打开数据库连接,创建具有查询文本的命令,再执行该命令的reader,然后对该reader的结果进行迭代,最后再使用来自reader的数据填充Person类的实例。你会看到,这里包含了很多步骤,而且更重要的是,这样写的代码维护成本很高。比如,数据库中改了一个列名,这样还要去代码中进行相应更改,否则运行时就会抛出异常。此外,我们数据库中存储的是标量值数据(int,string等),但我们的目标是一个对象或者对象图。这样看来,这种访问数据的方式有很多问题。
首先,RDBMS的列类型和.Net类型之间有类型失配;其次,存储和目标之间也不匹配,前者是标量值的集合,后者是具有属性的对象。更糟糕的是,键入我们的person对象有一个更复杂的属性List Phones,该属性代表其他表的集合。这些问题在OOP和关系数据库中被称为“阻抗失配”(impedance mismatch)。
ORM这些工具出现的原因就是为了解决这种失配问题。ORM工具将存储在数据表中的数据表示为对象,这比起传统的代码有很多优势:
它们使用原生.net类型暴露数据,使用简单的属性暴露相关的数据,提供编译时检查。
最后,在后面会看到,你会写更少的代码。更少的代码意味着更少的bugs,不是吗?:)
Entity Framework简史
多年来,有许多ORM工具进入市场,有开源的,也有商业的。微软也开发了自己的ORM工具。第一个是内置于.Net 3.5的LINQ to SQL。该ORM仅支持
SQL Server和SQL Server Compact。2008年第一次发布的Entity Framework是第二次尝试,相较于LINQ to SQL有很多优点。首先,有自己的provider架构,因此对于所有的关系数据库引擎都是开放的,而不仅仅是SQL Server。现在所有的主要RDBMS都有Entity Framework provider。
Entity Framework经历了很多版本。
第一版只支持Database First。这意味着你要将设计器指向一个已存在的数据库,然后就会生成一个包含数据库和表抽象的代码。除了代码之外,还会创建一个EDMX文件,该XML文件包含了实体数据模型(因此你也就知道了EDMX的意思了Entity Data Model Xml)。它包括三个模型:逻辑,存储和映射。逻辑模型(有时也叫概念模型)就是使用C#进行编码的那个,存储模型描述了数据是如何存储到数据库中的,映射模型提供了逻辑模型和存储模型之间的映射。如果你在数据库中更改了东西,那么你也要更新生成的模型,C#代码也要再次生成。映射模型有一个基于ObjectContext的类,该类有数据库中每张表的集合属性,每个集合都是一个泛型集合,集合中的元素类型是从EF中的一个基类中继承的。每个类都有属性和相应的数据表中的列对应。
第二版,也就是EF4,也开始支持Model-First了。这样 ,我们就可以使用设计面板创建实体类,然后设计器会产成SQL脚本来生成数据库。对于这种方法,仍会生成EDMX文件,最终的结果是和Database First是相同的。
最后,EF的Code First在版本4.1中引入。Code First不需要EDMX文件了,每个实体也不需要从EF的基类中继承了。这样,代码变得更加容易测试。这种方法也不需要依赖设计器了,你只需要编写类就行,而且它们会自动地映射到数据库中的表。当前的EF 6.1.3中的Code First已经相当强大了。
Entity Framework具有的能力
EF对于微软开发者可以做很多事情。
首先,它可以将数据库暴露成对象的集合,这是通过利用很多关键的类完成的。前提是你要了解DbContext,这个类是EF Code First的核心,在高层次上是数据库抽象。数据库包含了表,每个表又包含了行和列。DbContext有泛型集合属性,每个属性的类型是DbSet对应于每个表。集合中的每个对象指的是一个实体,代表相应表中的一行。数据表中的列是定义在TRowType类中的属性。
一旦这个结构布局好了,那么你就能够通过LINQ查询来查询底层的数据库了。如果你将一个全新的TRowType类的实例添加到父集合中,然后使用DbContext API保存更改,那么这个新的对象就会变成相应表中的一行,该对象的每个属性的值就会变成该行相应的列值。此外,EF有能力表示其他的数据库工件,比如存储过程和函数。数据库结构的进化是很重要的一个问题,在大多数情况,随着应用程序的变化,你需要添加列和表,EF是通过Migration(迁移)功能来解决这个问题的。这个能力允许你通过C#代码更改数据库结构,除了添加和删除表和列之外,还可以添加索引。Migration可以没有数据损失地进化数据库模式。你将会看到,EF会暴露你需要使用C#访问的一切数据而不需要编写SQL,并且像对待你整个应用程序代码的一部分来对待数据库。你可以将migration代码迁入到源代码控制系统(Git/SVN)中,因为它也是C#代码!
