1、Tomcat8优化
tomcat服务器在JavaEE项目中使用率非常高,所以在生产环境对tomcat的优化也变得非常重要了。
对于tomcat的优化,主要是从两个方面入手,第一是,tomcat自身的配置,另一个是tomcat所运行的jvm虚拟机的。1.1、Tomcat配置优化
1.1.1、部署安装tomcat8
下载并安装 :https://tomcat.apache.org/download-80.cgi 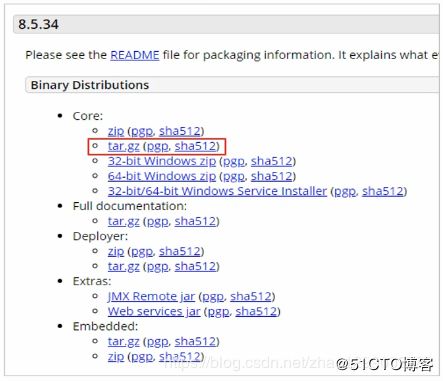
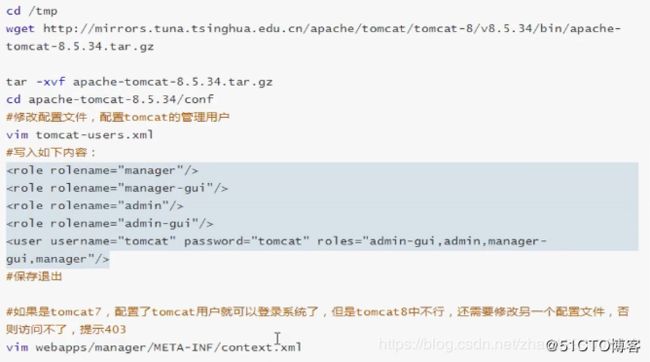

1.1.2 禁用AJP连接
在服务状态页面中可以看到,默认状态下会启用AJP服务,并且占用8009端口。
什么是AJP呢?
AJP(Apache JServer Protocol)
AJPv13协议是面向包的。WEB服务器和Servlet容器通过TCP连接来交互;为了节省Socket创建的昂贵代价,WEB服务器会
尝试维护一个永久TCP连接到servlet容器,并且在多个请求和响应周期过程会重用连接。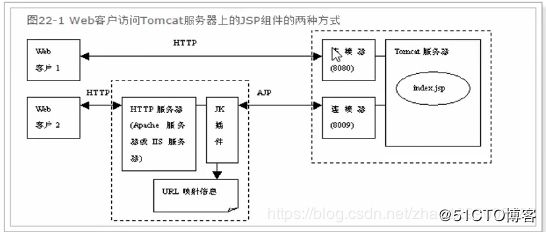
我们一般是使用Nginx+tomcat的架构,所以用不着AJP协议,所以把AJP连接器禁用。修改conf下的server.xml文件,将AJP
服务禁用掉即可。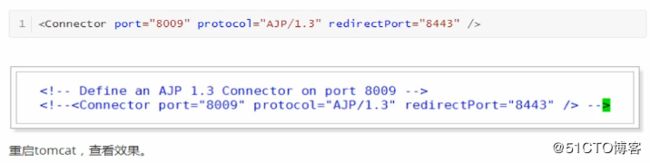
1.1.3、执行器(线程池)
在tomcat中每一个用户请求都是一个线程,所以可以使用线程池提高性能。
修改server.xml文件 :

保存退出,重启tomcat,查看效果。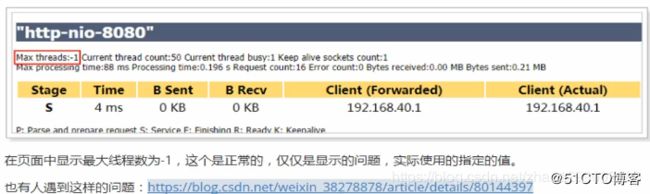
1.1.4 3种运行模式
tomcat的运行模式有3种 :
1. bio
默认的模式,性能非常低下,没有经过任何优化处理和支持。
2. nio
nio(new I/O),是Java SE 1.4及后续版本提供的一种新的I/O操作方式(既java.nio包及其子包)。Java nio是一个基于缓冲区、
并能提供非阻塞I/O操作的Java API,因此nio也被看成是non-blocking I/O的缩写。它拥有比传统I/O操作(bio)更好的并发运行
性能。
3. apr
安装起来最空难,但是从操作系统级别来解决异步的IO问题,大幅度的提高性能。
推荐使用nio,不过,在tomcat8中有最新的nio2,速度更快,建议使用nio2.
