MySQL基础 -- 表
目录
- 一. 表操作
- 1. MySQL数据类型
- 2. 用SQL创建表
- 3. 用SQL向表中添加数据
- 4. 用SQL删除表数据
- 5. 用SQL修改表
- 二. 作业
- 1. 列出所有超过或等于5名学生的课
- 2. 交换性别
- 三. 表联结
- 1. MySQL别名
- 2. MySQL连接的使用
- 四. 作业
- 1. 组合两张表
- 2. 删除重复的邮箱
- 3. 两张表都有的元素相加,各自有的都显示出来
- 4. 筛选在2006-06-01到2006-07-01某个时期之间的所有比赛
- 五. 视图以及存储过程
- 1. 视图
- 2. 存储过程
- 六. 管理事务处理
一. 表操作
1. MySQL数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
具体可参考:http://www.runoob.com/mysql/mysql-data-types.html
2. 用SQL创建表
创建表的时候,表中有字段,每一个字段有:
- 字段名(必需的)
- 字段数据类型(必需的)
- 字段长度限制
- 字段约束
#语法
CREATE TABLE 表名称
(
列名称1 数据类型(size),
列名称2 数据类型(size),
列名称3 数据类型(size),
....
)
约束:
- 对一个数据列建立的约束,称为列级约束
- 对多个数据列建立的约束,称为表级约束
- 列级约束即可以在列定义时生命,也可以在列定义后声明
- 表级约束只能在列定义后声明
- NOT NULL和DEFAULT只存在列级约束
- PRIMARY KEY、UNIQUE、FOREIGN KEY同时存在表级约束和列级约束
常见的字段约束:
- 非空约束:not null,针对某个字段设置其值不为空,如姓名;
- 唯一约束:unique,使某个字段的值不能重复,如手机号码;
- 主键约束:primary key,只允许一个主键,主键可以是单个字段或多字段的组合(联合主键),联合主键只能定义为表级约束;
- 外键约束:foreign key,外键主要是维护表之间的关系的,主要是为了保证参照完整性,如果表中的某个字段为外键字段,那么该字段的值必须来源于参照的表的主键;
- 检查约束:check(‘条件’),CHECK约束用来检查字段值所允许的范围。
其实约束格式是: [CONSTRAINT <约束名>] … ,通常表级约束加上去。
例如:
[CONSTRAINT <约束名>] FOREIGN KEY…REFERENCES <主表名> (<列名>)
#实例
#Persons为主表
CREATE TABLE Persons
(
#列级约束
Id int(10) primary key,
Name varchar(20) not null,
phone int(20) unique,
age int(3) ,
#CHECK表级约束( 写成列级约束也可以:age int(3) CHECK(age>0 AND age<120) )
CHECK(age>0 AND age<120)
);
#salary为从表
#外键,salary_id_FK为自己定义的外键名,外键为ID,参考列为Persons表的ID列
CREATE TABLE salary
(
ID int(10),
...
CONSTRAINT salary_id_FK FOREIGN KEY(ID) REFERENCES Persons(ID)
);
#或者也可以这样编写
CREATE TABLE salary
(
ID int(10) REFERENCES Persons(ID),
...
);
3. 用SQL向表中添加数据
INSERT INTO 语句用于向指定表格中插入新的行。
#语法
#不指定列
INSERT INTO 表名称 VALUES (值1, 值2,....);
#指定所要插入数据的列(建议使用此种方法)
INSERT INTO 表名称(列1, 列2,...) VALUES (值1, 值2,....);
#例子
INSERT INTO Persons(ID,Name,age) VALUES (002, 'XXX', 18);
4. 用SQL删除表数据
- drop table 表名称
drop (删除表):删除内容和定义,释放空间,表中数据和表结构(列、约束、视图、键)全部去掉。以后要新增数据是不可能的,除非新增一个表。 - truncate table 表名称
truncate (清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构)。与drop不同的是,只是清空表数据而已。 - delete from 表名称 where 列名称 = 值
delete (删除表中的数据):delete 语句用于删除表中的行。delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存,以便进行进行回滚操作。
例如:
DELETE FROM Persons WHERE age > 20;
不带where的delete:只删除数据,而不删除表的结构(定义)。
5. 用SQL修改表
- 添加行
上面说的INSER INTO - 删除行
上面说的 DELETE FROM 表名字 WHERE 条件; - 添加列
alter table 表名 add 列名 类型(值) 约束
alter table Persons add test1 varchar(40) NOT NULL;
新增加的列,被默认放置在这张表的最右边。如果要把增加的列插入在指定位置,则需要在语句的最后使用AFTER关键词(“AFTER 列1” 表示新增的列被放置在 “列1” 的后面)。如果想放在第一列的位置,则使用 FIRST关键词。 - 删除列
alter table 表名 drop 列名
alter table Persons drop test1; - 列名更名
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;
alter table Persons CHANGE test1 test2 varchar(10) NOT NULL;
重命名语句后面的数据类型不能省略,否则重命名失败。修改数据类型可能会导致数据丢失,所以要慎重使用。 - 更改列数据类型
ALTER TABLE 表名 MODIFY 列名字 新数据类型;
alter table Persons MODIFY test2 INT(10); - 修改表中某个值
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件;
UPDATE Persons SET age=19 WHERE ID=002
二. 作业
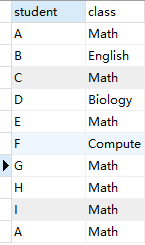
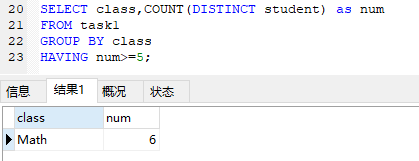
1. 列出所有超过或等于5名学生的课

