黑马程序员—java基础—集合框架
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
集合框架
说到集合框架,脑袋里便想到了两个分支,单列集合和双列集合,先上一个整体的结构图片吧(本来应该昨晚发布,停电,今天补充发布)
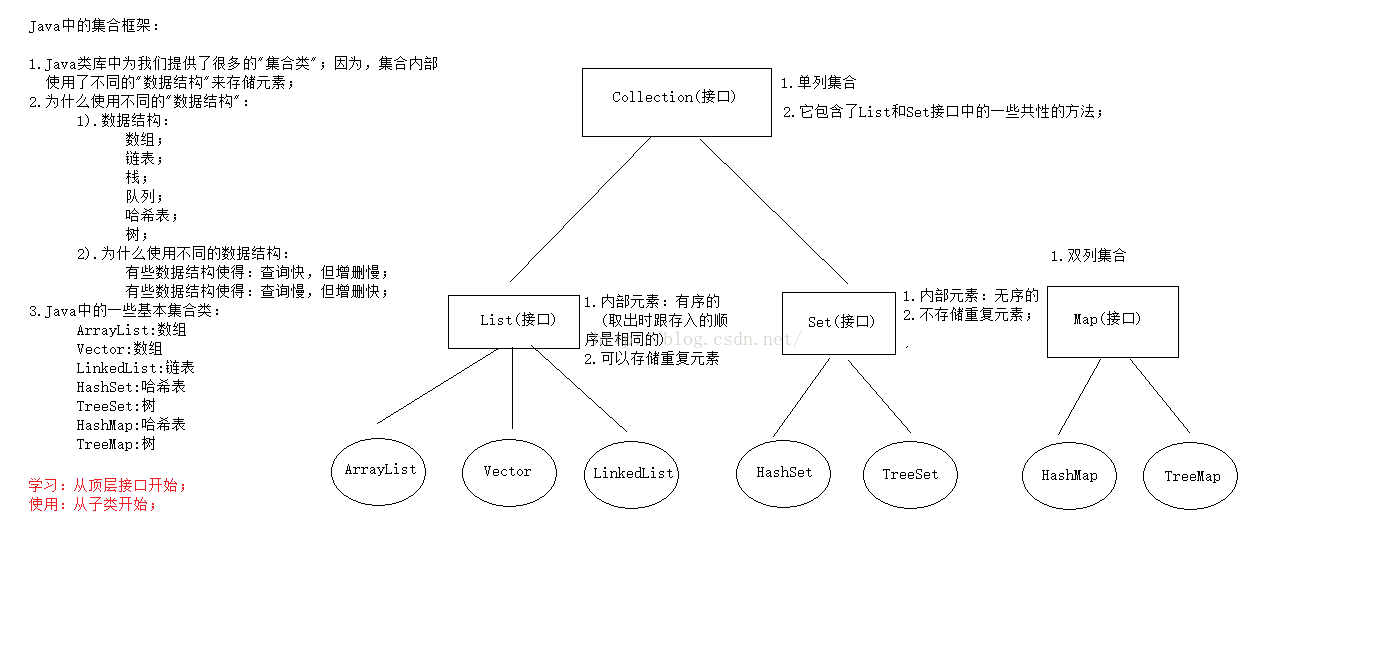
集合的概念:
集合的概念:
1.数组的弊端:
1).长度是固定的,后期不能改变;
2).数组一旦定以后,其类型就固定了,只能存储此类型数据;
2.Java为我们提供了一些类,这些叫:集合类。这些集合类功能类似于"数组",
为程序员做"容器"用的。
3.集合的好处:
1).我们程序员使用集合时,可以不用关心"长度"信息,我们只需要往里面存东西,或者从内部删除元素
package cn.itcast.demo03_集合的顶层接口_Collection接口中的功能;
import java.util.ArrayList;
import java.util.Collection;
/*
* java.util.Collection(接口):它是List和Set的顶层接口;
*
* 常用方法:
* 说明:下列方法中,看到E类型,把它当做:Object
* boolean add(Object e):向集合中添加一个元素
boolean remove(Object o):从集合中移除一个元素
void clear():清空集合
boolean contains(Object o):判断集合中是否包含参数对象
boolean isEmpty():判断集合是否为空
int size():获取集合内元素的数量
*/
public class Demo {
public static void main(String[] args) {
Collection list = new ArrayList();//1.有序的;2.存储重复元素;
// Collection list = new HashSet();//1.无序的;2.不存储重复元素;
//1.boolean add(Object e):向集合中添加元素:
System.out.println(list.add("刘德华"));
System.out.println(list.add("周润发"));
System.out.println(list.add("谢霆锋"));
System.out.println(list.add("黄晓明"));
System.out.println(list.add("吴彦祖"));
System.out.println(list.add("吴彦祖"));//添加成功
//打印集合
System.out.println(list);
//移除掉"谢霆锋"
System.out.println("移除\"谢霆锋\":" + list.remove("谢霆锋"));
System.out.println("移除\"高圆圆\":" + list.remove("高圆圆"));
System.out.println("移除后,打印集合:" + list);
//清空集合
/* list.clear();
System.out.println("清空集合后,打印集合:" + list);
*/
//判断张学友是否在集合中
System.out.println("判断\"张学友\"是否在集合中:" + list.contains("张学友"));
System.out.println("判断\"黄晓明\"是否在集合中:" + list.contains("黄晓明"));
System.out.println("判断集合是否为空:" + list.isEmpty());
//获取元素的数量
System.out.println("集合中元素的数量:" + list.size());
}
}
Collection中的批量的方法:
boolean addAll(Collection c):将参数集合加入到当前集合中;
boolean removeAll(Collection c):移除此 collection 中那些也包含在指定 collection 中的所有元素
boolean containsAll(Collection c):如果此 collection 包含指定 collection 中的所有元素,则返回 true。
boolean retainAll(Collection c):移除此 collection 中未包含在指定 collection 中的所有元素。都不常用,不做示例
迭代器遍历集合的方法:
package cn.itcast.demo05_集合的顶层接口_Collection接口_遍历的方法;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
* Collection中的遍历的方法:
*
* 1.Object[] toArray():
* 2.Iterator iterator():迭代器
* java.util.Iterator(接口):
* boolean hasNext() : 如果仍有元素可以迭代,则返回 true。
* Object next() :返回迭代的下一个元素
*/
public class Demo {
public static void main(String[] args) {
