一、并发
Unable to create new native thread ……
问题1:Java中创建一个线程消耗多少内存?
每个线程有独自的栈内存,共享堆内存
问题2:一台机器可以创建多少线程?
CPU,内存,操作系统,JVM,应用服务器
我们编写一段示例代码,来验证下线程池与非线程池的区别:
//线程池和非线程池的区别
public class ThreadPool {
public static int times = 100;//100,1000,10000
public static ArrayBlockingQueue arrayWorkQueue = new ArrayBlockingQueue(1000);
public static ExecutorService threadPool = new ThreadPoolExecutor(5, //corePoolSize线程池中核心线程数
10,
60,
TimeUnit.SECONDS,
arrayWorkQueue,
new ThreadPoolExecutor.DiscardOldestPolicy()
);
public static void useThreadPool() {
Long start = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
threadPool.execute(new Runnable() {
public void run() {
System.out.println("说点什么吧...");
}
});
}
threadPool.shutdown();
while (true) {
if (threadPool.isTerminated()) {
Long end = System.currentTimeMillis();
System.out.println(end - start);
break;
}
}
}
public static void createNewThread() {
Long start = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
new Thread() {
public void run() {
System.out.println("说点什么吧...");
}
}.start();
}
Long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void main(String args[]) {
createNewThread();
//useThreadPool();
}
}启动不同数量的线程,然后比较线程池和非线程池的执行结果:
| 非线程池 | 线程池 | |
|---|---|---|
| 100次 | 16毫秒 | 5ms的 |
| 1000次 | 90毫秒 | 28ms |
| 10000次 | 1329ms | 164ms |
结论:不要new Thread(),采用线程池
非线程池的缺点:
-
每次创建性能消耗大
- 无序,缺乏管理。容易无限制创建线程,引起OOM和死机
1.1 使用线程池要注意的问题
避免死锁,请尽量使用CAS
我们编写一个乐观锁的实现示例:
public class CASLock {
public static int money = 2000;
public static boolean add2(int oldm, int newm) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (money == oldm) {
money = money + newm;
return true;
}
return false;
}
public synchronized static void add1(int newm) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
money = money + newm;
}
public static void add(int newm) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
money = money + newm;
}
public static void main(String args[]) {
Thread one = new Thread() {
public void run() {
//add(5000)
while (true) {
if (add2(money, 5000)) {
break;
}
}
}
};
Thread two = new Thread() {
public void run() {
//add(7000)
while (true) {
if (add2(money, 7000)) {
break;
}
}
}
};
one.start();
two.start();
try {
one.join();
two.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(money);
}
}使用ThreadLocal要注意
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
我们编写一个ThreadLocalMap正确使用的示例:
//ThreadLocal应用实例
public class ThreadLocalApp {
public static final ThreadLocal threadLocal = new ThreadLocal();
public static void muti2() {
int i[] = (int[]) threadLocal.get();
i[1] = i[0] * 2;
threadLocal.set(i);
}
public static void muti3() {
int i[] = (int[]) threadLocal.get();
i[2] = i[1] * 3;
threadLocal.set(i);
}
public static void muti5() {
int i[] = (int[]) threadLocal.get();
i[3] = i[2] * 5;
