之前我们简单了解了各种查询的用法,然而在实际开发中还会用到一些比较高级的数据处理和查询,包括索引、视图、存储过程和触发器。从而能够更好地实现对数据库的操作、诊断及优化。
什么是索引呢,索引是 SQL Server 编排数据的内部方法,他为 SQL Server 提供了一种方法来编排查询数据的路由,从而达到通过使用索引来提高数据库的检索速度、改善数据库性能。
索引也是分为以下六类:
1、唯一索引:不允许两行具有相同的索引值,创建了唯一约束,将会自动创建唯一索引。
2、主键索引:是唯一索引的特殊类型,将表定义一个主键时将自动创建主键索引,他要求主键中的每个值都是唯一的。
3、聚集索引:在聚集索引中,表中各行的物理顺序和键值的逻辑索引顺序相同。(注意:一个表中只能包含一个聚集索引)
4、非聚集索引:建立在索引页上,在查询数据时可以从索引中找到记录存放的位置,聚集索引比非聚集索引有更快的数据访问速度。
5、复合索引:可以将多个列组合为索引。
6、全文索引:是一种特殊类型的基于标记的功能性索引,主要用于在大量文本中搜索字符串。
创建唯一索引:(不可有重复值)
create unique nonclustered index U_cardID
on TStudent (cardID)查看表上的索引:
Select * from sys.sysindexes
where id=(select object_id from sys.all_objects where name='Tstudent')按照指定的索引进行查询:
SELECT * FROM xueyuan
WITH (INDEX = IX_name)
WHERE 学员姓名 LIKE '孙%'视图是一种虚拟表,通常是作为来自一个或多个表的行或列的子集创建的。
视图的作用就是:
1、筛选表中的数据
2、防止未经允许的用户访问敏感数据
3、将多个物理数据表抽象为一个逻辑数据表
对用户的好处就是:结果更容易理解、获得数据更容易
对开发人员的好处就是:限制数据检索更容易、维护应用程序更方便
注意事项:
1、每个视图中可以使用多个表
2、与查询相似,一个视图可以嵌套另一个视图,最好不要超过三层
3、试图定义的 select 语句不能包括以下:
- ORDER BY 子句,除非在 select 语句中的选择列表中也有一个 TOP 子句
- INTO 关键字
- 引用临时表或表变量
创建视图:create view netstudent as select Sname,sex,Class from dbo.TStudent where Class='网络班'从视图中查找数据:
select * from netstudent where sex='男'创建视图、更改列的表头:
create view V_Tstudent1 as select StudentID 学号,Sname 姓名,sex 性别,cardID ×××号码,Birthday 生日,Class 班级 from dbo.TStudent select * from V_Tstudent1什么是存储过程,存储过程就是 SQL 语句和控制语句的预编译集合,保存在数据库里,可由应用程序调用执行。
那为什么需要存储过程呢,因为从客户端(client)通过网络向服务器(server)发送 SQL 代码并执行是不妥当的,导致数据可能会泄露不安全,印象了应用程序的运行性能,而且网络流量大。
使用存储过程的优点就是:
1、模块化程序设计
2、执行速度快、效率高
3、减少网络流量
4、具有良好的安全性
存储过程分为两类:系统存储过程和用户自定义的存储过程
系统存储过程:
是一组预编译的T-SQL语句,提供了管理数据库的更新表的机制,并充当从系统表中检索信息的快捷方式
以“sp” 开头,存放在 Resource数据库中,常用的系统存储过程有如下:
使用 T-SQL 语句调用执行存储过程的语法:EXEC [UTE] 存储过程名 [参数值] EXEC为EXECUTE的简写常用系统存储过程的用法:
exec sp_databases --列出当前系统中的数据库 exec sp_renamedb 'mybank','bank' --改变数据库名称(单用户访问) use MySchool go exec sp_tables --当前数据库中可查询对象的列表 exec sp_columns student --查看表student中列的信息 exec sp_help student --查看表student的所有信息 exec sp_helpconstraint student --查看表student表的约束 exec sp_helptext view_student_result --查看视图的语句文本 exec sp_stored_procedures --返回当前数据库中的存储过程列表根据系统存储过程的不同作用,系统存储过程可以分为不同类,扩展存储过程是 SQL Server 提供的各类系统存储过程中的一类。
允许使用其他编程语言(如C#)创建外部存储过程,提供从 SQL Server 实例到外部程序的接口
以“xp”开头,以DLL形式单独存在
一个常用的扩展存储过程为 xp_cmdshell 他可完成DOS命令下的一些操作,就以它为例举
语法为:**EXEC xp_cmdshell DOS命令 [NO_OUTPUT]**
一般 xp_cmdshell 作为服务器安全配置的一部分被关闭,应使用如下语句启用:exec sp_configure 'show advanced options', 1 --显示高级配置选项(单引号中的只能一个空格隔开) go reconfigure --重新配置 go exec sp_configure 'xp_cmdshell',1 --打开xp_cmdshell选项 go reconfigure --重新配置启用之后执行如下语句:
exec xp_cmdshell 'mkdir c:\bank',no_output --创建文件夹c:\bank exec xp_cmdshell 'dir c:\bank\' --查看文件用户自定义的存储过程:
一个完整的存储过程包括 - 输入参数和输出参数
- 在存储过程中执行的T-SQL语句
- 存储过程的返回值
用SSMS创建存储过程
一个完整的存储过程包括以下三部分:
1、输入和输出参数