Collection list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("周六");
list.add(10);// 自动装箱int-->Integer
list.add(3.14);// 自动装箱double-->Double
// 3.获取Object[]数组
/*
* Object[] objArray = list.toArray();
* for(int i = 0;i < objArray.length; i++){
* System.out.println(objArray[i]);
* }
*/
// 遍历方式二:
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}LIst集合特有的功能:
package cn.itcast.demo10_List的特有功能;
import java.util.ArrayList;
import java.util.List;
/*
* List的特有功能:
*
* Collection(接口):
* |--List(接口):
* 特有功能:
* void add(int index,Object element):将element添加到index位置,原index位置上的元素,及后续元素全部后移;
Object remove(int index):移除index位置上的元素;
Object get(int index):获取index位置上的元素;
Object set(int index,Object element):将index位置上的元素替换为参数的element元素
遍历的方法:
1.ListIterator listIterator():
2.结合Collection的size(),和本接口的get(int index)方法,可以使用for循环遍历;
* |--Set(接口):
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个List
List list = new ArrayList();
//2.填充集合
list.add("aaa");//Collection
list.add("bbb");//Collection
list.add("ccc");//Collection
//在bbb的后面添加一个fff
list.add(2,"fff");
System.out.println(list);
//移除元素
//移除fff
list.remove(2);
System.out.println("移除到fff后:" + list);
//获取ccc元素
System.out.println("获取ccc:" + list.get(2));
//将aaa替换为xxx
System.out.println("替换操作的返回值:" + list.set(0, "xxx"));
System.out.println("将aaa替换为xxx后:" + list);
}
}
学习一个异常:并发修改异常
package cn.itcast.demo12_List迭代器的并发修改异常;
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
/*
* 并发修改异常:
*
* 1.产生原因:通常是当我们使用"迭代器"遍历集合时,通过"集合对象"去修改集合中的元素,
* 这时,就会产生并发修改异常;
* 2.解决方式:
* 通过迭代器遍历,就通过迭代器去修改;
*/
public class Demo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("孙悟空");
list.add("猪八戒");
list.add("沙师弟");
list.add("唐三藏");
ListIterator it = list.listIterator();
while(it.hasNext()){
String str = (String)it.next();
if(str.equals("唐三藏")){
//向集合中添加一个元素:白龙马
// list.add("白龙马");//ConcurrentModificationException
it.add("白龙马");
}
}
System.out.println(list);
}
}
list的三个子类的特点:
Collection(接口):单列集合
|--List(接口):1.有序;2.可以存储重复值;
|--ArrayList(类):数组实现;线程不安全的(不同步的),效率高;
|--Vector(类):数组实现;线程安全的(同步的),效率低;
|--LinkedList(类):链表实现;线程不安全的(不同步的),效率高;
|--Set(接口):1.无序的;2.不能存储重复值;
Map(接口):双列集合
Vector集合的特有功能:
package cn.itcast.demo04_Vector的特有功能;
import java.util.Vector;
/*
* Collection(接口):
* |--List(接口):
* |--ArrayList(类):(无特有成员)
* |--Vector(类):
* 特有成员:
* public void addElement(Object obj):将元素obj添加到集合;