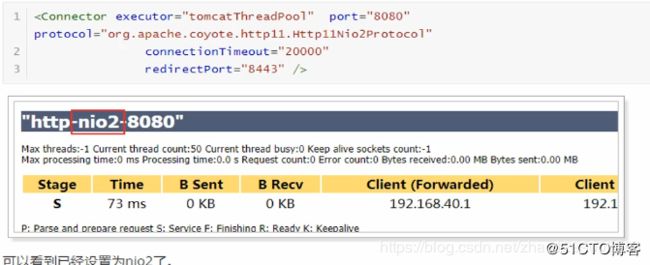
建议tomcat8以下使用nio,tomcat8及以上使用nio2.
1.3、使用Apache JMeter进行测试
Apache JMeter是开源的压力测试工具,测量tomcat的吞吐量等信息。
1.3.1、下载安装
下载地址 :http://jmeter.apache.org/download_jmeter.cgi
安装 :直接将下载好的zip压缩包进行解压即可。
1.3.2、修改主题和语言
默认的主题是黑色风格的主题并且语言是英语,这样不太方便使用,所以需要修改一下主题和中文语言。
1.3.3、创建首页的测试用例
第一步 :保存测试用例
第二步 :添加线程组,使用线程模拟用户的并发
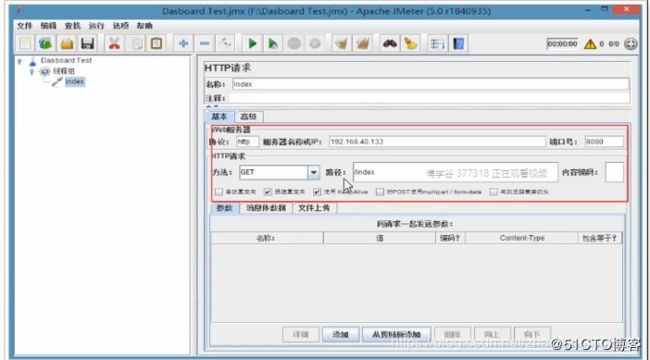
第四步 :添加请求监控
1.3.4、启动、进行测试
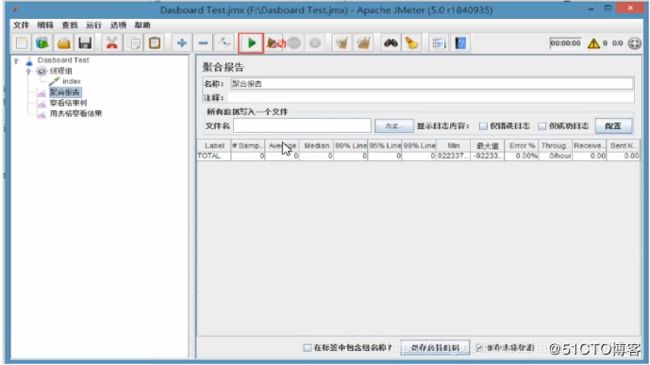
1.3.5、聚合报告
在聚合报告中,重点看吞吐量
1.4、调整tomcat参数进行优化
通过上面测试可以看出,tomcat在不做任何调整时,吞吐量为73次/秒。
1.4.1、禁用AJP服务
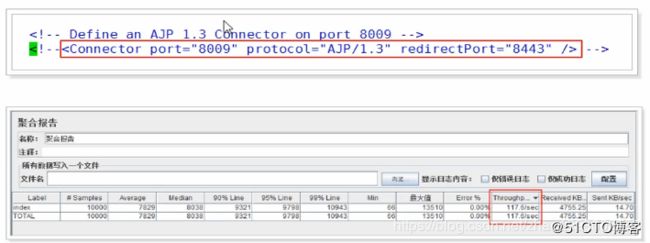
可以看到,禁用AJP服务后,吞吐量会有所提升。
1.4.2、设置线程池
通过设置线程池,调整线程池相关的参数进行测试tomcat的性能。
1.4.2.1、最大线程数为500,初始为50
![]()
测试结果 :

吞吐量为128次/秒。
1.4.2.2、最大线程数为1000,初始为200


吞吐量为151,有所提升。
1.4.2.3、最大线程数为5000,初始为1000
是否是线程数最多,速度越快呢?![]()

可以看到,虽然最大线程已经设置到5000,但是实际测试效果并不理想,并且平均的响应时间也变长, 所以单纯靠提升线程数量是不能一直得到性能提升的。