- 新建表并插入数据:

- 表:
- 结果:
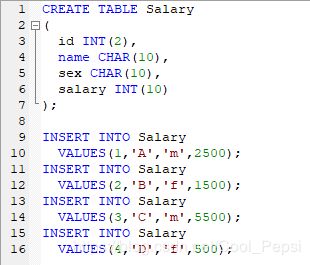
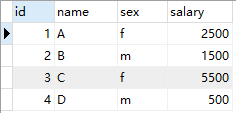
2. 交换性别

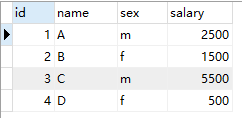
- 新建salary表并插入数据:
- Salary表:
- 结果
UPDATE Salary SET sex=(CASE WHEN sex='m' THEN 'f' ELSE 'm' END);
三. 表联结
1. MySQL别名
详细说明:https://www.yiibai.com/mysql/alias.html
使用别名方便作者编写并且增强了可读性。MySQL有列别名和表别名
- 列别名
MySQL列的别名,可以使用AS关键字后跟别名;如果别名包含空格,必须将别名用引号引住。AS关键字可以省略。
上面的第一个作业有具体例子。 - 表的别名称为表别名。像列别名一样,AS关键字是可选的,所以完全可以省略它。一般在包含INNER JOIN,LEFT JOIN,self join子句和子查询的语句中使用表别名。
2. MySQL连接的使用
在真正的应用中经常需要从多个数据表中读取数据, MySQL 的 JOIN 可以实现此功能,JOIN可以在两个或多个表中查询数据。
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录
- RIGHT JOIN(右连接):与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录
以上连接的详细说明:http://www.runoob.com/mysql/mysql-join.html
- CROSS JOIN(交叉连接):它们都返回被连接的两个表所有数据行的笛卡尔积,返回到的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。惟一的不同在于,交叉连接分开列名时,使用CROSS JOIN关键字而不是逗号。
例子:https://blog.csdn.net/tswc_byy/article/details/81948973 - 自连接:SQL自连接被用来联接表本身以作为两个表,暂时重命名,在SQL语句中至少有一个表。
例子:https://www.yiibai.com/sql/sql-self-joins.html - UNION:UNION 操作符合并两个或多个 SELECT 语句的结果。
注意:UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
详细说明:http://www.runoob.com/sql/sql-union.html
如果多次sql语句取出的列名不一致,此时以第一个sql的列名为准。
如果子句中有order by,limit,须加(),推荐放到所有子句之后使用。order by要配合limit使用才有实在意义,因为子句各自order by 之后再union在一起,最后也是无序了,不配合limit使用会被语法分析器优化分析时去除;但加了limit就规定了要各自order by之后再各自取N条记录union。
关于内联结与子查询:
例如我要查找IT部门中工资高于70000的人的姓名、工资以及部门。
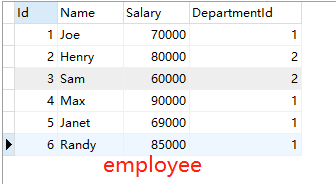
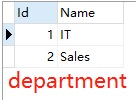
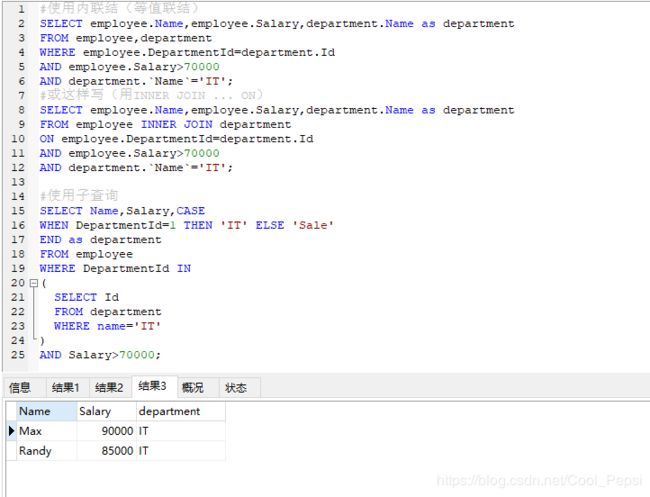
当我们不知道DepartmentId=1就是IT部门时,若要返回部门名字,是不能用子查询的,因为外部的查询是FROM employee。即当返回的查询结果涉及多张表,那是建议用联结。
四. 作业
1. 组合两张表