public Object elementAt(int index):获取index位置上的元素;
* |--Set(接口):
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个Vector
Vector vec = new Vector();
//2.填充集合
vec.add("aaa");
vec.addElement("bbb");
vec.addElement("ccc");
vec.add("ddd");
System.out.println("获取索引为1的元素:" + vec.elementAt(1));
//打印
System.out.println(vec);
}
}LinkedList的特有功能:
import java.util.LinkedList;
/*
* * Collection(接口):
* |--List(接口):
* |--ArrayList(类):(无特有成员)
* |--Vector(类):
* 特有成员:
* public void addElement(Object obj):将元素obj添加到集合;
public Object elementAt(int index):获取index位置上的元素;
|--LinkedList(类):
特有成员:
public void addFirst(E e)及addLast(E e)
public E getFirst()及getLast()
public E removeFirst()及public E removeLast()
* |--Set(接口):
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个LinkedList
LinkedList list = new LinkedList();
//2.填充集合
//普通的链表
/*
list.add("aaa");
list.add("bbb");
list.add("ccc");
*/
//压栈
list.addFirst("aaa");
list.addFirst("bbb");
list.addFirst("ccc");
System.out.println("getFirst()获取第一个元素:" + list.getFirst());
System.out.println("移除第一个元素:" + list.removeFirst());
//打印
System.out.println(list);
}
}
泛型的简介:
import java.util.ArrayList;
import java.util.List;
/*
* 泛型概述和基本使用
*
* 1.对于某些类来说(尤其是集合类),我们很可能期望在这个类中只存储某种特定的类型;
* 2.比如:集合类
* 1).本身是可以存储任何的引用类型的元素;这种功能看似非常的强大,
* 但取出时,反而为我们带来了一些麻烦;
* 2).起始我们在开发中,经常需要在一个集合中只存储一种类型的数据,这样也能避免
* 取出时进行强制转换时产生异常;
* 3).这时,Java中提供了一种机制,可以让我在定义集合时,就指定在这个集合中存储
* 某种类型的数据,那么在后续代码中,当我们调用集合的add()方法时,就只能向集合
* 中添加这种类型的数据,否则就会编译异常;这种机制:泛型
* List list = new ArrayList();//JDK7以前
* 或
* List list = new ArrarList<>();//JDK7版本之后(常用)
* 或
* List list = nwe ArrayList();
* 4).泛型的其它说明:
* 1>.泛型不只可以用在集合类中,类库中有很多其它的一些普通类,也支持泛型;
* 2>.泛型,只存在于"编译期",一旦编译成class之后,就将泛型信息丢弃;
*/
public class Demo {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
/*list.add(10);
list.add(3.14);*/
//遍历
for(int i = 0;i < list.size() ; i++){
//如果这里需要向下转型
/*Object obj = list.get(i);
if(obj instanceof String){
String str = (String)obj;
System.out.println(str);
}
if(obj instanceof Integer){
Integer intObj = (Integer)obj;
System.out.println(intObj);
}
if(obj instanceof Double){
Double dObj = (Double)obj;
System.out.println(dObj);
}*/
//使用泛型之后
String str = list.get(i);
System.out.println(str);
}
}
}
增强for的概述:
* 1.增强for(也叫:foreach循环)可以很简便的语法遍历:数组、集合
* 2.例如遍历数组:编译后,被编译成"普通for循环"
遍历集合:编译后,被编译为"迭代器的方式"
3.增强for特点:
1).在使用增强for时,没有使用"循环变量";
2).所以,如果在循环过程中需要使用循环变量,那么还得使用普通for循环;