1.4.2.4、设置最大等待队列数
默认情况下,请求发送到tomcat,如果tomcat正忙,那么该请求会一直等待。这样虽然可以保证每个请求都能请求到,但是请求时间就会变长。
有些时候,我们也不一定要求请求一定等待,可以设置最大等待队列大小,如果超过就不等待了。这样虽然有些请求是失败的,但是请求时间会缩短。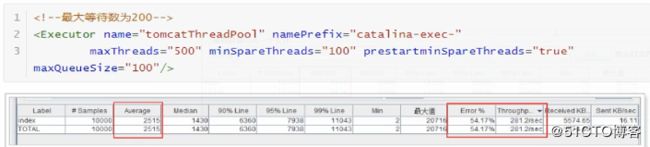
测试结果 :
平均响应时间 :2.5秒;响应时间明显缩短。
错误率 :54%;错误率提升到一半,也可以理解,最大线程为500,测试的并发为1000。
吞吐量 :281次/秒;吞吐量明显提升。
结论 :响应时间、吞吐量这2个指标需要找到平衡才能达到更好的性能。
1.4.3、设置nio2的运行模式
将最大线程设置为500进行测试 :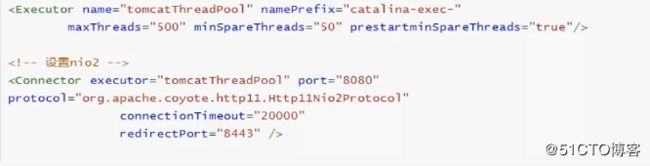

可以看到,平均响应时间有缩短,吞吐量有提升,可以得出结论 :nio2的性能要高于nio。
1.5、调整JVM参数进行优化
为了测试一致性,依然将最大线程数设置为500,启用nio2运行模式。
1.5.1、设置并行垃圾回收器
年轻代、老年代均使用并行收集器,初始堆内存64M,最大堆内存512M
JAVA_OPTS="-XX:+UseParallelGC -XX:UseParalleloldGC -Xms64 -Xmx512m -XX:+PrintGCDetails -XX:PringtGCTomeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:…/logs/gc.log"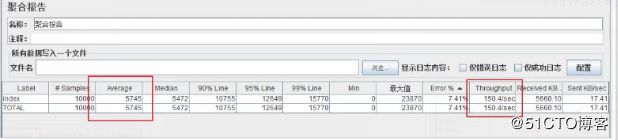
测试结果与默认的JVM参数结果接近。
1.5.2、查看GC日志
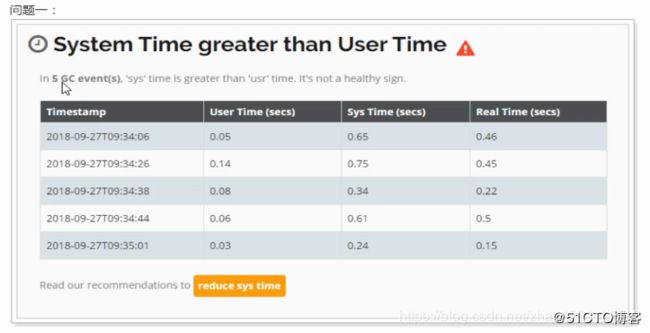