2、在存储过程中执行的 T-SQL 语句
3、存储过程的返回值
使用 T-SQL 语句创建存储过程的语法为:CREATE PROC[EDURE] 存储过程名 [ {@参数1 数据类型 } [= 默认值] [OUTPUT], ……, {@参数n 数据类型 } [= 默认值] [OUTPUT] ] AS SQL语句删除存储过程的语法为:
DROP PROC[EDURE] 存储过程名
举个例子,实现查询该课程最近一次考试的平均分:use schoolDB go if exists (select * from sysobjects where name='usp_getaverageresult') drop procedure usp_getaverageresult go create procedure usp_getaverageresult as declare @subjectid nvarchar(4) select @subjectid=subjectid from dbo.TSubject where subJectName='网络管理' declare @avg decimal (18,2) select @avg=AVG(mark) from dbo.TScore where subJectID=@subjectid print '网络管理专业平均分是:'+convert(varchar(5),@avg) go编写完毕之后执行:
exec usp_getaverageresult
触发器:
是在对表进行增、改或删操作时自动执行的存储过程
用于强制业务规则,可以定义比用 CHECK 约束更为复杂的约束
通过事件触发而被执行的
触发器分为三类:
INSERT触发器:当向表中插入数据时触发
UPDATE触发器:当更新表中某列、多列时触发
DELETE触发器:当删除表中记录时触发
inserted表和deleted表
由系统管理,存储在内存而不是数据库中,因此,不允许用户直接对其修改
临时存放对表中数据行的修改信息
当触发器工作完成,它们也被删除
触发器的作用就是:强化约束、跟踪变化、级联运行
创建触发器的语法为:
create trigger *triggername(触发器名)*
on *tablename(表名)*
[with encryption]
for {[delete,insert,update]}
as SQL 语句例:创建触发器,禁止修改admin表中的数据
create trigger reminder
on admin
for update
as
print '禁止修改,请联系DBA'
rollback transaction
go然后执行语句查看错误信息:
update Admin set LoginPwd='123' where LoginId='benet'
select * from Admin
事务(一般用在银行交易这一方面,如转账)
是一个不可分割的工作逻辑单元
一组命令,要么都执行,要么都不执行
事务作为单个逻辑工作单元执行的一系列操作,一个逻辑单元必须具备四个属性:原子性、一致性、隔离性、持久性,这些特性通常简称为ACID。
举个例子,以转账为准
首先创建表名为bank: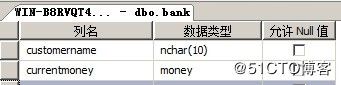
为 Currentmoney列的Check约束: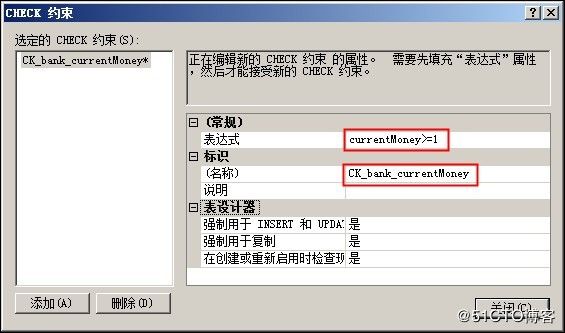
插入两条数据:
INSERT INTO bank(customerName,currentMoney) VALUES('张三',1000)
INSERT INTO bank(customerName,currentMoney) VALUES('李四',1)然后输入代码事务执行:
select customername,currentmoney as 转帐事务前的余额 from bank --查看转账事务前的余额
go
begin transaction -- 开始事务(指定事务从此开始,后续的T-SQL语句是一个整体)
declare @errorsum int --定义变量,用于累计事务执行过程中的错误
set @errorsum=0 --初始化为0,即无错误
update bank set currentmoney=currentmoney-1000 --转账,张三账户少1000 李四账户多1000
where customername='张三'
set @errorsum=@errorsum+@@ERROR --累计是否有错误
update bank set currentmoney=currentmoney+1000
where customername='李四'
set @errorsum=@errorsum+@@ERROR --累计是否有错误
select customername,currentmoney as 转帐事务过程中的余额 from bank --查看那转账过程中的余额
if @errorsum<>0 --如果有错误
begin
print '交易失败,回滚事务'
rollback transaction
end
else
begin
print '交易成功,提交事务,写入硬盘,永久的保存'
commit transaction
end
go
select customername,currentmoney as 转帐事务后的余额 from bank --查看转账后的余额转账失败:
转账成功: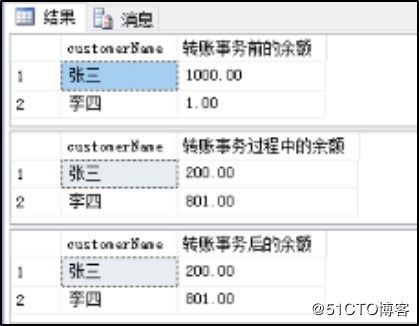
锁:
多用户能够同时操纵同一个数据库中的数据,会发生数据不一致的现象,锁就是能够在多用户环境下保证数据的完整性和一致性
锁的三种模式:
共享锁(S锁):用于读取资源所加的锁。
排他锁(X锁):和其他锁不兼容,包括其他排他锁。
更新锁(U锁):U锁可以看做S锁和X锁的结合,用于更新数据。
查看锁:
使用sys.dm_tran_locks动态管理视图
使用Profiler来捕捉锁信息
死锁
死锁的本质是一种僵持状态,是由多个主体对资源的争用而导致的。
形成死锁的条件是:
1、互斥条件:主体对资源是独占的
2、请求与等待条件
3、不剥夺条件
4、环路等待条件
预防死锁:
破坏互斥条件
破坏请求与等待条件
破坏不剥夺条件