竞争神经网络与SOM神经网络及其在矿井突水水源判别的应用
一、竞争神经网络与SOM神经网络的原理
1.竞争神经网络与SOM神经网络的概述
① 竞争神经网络和SOM神经网络的结构十分相似,可以大致看成一类,与BP神经网络、RBF和GRNN、PNN这一类区别,是在于其是无导师学习的神经网络,没有理想的输出,相当于只有输入,并且对输出的结果进行分类,因此这种方法十分适合对数据进行聚类操作。
② 对于以上的其他的神经网络的介绍与认识可以参照:BP神经网络的简介:https://blog.csdn.net/ChenQihome9/article/details/81508916。以及RBF和GRNN、PNN的简介:https://blog.csdn.net/ChenQihome9/article/details/81533918
2.竞争神经网络与SOM神经网络原理的介绍
 图 1-1 Competitive neural network
图 1-1 Competitive neural network
 图1-2 Self Organizing Map neural network
图1-2 Self Organizing Map neural network
首先图1-1中为竞争神经网络的结构,在竞争层中,神经元之间相互竞争,最终只有一个或者几个神经元获胜,以适应当前的输入样本。竞争胜利的神经元就代表着当前输入样本的分类模式;图1-2为SOM神经网络(自组织特征映射神经网络)的结构,跟竞争神经网络相比,它的结构更加简单,没有阈值的调整,而且它在调整权值的时候,即每次迭代的时候使用多个神经元进行调整。SOM神经网络的可以进行降维处理,即可以把高维的输入特征映射到一维或者二维的空间上面,然后可以查看它们组织映射的情况。也就是知道在训练完后的神经元分别属于哪一类和它们之间的差异性。
二、竞争神经网络在矿井突水水源的应用
1. 矿井突水水源判别的背景介绍
① 矿井水害是我国煤矿安全生产的重大隐患,是仅次于煤矿瓦斯灾害的第二大自然灾害;矿井突水是指掘进或采矿过程中当巷道揭穿导水断裂、富水溶洞、积水老窿时,大量的地下水突然涌入矿山井巷的现象;一旦发生突水灾害事故,将会给矿井带来严重的经济损失和人员伤亡,因此准确判别突水来源是防范水害的关键。
② 基于水文地球化学理论的矿井突水水源判别方法主要有,常规水化学分析法主要是对水源样本中的宏量组成成分(![]() ) 和水质综合指标进行检测。这次神经网络的判别主要选取六大常规离子:即(
) 和水质综合指标进行检测。这次神经网络的判别主要选取六大常规离子:即(![]() )作为判别水源的依据。
)作为判别水源的依据。
2. 建立竞争神经网络
① 竞争神经网络主要包括输入层和竞争层,并且通过连接权相连。假设输入层有M个神经元,竞争层有N个神经元,则网络的连接权值为![]() ,并且满足条件从输入层到竞争层各个神经元的连接权值的和为1。
,并且满足条件从输入层到竞争层各个神经元的连接权值的和为1。
② 对检测所得的数据进行数据预处理,首先为了更好定量分析判别结果,对各含水层水源类型自上而下进行二进制编码。将水源样本分为这四类,因此需要设置的竞争层的神经元个数为4个。
| 第四系含水层 | (1 0 0 0) | 顶板砂岩含水层 | (0 1 0 0) |
| 八灰含水层 | (0 0 1 0) | 二灰和奥陶纪含水层 | (0 0 0 1) |
根据设置的神经元个数和输入层与输出层的因素,可以得出下列竞争神经网络图:
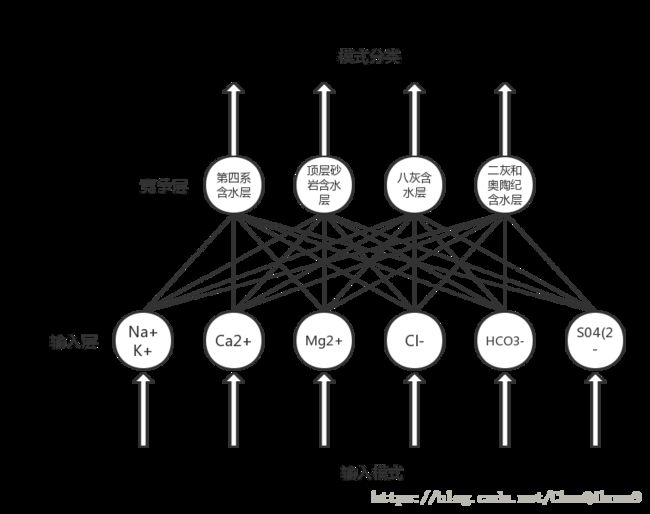
③ 下列表格为35个水源样本的六大常规离子的数据,并将它们作为训练集参加竞争
| 编 | ||||||
| 号 | ||||||
| 1 | 11.98 | 76.15 | 15.56 | 8.5 | 26.9 | 292.84 |
| 2 | 19.34 | 65.73 | 18.48 | 10.64 | 67.24 | 239.19 |