在报告中线上,在5次GC时,系统所消耗的时间大于用户时间,这反应出的服务器的性能存在瓶颈,调度CPU等资源所消耗的时间要长一些。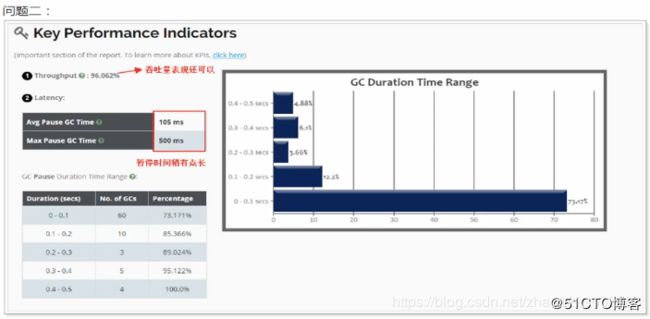
可以从关键指标中看出,吞吐量表现不错,但是GC时,线程的暂停时间稍有点长。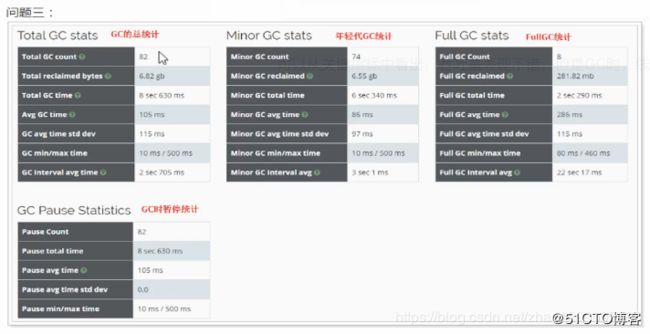
通过GC的统计可以看出 :
年轻代的gc有74次,次数稍有点多,说明年轻代设置的大小不合适需要调整;
FullGC有8次,说明堆内存的大小不合适,需要调整。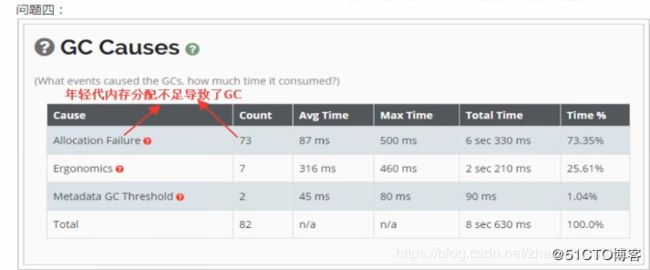
从GC原因可以看出,年轻代大小设置不合理,导致了多次GC。
1.5.3、调整年轻代大小
JAVA_OPTS="-XX:+UseParallelGC -XX:+UseParalleloldGC -Xms128m -Xmx1024m -XX:NewSize=64m -XX:MaxNewSize=256m -XX:PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:…/logs/gc.log"
将初始堆大小设置为128m,最大为1024m
初始年轻代大小64m,年轻代最大256m
从测试结果来看,吞吐量以及响应时间均有提升。
查看gc日志 :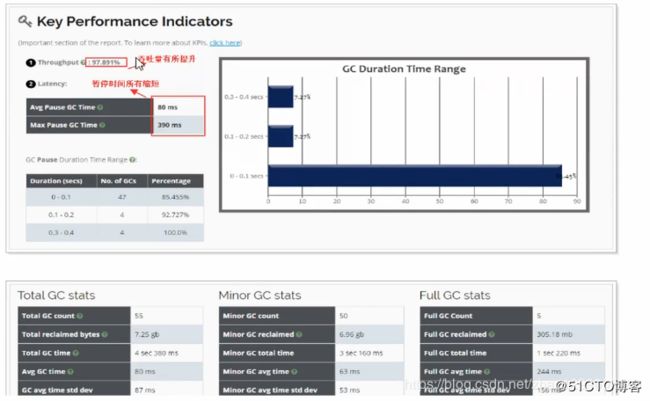
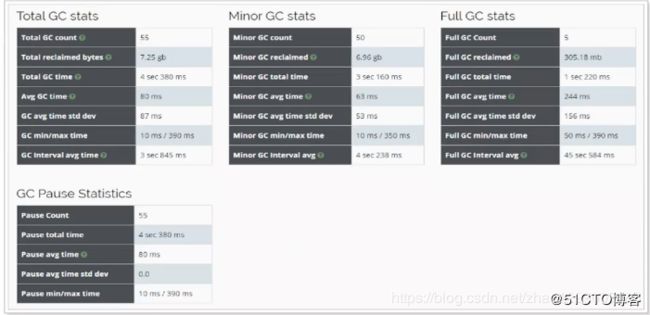
可以看到GC次数要明显减少,说明调整是有效的。
1.5.4、设置G1垃圾回收器
设置最大停顿时间100毫秒,初始堆内存128m,最大堆内存1024m
JAVA_OPTS="-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -Xms128m -Xmx1024m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:…/logs/gc.log"