- 创建表:

- 表:
Person表:

Address表:

- 结果:
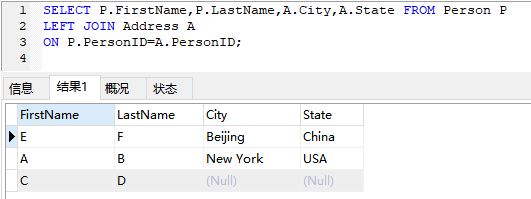
2. 删除重复的邮箱

- 之前创建过这个email表,直接上结果:
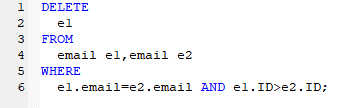
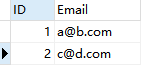
3. 两张表都有的元素相加,各自有的都显示出来

注意:单用UNION是会这样的(相当于去重了):

这里用union all

4. 筛选在2006-06-01到2006-07-01某个时期之间的所有比赛
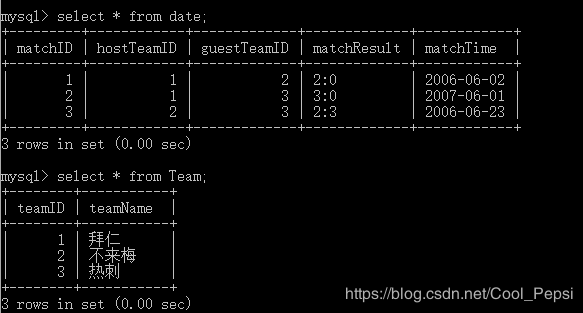
筛选在2006-06-01到2006-07-01之间的所有比赛,并以以下结果展示:

思路:因为主客队对在Team表中有对应ID,所以第一步可以先把主队名字打印出来,然后再把客队名字打印出来;
用两次左连接,分别对date表和Team表(另名t1)左连接求主队名字,再与Team(另名t2)左连接求客队名字。

五. 视图以及存储过程
1. 视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。

视图为虚拟的表。它们包含的不是数据而是根据需要检索数据的查询。视图提供了一种封装 SELECT语句的层次,可用来简化数据处理,重新格式化或保护基础数据。
2. 存储过程
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
可参考:https://www.cnblogs.com/mark-chan/p/5384139.html
六. 管理事务处理
事务处理是一种机制,用来管理必须成批执行的 SQL操作,保证数据库不包含不完整的操作结果。利用事务处理,可以保证一组操作不会中途停止,它们要么完全执行,要么完全不执行(除非明确指示)。如果没有错误发生,整组语句提交给(写到)数据库表;如果发生错误,则进行回退到保留点(或者撤销),将数据库恢复到某个已知且安全的状态。