如果不需要循环变量,只是简单的从头遍历到结尾,那么可以考虑使用"增强for";
简单介绍一下Arrays类中的一个方法:public static
途径用户界面MVC分层模式:由于代码量太多,就不上代码了,简单说一说MVC模式之我的理解。MVC模式就是将代码分层实现,视图层,控制层,持久层,模型层。以后修改代码方便,修改某一个层的代码不会影响其他层的代码。便于维护
下面开始了set集合的总结:
import java.util.Collection;
import java.util.HashSet;
/*
* Set集合概述:
*
* Collection(接口):单列集合
* |--List(接口):1.有序的;2.可以存储重复值;
* |--ArrayList(类):数组实现:线程不安全(不同步),效率高;
* |--Vector(类):数组实现:线程安全的(同步),效率低;
* |--LinkedList(类):链表实现:线程不安全的(不同步),效率高;
* |--Set(接口):1.无序的;2.不能存储重复值;
* |--HashSet(类):
* |--LinkedHashSet(类):
* |--TreeSet(类):
* Map(接口):双列集合
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个Set对象
Collection set = new HashSet<>();
//2.填充元素
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("ddd");
//存储重复元素
String s1 = new String("ccc");
String s2 = new String("ddd");
set.add(s1);//添加失败
set.add(s2);//添加失败
set.add("eee");
//3.遍历
//1.toArray()
//2.iterator();
//3.增强for;
for(String s : set){
System.out.println(s);//取出时,跟存入的顺序不同;
}
}
}
linkedHashSet 集合:
import java.util.LinkedHashSet;
/*
* Collection
* |--List:
* |--Set:
* |--HashSet(类):哈希表实现;
* 保证元素唯一性:hashCode()和equals();
* |--LinkedHashSet(类):由链表、哈希表实现;(特例:有序)
* 由"链表"保证顺序;
* 由"哈希表"保证元素唯一;
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个LinkedHashSet
LinkedHashSet strSet = new LinkedHashSet<>();
//2.填充集合
strSet.add("aaa");
strSet.add("bbb");
strSet.add("ccc");
strSet.add("ddd");
//3.遍历
for(String s : strSet){
System.out.println(s);//有序的;
}
}
} TreeSet集合:
|--TreeSet:对元素进行排序的;
排序的方式:
1.自然排序:
2.比较器排序:由于涉及到排序,所以就不拿String排序了,直接举例存储自定义元素,实现比较器
示例一:存储自定义对象,自然排序
import java.util.TreeSet;
/*
* 当使用TreeSet存储自定义对象时:
* 1.实现"自然排序":
* 1.要存储的元素实现Comparable接口;
* 2.并重写compareTo()方法;
* 或者
* 2.实现"比较器":
* 1.要存储的元素,无需实现任何接口;
* 2.自定义比较器类,实现:Comparator接口;
* 重写:compare()方法;
* 3.在实例化TreeSet时,将自定义的比较器传给TreeSet构造方法;
*/
public class Demo {
public static void main(String[] args) {
TreeSet stuSet = new TreeSet<>();
stuSet.add(new Student("zhagnxueyou",20));//TreeSet的add()方法中,自动调用元素的compareTo()方法
stuSet.add(new Student("liudehua",22));
stuSet.add(new Student("zhangziy",24));
stuSet.add(new Student("daolang",22));
stuSet.add(new Student("chenglong",23));
stuSet.add(new Student("kangshifu",25));
stuSet.add(new Student("kangshifu",27));
//遍历
for(Student stu : stuSet){
System.out.println(stu.name + "," + stu.age);
}
}
}
public class Student implements Comparable{
String name;