测试结果 :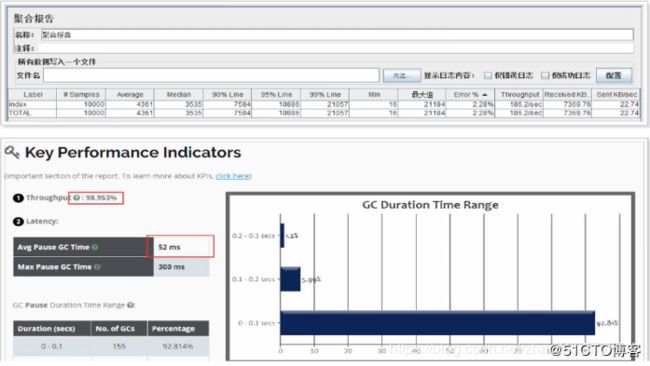
可以看到,吞吐量有所提升,响应时间也有所缩短。
1.5.5、小结
通过上述测试,可以总结出,对tomcat性能优化就是需要不断的进行调整参数,然后测试结果,可能会调优也可能会调差,这时就需要借助于gc的可视化工具来看gc的情况。再帮助我们做出决策应用调整那些参数。
2、JVM字节码
通过tomcat本身的参数以及jvm的参数对tomcat做了优化,其实要想将应用程序跑的更快、效率更高,除了对tomcat容器以及jvm优化外,应用程序代码本身如果写的效率不高,那么也是不行的,所以,对于程序本身的优化也就很重要的。
对于程序本身的优化,需要通过查看编译好的class文件中字节码。
java编写应用,需要先通过javac命令编译成class文件,再通过jvm执行,jvm执行时是需要将class文件中的字节码载入到jvm进行运行的。
2.1、通过javap命令查看class文件的字节码内容
首先,看一个简单的test1类的代码 :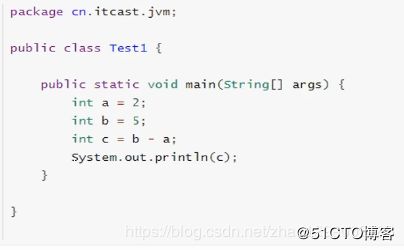
通过javap命令查看class文件中的字节码内容 :
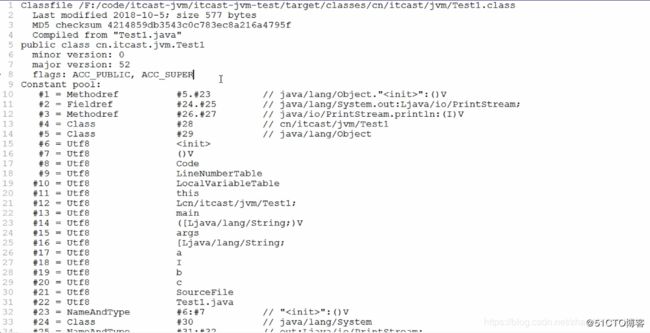
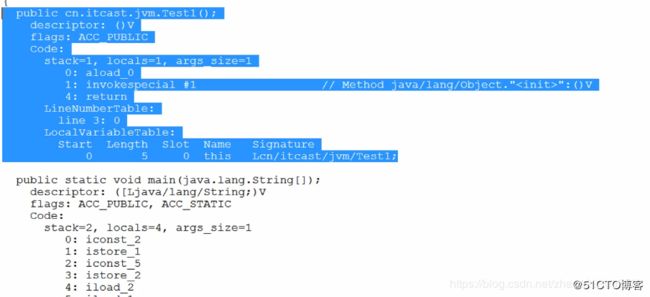
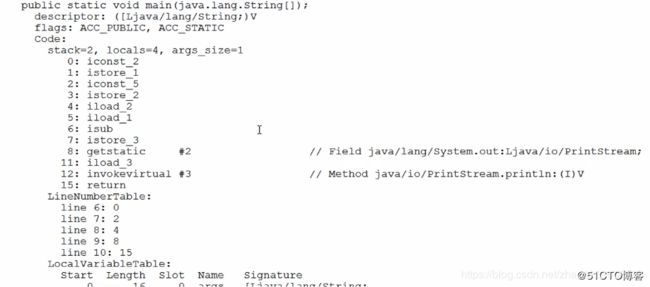
内容大致分为四个部分 :
第一部分 :显示了生成这个class的java源文件、版本信息、生成时间等。
第二部分 :显示了该类中所涉及到常量池,共35个常量。
第三部分 :显示该类的构造器,编译器自动插入的。
第四部分 :显示了main方法的信息。(这个需要重点关注)
2.2、常量池
