hadoop-mapreduce进阶
本文围绕四部分展开
- Partitioner编程
- 自定义排序编程
- Combiner编程
- 常见的MapReduce算法
Partitioner编程
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
HashPartitioner是mapreduce的默认partitioner。计算方法是
which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
AreaPartitioner.java Github-repo-code
package com.elon33.hadoop.mapreduce.partition;
import java.util.HashMap;
import org.apache.hadoop.mapreduce.Partitioner;
public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE> {
private static HashMap areaMap = new HashMap<>();
static {
areaMap.put("136", 0);
areaMap.put("137", 1);
areaMap.put("138", 2);
areaMap.put("139", 3);
}
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
Integer provinceCode = areaMap.get(key.toString().substring(0, 3));
return provinceCode == null ? 4 : provinceCode;
}
} FlowCountPartition.java Github-repo-code
package com.elon33.hadoop.mapreduce.partition;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import com.elon33.hadoop.mapreduce.flowcount.FlowBean;
public class FlowCountPartition {
public static class FlowCountPartitionMapper
extends Mapper<LongWritable, Text, Text, FlowBean> {
private FlowBean flowBean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws
IOException, InterruptedException {
// 拿到一行数据
String line = value.toString();
// 切分字段
String[] fields = StringUtils.split(line, "\t");
// 拿到我们需要的若干个字段
String phoneNbr = fields[1];
long up_flow = Long.parseLong(fields[fields.length - 3]);
long d_flow = Long.parseLong(fields[fields.length - 2]);
// 将数据封装到一个flowbean中
flowBean.set(phoneNbr, up_flow, d_flow);
// 以手机号为key,将流量数据输出去
context.write(new Text(phoneNbr), flowBean);
}
}
public static class FlowCountPartitionReducer extends
Reducer<Text, FlowBean, Text, FlowBean> {
private FlowBean flowBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
long up_flow_sum = 0;
long d_flow_sum = 0;
for (FlowBean bean : values) {
up_flow_sum += bean.getUp_flow();
d_flow_sum += bean.getD_flow();
}
flowBean.set(key.toString(), up_flow_sum, d_flow_sum);
context.write(key, flowBean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "flowpartjob");
job.setJarByClass(FlowCountPartition.class);
job.setMapperClass(FlowCountPartitionMapper.class);
job.setReducerClass(FlowCountPartitionReducer.class);
/**
* 加入自定义分区定义 : AreaPartitioner
*/
job.setPartitionerClass(AreaPartitioner.class);
/**
* 设置reduce task的数量,要跟AreaPartitioner返回的partition个数匹配 ◆
* reducetask的数量比partitioner中分组数多,就会产生多余的几个空文件 ◆
* reducetask的数量比partitioner中分组数少,就会发生异常,因为有一些key没有对应reducetask接收 ◆
* reducetask的数量为1,也能正常运行,所有的key都会分给这一个reduce task) reduce task 或 map
* task 指的是,reuder和mapper在集群中运行的实例
*/
job.setNumReduceTasks(5);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("./wc/srcdata/input2"));
FileOutputFormat.setOutputPath(job, new Path("./wc/outdata/output3"));
job.waitForCompletion(true);
}
} 自定义排序编程
在map和reduce阶段进行排序时,比较的是k2。v2是不参与排序比较的。如果要想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。详见示例
分组时也是按照k2进行比较的。
利用在Bean中加入compareTo函数的实现,以及在map阶段将Bean通过key全部传入 实现自定义排序
FlowBean.java Github-repo-code
package com.elon33.hadoop.mapreduce.flowcount;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