Entity Framework的架构
EF构建在provider架构之上。当开发者使用C#创建一个LINQ查询时,EF框架引擎会连接一个provider,将它转换成实际的SQL语句,最后发往数据库。任何给定的provider都是连接Entity Framework和一个特定的RDBMS的桥梁。一旦该provider执行了最终的SQL命令,结果就被EF物质化到.NET对象中。Data reader就是为了这个目的。理解EF构建于ADO.NET之上非常重要,因此,EF也使用了诸如connection,command,和data reader的概念。谈到数据持久化,也就是插入,更新和删除功能,插入时,开发者将一个实体类的实例添加到数据库上下文中。相似地,之前添加到上下文中的实例被标记为changed或deleted,就会产生对数据库即将执行更新和删除的语句。EF会检查上下文中的每个对象,再次使用provider来创建RDBMS特定的insert,update,或delete命令。
Entity Framework建模和持久化
EF依赖概念模型完成工作,首先来理解一下什么是Entity Data Model(EDM)以及EF如何使用它管理数据库操作。
理解EDM
概念数据模型是EF的核心。要使用EF,我们必须创建概念数据模型,即EDM。EDM定义了我们的概念模型类,这些类之间的关系,以及这些模型到数据库模式之间的映射。
一旦创建了EDM,我们就可以对概念模型执行所有的CRUD操作,EF会将所有的这些对象查询翻译成数据库查询(SQL)。一旦这些查询执行了,EF就会将返回的结果转成概念模型对象实例。EF会使用存储在EDM中的映射信息来执行对象查询到SQL查询,以及相关的数据到概念模型的翻译。
一旦EDM准备就绪,我们就可以使用模型对象来执行CRUD操作。要能够执行CRUD操作,我们必须使用ObjectContext类。接下来让我们理解一下这个类。
理解ObjectContext类
一旦我创建了EDM,我就有了应用程序中可以使用的所有的实体。然而,我还需要一个东西来让我在这些实体上执行各种操作。它就是EF中的ObjectContext类。
ObjectContext类是EF中的主要对象。它负责:
- 管理数据库连接
- 提供执行CRUD操作的支持
- 追踪模型的更改,目的在于在数据库中更新模型
ObjectContext类可以理解成管理EDM中所有实体的东西,让我们为这些实体执行所有的数据库操作。当我们想要保存一个新的或者更改的对象到数据库时,我们必须调用ObjectContext类中的SaveChanges方法。
还有另一个类
DbContext,它和ObjectContext类很相似。实际上,Dbcontext类就是ObjectContext类的封装类。它是一个更新的API,而且它提供了更好的API来管理数据库连接和执行CRUD操作。
因为DbContext是更好的API,所以我们会使用DbContext来执行所有的数据库操作。
Entity Framework的三种开发风格
- Database First:这是一种用于已存在数据库模式的方法。使用这种方法,EDM是从数据库模式中生成的,这种方法最适合于使用了已经存在的数据库的应用。