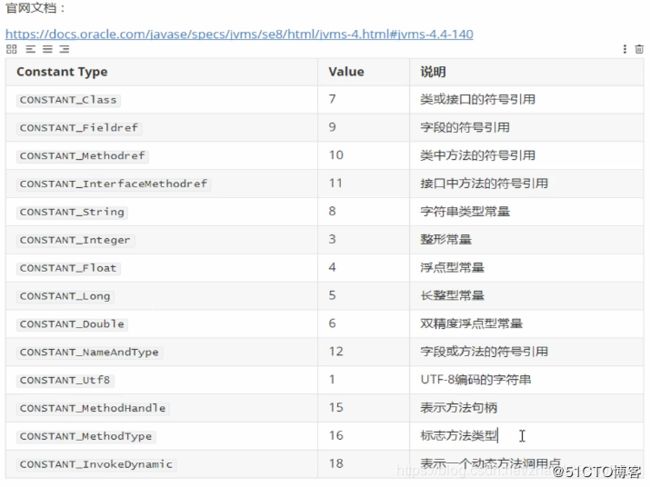
2.3、描述符
2.3.1、字段描述符
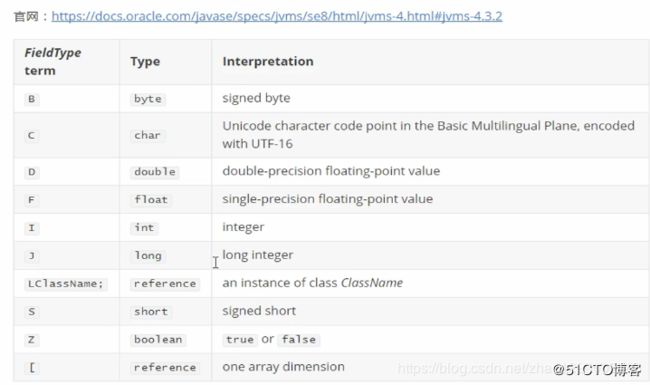
2.3.2、方法描述符
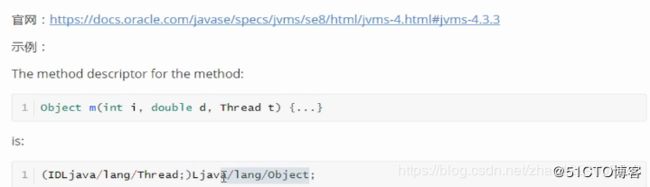
2.4、解读方法字节码
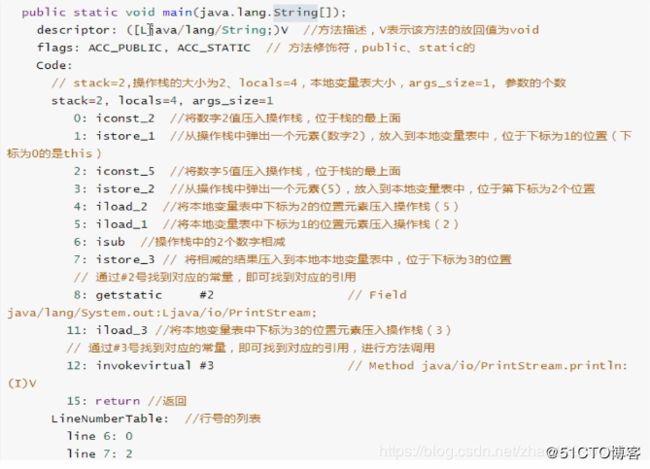

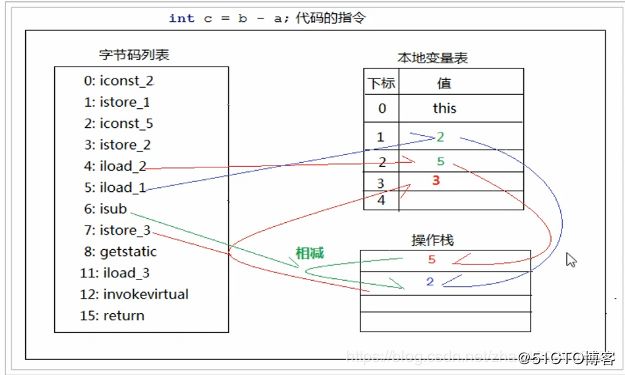
2.4.1、图解
2.5、研究i++与++i的不同
测试代码 :
2.5.1、对比

2.5.2、图解
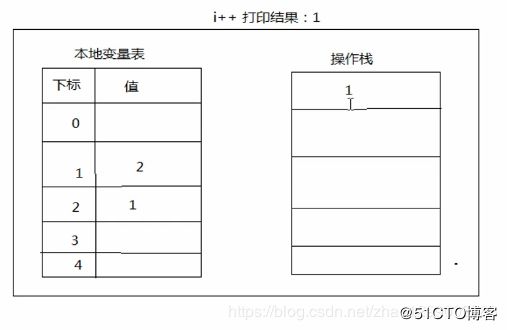
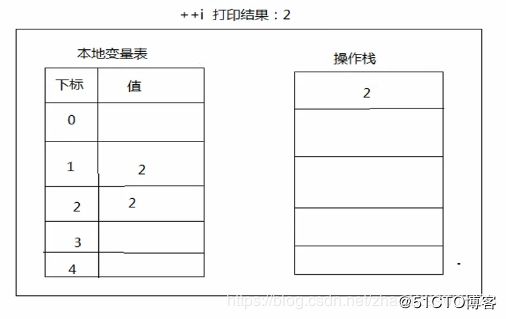
区别 :
1++
只是在本地变量中对数字做了相加,并没有将数据压入到操作栈。
将前面拿到的数字1,再次从操作栈中拿到,压入到本地变量中。
++i
将本地变量中的数字做了相加,并且将数据压入到操作栈。
将操作栈中的数据,再次压入到本地变量中。
小结 :可以通过查看字节码的方式对代码的底层做研究,探究其原理。
2.6、字符串拼接
字符串的拼接在开发过程中使用是非常频繁的,常用的方式有三种 :
+号拼接 :str + “456”
StringBuilder拼接
StringBuffer拼接
StringBuffer是保证线程安全的,效率是比较低的,但是我们更多情况下是线程安全的,所以更多时候选择StringBuilder,效率会高一些。
那么,问题来了,StringBuilder和“+”号拼接,那个效率高呢?可以通话字节码的方式进行探究。
示例 :
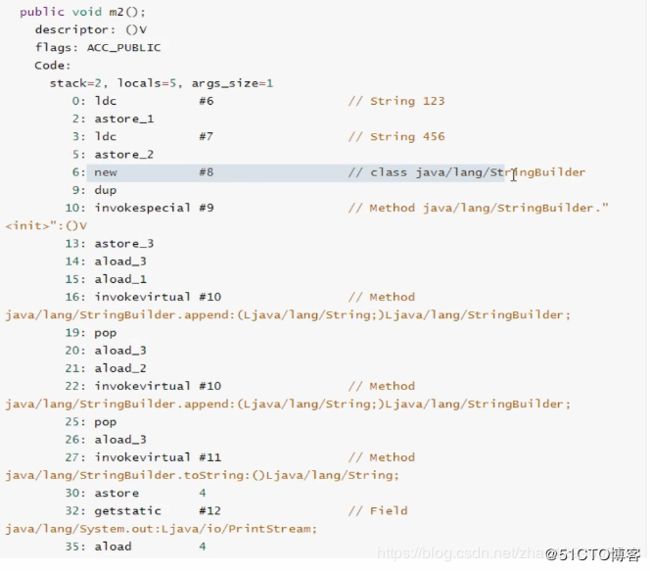
从解字节码中可以看出,m1()方法源码中是使用+号拼接,但是在字节码中也被编译成了StringBuilder方式。所以,可以得出结论,字符串拼接,+号和StringBuilder是相等的,效率一样。
