论文学习《Recurrent Convolutional Neural Net works for Text Classification》
论文:
《Recurrent Convolutional Neural Networks for Text Classification》 作者Siwei Lai,Liheng Xu, Kang Liu, Jun Zhao
代码:https://github.com/roomylee/rcnn-text-classification
摘要:
- 传统文本分类需依赖人为设计的特征,比如知识库等
- 引入无需人为设计特征的循环结构的神经网络来进行文本分类
- 在这个模型中,在学习词表示时采用循环结构尽可能地捕获上下文信息
- 利用max-pooling层自动判断哪些词在文本中起到关键作用,以捕获文本中地关键词
- 对四个常用数据集进行实验,实验结果表明,在几个数据集上优于当时最先进的方法,尤其是在文档级别的数据集上
介绍
- 文本分类的关键是特征表示,特征选择的方法有词频、MI、pLSA、LDA
- 传统特征表示会忽略文本中的上下文信息、单词顺序、单词语义的准确性。比如n-gram和更复杂的tree kernels都旨在获取更多的上下文信息和单词顺序,但是它们仍然具有数据稀疏性问题,会严重影响分类的准确性
- 词嵌入是单词的分布式表示,环节数据稀疏性问题,单词嵌入可以捕捉有意义的句法和语义规律。在词嵌入的帮助下,提出基于组合方法来获取文本的语义表示
- RecursiveNN在构造句子方面是有效的,但是在通过树结构来捕获句子的语义时需要取决于文本树结构的性能。构造文本树的时间复杂度是O(2^n),其中n=len(文本),所以当模型遇到长句过文档时,非常耗时,而且两个句子之间的关系很难用树结构来表示,所以,RNN不适合建模长句或文档。
- RecurrentNN
优点:
1)模型的时间复杂度只有O(n)
2) 具有很好的语义捕获能力,有助于捕获长文本的语义。
缺点:
1)有偏模型(biased model)
2)RNN在捕获文档时,捕获后面词的语义要比捕获文档前面的词要更占优势(也就说RNN 后面时间的节点对于前面时间的节点感知力下降,也就是忘事儿,这也是NN在很长一段时间内不得志的原因,网络一深就没法训练了,深度学习那一套东西暂且不表,RNN解决这个问题用到的就叫LSTM,简单来说就是你不是忘事儿吗?我给你拿个小本子把事记上,好记性不如烂笔头嘛,所以LSTM引入一个核心元素就是Cell。 )
结论:
用RNN捕获整个文档的语义时,可能会降低效率,因为关键词可能出现在文档中的任意位置 - CNN
优点:
1)与递归或RNN相比可以更好得获取文本得语义
2)时间复杂度也为O(n)与递归或RNN相比可以更好得获取文本得语义
3)无偏模型(unbiased model),可通过最大池化获得重要特征
缺点:
1)CNN使用简单的卷积核作为固定窗口。但是这种内核很难确定窗口的大小,窗口小了会丢失一些关键信息,窗口大了会导致出现一个很难训练的大参数空间
结论:
如何比传统的基于窗口的神经网络学习到更多上下文新信息,准确地分类 - Recurrent Convolutional Neural Network(RCNN)
特点:
1)引用双向递归结构
优点:
1)比传统基于窗口的神经网络相比,引入的噪声少
2)学习单词表示时最大程度地捕获上下文信息
3)文本表示时可保留最大范围的单词排序
4)最大池化层判断哪些特征在文本分类中起关键作用
5)结合递归结构和max-pooling,利用RNN和CNN的优势
6)时间复杂度O(n)
相关工作
文本分类
- 传统文本分类的工作:特征工程、特征选择、机器学习模型
- 特征工程:
广泛使用BOW(词袋),还有词性标签part-of-speech tags、实体和tree kernels - 特征选择:
删除噪声特征:如去除停顿词,使用信息增益,L1正则化 - 机器学习模型:
逻辑回归(LR),朴素贝叶斯(NB),支持向量机(SVM) --> 存在数据稀疏性问题
深度学习网络
- 词嵌入:单词的神经网络表示,一种实值矢量。词嵌入通过两个嵌入向量之间的距离测量单词相关性
模型
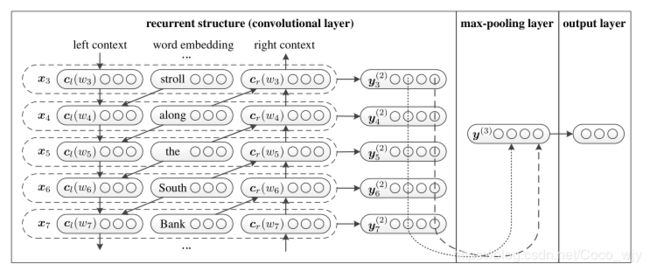
模型的输入: 词w1,w2,…,wn序列表示的文档D
模型的输出:类别
文档属于k类的概率可以表示为P(k|D,θ),其中θ是网络的参数
词表示的学习
- 一个单词的表示是该单词及其上下文来表达的,因为上下文可以帮助获得更精准的词义,在模型中使用双向递归神经网络来捕捉上下文
- 定义:
1) c l ( w i ) c_l(w_i) cl(wi)是单词 w i w_i wi上文左侧词汇,2) c r ( w i ) c_r(w_i) cr(wi)是单词 w i w_i wi下文右侧词汇,
3)单词 w i w_i wi左侧上下文 c l ( w i ) = f ( W ( l ) c l ( w i − 1 ) + W ( s l ) e ( w i − 1 ) ) c_l(w_i) = f(W^{(l)}c_l(w_{i-1}) + W^{(sl)}e(w_{i-1})) cl(wi)=f(W(l)cl(wi−1)+W(sl)e(wi−1))
其中 e ( w i − 1 ) e(w_{i-1}) e(wi−1)是单词 w i − 1 w_{i-1} wi−1的词嵌入,是一个实值为|e|的稠密向量,
c l ( w i − 1 ) c_l(w_{i-1}) cl(wi−1)是单词 w i − 1 w_{i-1} wi−1左侧上下文
4)任何文档左侧上下文的第一个单词都使用相同的共享参数 c l ( w 1 ) c_l(w_1) cl(w1)
5) W ( l ) W^{(l)} W(l)是一个将hidden layer(context)转为下一个hidden layer的矩阵
6) W ( s l ) W^{(sl)} W(sl) 将当前词同它下一个词的左上文词相结合的矩阵。
7)f是一个非线性激活函数
8) w i w_i wi右侧上下文 c r ( w i ) = f ( W ( r ) c r ( w i + 1 ) + W ( s r ) e ( w i + 1 ) ) c_r(w_i) = f(W^{(r)}c_r(w_{i+1}) + W^{(sr)}e(w_{i+1})) cr(wi)=f(W(r)cr(wi+1)+W(sr)e(wi+1)) - eg:“A sunset stroll along the South Bank affords an array of stunning vantage points”
例如结构图中 c l ( w 7 ) c_l(w_7) cl(w7)是对"bank"例如结构图中 c l ( w 7 ) c_l(w_7) cl(w7)是对"Bank"左侧上下文“along the South”以及句子中之前的所有文本的语义进行编码; c r ( w 7 ) c_r(w_7) cr(w7)对“Bank”右侧上下文“affords an…”的语义进行编码。
单词 w i w_i wi的表示为 x i = [ c l ( w i ) ; e ( w i ) ; c r ( w i ) ] x_i = [c_l(w_i);e(w_i);c_r(w_i)] xi=[cl(wi);e(wi);cr(wi)]
其中 c l ( w i ) c_l(w_i) cl(wi)是单词 w i w_i wi左侧上下文向量; c r ( w i ) c_r(w_i) cr(wi)是单词 w i w_i wi右侧上下文向量; e ( w i ) e(w_i) e(wi)是单词 w i w_i wi的词嵌入,三者 串联 - 循环结构可以在文本的正向查找中获取所有的 c l c_l cl,向后查找中获取 c r c_r cr,且时间复杂度为O(n),与文本长度呈线性相关
- 线性变换和tanh激活函数结合作用于单词 w i w_i wi的表示 x i x_i xi,将结果传递给下一层,即 x i x_i xi作为输入,输入到激活函数为tanh,kernel size为1的卷积层,得到 w i w_i wi的潜在语义向量(latent semantic vector): y i ( 2 ) y^{(2)}_i yi(2)
- y i ( 2 ) = t a n h ( W ( 2 ) x i + b ( 2 ) ) y^{(2)}_i= tanh(W^{(2)}x_i + b^{(2)}) yi(2)=tanh(W(2)xi+b(2))
文本表示学习
- 模型中的卷积神经网络的目的:表示文本
- 模型中的循环结构是卷积层,用max-pooling layer计算单词表示
- 经过卷积层后,获得了所有词的表示,然后在经过最大池化层和全连接层得到文本的表示,最后通过softmax层进行分类。
- max function是逐元函数(element-wise function), y ( 3 ) y^{(3)} y(3)的第k个元素是 y i ( 2 ) y^{(2)}_i yi(2)的第k个元素中最大值
- Max-pooling layer: y ( 3 ) = m a x i = 1 n y i ( 2 ) y^{(3)} = max^{n}_{i=1}y^{(2)}_i y(3)=maxi=1nyi(2)