threadLocal.set(i);
}
public static void main(String args[]) {
for (int i = 0; i < 5; i++) {
new Thread() {
public void run() {
int start = new Random().nextInt(10);
int end[] = {0, 0, 0, 0};
end[0] = start;
threadLocal.set(end);
ThreadLocalApp.muti2();
ThreadLocalApp.muti3();
ThreadLocalApp.muti5();
//int end = (int) threadLocal.get();
System.out.println(end[0] + " " + end[1] + " " + end[2] + " " + end[3]);
threadLocal.remove();
}
}.start();
}
}
}1.2 线程交互—线程不安全造成的问题
经典的HashMap死循环造成CPU100%问题
我们模拟一个HashMap死循环的示例:
//HashMap死循环示例
public class HashMapDeadLoop {
private HashMap hash = new HashMap();
public HashMapDeadLoop() {
Thread t1 = new Thread() {
public void run() {
for (int i = 0; i < 100000; i++) {
hash.put(new Integer(i), i);
}
System.out.println("t1 over");
}
};
Thread t2 = new Thread() {
public void run() {
for (int i = 0; i < 100000; i++) {
hash.put(new Integer(i), i);
}
System.out.println("t2 over");
}
};
t1.start();
t2.start();
}
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
new HashMapDeadLoop();
}
System.out.println("end");
}
}
https://coolshell.cn/articles/9606.htmlHashMap死循环发生后,我们可以在线程栈中观测到如下信息:
/HashMap死循环产生的线程栈
Thread-281" #291 prio=5 os_prio=31 tid=0x00007f9f5f8de000 nid=0x5a37 runnable [0x0000700006349000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap$TreeNode.split(HashMap.java:2134)
at java.util.HashMap.resize(HashMap.java:713)
at java.util.HashMap.putVal(HashMap.java:662)
at java.util.HashMap.put(HashMap.java:611)
at com.example.demo.HashMapDeadLoop$2.run(HashMapDeadLoop.java:26)应用停滞的死锁,Spring3.1的deadlock 问题
我们模拟一个死锁的示例:
//死锁的示例
public class DeadLock {
public static Integer i1 = 2000;
public static Integer i2 = 3000;
public static synchronized Integer getI2() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return i2;
}
public static void main(String args[]) {
Thread one = new Thread() {
public void run() {
synchronized (i1) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (i2) {
System.out.println(i1 + i2);
}
}
}
};
one.start();
Thread two = new Thread() {
public void run() {
synchronized (i2) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (i1) {
System.out.println(i1 + i2);
}
}
}
};
two.start();
}
}死锁发生后,我们可以在线程栈中观测到如下信息:
//死锁时产生堆栈
"Thread-1":
at com.example.demo.DeadLock$2.run(DeadLock.java:47)
- waiting to lock (a java.lang.Integer)
- locked (a java.lang.Integer)
"Thread-0":
at com.example.demo.DeadLock$1.run(DeadLock.java:31)
- waiting to lock (a java.lang.Integer)
- locked (a java.lang.Integer)
Found 1 deadlock.1.3 基于JUC的优化示例
一个计数器的优化,我们分别用Synchronized,ReentrantLock,Atomic三种不同的方式来实现一个计数器,体会其中的性能差异
//示例代码
public class SynchronizedTest {
public static int threadNum = 100;
public static int loopTimes = 10000000;
public static void userSyn() {
//线程数
Syn syn = new Syn();
Thread[] threads = new Thread[threadNum];