/**
* 包含Bean对象字节流式传输的序列化和反序列化过程
*
* @author elon
*
*/
public class FlowBean implements WritableComparable<FlowBean> {
private String phoneNbr;
private long up_flow;
private long d_flow;
private long sum_flow;
public void set(String phoneNbr, long up_flow, long d_flow) {
this.phoneNbr = phoneNbr;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.sum_flow = up_flow + d_flow;
}
public String getPhoneNbr() {
return phoneNbr;
}
public void setPhoneNbr(String phoneNbr) {
this.phoneNbr = phoneNbr;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getSum_flow() {
return sum_flow;
}
public void setSum_flow(long sum_flow) {
this.sum_flow = sum_flow;
}
/**
* 序列化,将数据字段以字节流写出去
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNbr);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(sum_flow);
}
/**
* 反序列化,从字节流中读出各个数据字段 读出的顺序应该跟序列化时写入的顺序保持一致
*/
@Override
public void readFields(DataInput in) throws IOException {
phoneNbr = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
sum_flow = in.readLong();
}
@Override
public String toString() {
return up_flow + "\t" + d_flow + "\t" + sum_flow;
}
/**
* 对FlowBean添加排序机制:按照sun_flow从大到小排序
*/
@Override
public int compareTo(FlowBean o) {
return sum_flow > o.getSum_flow() ? -1 : 1;
}
}
FlowCountSort.java Github-repo-code
package com.elon33.hadoop.mapreduce.flowcount;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class FlowCountSort {
public static class FlowCountSortMapper extends
Mapper<LongWritable, Text, FlowBean, NullWritable> {
FlowBean bean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 拿到一行数据
String line = value.toString();
// 切分字段
String[] fields = StringUtils.split(line, "\t");
// 拿到我们需要的若干个字段
String phoneNbr = fields[0];
// long up_flow = Long.parseLong(fields[1]);
// long d_flow = Long.parseLong(fields[2]);
long up_flow = Long.parseLong(fields[fields.length - 3]);
long d_flow = Long.parseLong(fields[fields.length - 2]);
// 将数据封装到一个bean中
bean.set(phoneNbr, up_flow, d_flow);
// 以整个Bean对象作为key,将Bean整体都参与到排序中
context.write(bean, NullWritable.get());
}
}
public static class FlowCountSortReducer extends
Reducer<FlowBean, NullWritable, Text, FlowBean> {
@Override
protected void reduce(FlowBean bean, Iterable values, Context context)
throws IOException, InterruptedException {
// 以phone作为key,bean的toString方法作为value输出最终reduce结果
context.write(new Text(bean.getPhoneNbr()), bean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "sortjob");
job.setJarByClass(FlowCountSort.class);
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("./wc/srcdata/input2"));
FileOutputFormat.setOutputPath(job, new Path("./wc/outdata/output2"));
job.waitForCompletion(true);
}
}
Combiner编程
每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
Job执行流程图
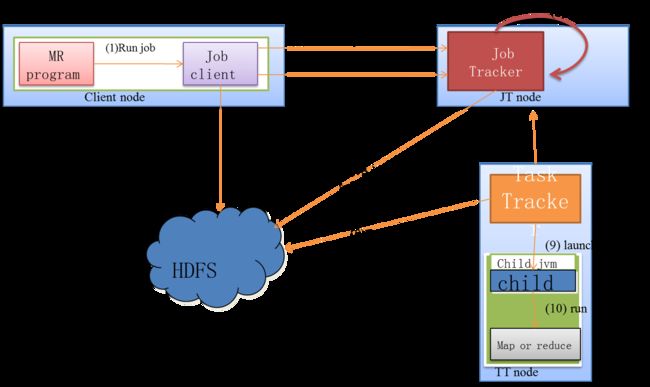
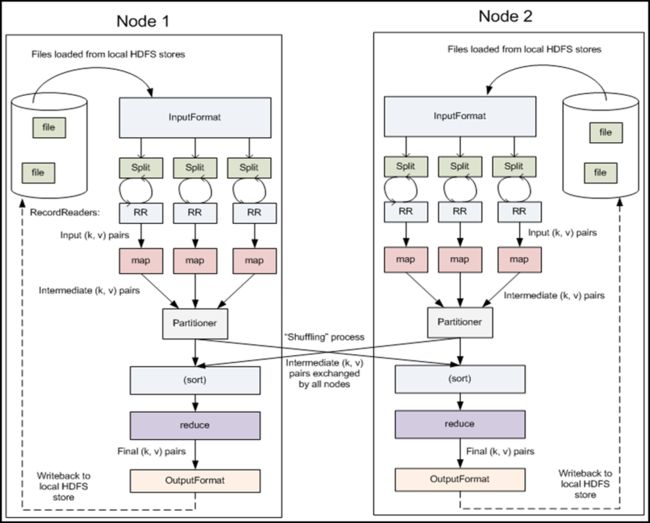
Shuffle
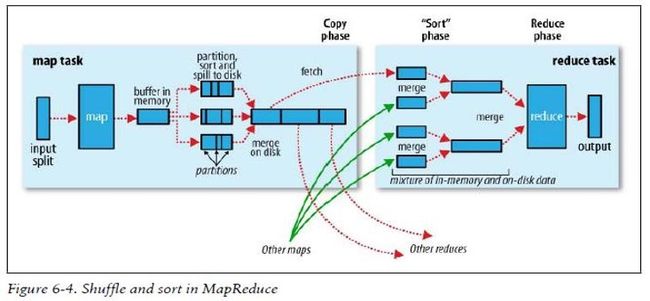
- 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
- Reducer通过Http方式得到输出文件的分区。
- TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
- 排序阶段合并map输出。然后走Reduce阶段。
常见的MapReduce算法
◆ 单词计数
◆ 数据去重
◆ 排序
◆ Top K
◆ 选择
◆ 投影
◆ 分组
◆ 多表连接