int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public int compareTo(Student o) {
System.out.println("this.name = " + this.name + " o.name = " + o.name);
//1.先按姓名排序
int n1 = this.name.compareTo(o.name);
//2.如果姓名相同,按年龄排序
int n2 = (n1 == 0 ? this.age - o.age : n1);
return n2;
}
}
示例2 :存储自定义对象,比较器排序,因为对象类照常写,这里只展示集合类的写法
import java.util.Comparator;
import java.util.TreeSet;
public class Demo {
public static void main(String[] args) {
//1.实例化一个TreeSet
TreeSet stuSet = new TreeSet<>(new MyComparator());
stuSet.add(new Student("zhangxueyou",20));
stuSet.add(new Student("liudehua",22));
stuSet.add(new Student("zhangziyi",24));
for(Student stu : stuSet){
System.out.println(stu.name + "," + stu.age);
}
}
}
class MyComparator implements Comparator{
@Override
public int compare(Student o1, Student o2) {
System.out.println("o1.name = " + o1.name + " o2.name = " + o2.name);
//1.先按姓名比
int n1 = o1.name.compareTo(o2.name);
//2.如果姓名相同,比较年龄
int n2 = (n1 == 0 ? o1.age - o2.age : n1);
return n2;
}
}
Map集合
Map(接口):双列集合:在存储时,同时指定两个字段;一个做"键",一个做"值"(键值对);
|--HashMap:哈希表结构:
|--LinkedHashMap:链表、哈希表结构:
|--TreeMap:树结构:
以上Map接口的各种"数据结构"全部是针对"键"有效,跟"值"无关
import java.util.HashMap;
import java.util.Map;
/*
* Map接口的基本功能:
*
* 注:以下方法中标示为:K的表示:键,V的表示:值
*
* V put(K key,V value) :向集合中添加"键值对",如果发生重复的键,将用新值替换原值,并将原值返回;
V remove(Object key):移除key所指定的"键值对"
void clear():清空集合
boolean containsKey(Object key):判断是否包含指定key
boolean containsValue(Object value):判断是否包含指定的value
boolean isEmpty():判断集合是否为空
int size():集合中"键值对"的数量
*/
public class Demo {
public static void main(String[] args) {
Map map = new HashMap<>();
System.out.println(map.put("it001", "刘德华"));
System.out.println(map.put("it002", "张学友"));
System.out.println("集合元素:" + map);
System.out.println(map.put("it002", "章子怡"));//替换原it002对应的值
System.out.println("集合元素:" + map);
System.out.println("移除掉it001:" + map.remove("it001"));
System.out.println("移除后的集合:" + map);
//清空集合
// map.clear();
System.out.println("是否包含键:it001 : " + map.containsKey("it001"));
System.out.println("是否包含值:章子怡 : " + map.containsValue("章子怡"));
System.out.println("是否包含值:刘德华 :" + map.containsValue("刘德华"));
System.out.println("集合是否为空:" + map.isEmpty());
System.out.println("集合中元素数量:" + map.size());
}
Map的获取功能:
V get(Object key):使用指定key查找对应"值"
Set
Collection
Set
一个Entry内部封装了一个"键"和一个"值"
public class Demo {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("it001", "刘德华");