//记录运行时间
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
//syn.increaseLock();
syn.increase();
}
}
});
threads[i].start();
}
//等待所有线程结束
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userSyn" + "-" + syn + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void useRea() {
//线程数
Syn syn = new Syn();
Thread[] threads = new Thread[threadNum];
//记录运行时间
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
syn.increaseLock();
//syn.increase();
}
}
});
threads[i].start();
}
//等待所有线程结束
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userRea" + "-" + syn + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void useAto() {
//线程数
Thread[] threads = new Thread[threadNum];
//记录运行时间
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
Syn.ai.incrementAndGet();
}
}
});
threads[i].start();
}
//等待所有线程结束
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userAto" + "-" + Syn.ai + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void main(String[] args) {
SynchronizedTest.userSyn();
SynchronizedTest.useRea();
SynchronizedTest.useAto();
}
}
class Syn {
private int count = 0;
public final static AtomicInteger ai = new AtomicInteger(0);
private Lock lock = new ReentrantLock();
public synchronized void increase() {
count++;
}
public void increaseLock() {
lock.lock();
count++;
lock.unlock();
}
@Override
public String toString() {
return String.valueOf(count);
}
}结论,在并发量高,循环次数多的情况,可重入锁的效率高于Synchronized,但最终Atomic性能最好。
二、通信
2.1 数据库连接池的高效问题
- 一定要在finally中close连接
- 一定要在finally中release连接
2.2 OIO/NIO/AIO
| OIO | NIO | AIO | |
|---|---|---|---|
| 类型 | 阻塞 | 非阻塞 | 非阻塞 |
| 使用难度 | 简单 | 复杂 | 复杂 |
| 可靠性 | 差 | 高 | 高 |
| 吞吐量 | 低 | 高 | 高 |
结论:我性能有严苛要求下,尽量应该采用NIO的方式进行通信。
2.3 TIME_WAIT(client),CLOSE_WAIT(server)问题
反应:经常性的请求失败
获取连接情况 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
-
TIME_WAIT:表示主动关闭,优化系统内核参数可。
-
CLOSE_WAIT:表示被动关闭。
- ESTABLISHED:表示正在通信
解决方案:二阶段完成后强制关闭
2.4 串行连接,持久连接(长连接),管道化连接
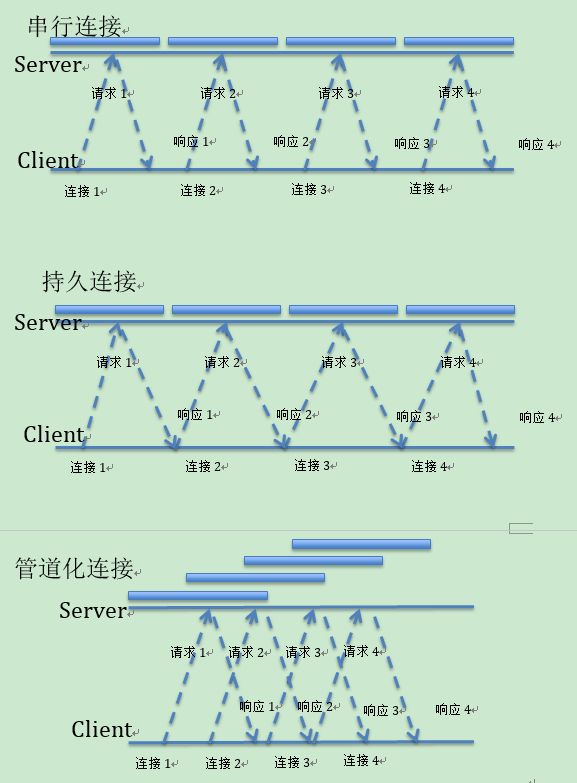
结论:
管道连接的性能最优异,持久化是在串行连接的基础上减少了打开/关闭连接的时间。
管道化连接使用限制:
1、HTTP客户端无法确认持久化(一般是服务器到服务器,非终端使用);
2、响应信息顺序必须与请求信息顺序一致;
3、必须支持幂等操作才可以使用管道化连接.
三、数据库操作
必须要有索引(特别注意按时间查询)
单条操作or批量操作
注:很多程序员在写代码的时候随意采用了单条操作的方式,但在性能要求前提下,要求采用批量操作方式。
四、JVM
4.1 CPU标高的一般处理步骤
- top查找出哪个进程消耗的cpu高
- top –H –p查找出哪个线程消耗的cpu高
- 记录消耗cpu最高的几个线程
- printf %x 进行pid的进制转换
- jstack记录进程的堆栈信息
- 找出消耗cpu最高的线程信息
4.2 内存标高(OOM)一般处理步骤
- jstat命令查看FGC发生的次数和消耗的时间,次数越多,耗时越长说明存在问题;
- 连续查看jmap –heap 查看老生代的占用情况,变化越大说明程序存在问题;
- 使用连续的jmap –histo:live 命令导出文件,比对加载对象的差异,差异部分一般是发生问题的地方。
4.3 GC引起的单核标高
单个CPU占用率高,首先从GC查起。
4.4 常见SY标高
- 线程上下文切换频繁
- 线程太多
- 锁竞争激烈
4.5 Iowait标高
如果IO的CPU占用很高,排查涉及到IO的程序,比如把OIO改造成NIO。
4.6 抖动问题
原因:字节码转为机器码需要占用CPU时间片,大量的CPU在执行字节码时,导致CPU长期处于高位;
现象:“C2 CompilerThread1” daemon,“C2 CompilerThread0” daemon CPU占用率最高;
解决办法:保证编译线程的CPU占比。
作者:梁鑫
来源:宜信技术学院