◆ 单表关联
参考链接:MapReduce中的常见算法 https://www.cnblogs.com/1130136248wlxk/p/4975116.html
倒排索引过程算法实现
通过多个文件,统计每个单词在每个文件中出现的次数,以 word file1-->count1 file2-->count2...形式输出最终结果
该mr程序分为两步:
1. 对同一文件夹中,相同的key值进行数值统计
2. 将不同文件中的同一个word,统计”文件–>计数“的信息,并拼接在一起输出
{% note success %}
源数据包–>利用map(切分)–>shuffer(合并)、sort(对key值排序)—>reduce(统计value值)—>输出结果
{% endnote %}
InverseIndexStepOne.java Github-repo-code
package com.elon33.hadoop.mapreduce.inverseIndex;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 倒排索引的第一个步骤
* 对同一文件夹中,相同的key值进行数值统计
* @author [email protected]
*
*/
//cn.itheima.bigdata.hadoop.mr.ii.InverseIndexStepOne
public class InverseIndexStepOne {
public static class InverseIndexStepOneMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = StringUtils.split(line, " ");
//获取本次调用传递进来的数据所在的文件信息,先要获取所属切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//从切片信息中获取到文件路径及文件名
String fileName = inputSplit.getPath().getName();
//输出 kv对 < hello-->a.txt , 1>
for (String word : words) {
k.set(word + "-->" + fileName);
v.set(1);
context.write(k, v);
}
}
}
public static class InverseIndexStepOneReducer extends
Reducer<Text, LongWritable, Text, LongWritable>{
private LongWritable v = new LongWritable();
// a.txt ,{1,1,1...}>
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
//遍历values进行累加
long count = 0;
for(LongWritable value:values){
count += value.get();
}
v.set(count);
context.write(key, v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job_stepOne = Job.getInstance(conf);
job_stepOne.setJarByClass(InverseIndexStepOne.class);
job_stepOne.setMapperClass(InverseIndexStepOneMapper.class);
job_stepOne.setReducerClass(InverseIndexStepOneReducer.class);
job_stepOne.setOutputKeyClass(Text.class);
job_stepOne.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job_stepOne, new Path("./wc/srcdata/input3"));
FileOutputFormat.setOutputPath(job_stepOne, new Path("./wc/outdata/output5"));
job_stepOne.waitForCompletion(true);
}
} InverseIndexStepTwo.java Github-repo-code
package com.elon33.hadoop.mapreduce.inverseIndex;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 倒排索引的第二个步骤、
* 将不同文件中的同一个word,统计”文件-->计数“的信息,并拼接在一起输出
* @author [email protected]
*
*/
public class InverseIndexStepTwo {
public static class InverseIndexStepTwoMapper extends
Mapper<LongWritable, Text, Text, Text> {
private Text k = new Text();
private Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
// 切分出各个字段
String[] fields = StringUtils.split(line, "\t");
long count = Long.parseLong(fields[1]);
String wordAndFile = fields[0];
String[] wordAndFileName = StringUtils.split(wordAndFile, "-->");
String word = wordAndFileName[0];
String fileName = wordAndFileName[1];
//将单词作为key ,文件-->次数 作为value 输出
k.set(word);
v.set(fileName + "-->" + count);
context.write(k, v);
}
}
public static class InverseIndexStepTwoReducer extends Reducer<Text, Text, Text, Text>{
// private Text k = new Text();
private Text v = new Text();
// key: hello values: [a-->3,b-->2,c-->1]
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
String result = "";
//一个key,有多个value 用result将多个value拼接在一起
for(Text value:values){
result += value + " ";
}