map.put("it002", "张学友");
map.put("it003", "郭富城");
map.put("it004", "黎明");
System.out.println("it003对应的值:" + map.get("it003"));
Set keys = map.keySet();
//遍历键的集合
for(String key : keys){
System.out.println(key + "," + map.get(key));
}
System.out.println("******获取所有的值**********");
Collection values = map.values();
for(String v : values){
System.out.println(v);
}
System.out.println("******获取所有的键值对--对象*******");
Set> entrySet = map.entrySet();
for(Map.Entry m : entrySet){
String key = m.getKey();
String value = m.getValue();
System.out.println(key + "," + value);
}
}
} map集合中键是基本数据类型和String类型的比较简单,这里主要整理键是自定义类型时候的问题,因为当键是自定义类型的时候,需要重写一些方法:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* HashMap集合键是Student值是String的案例
*
* 1.由于Student做键,HashMap对键使用"哈希表结构",要判断键的重复性,使用hashCode()和equals()
* 2.所以,使用自定义做键,要重写hashCode和equals()方法;
*
*/
public class Demo {
public static void main(String[] args) {
Map map = new HashMap<>();
//填充集合
map.put(new Student("张学友",20), "it001");
map.put(new Student("刘德华",22), "it002");
map.put(new Student("张曼玉",18), "it003");
map.put(new Student("章子怡",19), "it004");
map.put(new Student("章子怡",19), "it005");
Set> entrySet = map.entrySet();
for(Map.Entry e : entrySet){
Student stu = e.getKey();
String value = e.getValue();
System.out.println("键:" + stu.name + "," + stu.age + " 值:" + value);
}
}
}
链表哈希表结构:特点:有序,谁保证顺序:链表
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
/*
* LinkedHashMap的概述和使用
*
* 1.有序的;由链表保证顺序;
* 2.由哈希表保证元素唯一;
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个LinkedHashMap
Map map = new LinkedHashMap<>();
//2.填充集合
map.put("it001", "刘德华");
map.put("it002", "张学友");
map.put("it003", "章子怡");
map.put("it004", "刘亦菲");
map.put("it004", "高圆圆");
//3.遍历集合
Set keys = map.keySet();
for(String key : keys){
System.out.println(key + "," + map.get(key));//取出时,跟存入的顺序是一样的;
}
}
}
最后,是Treemap集合的知识,Treemap是排序的双列集合,底层是数结构:这里使用匿名内部类的方式实现比较器
import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;
/*
* TreeMap集合键是Student值是String的案例
*
* 自定义对象做键,必须实现两种比较的方式之一;
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个对象
TreeMap map = new TreeMap<>(
new Comparator(){
@Override
public int compare(Student o1, Student o2) {
//1.先按姓名排序
int n1 = o1.name.compareTo(o2.name);
//2.如果姓名相同,按年龄排序
int n2 = (n1 == 0 ? o1.age - o2.age : n1);
return n2;
}});
//2.填充集合
map.put(new Student("刘德华",20), "it001");