| 3 | 11.5 | 84.57 | 24.81 | 19.86 | 82.61 | 253.83 |
| 4 | 19.78 | 52.5 | 16.29 | 9.93 | 37.66 | 229.43 |
| 5 | 35.1 | 46.2 | 17.6 | 35.8 | 43.2 | 212.9 |
| 6 | 44.88 | 73.24 | 24.8 | 24.07 | 85.97 | 303.56 |
| 7 | 10.29 | 61.23 | 29.33 | 12.16 | 47.46 | 309.85 |
| 8 | 10.64 | 59.3 | 28.4 | 12.59 | 34.7 | 291.68 |
| 9 | 8 | 69.3 | 26.39 | 10.96 | 43.85 | 295.24 |
| 10 | 6.45 | 63.43 | 24.1 | 9.24 | 41.9 | 266.34 |
| 11 | 8.3 | 63.5 | 26.9 | 11.19 | 43.85 | 282.52 |
| 12 | 7.1 | 63 | 24.7 | 7.35 | 37.8 | 266.13 |
| 13 | 7.7 | 67.1 | 39 | 8.82 | 46.5 | 281.57 |
| 14 | 7 | 68.7 | 24 | 11.7 | 43.77 | 282.16 |
| 15 | 17.85 | 62.96 | 17.28 | 6.68 | 23.31 | 284.57 |
| 16 | 13.59 | 61.59 | 18.85 | 6.68 | 23.57 | 276.69 |
| 17 | 10 | 63.87 | 32.83 | 4.06 | 65.09 | 295.87 |
| 18 | 12.69 | 69.39 | 29.38 | 13.64 | 34.54 | 325.08 |
| 19 | 98.1 | 3.1 | 1.1 | 23.5 | 43.84 | 638.7 |
| 20 | 207.35 | 34.75 | 11.16 | 23.78 | 46.54 | 558.82 |
| 21 | 311.75 | 16.25 | 2.04 | 33.58 | 20.56 | 736.76 |
| 22 | 303.12 | 10.24 | 8.55 | 32.84 | 17.47 | 773.45 |
| 23 | 304.82 | 5.77 | 3.61 | 40.77 | 53 | 628.96 |
| 24 | 257.23 | 0 | 0 | 27.22 | 12.24 | 428.71 |
| 25 | 502.45 | 0 | 2.48 | 29.04 | 9.79 | 1105.8 |
| 26 | 309.33 | 0 | 0 | 29.03 | 0 | 562.17 |
| 27 | 358.58 | 10.22 | 3.72 | 32.68 | 14.69 | 691.17 |
| 28 | 9.1 | 86.5 | 31.8 | 22.4 | 57.8 | 348.31 |
| 29 | 13.25 | 99.2 | 31.1 | 29.85 | 83 | 361.12 |
| 30 | 9.2 | 106.7 | 39.1 | 40.1 | 69.8 | 402.1 |
| 31 | 17.3 | 98.2 | 20.6 | 20.24 | 53.2 | 354.4 |
| 32 | 4.68 | 69.14 | 22.93 | 26.67 | 13.38 | 251.26 |
| 33 | 19.58 | 74.67 | 16.92 | 24.46 | 27.62 | 272.94 |
| 34 | 19.9 | 70.47 | 16.78 | 18.4 | 10.79 | 294.47 |
| 35 | 20.54 | 51.73 | 16.04 | 24.34 | 12.34 | 236 |