- pooling layer 将各种长度的文本转换为固定长度的矢量,通过pooling layer可获取整个文本中的信息,pooling layer还有其他种类例如:average pooling layer
- max-pooling :寻找文本中最重要的特征
pooling将循环结构得到的上下文作为输入,时间复杂度为O(n),循环结构和max-pooling级联,该模型的时间复杂度仍为O(n)。 - 输出层(全连接层):
y ( 4 ) = W ( 4 ) y ( 3 ) + b ( 4 ) y^{(4)} = W^{(4)}y^{(3)} + b^{(4)} y(4)=W(4)y(3)+b(4) - softmax层将输出的 y ( 4 ) y^{(4)} y(4)转换为概率
p i = e x p ( y i ( 4 ) ) ∑ k = 1 n e x p ( y k ( 4 ) ) p_i = \frac{exp(y^{(4)}_i)}{\sum_{k=1}^{n}exp(y^{(4)}_k)} pi=∑k=1nexp(yk(4))exp(yi(4)) - 整个模型的流程:
1)先经过1层双向LSTM,该词的左侧的词正向输入进去得到一个词向量,该词的右侧反向输入进去得到一个词向量。再结合该词的词向量,生成一个 1*3k 的向量。
2)再经过全连接层,tanh为非线性函数,得到 y ( 2 ) y^{(2)} y(2)。
3)再经过最大池化层,得出最大化向量 y ( 3 ) y^{(3)} y(3).
4)再经过全连接层,得到 y ( 4 ) y^{(4)} y(4)sigmod为非线性函数,得到最终的多分类。再由softmax层获得众多分类的概率
训练
训练网络参数
- 定义所有被训练的参数为θ, θ \theta θ = {E, b ( 2 ) b^{(2)} b(2), b ( 4 ) b^{(4)} b(4), c l ( w 1 ) c_l(w_1) cl(w1), c r ( w n ) c_r(w_n) cr(wn), W ( 2 ) W^{(2)} W(2), W ( 4 ) W^{(4)} W(4), W ( l ) W^{(l)} W(l), W ( s l ) W^{(sl)} W(sl), W ( s r ) W^{(sr)} W(sr)}
- 网络训练的目标是使最大似然的参数θ:θ --> ∑ D ∈ D l o g p ( c l a s s D ∣ D , θ ) \sum_{D\in D}log p(class_D | D, \theta) ∑D∈Dlogp(classD∣D,θ),其中 D ∈ D D\in D D∈D后面的D是训练文本集, c l a s s D class_D classD是文本D的正确分类
- 利用随机梯度下降来优化训练目标。在每一步,随机选择一组样本(D, c l a s s D class_D classD)并作 一次梯度下降 θ \theta θ <-- θ + α ∂ l o g p ( c l a s s D ∣ D , θ ) ∂ θ \theta + \alpha{\frac{\partial log p(class_D | D, \theta)}{\partial \theta}} θ+α∂θ∂logp(classD∣D,θ) ,其中 α \alpha α是学习率
预训练词嵌入
- 词嵌入是一个词的分布式表示,用于神经网络的输入,传统的独热表示会带来维度上的灾难
- 这篇文章采用Skip-Gram模型预训练词向量,通过最大化平均对数概率:
1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 l o g p ( w t + j ∣ w t ) \frac{1}{T}\sum^{T}_{t=1}\sum_{-c\leq j\leq c,j\neq 0}log p(w_{t+j}|w_t) T1∑t=1T∑−c≤j≤c,j̸=0logp(wt+j∣wt)
p ( w b ∣ w a ) = e x p ( e ′ ( w b ) T e ( w a ) ) ∑ k = 1 ∣ V ∣ e x p ( e ′ ( w k ) T e ( w a ) ) p(w_b|w_a) = \frac{exp(e\prime(w_b)^Te(w_a))}{\sum^{|V|}_{k=1}exp(e\prime(w_k)^Te(w_a))} p(wb∣wa)=∑k=1∣V∣exp(e′(wk)Te(wa))exp(e′(wb)Te(wa)),|V|是未标记文本的词汇, e ′ ( w i ) e\prime(w_i) e′(wi)是单词 w i w_i wi的另一个嵌入