map.put(new Student("张学友",22), "it002");
map.put(new Student("章子怡",24), "it003");
map.put(new Student("章子怡",24), "it004");
Set keys = map.keySet();
for(Student stu : keys){
System.out.println("键:" + stu.name + "," +
stu.age + " 值:" + map.get(stu));
}
}
}
import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;
/*
* TreeMap集合键是Student值是String的案例
*
* 自定义对象做键,必须实现两种比较的方式之一;
*/
public class Demo {
public static void main(String[] args) {
//1.实例化一个对象
TreeMap map = new TreeMap<>(
new Comparator(){
@Override
public int compare(Student o1, Student o2) {
//1.先按姓名排序
int n1 = o1.name.compareTo(o2.name);
//2.如果姓名相同,按年龄排序
int n2 = (n1 == 0 ? o1.age - o2.age : n1);
return n2;
}});
//2.填充集合
map.put(new Student("刘德华",20), "it001");
map.put(new Student("张学友",22), "it002");
map.put(new Student("章子怡",24), "it003");
map.put(new Student("章子怡",24), "it004");
Set keys = map.keySet();
for(Student stu : keys){
System.out.println("键:" + stu.name + "," +
stu.age + " 值:" + map.get(stu));
}
} 集合工具类:
集合的工具类:java.util.Collections(工具类):里面包含了一些对Collection集合操作的一些常用方法;
1.之前我们讲过数组的工具类:Arrays;它是对数组操作的工具类;
2.还学过一个接口Collection,它是List和Set集合的顶层接口;
Collections工具类的常用方法:
public static
public static
public static
public static void reverse(List list):反转指定列表中元素的顺序。
public static void shuffle(List list):打乱集合内元素的顺序;
一个比较重要的小知识:hashmap和hashtable的区别:
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
/*
* 面试题:HashMap和Hashtable的区别
*
* Hashtable:
* 1.任何非 null 对象都可以用作键或值
* 2.从1.0版本开始;
* 3.线程安全的(同步的),效率低;
* HashMap:
* 1.允许使用 null 值和 null 键
* 2.从1.2版本开始;
* 3.线程不安全的(非同步的),效率高;
*/
public class Demo {
public static void main(String[] args) {
Map table = new Hashtable<>();
table.put("it001", "郑智");
// table.put(null, "郜林");//空指针异常
// table.put("it002", null);//空指针异常
Map map = new HashMap<>();
map.put(null, "郑智");
map.put("it002", null);
map.put("it003", null);
map.put("it004", null);
map.put(null, "郜林");
System.out.println("map = " + map);
}
} 最后,做一个集合知识框架最终结构图:
一.集合的特点和数据结构总结
Collection(接口):单列集合
|--List(接口):1.有序的;2.可以存储重复值;
|--ArrayList(类):数组实现;线程不安全的(不同步),效率高;
|--Vector(类):数组实现;线程安全的(同步),效率低;
|--LinkedList(类):链表;线程不安全的(不同步),效率高;
|--Set(接口):1.无序的;2.不能存储重复值;
|--HashSet(类):哈希表实现;
保证元素唯一性的方法:hashCode()和equals()方法;
|--LinkedHashSet(类):链表、哈希表实现;(特例:有序的)
链表:保证顺序;
哈希表:保证元素唯一;
|--TreeSet(类):树实现;
对元素排序和保证元素唯一的方法:
1.自然排序:
1).要存储的元素实现Comparable接口
2).重写compareTo()方法;