④ 以下为待测的样本数据,是4个已知或者可以判断的实际水源类型的样本数据
| 编 | 实际水源类型 | ||||||
| 号 | |||||||
| I | 23.76 | 66.4 | 19.59 | 18.13 | 57.26 | 255.29 | 0 0 0 1 |
| II | 9.97 | 64.45 | 26.48 | 9.59 | 40.53 | 288.14 | 0 0 1 0 |
| III | 294.75 | 8.93 | 3.63 | 30.27 | 24.24 | 680.51 | 0 1 0 0 |
| IV | 14.19 | 81.96 | 24.41 | 25.81 | 40.99 | 315.08 | 1 0 0 0 |
⑤ 将训练集数据和待测数据输入至MATLAB并执行下列程序
load water_data.mat %即含有总共39个数据的mat文件
attributes = mapminmax(attributes); % 2. 数据归一化
P_train = attributes(:,1:35); % 训练集——35个样本
P_test = attributes(:,36:end); % 测试集——4个样本
net = newc(minmax(P_train),4,0.01,0.01);% 1. 创建网络
net.trainParam.epochs = 1500; %你可以设置训练次数,比如500,1000等,默认是1000
net = train(net,P_train); %开始训练
y= sim(net,P_train); %将训练样本的分类结果以列矩阵列出
y1 = vec2ind(y); %将列矩阵转换成数字类型
y2= sim(net,P_test); %将待检测的分类结果以列矩阵列出
y3= vec2ind(y2); %将待检测的列矩阵转换成数字类型⑥ 35个用于训练集的样本与4个作为检测的样本的分类即最终结果如下
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 分类 | 3 | 4 | 1 | 3 | 1 | 1 | 4 | 4 | 4 | 4 |
| 编号 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 分类 | 4 | 4 | 4 | 4 | 3 | 3 | 4 | 4 | 2 | 3 |
| 编号 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 分类 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 |
| 编号 | 31 | 32 | 33 | 34 | 35 | 待 | 36 | 37 | 38 | 39 |
| 分类 | 1 | 3 | 3 | 3 | 3 | 待 | 1 | 4 | 2 | 1 |
3. 结论
分析待测样本的检测结果可以知道,样本中编号I与编号IV(即第四系含水层与二灰和奥陶纪含水层)的差异性不是很高,但其他的分类较为明显,比如我们知道分类是2的多是属于顶板砂岩含水层,即样本(编号是19、21、22、23、24、25、26、27)极大可能是来自顶板砂岩含水层的水源样本。而分类是4多是属于八灰含水层,即样本(编号是2、7、8、9、10、11、12、13、14、17、18)极大可能是来自八灰含水层的水源样本。这样通过到勘察地所采水源样本的数据与以上样本数据进行训练竞争可以判别出所处的含水层。(非专业认知仅供参考)
参考文献:
[1]徐星,李垣志,田坤云,张瑞林.ACPSO-BP神经网络在矿井突水水源判别中的应用[J].重庆大学学报,2018,41(06):91-101.
[2]陈红颖.矿井突水水源判别研究现状与进展[J].内蒙古煤炭经济,2018(08):20+30.
[3]汪洋,左文喆,王斌海,程紫华.矿井突水水源判别方法研究进展[J].现代矿业,2018,34(01):69-73.