spark本地模式

spark-shell
还可带参数,设置开启几个线程
spark-shell --master local[3]
设置开启3个线程去跑任务
spark调度



repartition(1)设置reduce的个数,这里设置为1
spark读取hdfs上的文件:wuke01为namenode所在机器名。
sc.textFile("hdfs://wuke01:9000/input/wuke.txt").flatMap(_.split(",")).map((_,1)).collect
var rdd1=sc.parallelize(Array(("one",1),("two",2),("three",3),("four",4)))
var rdd2=sc.parallelize(Array(("five",5),("six",6)))
(rdd1 union rdd2).repartition(1).saveAsTextFile("hdfs://wuke01:9000/tmp")
创建RDD
https://www.iteblog.com/archives/1512
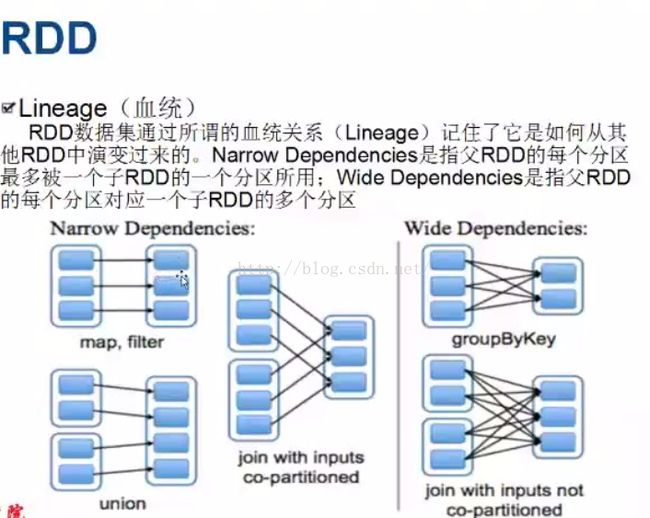
RDD血统
.cache虚拟化 (针对宽依赖的处理)
Spark standalone模式安装
配置:
spark-env.sh (conf
目录下
)
export
JAVA_HOME= /usr/java/jdk1.7.0_67-cloudera/
export
SPARK_MASTER_IP= 127.0.0.1 (指定主节点)
export
SPARK_WORKER_CORES=6 (配置worker节点的cpu核数)
export
SPARK_WORKER_INSTANCES=2 (启动多少个worker,一台从节点机器可以有多个WORKER,一个worker启动一个JVM)
export
SPARK_WORKER_MEMORY=10g (每个worker占多少内存)
export
SPARK_MASTER_PORT= 7076 (spark URL端口,如spark://crxy172:7076)
export
SPARK_JAVA_OPTS=
"-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps”
(用来设置
GC
参数)
注意:SPARK_WORKER_CORES * SPARK_WORKER_INSTANCES= 每台机器总cores
slaves (conf
目录下
)
xx.xx.xx.
1
//
从节点机器
ip
,可以写
hostname
xx.xx.xx.
2
给
spark-shell
指定
URL
地址
MASTER=spark://crxy172:7077 ./spark-shell
Spark standalone模式安装
Spark 1.0相关变动:
spark-defaults.conf
默认参数:
spark.master spark://server1:8888
spark.local.dir
本地目录
/data/tmp_spark_dir/ (
新增
)
spark.executor.memory 10g
SPARK_JAVA_OPTS
不建议在使用
(用来设置
GC
参数)
SPARK_SUBMIT_OPTS
作为替代者
SPARK_MEM 已被弃⽤
任务提交:
./bin/spark-submit –class cn.crxy.standalone xxx.jar inputdir outdir
提交任务
用maven将项目打包成jar包后,拷贝到服务器上,用spark-submit提交任务spark-submit --class main函数所在的类全路径名 jar包所在位置 后面就是输入的参数(比如输入路径 输出路径)
spark-submit --class com.xxx.mainClass xxx.jar hdfs://xxx/input/word.txt hdfs://xxx/output