实验
数据集
- 选用四种数据集

1)20Newsgroup: 包含了来自20个新闻组的信息,使用bydate版本的数据并选择四个主要类别哦
2)Fudan set: 来自复旦大学的中文文献分类集,20个类包括艺术、教育和能源
3)ACL Anthology Network 这个数据集包含ACL和相关组织发布的文献标注了五种语言:英语、日语、德语、中文和法语
4)Stanford Sentiment Treebank :包含了被解析和标记了的电影评论,标签分为消极,负面,中性,正面
实验设置
- 将四个数据集分为训练集和测试集.ACL、SST数据集预定义为训练、开发、测试分离,对于其他的两个数据集。10%的训练集分成一个development set、90%的training set
- 超参数的设置取决于适应的数据集,随机梯度下降 α \alpha α的学习率设置为入0.01,Hidden_size H=100,词向量的矢量大小为|e| = 50, 上下文的大小为|c|=50,word embedding用在word2vec中默认参数和Skip-Gram算法
方法比较
- Bag of Words/Bigrams + LR/SVM:
文本分类的基准主要使用单词或双词作为特征的机器学习算法。 分别使用LR和SVM,每个特征的权重为术语出现的频率。 - Average Embedding + LR :
这个基准使用词嵌入的平均权重,随后应用到一个softmax层。每个单词的权重是它词频-逆向文件频率的值 - LDA:
在集中分类任务中,基于LDA的方法能够较好捕获文本的语义。我们选择两种方法用于比较:ClassifyLDA-EM和Labeled-LDA - 使用各种tree kernel作为特征,是ACL母语分类任务中最先进的工作。列举两个主要方法用以比较:the context-free grammar (CFG) produced by the Berkeley parser and the reranking feature set of Charniak and Johnson。
- RecursiveNN:
我们使用两种递归结构比较:递归神经网络(RecursiveNN)和递归神经张量网络(RNTNs)。 - CNN :
选择卷积神经网络用于比较。它的卷积内核只是简单的级联了预定义窗口大小的词嵌入,词表示 x i = [ e ( w i − [ w i n / 2 ] ) ; . . . ; e ( w i ) ; . . . ; e ( w i + [ w i n / 2 ] ) ] x_i = [e(w_i-[win/2]);...;e(w_i);...;e(w_i+[win/2])] xi=[e(wi−[win/2]);...;e(wi);...;e(wi+[win/2])]
其中 w i n / 2 win/2 win/2前为向下取整括号
结论和讨论
实验结果如下
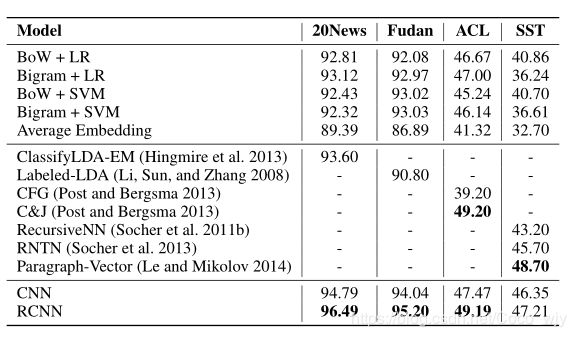
- 神经网络方法优于传统方法,证明了基于神经网络的方法可以有效地组成文本语义表示,神经网络可以比基于BOW传统方法捕获更多上下下文语义信息的特征,受到数据稀疏性的影响更小
- 使用SST数据对CNN、RCNN和RNN进行比较 ,可看到基于卷积的方法可以获得更好的结果,与递归神经网络相比,基于卷积的框架更适合于构建文本的语义表示 。主要原因是CNN可以通过max-pooling层来选择更具辨别力的特征,通过卷积层抓取上下文信息。相比之下,递归神经网路仅仅只能在文本构造树下通过语义构造捕获上下文的信息,这很大成单独上取决于树构造的结构。
- 递归神经网络构造句子表示的时间复杂度为0(n^2),此模型的时间复杂度为 O(n),使用单线程在SST数据集上训练只需几分钟
- 对于20News数据集,RCNN的错误率降级至33%,对于具有最佳基线的复旦集,错误率降低19%,结果证明了该方法的有效性
- RCNN与CFG和C&J对比,可以捕获更长距离模式(patterns)
- RCNN在所有情况下均优于CNN,原因是RCNN中的循环结构比CNN中的窗口结构更好地捕获上下文信息,结果证实了所提方法地有效性
上下文信息
- CNNs使用固定的词窗口(window of words), 实验结果受窗口大小影响
- RCNNs使用循环结构捕获广泛的上下文信息

学习关键词
max-pooling层获取在句子中出现频次最高地词作为trigram中心词
RNTN与RCNN在关键词学习上的学到的关键词如下