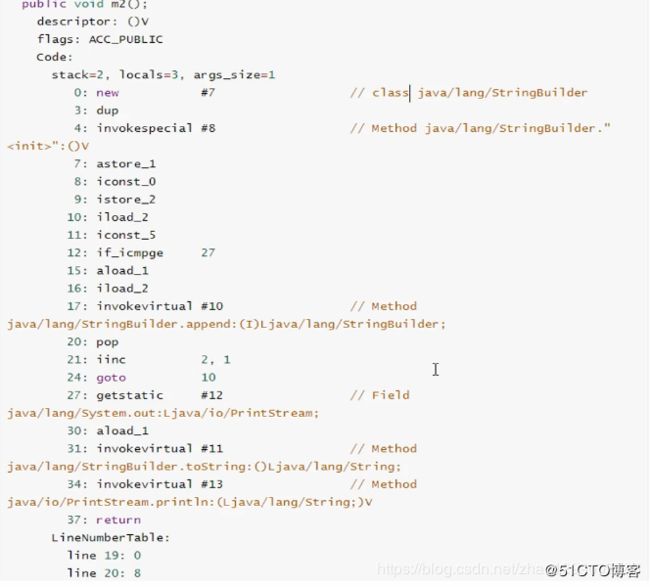
可以看到,m1()方法中的循环体内,每次循环都会创建StringBuilder对象,效率低于m2()方法。
2.7、小结
使用字节码的方式可以很好查看代码底层的执行,从而可以看出哪些实现效率高,哪些实现效率低。可以更好的对我们的代码做优化。让程序执行效率更高。
3、代码优化
不仅仅在运行环境进行优化,还需要在代码本身做优化,如果代码本身存在性能问题,那么在其他方面再怎么优化也不可能达到最优效果。
3.1、尽可能使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中速度较快,其他变量,如静态变量、实例变量等,都在堆中创建,速度较慢。另外,栈中创建的变量,随着方法的运行结束,这些内容就没了,不需要额外的垃圾回收。
3.2、尽量减少对变量的重复计算
明确一个概念,对方法的调用,即使方法中只有一条语句,也是有消耗的。例如 :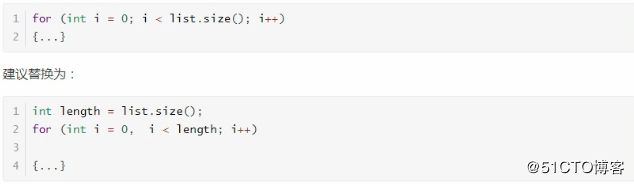
这样,在list.size()很大的时候,就减少了很多的消耗。
3.3、尽量采用懒加载的策略,即在需要的时候才创建

3.4、异常不应该用来控制程序流程
异常对性能不利。抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用名为fillInStackTrace()的本地同步方法,
filllnStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。异常只能用于错误处理,不应该用来控制程序流程。
3.5、不要将数组声明为public static final
因为毫无意义,这样只是定义了引用为static final,数组的内容还是可以随意改变的,将数组声明为public更是一个安全漏洞,这意味着这个数组可以被外部类所改变。