2.比较器排序:
1).要自定义比较器,实现Comparator接口;
2).重写compare()方法;
3).实例化TreeSet时,将自定义比较器对象作为参数传递给TreeSet的构造方法;
Map(接口):双列集合
|--HashMap(类):键:哈希表结构:
|--LinkedHashMap(类):键:链表、哈希表结构
|--TreeMap(类):键:树结构
|--Hashtable(类):键:哈希表结构;
HashMap和Hashtable的区别:
1.Hashtable:
1).不能存储null键和null值;
2).从1.0版本开始;
3).线程安全的(同步),效率低;
2.HashMap:
1).可以存储null键和null值;
2).从1.2版本开始;
3).线程不安全的(不同步),效率高;
二.数据结构:
1.数组:查询快;增删慢;
2.链表:查询慢;增删快;
3.栈:先进后出;
4.队列:先进先出;
5.哈希表:综合了数组和链表的优点,增删、查询都很快,关键是取决于:哈希算法;
6.树:对元素进行排序;
1).比当前节点元素小,存到左边;
2).比当前节点元素大,存到右边;
3).如果相等,不存;
三.如何选择使用哪种集合呢:
单列还是双列:
单列:Collection:
|--有序无序;是否存储不重复:
|--有序:
ArrayList、Vector、LinkedList
|--无序:
HashSet(不重复)、LinkedHashSet(有序,不重复)、TreeSet(排序、不重复)
双列:Map
|--是否有序:
|--是:LinkedHashMap
|--是否排序:
|--是:TreeMap
|--否:HashMap
四.遍历方式总结:
Collection(接口):
|--(1).toArray():
|--(2).iterator():迭代器
|--(3).增强for
|--List(接口):
|--(4).结合Collection的size和List的get()方法,使用普通for循环;
|--(5).ListIterator():可以双向遍历;
|--Set(接口):
(无特有遍历方式)
Map(接口):
(1).keySet():
(2).entrySet():
最后,做一个集合知识框架最终结构图:
一.集合的特点和数据结构总结
Collection(接口):单列集合
|--List(接口):1.有序的;2.可以存储重复值;
|--ArrayList(类):数组实现;线程不安全的(不同步),效率高;
|--Vector(类):数组实现;线程安全的(同步),效率低;
|--LinkedList(类):链表;线程不安全的(不同步),效率高;
|--Set(接口):1.无序的;2.不能存储重复值;
|--HashSet(类):哈希表实现;
保证元素唯一性的方法:hashCode()和equals()方法;
|--LinkedHashSet(类):链表、哈希表实现;(特例:有序的)
链表:保证顺序;
哈希表:保证元素唯一;
|--TreeSet(类):树实现;
对元素排序和保证元素唯一的方法:
1.自然排序:
1).要存储的元素实现Comparable接口
2).重写compareTo()方法;
2.比较器排序:
1).要自定义比较器,实现Comparator接口;
2).重写compare()方法;
3).实例化TreeSet时,将自定义比较器对象作为参数传递给TreeSet的构造方法;
Map(接口):双列集合
|--HashMap(类):键:哈希表结构:
|--LinkedHashMap(类):键:链表、哈希表结构
|--TreeMap(类):键:树结构
|--Hashtable(类):键:哈希表结构;
HashMap和Hashtable的区别:
1.Hashtable:
1).不能存储null键和null值;
2).从1.0版本开始;
3).线程安全的(同步),效率低;
2.HashMap:
1).可以存储null键和null值;
2).从1.2版本开始;
3).线程不安全的(不同步),效率高;
二.数据结构:
1.数组:查询快;增删慢;
2.链表:查询慢;增删快;
3.栈:先进后出;
4.队列:先进先出;
5.哈希表:综合了数组和链表的优点,增删、查询都很快,关键是取决于:哈希算法;
6.树:对元素进行排序;
1).比当前节点元素小,存到左边;
2).比当前节点元素大,存到右边;
3).如果相等,不存;
三.如何选择使用哪种集合呢:
单列还是双列:
单列:Collection:
|--有序无序;是否存储不重复:
|--有序:
ArrayList、Vector、LinkedList
|--无序:
HashSet(不重复)、LinkedHashSet(有序,不重复)、TreeSet(排序、不重复)
双列:Map
|--是否有序:
|--是:LinkedHashMap
|--是否排序:
|--是:TreeMap
|--否:HashMap
四.遍历方式总结:
Collection(接口):
|--(1).toArray():
|--(2).iterator():迭代器
|--(3).增强for
|--List(接口):
|--(4).结合Collection的size和List的get()方法,使用普通for循环;
|--(5).ListIterator():可以双向遍历;
|--Set(接口):
(无特有遍历方式)
Map(接口):
(1).keySet():
(2).entrySet():