v.set(result);
// key: hello v: a-->3 b-->2 c-->1
context.write(key, v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job_stepTwo = Job.getInstance(conf);
job_stepTwo.setJarByClass(InverseIndexStepTwo.class);
job_stepTwo.setMapperClass(InverseIndexStepTwoMapper.class);
job_stepTwo.setReducerClass(InverseIndexStepTwoReducer.class);
job_stepTwo.setOutputKeyClass(Text.class);
job_stepTwo.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job_stepTwo, new Path("./wc/outdata/output5/part-r-00000"));
FileOutputFormat.setOutputPath(job_stepTwo, new Path("./wc/outdata/output6"));
job_stepTwo.waitForCompletion(true);
}
} 多表连接,利用mr程序实现大数据量的关联查询
a.txt
id name
001 iphone6
002 xiaominote
003 mate7
004 nubia
005 meilan
b.txt
id orderid
001 00101
001 00110
002 01001
...
001 iphone6-->a 00101-->b 00110-->b
join query 期望结果:
select a.name,b.orderid from a,b where a.id=b.id
iphone6 00101
iphone6 00110
JoinQuery.java Github-repo-code
package com.elon33.hadoop.mapreduce.joinquery;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JoinQuery {
public static class JoinQueryMapper extends Mapper{
private Text k = new Text();
private Text v = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String record = value.toString();
String[] fields = StringUtils.split(record,"\t");
String id = fields[0];
String name = fields[1];
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
k.set(id);
v.set(name+"-->"+fileName);
// k:001 v: iphone6-->a.txt
context.write(k, v);
}
}
public static class JoinQueryReducer extends Reducer{
// 通过map阶段,已经将a.txt和b.txt中key值相同的项关联起来了,reduce阶段的任务就是对value做切分
// k:001 values:[iphone6-->a.txt, 00101-->b.txt,00110-->b.txt]
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
//第一次循环拿出a表中的那个字段
String leftKey = "";
ArrayList rightFields = new ArrayList<>();
for(Text value:values){
if(value.toString().contains("a.txt")){
leftKey = StringUtils.split(value.toString(), "-->")[0]; // leftKey:["iphone6"]
}else{
rightFields.add(value.toString()); //rightField:["00101-->b.txt", "00110-->b.txt"]
}
}
//再用leftkey去遍历拼接b表中的字段,并输出结果
for(String field:rightFields){
String result ="";
result += leftKey +"\t" +StringUtils.split(field.toString(), "-->")[0]; //result:["iphone6 00101","iphone6 00110"]
context.write(new Text(leftKey), new Text(result));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job joinjob = Job.getInstance(conf);
joinjob.setJarByClass(JoinQuery.class);
joinjob.setMapperClass(JoinQueryMapper.class);
joinjob.setReducerClass(JoinQueryReducer.class);
joinjob.setOutputKeyClass(Text.class);
joinjob.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(joinjob, new Path(args[0]));
FileOutputFormat.setOutputPath(joinjob, new Path(args[1]));
joinjob.waitForCompletion(true);
}
}
思考题
◆ 如何使用计数器
利用mr程序通过切分,合并、排序,统计得到最终的计数结果,具体实现查看 源代码
◆ Combiner的作用是什么,应用场景是什么 导航Combiner
Mapper过程中Combiner的作用 http://www.aboutyun.com/thread-7093-1-1.html
◆ Partitioner的作用是什么,应用场景是什么
将reduce通过多个分区来分别运算,得到不同分区的值。
MapReduce中combine、partition、shuffle的作用是什么?在程序中怎么运用? http://blog.csdn.net/u013063153/article/details/72357560
◆ Shuffler的过程是什么
MapReduce:详解Shuffle过程 http://langyu.iteye.com/blog/992916