- Code First:这种方法中,所有的领域模型都是以类的形式编写的。这些类会建立我们的EDM,数据库模式会从这些类中创建。这种方法最适合于那些高度以领域为中心并且领域模型类创建优先的应用程序。这里需要的数据库只是为了这些领域模型的持久化机制。
- Model First:这种方法和Code First方法很相似,但是这种情况下我们使用了EDM视觉设计器来设计我们的模型。数据库模式和类将会通过这个概念模型生成。该模型将会给我们创建数据库的SQL语句,然后我们可以使用它来创建数据库并连接应用程序。
三种风格的比较
Database First
主要的好处就是:如果数据库已经存在了,那么只需要花一点时间就可以编写数据访问层。EDM可以从数据库中生成,然后根据需求更改EDM。
一些场景:
- 对遗留的数据库进行开发
- 当其他团队的DBA完成了数据库设计时,一旦数据库完成,应用开发就要开始
- 当要开发数据为中心的应用时,应用领域模型就是数据库本身,数据库会频繁修改来满足新的需求。
Model First
和Database First相似,Model First最终以EDM结束。使用该EDM,我们可以创建概念模型和数据库。使用这种方法的唯一原因就是我们真的想要使用视觉实体设计器。
Code First
Code First对于所有的业务逻辑以类实现,并且数据库只用作这些模型的持久化机制时很有用。
选择Code First的一些原因:
- 数据库只是作为模型的持久化机制,即数据库中没有逻辑。
- 完全控制代码,即没有自动生成的模型和上下文代码。
- 数据库不会手动更改。模型类总是更改,然后数据库基于模型类的更改而更改。
如何选择持久化方法
上面介绍了三种选择,至于选择哪一种,这也是个不大不小的问题,那么请参考下面进行决定:
方法一:工作流决定树
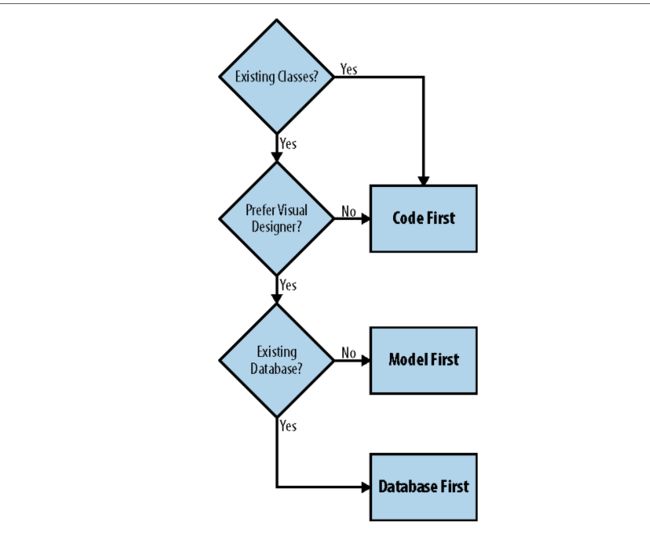
方法二:检查清单
| 场景 | 方式 |
|---|---|
| 有遗留的数据库或者数据库已经存在 | Database First |
| 在开始开发前,我们会获得DBA创建的数据库 | Database First |
| 数据库频繁改变,应用程序应该随之改变 | Database First |
| 我们想要使用视觉实体设计器来生成数据库和模型类 | Model First |
| 我们已有模型类并且只需要数据库保存数据 | Code First |
| 我们想要编写所有的模型类,实现这些类,然后考虑数据库存储 | Code First |
| 我们不想处理自动生成的类,且更喜欢动手亲自编写 | Code First |
本章小结
这一节我们看到了传统的嵌入式sql访问数据的短处,并理解了什么是ORM以及ORM主要解决的问题。同时,我们回顾了一下Entity Framework的历史发展,也看到EF能做什么。我们也简要地看了一下EF的架构。然后理解了什么EDM,ObjectContext,以及它和DbContext的区别和联系。随后我们介绍了EF的三种开发方式(也叫EF工作流)和它们之间的比较,以及使用它们的可能场景,最后介绍了如何选择哪一种方式。