3.6、不要创建一些不使用的对象,不要导入一些不使用的类
这毫无意义,如果代码中出现“The value of local variable i is not used”、“The import java.util is never used”,那么请删除这些无用的内容。
3.7、程序原先过程中避免使用反射
反射是Java提供给用户一个很强大的功能,功能强大往往意味着效率不高。不建议在程序运行过程中使用尤其是频繁使用返回机制,特别是Method的invoke方法。
如果确实有必要,一种建议性的做法是将那些需要通过反射加载的类在项目启动的时候通过反射实例化出一个对象并放入内存。
其他优化
1、使用数据库连接池和线程池,这样可以重用对象,避免频繁地打开和关闭连接,后者可以避免频繁地创建和消耗线程。
2、容器初始化时尽可能指定长度,如 :new ArrayList<>(10);new HashMap<>(32);避免容器长度不足时,扩容带来性能损耗。
3、ArrayList随机遍历快,LinkedList添加删除快。
4、避免使用这种方式 :
Map map = new HashMap<>();
for (String key : map.keySet()) {
String value = map.get(key);
} 尽量使用这种方式 :
for (Map.Entry entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
} 5、不要手动调用System.gc();
6、String尽量少用正则表达式 :
正则表达式虽然功能强大,但是其效率较低,除非是有需要,否则尽可能少用。
replace() : 不支持正则
replaceAll() : 支持正则
如果仅仅是字符的替换建议使用replace();
7、日志的输出要注意级别;
8、对资源的close()建议分开操作。